Amazon Web Services ブログ
Amazon DynamoDB が Amazon S3 のデータを新しいテーブルにインポートできるようになりました
この記事は Amazon DynamoDB can now import Amazon S3 data into a new table (記事公開日: 2022 年 8 月 18 日) を翻訳したものです。
本日、Amazon Simple Storage Service (Amazon S3) から新しい DynamoDB テーブルへのデータのインポートを容易にする新機能をリリースします。この機能はフルマネージドで実行され、コードの記述やインフラストラクチャの管理は必要ありません。この投稿では、S3 からの DynamoDB インポート について紹介し、これを使用して一括インポートを実行する方法を示します。
概要
S3 から DynamoDB をインポートする前は、DynamoDB にデータを一括インポートするオプションが限られていました。従来のスキーマ用に設計された抽出、変換、ロード(ETL)ツールおよび移行ツールは利用できますが、単一テーブル設計やドキュメントストレージなど、さまざまな NoSQL パターンでは簡単ではない場合があります。データの一括インポートにはカスタムデータローダーが必要になる場合があり、構築と操作にはリソースが必要です。ソリューションがマルチスレッド化され、Amazon EMR クラスターなどの仮想インスタンスのフリートにデプロイされない限り、テラバイト単位のデータのロードには数日から数週間かかる場合があります。キャパシティの決定、ジョブの監視、および例外処理により、一度しか実行しないであろうソリューションが複雑になります。クロスアカウントテーブルの移行などの DBA タスクを実行する必要がある場合、Amazon S3 への DynamoDB テーブルのエクスポート 機能を使用できますが、データを新しい DynamoDB テーブルにインポートして戻すためのカスタムテーブルロードルーチンを構築する必要もあります。
S3 からの DynamoDB インポートは、コードやサーバーを必要とせずに、Amazon S3 から新しい DynamoDB テーブルにテラバイト単位のデータを一括インポートするのに役立ちます。S3 へのテーブルのエクスポート機能と組み合わせることで、DynamoDB テーブルを 1 つのアプリケーション、アカウント、または AWS リージョンから別のアプリケーション、アカウント、または AWS リージョンに簡単に移動、変換、コピーできるようになりました。CSV、DynamoDB JSON、または ION 形式でステージングされたレガシーアプリケーションデータを DynamoDB にインポートして、クラウドアプリケーションの移行を高速化できます。インポートは、AWS マネジメントコンソール 、AWS コマンドラインインターフェイス (AWS CLI) 、または AWS SDK を使用して開始できます。
S3 からの DynamoDB インポートは書き込みキャパシティーを消費しないため、新しいテーブルを定義するときに追加のキャパシティーをプロビジョニングする必要はありません。プロビジョニングされたキャパシティモードを使用する場合は、キャパシティモードとキャパシティーユニットなど、必要な最終テーブル設定のみを指定します。
インポート中、DynamoDB はデータの解析中にエラーが発生することがあります。エラーごとに、DynamoDB は Amazon CloudWatch Logs にログエントリを作成し、発生したエラーの総数のカウントを保持します。その数が10,000の閾値を超えると、ログは停止しますが、インポートは続行されます。したがって、最初に小さなデータセットでインポートをテストして、エラーなしで実行できることを確認することをお勧めします。S3 バケットのデータは、CSV、DynamoDB JSON、または ION のいずれかの形式で、GZIP または ZSTD 圧縮、もしくは圧縮なしの必要があります。各レコードには、ターゲットテーブルのキースキーマと一致するようにパーティションキー値と、オプションとしてテーブルの構成でソートキーも設定している場合はどちらも含める必要があります。
S3 から DynamoDB にデータをインポートする
S3 からの DynamoDB インポートの基本を理解したので、それを使用して Amazon S3 から新しい DynamoDB テーブルにデータを移動しましょう。一連のサンプル JSON ファイル をダウンロードして S3 バケットにデプロイし、開始できます。このウォークスルーでは、以下の図 1 に示すように、これらの非圧縮 DynamoDB JSON データファイルを、フォルダパス /demo の s3-import-demo という S3 バケットに配置したと仮定します。

図 1 — S3 バケットの内容
データレコードにはそれぞれ、PK というパーティションキーと SK と呼ばれるソートキーを持つテーブルを意図した PK および SK 属性が含まれています。新しいテーブルのキースキーマを定義するには、インポートプロセス中に一致するキー名を入力する必要があります。次のスニペットは、DynamoDB JSON 形式のいくつかのサンプルレコードを示しています。
最初の JSON レコードには PK と SK の両方のキー属性がありますが、2 番目のレコードには PK 属性がありません。キースキーマ属性 PK がないため、2 番目のレコードはインポート中にエラーが発生します。このデモンストレーションでは、2 つのエラーレコードを意図的にサンプルデータに含めます。1 つは PK 属性が欠落しており、もう 1 つは SK 属性が欠落しています。
S3 から DynamoDB にデータをインポートするには
- コンソール にログインし、DynamoDB サービスに移動します。ナビゲーションペインで Import from S3 を選択します。

図 2 — S3からのインポートの選択
- Import from S3 ページには、作成された既存または最近のインポートジョブに関する情報が一覧表示されます。Import from S3 を選択して、Import options ページに移動します。

図 3 — S3 からのインポートのリスト
- Import options ページで次の操作を行います。
- S3 URL に、ソース S3 バケットと任意のフォルダへのパスを URI 形式で入力します (例:
s3://s3-import-demo/demo)。 - This AWS account をバケット所有者として選択します。
- 残りのフィールドがデフォルトに設定されていることを確認します。
Import file format : DynamoDB JSON
Import file compression: None - Next を選択

図 4 — S3 バケットのインポートオプション
- S3 URL に、ソース S3 バケットと任意のフォルダへのパスを URI 形式で入力します (例:
- On Destination table – new table
- Table name に、新しいテーブルの名前を入力します。
- Partition key で、名前として PK と入力し、データ型として String を選択します。
- この例では、データにはソートキーが含まれています。Sort Key ボックスで、ソートキー名として SK と入力し、データ型として String を選択して、ソートキーを定義します。
- Settings で、Default settings が選択されていることを確認し、Next を選択します。これにより、5 つの読み込みキャパシティーユニット (RCU) と 5 つの書き込みキャパシティーユニット (WCU) のプロビジョニング済みキャパシティーを持つテーブルが作成されます。ただし、インポートはテーブルの容量を消費せず、これらの設定に依存しません。
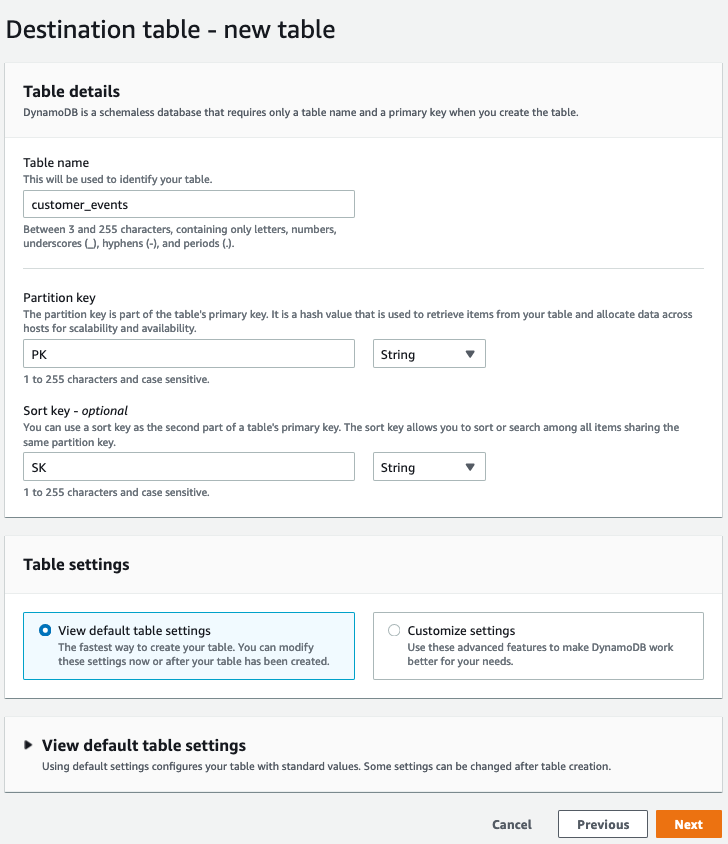
図 5 — デスティネーションテーブル — 新しいテーブル
- 選択と設定が正しいことを確認し、Import を選択してインポートを開始します。
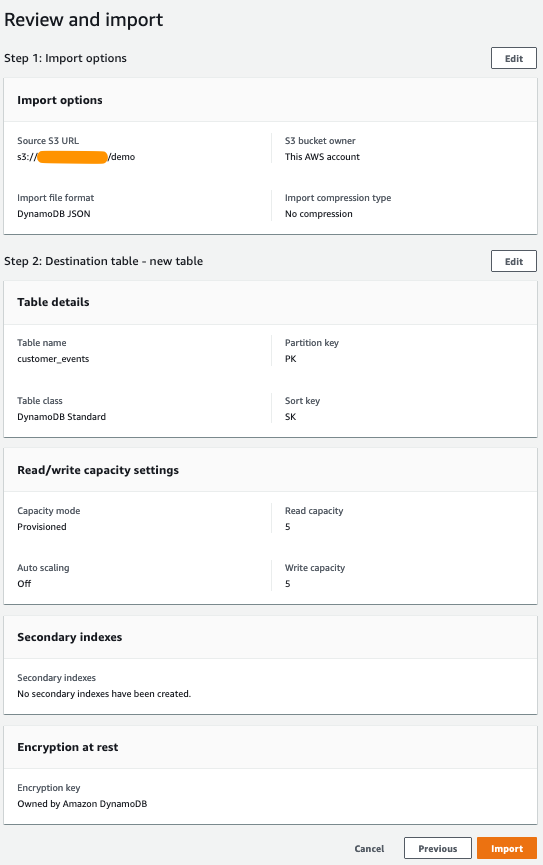
図 6 — 確認とインポート
- インポートには少し時間がかかります。インポートのステータスは、Imports from S3 ページで追跡できます。続行する前に、インポートジョブのステータスが Importing から Complete に変わるのを待ちます。
インポート結果の確認
インポートジョブごとに、DynamoDB は最初の /info ログストリームを CloudWatch に記録します。このログストリームは、インポートの開始を示し、ロギングを継続するための十分な権限が存在することを確認します。十分な権限がない場合、インポートジョブはただちに失敗します。
以下の図 7 は、CloudWatch のログストリームの例を示しています。

図 7 — CloudWatch エラーロググループ
エラーの原因となった個々のレコードが、S3 オブジェクト内のレコード番号やエラーメッセージなどのエラーメタデータとともにログに記録されます (合計エラーカウントで最大 10,000 件)。

図 8 — S3 からの DynamoDB インポート時の CloudWatch エラーログ
前の図 8 に示すように、意図的に配置された 2 つのエラーレコードのうちの 1 つに PK 属性がなく、もう 1 つに SK 属性が欠落しています。DynamoDB はこの2つの属性が新しいテーブルのパーティションキーとソートキーとして必要なので、どちらのレコードもテーブルにインポートすることができません。
前述のとおり、エラー数が 10,000 を超えると、DynamoDB はエラーのログ記録を停止しますが、残りのソースデータのインポートは続行します。エラーのトラブルシューティングの詳細については、開発者ガイド の Validation errors セクションを参照してください。テーブルのステータスが CREATING でインポートが進行中であることを示している間は、テーブル内のデータにアクセスできません。
運用上の考慮事項
サービスは、指定されたソースプレフィックスと一致するすべての S3 オブジェクトを処理しようとします。
S3 バケットは、ターゲット DynamoDB テーブルと同じリージョンである必要はありません。
以前に DynamoDB テーブルの S3 へのエクスポート 機能で作成したファイルをインポートする場合は、データフォルダへのパスを指定する必要があります。親フォルダーに含まれるマニフェストファイルは使用されません。S3 パスの例を以下に示します。 s3://my-bucket/AWSDynamoDB/01636728158007-9c06f1a9/data
AWS アカウント間でデータをインポートするには、インポートのリクエスタが、ソース S3 バケットからデータを一覧表示して取得する権限を持っていることを確認する必要があります。また、S3バケットのポリシーは、リクエスタのアクセスを許可する必要があります。
インポートジョブが実行されると、多くの並列プロセスが S3 からオブジェクトを読み取り、テーブルをロードします。従来の書き込みユニットを消費したり、インポートプロセス中にスロットリングを心配したりする必要もありません。インポートの実行に必要な時間は、主にソースデータのサイズとソースデータ内のキーの分散に応じて、数分から数時間までさまざまです。ソースデータのキーの分散が大きく偏っている場合、適切に分散されたキーを持つデータよりもインポートが遅くなる可能性があります。
発生する可能性のある一般的なエラーには、構文エラー、フォーマットの問題、必要な主キーのないレコードなどがあります。エラーに関する情報は、さらなる調査のために CloudWatch ログに記録されます。
新しい DynamoDB テーブルを定義する通常のプロセスと同様に、アプリケーションの追加のアクセスパターンをサポートするためにセカンダリインデックスを作成することを選択できます。データのロード中にセカンダリインデックスを定義すると、インポート中にインデックスが満たされるため、テーブルが稼働してから新しいセカンダリインデックスを作成して書き込みキャパシティーユニットを消費する場合に比べて、時間とコストを節約できます。
Note: インポートプロセスでは、インポートプロセス中に作成された新しいテーブルにのみデータをロードできます。
コストに関する考慮事項
インポートの実行コストは、S3 のソースデータの非圧縮サイズに GB あたりのコストを掛けたものです。これは、米国東部(バージニア北部)リージョンでは GB あたり 0.15 USD です。1 つ以上のグローバルセカンダリインデックス (GSIs) が定義されているテーブルでは、追加コストは発生しませんが、失敗したレコードのサイズによって合計コストが加算されます。
現在 DynamoDB オンデマンドバックアップを使用していて、テーブルを復元した経験がある場合、新しい S3 インポート機能のコストとパフォーマンスは同等であることがわかります。
S3 インポート機能を使用してデータをロードする総コストは、以下のコストの内訳を示したサンプルシナリオにあるように、非ネイティブソリューションを使用して DynamoDB にデータをロードする場合の通常の書き込みコストよりも大幅に低くなっています。
| Items to load | 100,000,000 |
| Item size | 2 KB |
| GSIs | 1 |
| Base table size | 191 GB |
| Total table size | 381 GB |
| WCUs required | 400,000,000 |
| DynamoDB Import from S3 price per GB | $0.15 |
| DynamoDB write modes, if importing yourself | Cost |
| On demand | $500 |
| Provisioned capacity | $83 |
| DynamoDB Import from S3 | $28 |
訳注: 上記”DynamoDB write nodes, if importing yourself”の項目でOn Demandと記載があるものはCapacty UnitのOn Demand modeです。On demand backupではないのでご注意下さい。
S3 インポート機能はすべてのリージョンで利用できます。詳細については、DynamoDBの料金表 ページを参照してください。
結論
この記事では、S3 から DynamoDB のインポート機能を紹介し、S3 バケットから DynamoDB にデータをインポートする方法を紹介しました。大規模なレガシーデータセットを DynamoDB に取り込むのがはるかに容易になりました。インフラストラクチャをセットアップしたり、ロードルーチンを記述したり、容量設定やスロットリングエラーを心配したりすることなく、インポートをリクエストできるようになりました。以前リリースされた S3 へのエクスポート機能を使用して、DynamoDB の管理を合理化できます。コンソールで数回クリックするだけで、リージョン間およびアカウント間で DynamoDB テーブルデータを移動できます。このサンプルスクリプトをスクリプトのテンプレートとして使用して、MySQL データを DynamoDB JSON 形式に変換し、S3 バケットに書き込むことができます。
翻訳はソリューションアーキテクトの木村が担当しました。原文はこちらです。