Amazon Web Services ブログ
Amazon Redshift DC2 インスタンスからの移行アプローチ:お客様事例
本記事は 2026 年 3 月 11 日 に公開された「Amazon Redshift DC2 migration approach with a customer case study」を翻訳したものです。
この記事は、AWS パートナーである Classmethod のソリューションアーキテクト、石川 覚氏によるゲスト投稿です。
2025 年 4 月、AWS は Amazon Redshift DC2 インスタンスの廃止を発表し、Redshift RA3 インスタンスまたは Redshift Serverless への移行を推奨しました。Redshift RA3 インスタンスと Serverless はストレージとコンピューティングを分離する設計を採用しており、データ共有、書き込みの同時実行スケーリング、zero-ETL、クラスターリロケーションなどの新機能を提供します。
本記事では、あるお客様が DC2 から RA3 インスタンスへ移行した事例を紹介します。小売業の大手企業であるこのお客様は、BI と ETL ワークロード向けに 16 ノードの dc2.8xlarge クラスターを運用していました。データ量の増加とディスク容量の制約に直面し、Blue-Green デプロイメントアプローチで RA3 インスタンスへの移行に成功。ETL クエリパフォーマンスの向上とストレージ容量の拡大を、コスト効率を維持しながら実現しました。
Amazon Redshift のアーキテクチャタイプ
Amazon Redshift には 2 つのデプロイオプションがあります。Provisioned モードではインスタンスタイプとノード数を選択し、必要に応じてリサイズを管理します。Redshift Serverless はデータウェアハウスのキャパシティを自動的にプロビジョニングし、基盤リソースをインテリジェントにスケーリングします。次の図は、これら 2 つのアーキテクチャタイプを比較したものです。
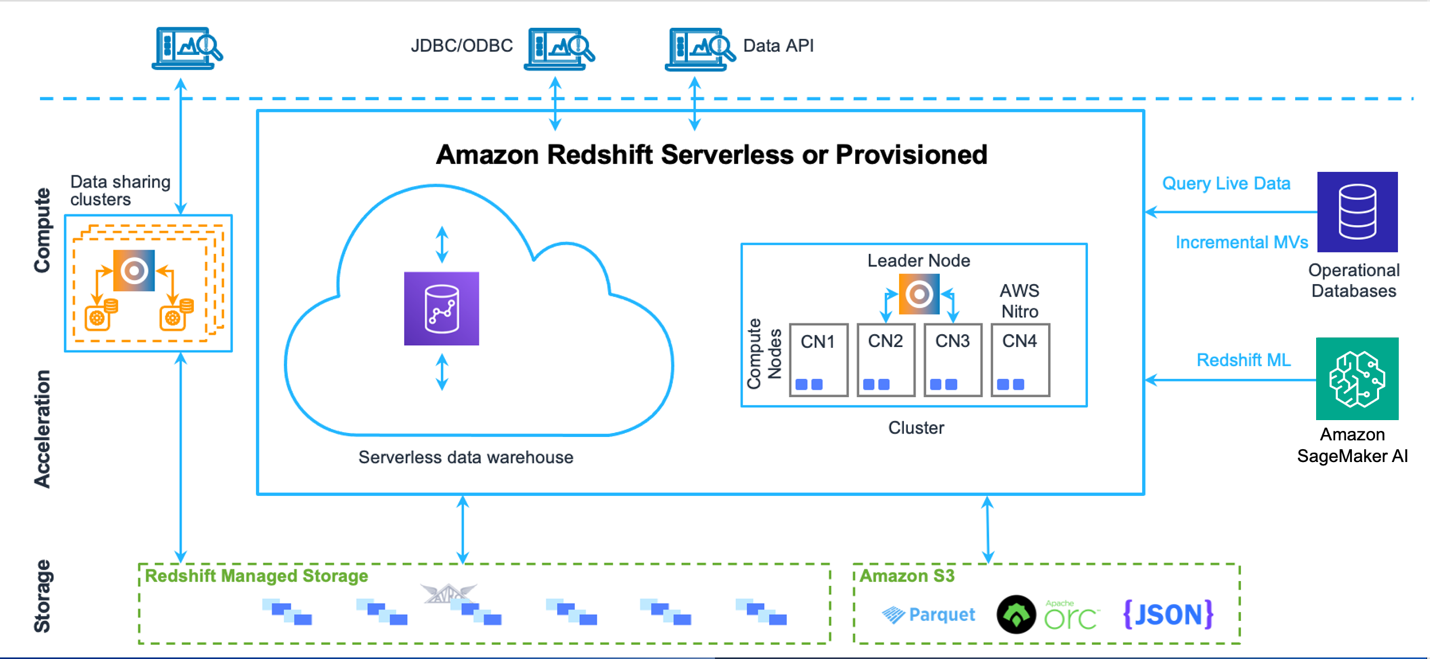
Provisioned クラスターはクラスターサイズを事前に決定する必要がありますが、リザーブドインスタンス (RI) の購入や一時停止・再開のスケジューリングでコストを最適化できます。Serverless は必要に応じてリソースを自動プロビジョニングし、消費したコンピューティングリソースに対してのみ課金される従量課金モデルです。両サービスとも相互移行をサポートし、SQL、zero-ETL、Federated Query などの同じ機能を提供します。料金の詳細は Amazon Redshift の料金をご覧ください。
Provisioned クラスターは大規模で予測可能なワークロードに適しており、キューイングに基づく自動スケーリングを提供します。Serverless は変動するワークロードに対して管理不要の自動スケーリングを提供し、ワークロードの複雑さとデータ量に基づいてスケーリングする AI 駆動の最適化を備えています。詳細は Amazon Redshift Serverless とプロビジョニング済みデータウェアハウスの比較をご覧ください。
お客様事例:DC2 インスタンスからの移行
このセクションでは、お客様の Amazon Redshift DC2 から RA3 インスタンスタイプへの移行について説明します。Blue-Green デプロイメントアプローチを採用し、ダウンタイムを最小限に抑えながらコスト最適化とパフォーマンス向上の両方を達成しました。
お客様のワークロードには以下の特徴がありました。
ユースケース
お客様の Amazon Redshift の主なユースケースは以下のとおりです。
- 営業時間中の BI ツールによるクエリ
- 大量の読み取りクエリ
- 月曜日と月初にアクセスがピークに達する
- 早朝のデータ処理
- データロードと変換のための書き込みクエリが集中
- 定常的なワークロード特性
- 1 日 16 時間以上クエリを実行
要件
お客様の Amazon Redshift 移行における主な要件は以下のとおりです。
- パフォーマンス
- ピークアクセス時に自動スケーリング (同時実行スケーリングなど) を使用
- データサイズ
- ディスク容量の拡張が必要
- コスト管理
- 予算の予測と管理が容易であること
- 長期利用向けの割引サービスを活用
- 互換性
- 既存のアプリケーションと BI ツールとの互換性を維持
- エンドポイントの変更を回避
- 可用性
- 移行中の最大ダウンタイムは 8 時間まで許容
- ネットワーク
- 既存の 2 アベイラビリティーゾーン (AZ) サブネット構成を変更しない
- 移行タイミング
- 負荷の低い日時に実施
- 8 時間以内の計画ダウンタイムが可能
システム設計、実装、運用における主な検討事項は、長時間の運用、予算の予測と管理の容易さ、リザーブドインスタンス (RI) によるコスト最適化、既存システムとの互換性維持 (エンドポイント変更の回避) でした。お客様は Amazon Redshift Serverless も評価しました。従量課金モデル、自動スケーリング機能、変動するワークロードに対するより良い価格性能比など、魅力的な機能を備えていました。Redshift Serverless と Provisioned クラスターのどちらもワークロードパターンを効果的にサポートできましたが、お客様は Provisioned 環境での長年の運用経験、既存の RI 戦略、確立されたキャパシティプランニングアプローチを活かし、RA3 ノードの Provisioned モデルを選択しました。
RA3 インスタンスタイプの特徴
AWS Nitro System 上に構築された RA3 インスタンスは、マネージドストレージを備え、コンピューティングとストレージを分離するアーキテクチャを採用しています。各コンポーネントを独立してスケーリングでき、課金も個別に行われます。ホットデータには高性能 SSD、コールドデータには Amazon S3 を使用し、使いやすさ、コスト効率の高いストレージ、高速なクエリパフォーマンスを実現します。詳細は Amazon Redshift RA3 instances with managed storage をご覧ください。
移行の前提条件
お客様の移行の前提条件は以下のとおりです。
- 16 ノードの dc2.8xlarge 構成の Redshift クラスターを使用していました。
- 移行には Blue-Green デプロイメントアプローチを採用し、スナップショットから RA3 インスタンスタイプにリストアすることで、必要に応じて迅速にロールバックできるようにしました。
- クラスター識別子のローテーションによるエンドポイント切り替えで、クラスターの切り替えとロールバックを実装しました。
- さらに、高い同時実行性でのパフォーマンス向上のため、トランザクション分離レベルを SERIALIZABLE ISOLATION から SNAPSHOT ISOLATION に移行しました。
クラスター移行方法
移行には Elastic Resize と Classic Resize の 2 つのオプションがありました。
Amazon Redshift の Classic Resize 機能が強化され、RA3 インスタンスタイプへのリサイズにおいて書き込み不可期間が大幅に短縮されました。PoC テストの結果、リサイズ開始後、クラスターのステータスが modifying になってから利用可能になるまで 16 分でした。この結果を踏まえ、お客様は Classic Resize アプローチで進めました。
クラスターサイジング
サイジングでは、移行先のインスタンスタイプとノード数を決定しました。CPU 集約型 (高 CPU 使用率のクエリ)、I/O 集約型 (データ読み書きが多いクエリ)、またはその両方といったワークロード特性を考慮しました。DC2 インスタンスタイプからの移行では、ワークロード要件に応じて追加ノードが必要になる場合があります。必要なクエリパフォーマンスに応じたコンピューティング要件に基づいてノードを増減しました。
インスタンスサイズとノード数でクラスターコストが同等の構成を比較すると、dc2.8xlarge 16 ノードクラスターの推奨構成は ra3.16xlarge 8 ノードでした。東京リージョンでのコスト比較は以下のとおりです。
- 推奨構成:dc2.8xlarge 16 ノードクラスター => ra3.16xlarge 8 ノードクラスター
- $97.52/h (6.095/h * 16 ノード) => $122.776/h (15.347/h * 8 ノード)
- コスト重視:dc2.8xlarge 16 ノードクラスター => ra3.16xlarge 6 ノードクラスター
- $97.52/h (6.095/h * 16 ノード) => $92.082/h (15.347/h * 6 ノード)
今回の移行では、既存の予算制約内に収めるため、コスト効率の高い 6 ノードの ra3.16xlarge クラスターで進めました。ただし、このノード数では特定の時間帯にスループットの制約が生じる可能性があるため、RA3 インスタンスタイプの同時実行スケーリングを有効にしてスパイクアクセスに対応しました。
同時実行スケーリングは、アクティブなクラスターごとに 1 日最大 1 時間の無料クレジットを提供し、最大 30 時間まで蓄積できます。この無料枠を超えるとオンデマンド料金が適用されます。お客様は同時実行スケーリングの導入を選択しましたが、ピーク負荷時に一時的にノードを増やす Elastic Resize も検討されました。しかし、追加ノードのオンデマンドコストと切り替え時の短時間の切断が発生するため、採用を見送りました。
マネージドストレージのコスト
RA3 インスタンスは Redshift Managed Storage (RMS) を使用し、固定の GB 月額料金で課金されます。お客様の約 2 TB のデータについて、ストレージコストを見積もりに含める必要がありました。料金の詳細は Amazon Redshift の料金をご覧ください。
DC2 から RA3 への移行手順
DC2 クラスターのスナップショットから RA3 クラスターを作成した後、クラスター識別子を入れ替えました。次の図はこのプロセスを示しています。
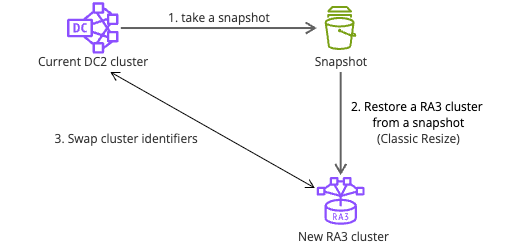
- 現在の DC2 クラスターのスナップショットを取得します。
- 異なるクラスター識別子でスナップショットから RA3 クラスターをリストアします (Classic Resize)。
- 現在の DC2 クラスターと新しい RA3 クラスターのクラスター識別子を入れ替えます。
クラスター切り替え後に問題が発生した場合、元の DC2 クラスターのクラスター識別子を元に戻すことで迅速にロールバックできます。
注:スナップショットからのリストア
操作ミスを最小限に抑え、再現性を確保するため、CLI コマンドでリストア操作を実行することを推奨します。以下はサンプルコマンドです。
本番移行の所要時間
リストアと Classic Resize の所要時間は、データ量とターゲットクラスターの仕様によって大きく異なります。お客様は事前にリハーサルを実施し、実際の所要時間を計測しました。
テスト結果
本番移行の前に、お客様はスナップショットを RA3 インスタンスタイプにリストアしてテストクラスターを作成しました。通常、ワークロードテストには Redshift Test Drive が有用ですが、このお客様には固有の制約がありました。本番クラスターで監査ログを有効にするには、設定変更、クラスター再起動、厳格な変更管理ポリシーに基づく複雑な承認プロセスが必要でした。この課題に対応するため、Amazon Redshift のシステムビュー (SYS_QUERY_HISTORY と SYS_QUERY_TEXT) を使用してワークロードパターンをキャプチャする独自の負荷テストツールを開発しました。これらのシステムビューは 7 日間のクエリ履歴を保持しています。このツールで 55,755 件の過去のクエリを 50 並列で DC2 と RA3 の両クラスターに対してリプレイし、クエリ実行時間、CPU 使用率、ディスク I/O などのメトリクスを比較しました。正確な比較のため、テスト中はクエリ結果のキャッシュを無効にしました。
BI クエリパフォーマンス
BI クエリは前述の独自の負荷テストツールでテストしました。結果は、55,755 件のクエリを 50 並列で実行した 15 回のテストの平均実行時間です。同時実行スケーリングなしの場合、dc2.8xlarge 16 ノードクラスターの平均はクエリあたり 45.82 秒、ra3.16xlarge 6 ノードクラスターの平均は 91.30 秒でした。最適化なしの直接移行では、RA3 インスタンスは短・中程度のクエリで実行時間が長くなることが分かりました。しかし、同時実行スケーリングを有効にすると RA3 クラスターのパフォーマンスは段階的に改善しました。同時実行スケーリングを最大 2 クラスターで有効にした場合、ra3.16xlarge 6 ノードクラスターの平均はクエリあたり 72.48 秒となり、スケーリングなしの構成から 21% 改善しました。
| ノードタイプ / ノード数 | 平均クエリ時間 |
| ra3.16xlarge 6 ノードクラスター | 72.48 秒 |
ETL クエリパフォーマンスの比較
長時間実行される ETL クエリ (実行時間 10 分以上) では、RA3 クラスターは DC2 クラスターよりも優れたパフォーマンスを示しました。これらの結果は、最適化を適用していないお客様のワークロードの直接移行によるものです。
- 大規模データロードワークロード 1 では、ra3.16xlarge クラスターは dc2.8xlarge クラスターより 28% 高速にクエリを完了しました (41 分 vs. 57 分)。
- 複雑な変換ワークロード 1 では、ra3.16xlarge クラスターは 23% 高速でした (1 時間 1 分 vs. 1 時間 20 分)。
これらの結果から、RA3 ノードタイプは時間のかかるデータロードや変換タスクでより高いパフォーマンスを発揮することが分かりました。RA3 クラスターの CPU 使用率が高い値を示したことは、コンピューティングリソースをより効果的に活用していることを示唆しています。
| ノードタイプ / ノード数 | 平均クエリ時間 | MAXCPU% |
| ra3.16xlarge 6 ノードクラスター | 41 分 09 秒 | 11.45 |
| dc2.8xlarge 16 ノードクラスター | 57 分 07 秒 | 10.85 |
| ノードタイプ / ノード数 | 平均クエリ時間 | MAXCPU% |
| ra3.16xlarge 6 ノードクラスター | 1 時間 01 分 33 秒 | 74.23 |
| dc2.8xlarge 16 ノードクラスター | 1 時間 20 分 36 秒 | 53.58 |
パフォーマンスチューニング
テスト結果から、RA3 は短・中程度の BI クエリでは DC2 より実行時間が長くなる一方、長時間実行される ETL クエリでは高速であることが分かりました。全体的なパフォーマンスを最適化するため、遅いクエリと頻繁に参照されるテーブルを特定し、影響の大きい最適化を優先しました。
パフォーマンスチューニング戦略
お客様は RA3 のアーキテクチャ上の利点を活かすため、いくつかの最適化戦略を検討しました。主要な戦略の 1 つは、アドホックな短・中程度のクエリワークロードを低負荷時間帯に事前処理し、結合、集約、フィルタリング、射影を繰り返し実行するクエリ向けに事前処理テーブルやマテリアライズドビューを作成することでした。RA3 のコンピューティングとストレージを分離したアーキテクチャと、コスト効率の高い大容量ストレージがこのアプローチを支えました。
通常のビューからマテリアライズドビューへの変換
遅いクエリを分析したところ、ビュー内で結合が使用されており、頻繁に参照されるテーブルがこれらのビューを通じて複数回アクセスされていることが判明しました。対策として、頻繁に使用される通常のビューをマテリアライズドビューに置き換え、不要なデータ範囲と冗長なカラムを削除しました。
Amazon Redshift は REFRESH MATERIALIZED VIEW コマンドによるマテリアライズドビューの増分更新をサポートしており、効率的なデータ更新が可能です。
マテリアライズドビューとクエリリライト
通常のビューをマテリアライズドビューに変換すると、クエリプランナーが提供する「クエリリライト」機能により、既存のクエリが自動的に最適化される場合があります。詳細はマテリアライズドビューを使用した自動クエリリライトをご覧ください。
AutoMV による自動チューニング
DC2 クラスターではディスク使用率が常に 80% を超えており、ディスク容量不足のため AutoMV 機能が無効になっていました。RA3 のストレージ拡張により、AutoMV による自動チューニングが可能になり、さらなるパフォーマンス改善につながりました。AutoMV の詳細は マテリアライズドビューを使用するための自動クエリ書き換え をご覧ください。
パフォーマンスチューニングの結果
これらの最適化を適用した結果、お客様は以下を達成しました。
- コスト増加を抑えながら既存のパフォーマンスを維持
- スループットを維持しながら CPU 使用率を向上
- 同時実行スケーリングの自動スケーリングにより、ピーク負荷時の動的なスループットを強化
まとめ
本記事では、小売業の大手企業が Amazon Redshift DC2 インスタンスから RA3 インスタンスへ移行した事例を紹介しました。Blue-Green デプロイメントアプローチにより、迅速なロールバック機能を備えた安全な移行を実現しました。RA3 のコンピューティングとストレージを分離したアーキテクチャは、増加するデータ量に対応する柔軟性を提供しました。RA3 インスタンスは短い BI クエリで DC2 インスタンスと異なるパフォーマンス特性を示しましたが、長時間実行される ETL クエリでは大幅な改善を達成しました (データロードで最大 28% 高速化、複雑な変換で 23% 高速化)。マテリアライズドビューや AutoMV などの RA3 インスタンス固有の機能を活用し、リザーブドインスタンスと同時実行スケーリングによるコスト効率を維持しながら、全体的なクエリパフォーマンスを最適化しました。
RA3 インスタンスへの移行の詳細については、Best practices for upgrading from Amazon Redshift DC2 to RA3 and Amazon Redshift Serverless と Resize Amazon Redshift from DC2 to RA3 with minimal or no downtime をご覧ください。
著者について
この記事は Kiro が翻訳を担当し、Solutions Architect の Junpei Ozono がレビューしました。