Amazon Web Services ブログ
Amazon Fraud Detector が一般提供されました
発表内容
Amazon Fraud Detector が一般提供されました!?
2019 re:Invent での発表を逃したという皆さんのために説明すると、Amazon Fraud Detector は当初、2019 年 12 月 3 日にプレビューモードでリリースされました。その Amazon Fraud Detector が本日一般提供され、お客様にお試しいただけるようになります。
Amazon Fraud Detector とは
Amazon Fraud Detector は、オンライン決済詐欺や偽のアカウントの作成など、不正行為の可能性があるオンライン活動を簡単に特定できるようにするフルマネージドサービスです。
毎年、オンライン詐欺のために世界中で数百億ドルの損害が出ていることをご存知ですか?
オンラインビジネスを持つ企業は、偽のアカウントや盗まれたクレジットカードで行われた決済などの不正活動に絶えず目を光らせておく必要があります。 詐欺師を特定する試みのひとつは不正行為検出アプリの使用で、これらには機械学習 (ML) を使用するものもあります。
そこで登場するのが Amazon Fraud Detector です! これは、データ、ML、および Amazon の 20 年を超える不正検出の専門技術を用いて不正行為の可能性があるオンライン活動を自動的に識別するため、より多くの不正行為をより迅速に見つけることができます。Fraud Detector は ML に関する困難な作業のすべてを処理するため、ML 経験がなくてもほんの数クリックで不正検出モデルを作成することが可能です。
Fraud Detector の仕組み
「どんな仕組みになってるの?」と言われるかもしれません。??♀️
よくぞ聞いてくださいました! では、これを 5 つの主なステップに要約しましょう。???
- ステップ 1: 不正行為について評価したいイベントを定義する。
- ステップ 2: 履歴的なイベントデータセットを Amazon S3 にアップロードして、不正検出モデルタイプを選択する。
- ステップ 3: Amazon Fraud Detector が履歴データを入力として使用し、カスタムモデルを構築する。このサービスは、自動的にデータを調べてリッチ化し、特徴量エンジニアリングを実行して、アルゴリズムの選択、およびモデルのトレーニングと調整を行い、モデルをホストします。
- ステップ 4: モデルの予測に基づいて受け入れる、レビューする、またはより多くの情報を収集するかどうかのルールを作成する。
- ステップ 5: オンラインアプリケーションから Amazon Fraud Detector API を呼び出して、リアルタイムの不正行為予測を受け取り、設定された検出ルールに基づいて措置を講じる。 (例: e コマースアプリケーションは、E メールと IP アドレスを送信し、不正行為スコアとルールからの出力 (例: レビュー) を受け取ることができます)
デモを見てみましょう…
これらがどのように連携するのかをより良く理解できるようにデモを実行しましょう。今日の記事では、Amazon Fraud Detector モデルの構築とリアルタイムの不正行為予測の生成の 2 つの主な要素について詳しく説明します。
パート A: Amazon Fraud Detector モデルの構築
生成された架空のトレーニングデータを S3 バケットにアップロードすることから始めます。現に、ユーザーガイドには使用できるサンプルデータセットがあります。CSV ファイルをダウンロードしたら、このトレーニングデータを S3 バケットに取り込む必要があります。


内容を見るために、CSV ファイルを開いて中身を確認してみましょう…

??注意: Amazon Fraud Detector では、モデルをトレーニングするために、電子メールと IP アドレスだけではなく、最小で 2 つの変数を選択することができます。(実際に、モデルは最大 100 個の入力をサポートします!)
次に、イベントを定義 (作成) します。イベントとは基本的に、特定のイベントに関する属性のセットです。不正行為について評価したいイベントの構造を定義します。(Amazon Fraud Detector は不正行為について「イベント」を評価します。)
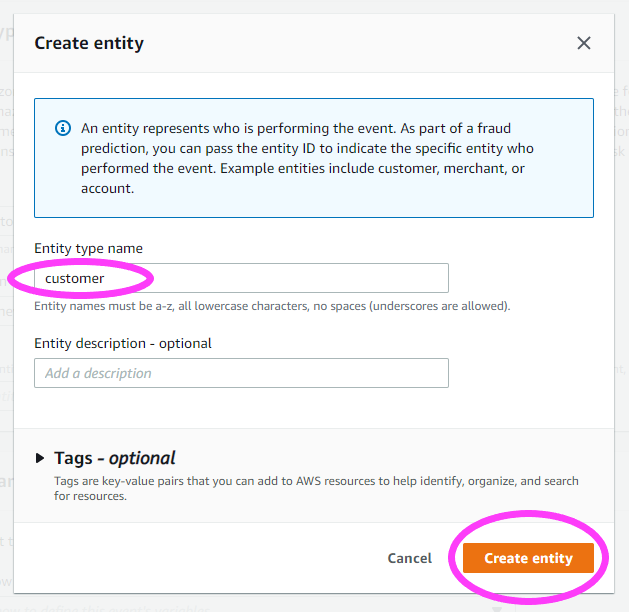
新しいエンティティを作成しましょう。このエンティティは、イベントをトリガーする人物または物を表します。

Event Variables (イベント変数) に移動します。トレーニングデータセットから変数を選択します。これによって、先ほどお話しした CSV ファイルを使用して、ヘッダーをプルすることができるようになります。

IAM role (IAM ロール) セクションでは、新しいロールを作成します。ここでは、先ほど作成したバケットと同じ名前 (fraud-detector-training-data) を使います。

これで、先ほどの CSV ファイルをアップロードして、ヘッダーをプルすることができるようになりました。

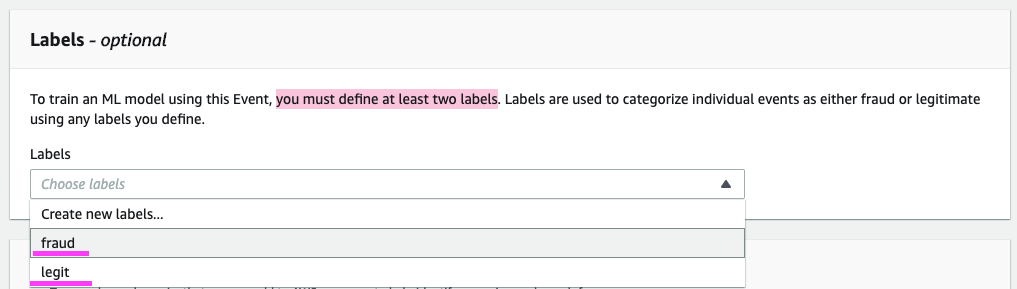
モデルを定義することから、少なくとも 2 つのラベルを定義する必要があります。
イベントの作成を確定しましょう!

すべてが問題なく実行されると、イベントが正常に作成されたことを知らせるハッピーな緑色のバーが表示されます!
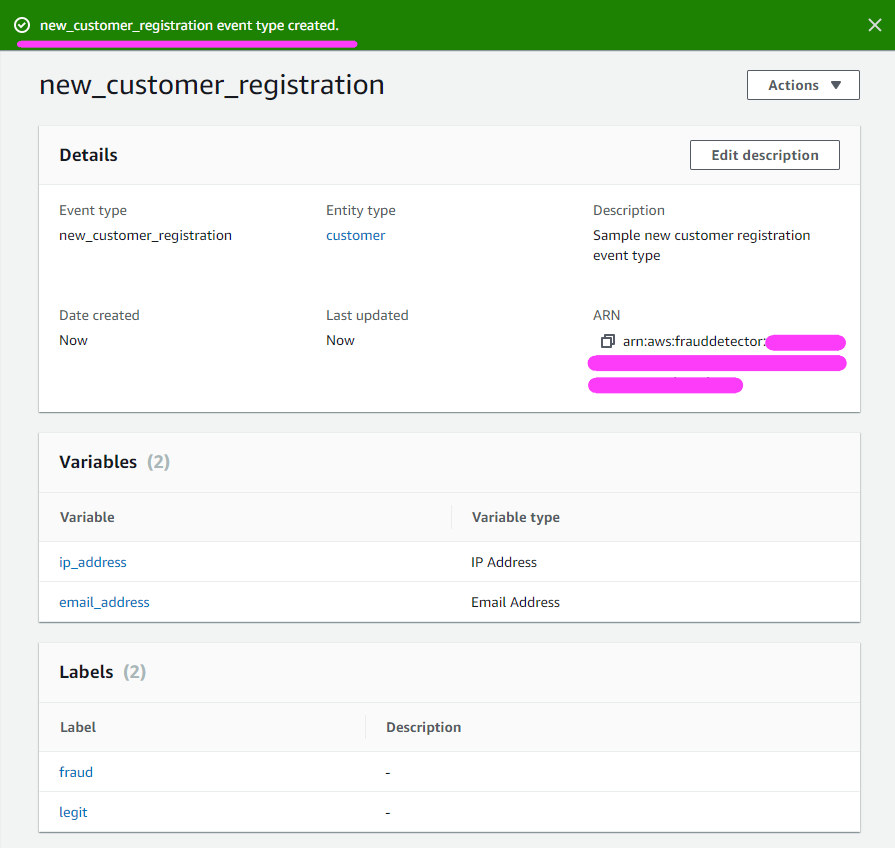
それでは、いよいよモデルを作成します。


少し時間を取って、モデルの詳細を定義しましょう。先ほど作成したイベントタイプを選択するようにします。

Configure training (トレーニングの設定) に進み、Fraud labels (不正行為ラベル) と Legitimate labels (正当ラベル) でラベルを選択するようにします。(こうすることで、モデルがこれら 2 つのラベルを区別することを学習できるように、分類を分離させることができます。)

モデルには、データセットのサイズに応じて 30~40 分から数時間かかる場合があります。この例のデータセットでは、データのトレーニングに約 40 分かかりました。
このブログ記事のため、トレーニングモデルの完成にかかる 40 分がすでに経過したとしましょう。??
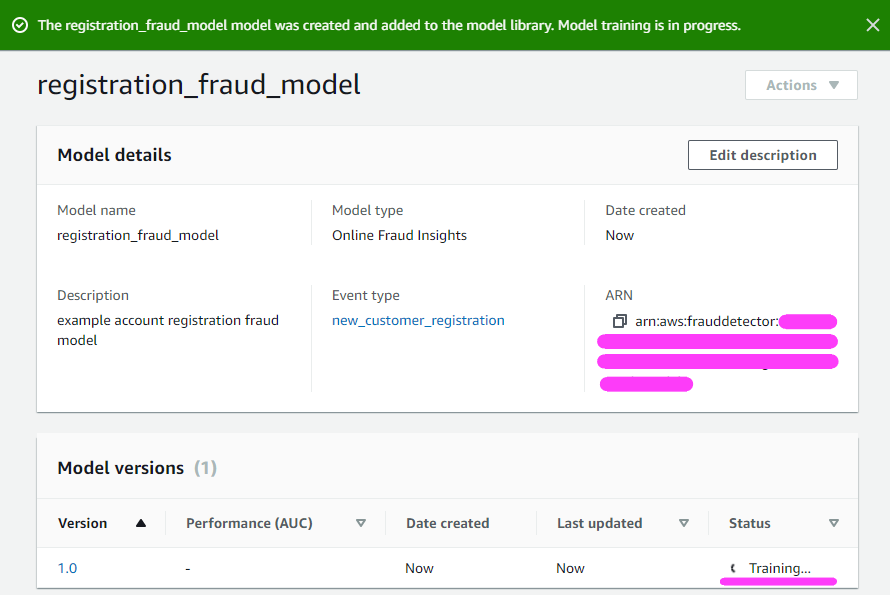
モデルのパフォーマンスメトリクスをチェックすることもできます!

これで、モデルのデプロイメントに進むことができるようになりました。

ポップアップモーダルが表示されて、これがデプロイしたいバージョンかどうかを確認するように求められます。
パート B: リアルタイムの不正行為予測の生成
それでは、リアルタイムの不正行為予測を生成しましょう! 準備はよいですか?
この時点で、納得のいく、予測の取得に使用したいモデルがデプロイされています。
モデルとルールのコンテナである検出器を構築する必要があります。これは、イベントを評価するために適用したい検出ロジックです。
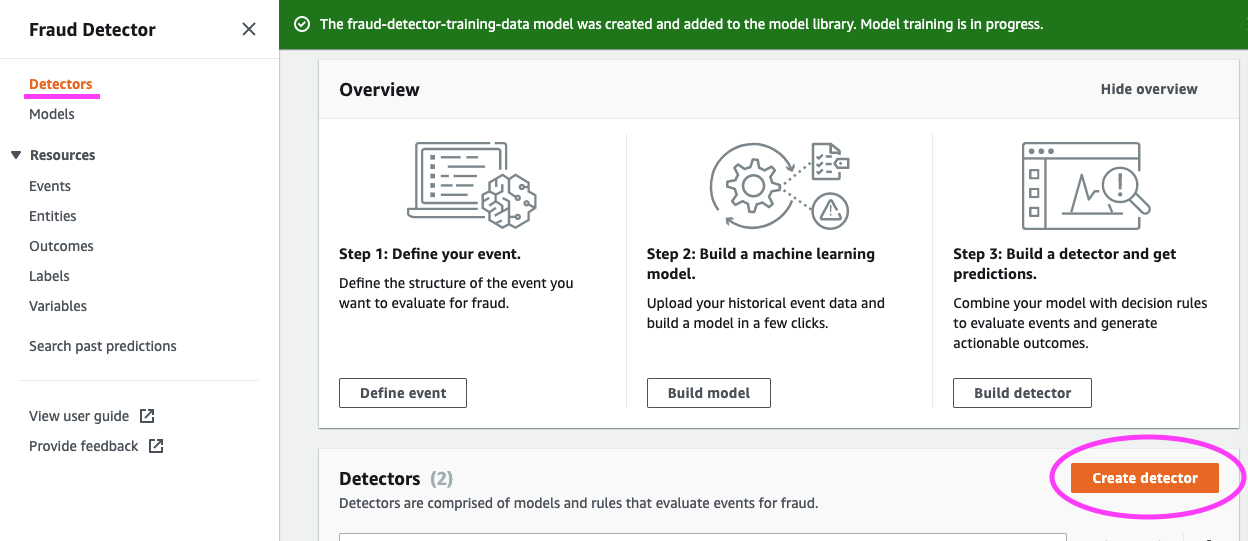
次に、Detector details (検出器の詳細) を定義します。
また、先ほど作成したイベントを選択する必要もあります。
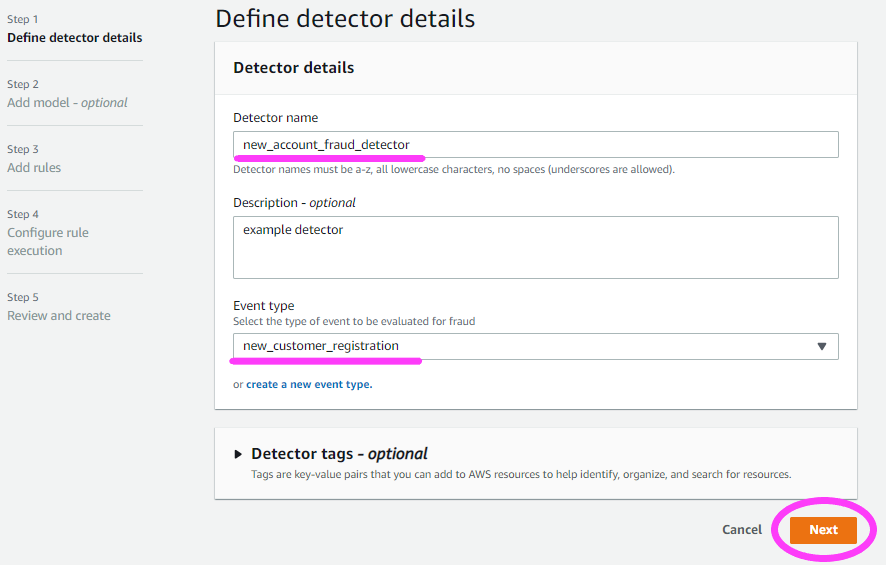
ここでモデルを選択します。
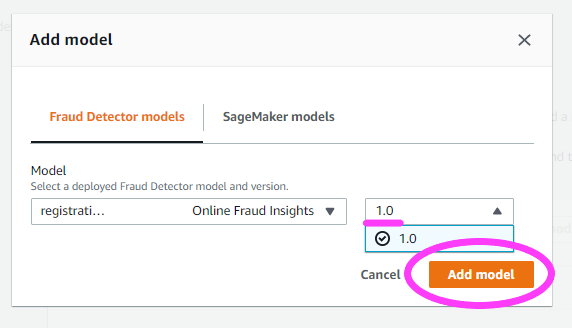
その後、しきい値ルールをいくつか設定します。
ルールは、モデルの出力を解釈します。また、検出器の出力も決定します。
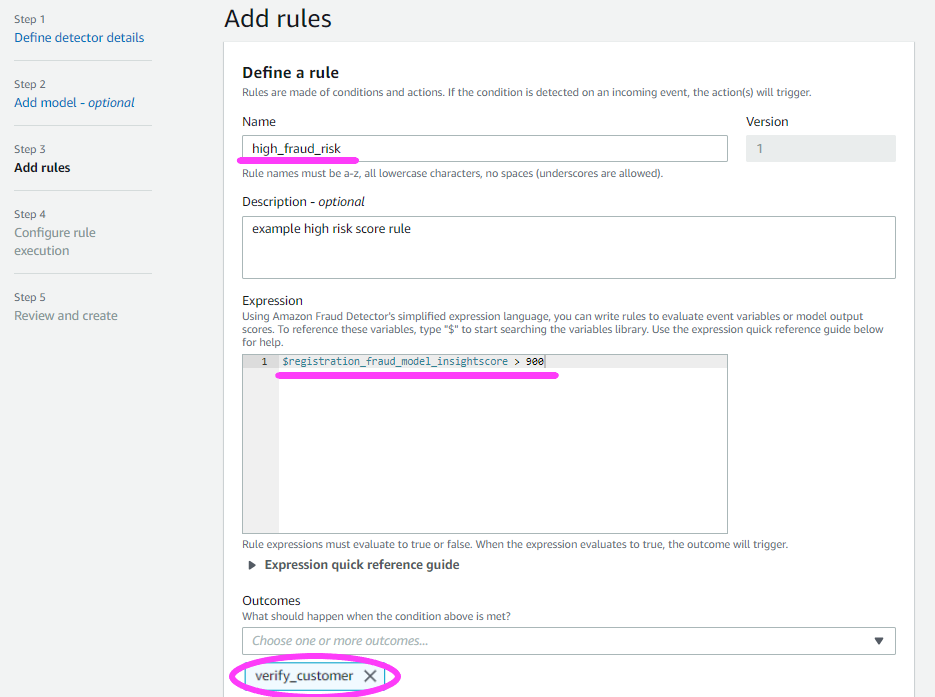
ルールをあと 2 つ設定しましょう。
high_fraud_risk ラベル以外に、low_fraud_risk と medium_fraud_risk ラベルも追加します。

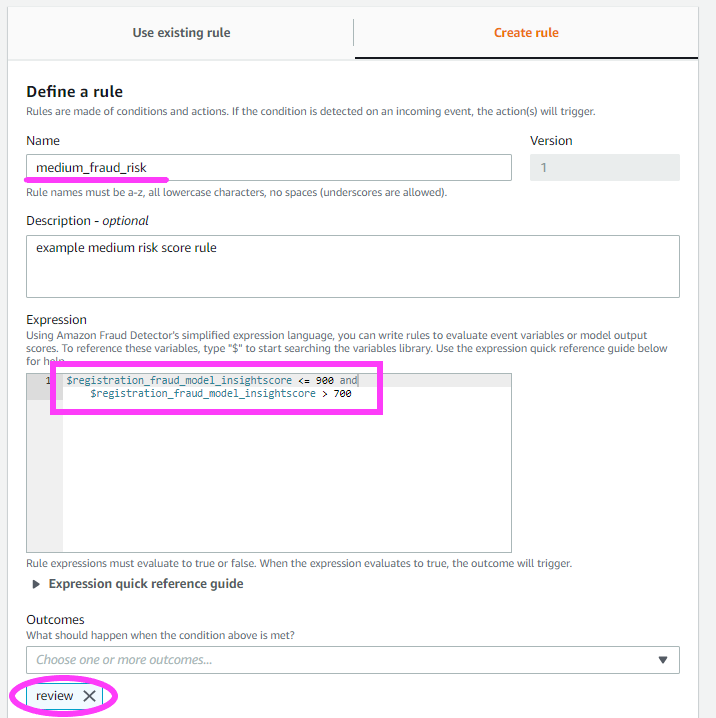
これらのルールのしきい値は単なる例であることに留意してください。独自の検出器のためにルールを作成するときは、モデル、データ、およびビジネスに基づいた適切な値を使用する必要があります。
この記事の例では、これらの特定のしいき値ルールが同時に一致することはありません。

これは、現在の例では Rule Execution modes (ルール実行モード) のどちらでも使用できることを意味します。

完成です! 検出器ができました。

[Rules] (ルール) タブをクリックしてみましょう。
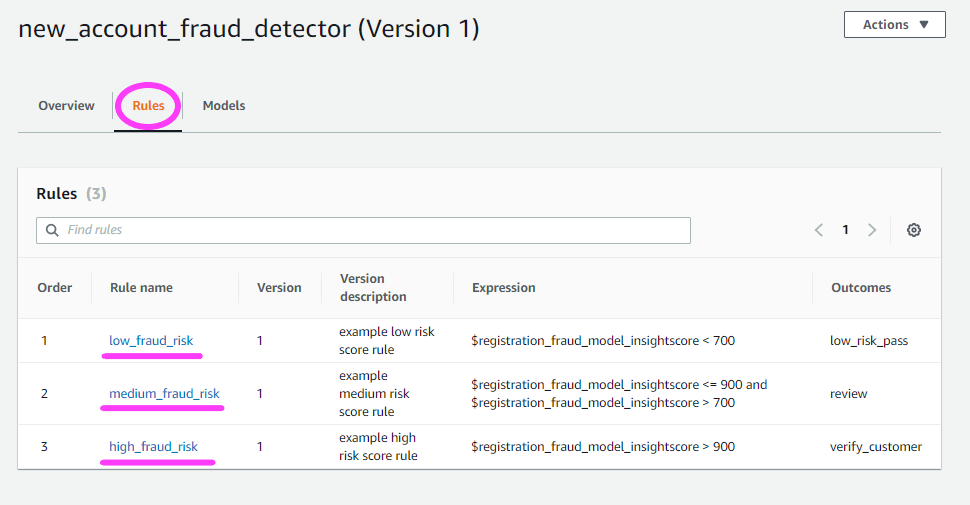
[Models] (モデル) タブで、使用しているモデルを確認することもできます。

[Overview] (概要) タブに戻ると、簡単なテストを実行することもできます! 検出器からの出力をサンプリングするためのテストを実行できます。
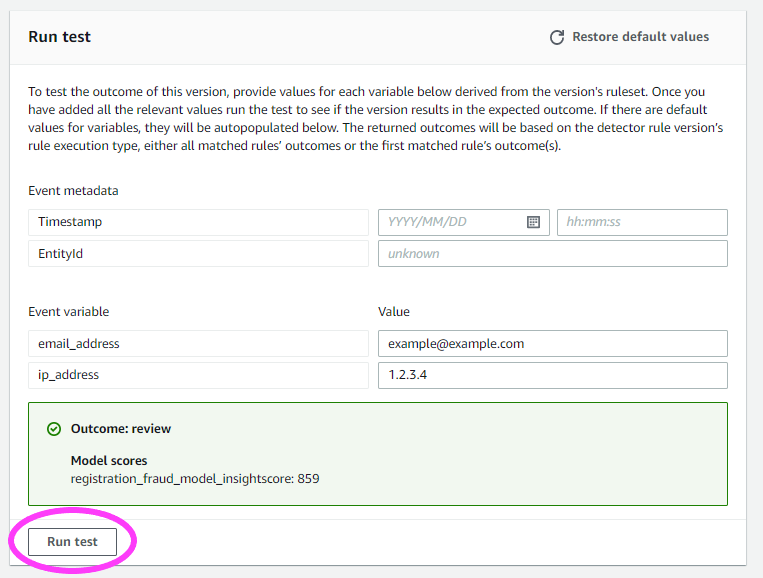
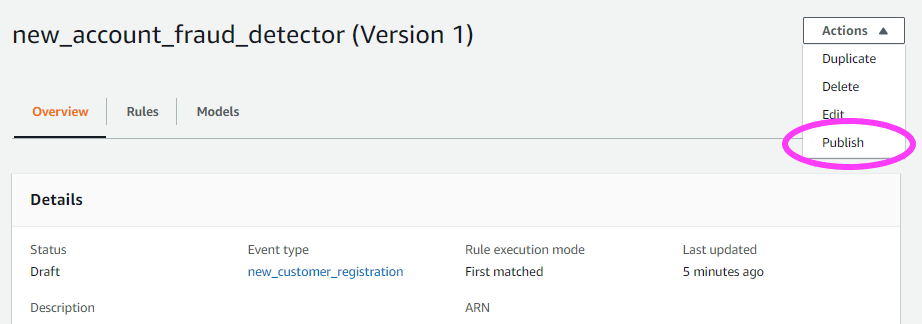
準備できたら、検出器のこのバージョンを [publish] (パブリッシュ) して、これをアクティブバージョンにすることができます。各検出器は、一度に 1 個のアクティブバージョンを持つことができます。
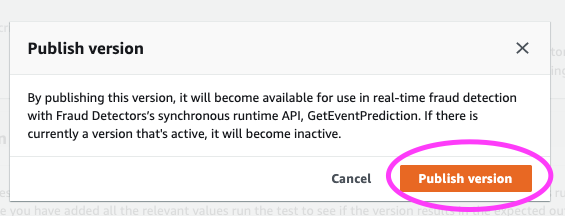
ポップアップモーダルが、このバージョンをパブリッシュする準備ができたかどうかを確認するように求めます。
次のステップは、リアルタイム予測の実行です! Amazon SageMaker ノートブックを使って 1 回限りの予測サンプルを表示して、それがどのようなものかを見てみましょう。
Amazon SageMaker コンソールに移行して、[Notebook instances] (ノートブックインスタンス) に移動します。
この場合、すぐに使用できる Jupyter ノートブックがすでに存在しているのがわかります。
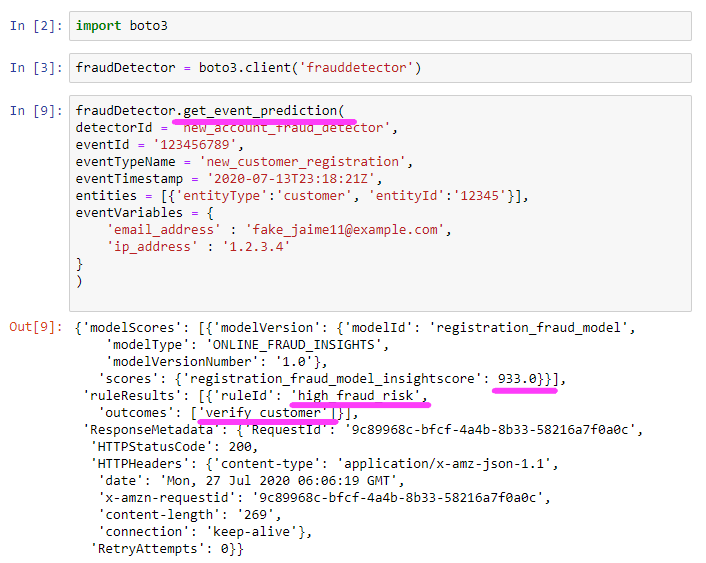
get_event_prediction ブロックを実行します。これは AWS の主要ランタイム API で、お客様はサンプル予測のバッチを実行するためのスクリプトを使用して呼び出すことができます。その代わりに、リアルタイム予測を生成するアプリケーションにこの API を統合して、リスクに基づいてユーザーエクスペリエンスを動的に調整することもできます。
このブロックを実行したら、以下のようなモデルスコア結果を受け取ります。
この検出器にはひとつのモデルがあり、スコア 933 を返しました。作成したルールによると、これは、このトランザクションが high_fraud_risk として戻されると私たちが考えていることを意味します。
Amazon Fraud Detector コンソールに戻り、検出器の [Rules] (ルール) をチェックしましょう。
検出器のルールを見ると、リスクのスコアが 900 を超える場合に結果が verify_customer になるべきであることがわかります。

これですべて完了です!
この検出器をリアルタイムで呼び出して、不正行為予測を取得できることがわかりました。
? 最後に…
Amazon Fraud Detector は世界中の AWS のお客様にご利用いただけるようになりました。Fraud Detector は Amazon CloudWatch、AWS CloudTrail、AWS PrivateLink などの多数の AWS のサービスと統合されています。
Amazon Fraud Detector の詳細については、ウェブサイトとデベロッパーガイドをご覧ください。
¡Gracias por tu tiempo!
~Alejandra ??♀️? y Canela ?