AWS Database Blog
Get Started with Amazon Elasticsearch Service: How Many Data Instances Do I Need?
September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details.
Welcome to the first in a series of blog posts about Elasticsearch and Amazon Elasticsearch Service, where we will provide the information you need to get started with Elasticsearch on AWS.
How many instances will you need?
When you create an Amazon Elasticsearch Service domain, this is one of the first questions to answer.

To determine the number of data nodes to deploy in your Elasticsearch cluster, you’ll need to test and iterate. Start by setting the instance count based on the storage required to hold your indices, with a minimum of two instances to provide redundancy.
Storage Needed = Source Data x Source:Index Ratio x (Replicas + 1)
First, figure out how much source data you will hold in your indices. Then, apply a source-data to index-size ratio to determine base index size. Finally, multiply by the number of replicas you are going to store plus one (replica count is 0-based) to get the total storage required. As soon as you know the storage required, you can pick a storage option for the data nodes that dictates how much storage you will have per node. To get the node count, divide the total storage required by the storage per node.
Instances Needed = Storage Needed / Storage per data node
As you send data and queries to the cluster, continuously evaluate the resource usage and adjust the node count based on the performance of the cluster. If you run out of storage space, add data nodes or increase your Amazon Elastic Block Store (Amazon EBS) volume size. If you need more compute, increase the instance type, or add more data nodes. With Amazon Elasticsearch Service, you can make these changes dynamically, with no down time.
Determine how much source data you have
To figure out how much storage you need for your indices, start by figuring out how much source data you will be storing in the cluster. In the world of search engines, the collection of source data is called the corpus. Broadly speaking, there are two kinds of workloads AWS customers run:
- Single index workloads use an external “source of truth” repository that holds all of the content. You write scripts to put the content into the single index for search, and that index is updated incrementally as the source of truth changes. These are commonly full-text workloads like website, document, and e-commerce search.
- Rolling index workloads receive data continuously. The data is put into a changing set of indices, based on a timestamp and an indexing period (usually one day). Documents in these indices are not usually updated. New indices are created each day and the oldest index is removed after some retention period. These are commonly for analytics use cases like log analytics, time-series processing, and clickstream analytics.

If you have a single index workload, you already know how much data you have. Simply check your source of truth for how much data you’re storing, and use that figure. If you are collecting data from multiple sources (such as documents and metadata), sum up the size of all data sources to get the total.
If you have a rolling index workload, you’ll need to calculate how much data you will be storing, based on a single time period and a retention length. A very common case is to store the logs generated every 24 hours (the time period) for two weeks (the retention period). If you don’t already know how much log data you’re generating daily, you can get a rough estimate based on 256 bytes per log line times the number of log lines you’re generating daily. Multiply your daily source data size by the number of days in the retention period to determine the total source data size.
How much index space?
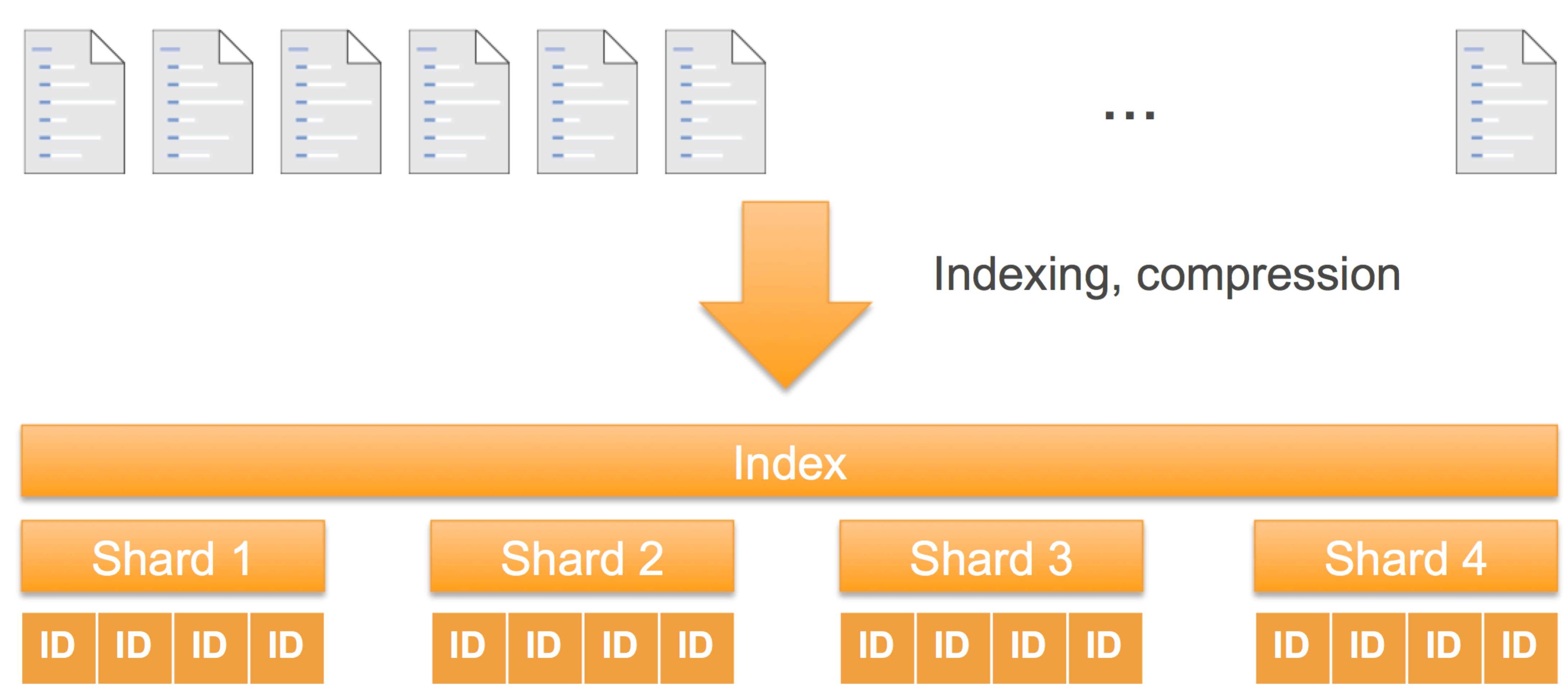
The amount of storage space you’ll use for your index depends on a number of factors. As you send your documents to Elasticsearch, they are processed to create the index structures to support searching them. The on-disk size of these index structures depends on your data and the schema you set up. In practice, and using the default settings, the ratio of source data to index size is usually approximately 1:1.1.
For all practical purposes, and remembering to leave 10% overhead, you can use the source data size as the required index storage size.
Replicas increase the index size
Elasticsearch allows you to set (and change dynamically) a number of replicas for your index. The most important reason to use a replica is to create redundancy in the cluster. For production workloads and for all cases where you cannot tolerate data loss, we recommend using a single replica for redundancy. You might need more replicas to increase query processing capacity. We’ll cover that in a future post. You can have node-level redundancy only if you have more than one node. A single node, even with a replica, will not provide high availability.
Each replica is a full copy of the index, at the shard level. As such, it uses the same storage as the primary copy of the index. If you are using one replica, double the amount of storage for the index.
What’s the storage per instance?
When you configure your Amazon Elasticsearch Service domain, you choose your storage option: instance (ephemeral) storage or EBS storage. If you choose instance storage, then the storage per data node is already set based on your instance type selection. If you choose EBS storage, you can configure the amount of storage per instance, up to the Amazon Elasticsearch Service EBS storage limit for that instance type.
For example, if you choose to use m3.medium.elasticsearch instances and choose instance store as your storage option, each node will have 4 GB of SSD storage. If you choose to use EBS as your storage, you can attach up to 100 GB to each m3.medium.elasticsearch instance.
The amount of usable storage per instance is less than the total storage available. The service files and operating system files take 3% of the storage on an m3.medium (less on larger instances). The service also reserves 20% of the disk, up to a maximum of 20 GB. What this means, especially for smaller instance types, is that if your computed storage is close to the boundary, opt for an additional data node.
Putting it all together
Let’s work through two examples.
The first example is a single index workload that represents a product catalog for an e-commerce website. The company has a catalog of 100,000 products that take up 1 GB of storage in its database. We multiply this 1 GB by the compression ratio (1.0) to get 1 GB of index size. The company will have one replica, so the total storage required is 2 GB. Because they have 4 GB available for each m3.medium.elasticsearch instance, the company could use just one node. However, they would not have anywhere to deploy a redundant replica, so they choose two m3.medium instances.
The second example is a dynamic index workload. The same company ingests data from the Twitter firehose to do brand sentiment analysis and improve their rank function for their product search. They download 100 GB of Twitter data each day and retain it for seven days. We multiply this 100 GB by the compression ratio (1.0) to get 100 GB of index daily. The company will have one replica of this data, yielding 200 GB of daily index, which they will retain for seven days. Multiplying 200 GB by seven days, the company will need 1,400 GB of storage. They choose m3.large.elasticsearch instances, to which they will attach 512 GB, General Purpose SSD (gp2) EBS volumes. At a minimum, they need three of these volumes, but decide on four m3.large.elasticsearch instances to provide additional storage.
How many instances?
It’s easy to get started with Elasticsearch using Amazon Elasticsearch Service, but there are some choices to make up front. One of your first decisions is to decide how many nodes you’ll need. You can calculate the number of nodes by determining how much data you want to store, multiplying by a compression ratio (usually 1), and then multiplying by the number of replicas. This yields the total on-disk size of the index or indices. Divide that by the per-node storage amount to get the total number of nodes required.
About the Author
 Dr. Jon Handler (@_searchgeek) is an AWS solutions architect specializing in search technologies. He works with our customers to provide guidance and technical assistance on database projects, helping them improve the value of their solutions when using AWS.
Dr. Jon Handler (@_searchgeek) is an AWS solutions architect specializing in search technologies. He works with our customers to provide guidance and technical assistance on database projects, helping them improve the value of their solutions when using AWS.