Amazon Web Services ブログ
Amazon Redshift MCP サーバーを活用した SQL 分析の高速化
データ分析者やエンジニアは、データベーススキーマを探索したり、テーブル構造を理解したり、さまざまな Amazon Redshift データウェアハウス間でクエリを実行するために、複数のツールを行き来することがよくあります。メタデータやデータを自然言語で探索できれば、このプロセスが簡素化されますが、AI エージェントは、最適な実行パスを探索して構築するために、Redshift クラスターの構成とスキーマの追加コンテキストを必要とすることがよくあります。
ここで Model Context Protocol (MCP) が AI エージェントと Redshift クラスターの橋渡しをし、データへの自然言語インターフェースをより適切にサポートするために必要な情報を提供できます。MCP は、AI アプリケーションが外部のデータソースやツールに安全に接続し、ユーザーの特定の環境に関する豊富なリアルタイムのコンテキストを提供できるようにする、オープンな標準規格です。静的なツールとは異なり、MCP を使えば AI エージェントが動的にデータベース構造を探索し、テーブル関係を理解し、Amazon Redshift 設定を完全に認識したうえでクエリを実行できます。
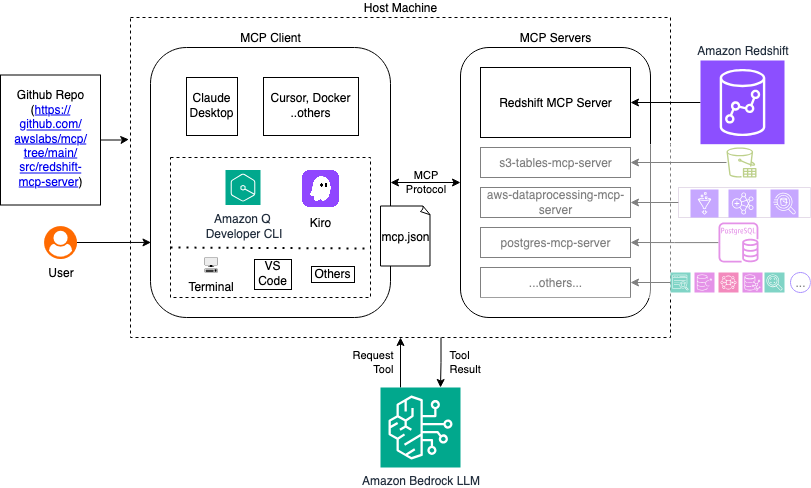
これらの課題に対処し、会話型データ分析の可能性を最大限に引き出すために、Amazon Web Services (AWS) は、Amazon Redshift データウェアハウスとのインタラクションの仕方を革新するオープンソースソリューションの Amazon Redshift MCP サーバー をリリースしました。Amazon Redshift MCP サーバーは、Amazon Q Developer コマンドラインインターフェース (CLI)、Claude Desktop、Kiro、およびその他の MCP 互換ツールとシームレスに統合されています。これにより、データベース環境を本当に理解する AI アシスタントとの自然言語会話を通じて、Amazon Redshift のメタデータとデータを発見、探索、分析できるようになります。
この記事では、Amazon Redshift MCP サーバーのセットアップ方法を説明し、データ分析者が自然言語クエリを使用して Redshift データ ウェアハウスを効率的に探索し、データ分析を行う方法を示します。
Amazon Redshift MCP サーバーとは
Amazon Redshift MCP サーバーは、AI エージェントに Amazon Redshift リソースへの安全で構造化されたアクセスを提供する MCP 実装です。以下の機能を実現します:
- クラスター検出 – プロビジョニングされた Redshift クラスターとサーバーレスワークグループの両方を自動的に検出します
- メタデータ探索 – 自然言語でデータベース、スキーマ、テーブル、カラムを参照できます
- 安全なクエリ実行 – 組み込みの安全保護機能を備えた READ ONLY モードで SQL クエリを実行できます
- マルチクラスターサポート – データ照合タスクのために、複数のクラスターとワークグループを同時に操作できます
MCP サーバーは、Amazon Q CLI とあなたの Amazon Redshift インフラストラクチャの間の橋渡しの役割を果たし、自然言語のリクエストを適切な API 呼び出しと SQL クエリに変換します。次の図は、高レベルのアーキテクチャを示しています。
前提条件
始める前に、次のものがあることを確認してください。
システム要件
- Python 3.10 以降のバージョン
uvパッケージマネージャ (インストールガイド)- Amazon Q CLI または Claude Desktop のような MCP サポートクライアントツールがインストールされ、設定済みであること
AWS の要件
- AWS Command Line Interface (AWS CLI)、環境変数、または AWS Identity and Access Management (IAM) ロールを使用して設定された AWS 認証情報
- Amazon Redshift へのアクセスに適切な IAM 権限
- 少なくとも 1 つの Redshift クラスターまたはサーバーレスワークグループ
必要な IAM 権限
ユーザー ID には、アクセスポリシーで以下の IAM 権限が必要です。
インストールと設定
次のセクションでは、Amazon Redshift MCP サーバーをインストールして設定するための手順について説明します。
必要な依存関係のインストール
次の手順に従って、必要な依存関係をインストールしてください:
uvパッケージマネージャーをまだインストールしていない場合はインストールしてください:
- Python 3.10 以降をインストールしてください:
uv python install 3.10
MCP サーバーの設定
MCP サーバーは、いくつかの MCP サポートクライアントを使用して設定できます。この記事では、Amazon Q Developer CLI と Claude Desktop を使用する手順について説明します。ホストマシンで Amazon Q Developer CLI を設定し、Amazon Redshift MCP サーバーにアクセスするには、以下の手順を実行してください。
- Amazon Q Developer CLI をインストールしてください。
- Amazon Q CLI 設定で Amazon Redshift MCP サーバーを設定します。
~/.aws/amazonq/mcp.jsonにある MCP 設定ファイルを編集してください。
インストールの詳細については、Amazon Redshift MCP サーバーの README.md のインストールセクションを参照してください。
- Amazon Q CLI を起動して、MCP サーバーが適切に設定されていることを確認します:

Amazon Redshift MCP サーバーが正常に初期化されたことを、起動ログで確認してください。ホストマシン上で Amazon Q Developer CLI をセットアップし、Claude Desktop から Amazon Redshift MCP サーバーにアクセスするには、以下の手順を実行してください。
- オペレーティングシステム用の Claude Desktop をダウンロードしてインストールします
- Claude Desktop を開き、左下のギアアイコンを選択して 設定 に移動します
- Developer タブを選択し、Amazon Q CLI 設定の手順 2 と同じ設定を追加して MCP サーバーを設定します
- MCP サーバー接続を有効にするために Claude Desktop を再起動します
- 新しい会話を開始し、
Show me all available Redshift clusters(利用可能な Redshift クラスターをすべて表示してください)と尋ねて統合をテストします
(訳註: Amazon Q Developer CLI では日本語を使用して指示や質問を行うことも可能です。)
顧客購買分析のユースケース
データアナリストが複数の Redshift クラスターにまたがる顧客の購買データを探索する必要がある実用的なシナリオを想像してみましょう。以下のウォークスルーでは、MCP サーバーがこのワークフローを簡素化する方法を示します。e コマース企業のデータアナリストとして、次の作業が必要です。
- 利用可能な Redshift クラスターを検出する
- データベース構造を調べて、顧客データと売上データを見つける
- 顧客の購買パターンを分析する
- ビジネスチームに向けて分析結果を生成する
これらのタスクを実行するには、次の手順に従います。
- Amazon Q に、利用可能な Amazon Redshift リソースを表示するよう依頼します:
Amazon Q は MCP サーバーを使用してクラスターを検出し、クラスター識別子やタイプ (プロビジョニングされたものかサーバーレスか)、現在のステータスと可用性、接続エンドポイントと設定、ノードタイプとキャパシティ情報などの詳細を提供します。
- データの構造を探索して、データの構成を把握します:
Amazon Q は、MCP サーバーを使用してクラスター内のオブジェクトを体系的に探索します:
- データを分析する前に、テーブルスキーマを把握します:
Amazon Q は MCP サーバーを使用して、テーブルの列を検査し、詳細なスキーマ情報を提供します。
- 自然言語クエリを使用して顧客の購買パターンを分析します:
Amazon Q は MCP サーバーを使用して適切な SQL クエリを実行し、インサイトを提供します。
- MCP サーバーは、複数のクラスターにまたがってデータを分析できます:
Amazon Q は MCP サーバーを使用して、適切な SQL クエリを実行し、analytics-cluster と marketing-cluster 間でデータを比較します。
ベストプラクティス
MCP サーバーには、データとシステムパフォーマンスを保護するための重要な安全対策がいくつか備わっています。READ ONLY モードは、意図しないデータ変更を防ぐための重要な保護機能であり、ユースケースに応じてこの機能を有効にすることをお勧めします。さらにセキュリティを高めるため、サーバーには潜在的に有害な影響を与える操作を検証するクエリ検証メカニズムが実装されており、最適な安全性を確保するために user-in-loop 検証が推奨されています。リソース管理については、サーバーはパフォーマンスに影響を与える無制限のクエリを防ぐためにリソース制限を適用しており、ここでもユーザーインザループ検証を行うことで最良の結果が得られます。アクセシビリティの観点では、MCP 機能は Amazon Redshift Data API がサポートされているすべての AWS リージョンで幅広く利用可能であり、Amazon Redshift Data API サービスの既存のスロットリング制限に合わせてスロットリング制限が設定されているため、一貫したパフォーマンスと信頼性が確保されています。最良の結果を得るには、以下の推奨事項に従ってください。
- ディスカバリから始める – クラスターやデータベースの構造、テーブルを探索することから始めます
- 自然言語を使う – 直接 SQL を書くのではなく、分析したいことを説明します
- 徐々に反復する – 複雑な分析を一歩ずつ構築します
- 結果を検証する – 重要な発見はビジネス担当者と相互確認します
- インサイトを文書化する – 重要なクエリと結果を将来の参照用に保存します
結論
Amazon Redshift MCP サーバーは、Kiro や Amazon Q CLI のようなエージェントツールを通じて自然言語によるデータ探索と分析を可能にすることで、データ分析者が Redshift クラスターとやり取りする方法を変革します。SQL クエリを手動で記述したり、複雑なデータベース構造を把握する必要がなくなるため、分析者はシンタックスやスキーマの探索に悩まされることなく、インサイトの生成に集中できます。一時的な分析を行うか、定期的なレポートを生成するか、新しいデータセットを探索するかにかかわらず、Amazon Redshift MCP サーバーは、データ分析ワークフローに強力で直感的なインターフェースを提供します。準備はできましたか? 以下の手順を行っていきましょう。
- この投稿の設定手順に従って MCP サーバーをインストールしてください
- 自然言語クエリを使用して Amazon Redshift 環境を探索してください
- シンプルな分析から始め、徐々に複雑さを高めてください
- 自然言語の要約を使ってチームとインサイトを共有してください
- フィードバックを提供して、MCP サーバーの機能改善に役立ててください
各ユースケースで自然言語を使用するためのナビゲーションをするブログ記事をご覧ください:
- Implementing conversational AI for S3 Tables using Model Context Protocol (MCP)
- Accelerating development with the AWS Data Processing MCP Server and Agent
- Introducing MCP Server for Apache Spark History Server for AI-powered debugging and optimization
- AWS Announces Billing and Cost Management MCP Server
- Introducing enhanced AI assistance in Amazon SageMaker Unified Studio: Agentic chat, Amazon Q Developer CLI, and MCP integration