インターネットやスマホ、SNS の広がりによりテキストデータなどの非構造化データの分析のニーズが急増しています。企業内の大量の文書、メール、SNS のテキスト、コンタクトセンターのログ等、テキスト情報には多くの知見が埋もれており、これらを活用することで、より正確な意思決定が行えると考えられます。このような分析を目的としたテキストマイニングのツールは数多く存在しますが、高価であったり、処理の拡張性に課題があるものも少なくありません。この記事では AWS のクラウドサービスを活用し、簡単、迅速に構築可能な自然言語処理ダッシュボードを紹介します。オープンソースの形態素解析ツールである GiNZA を Amazon SageMaker ノートブックに導入し、大量のテキストからワード、係り受けを抽出し、抽出した結果を Amazon QuickSight に取り込み、分析可能なダッシュボードを作成します。
アーキテクチャ
ソリューションのアーキテクチャは下図のようになります。テキストを含む CSV ファイルを Amazon SageMaker の ノートブックで処理します。ワード、係り受けの抽出はノートブックインスタンス上でも可能ですが、テキストの量が多い場合は、SageMaker Processing Job で並列に処理することで、短時間に実施することも可能です。Amazon QuickSight のダッシュボードの作成にはあらかじめテンプレートを用意しているため、1から分析画面を作成することなく、迅速に分析を開始することができます。
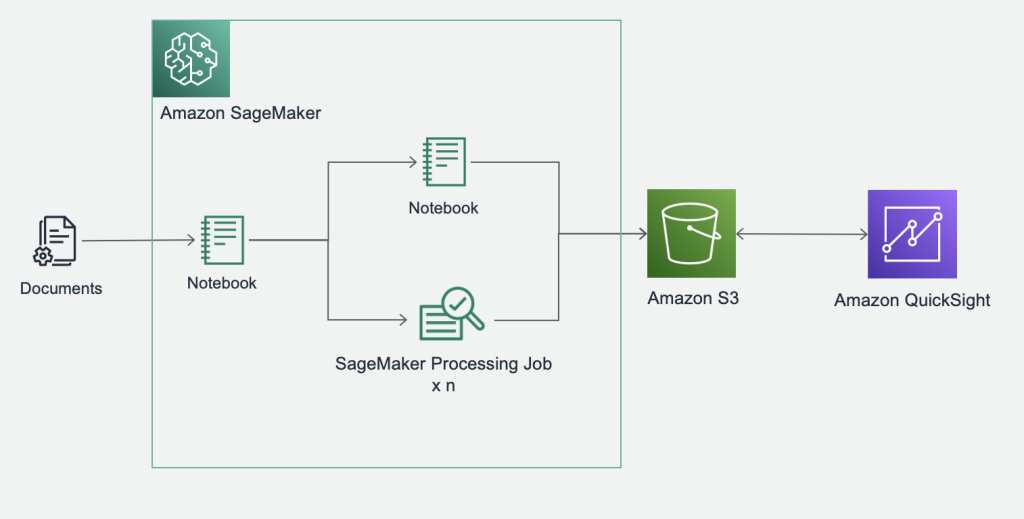
以降では、自然言語処理ダッシュボードの作成の手順を紹介します。
ノートブックインスタンスの作成
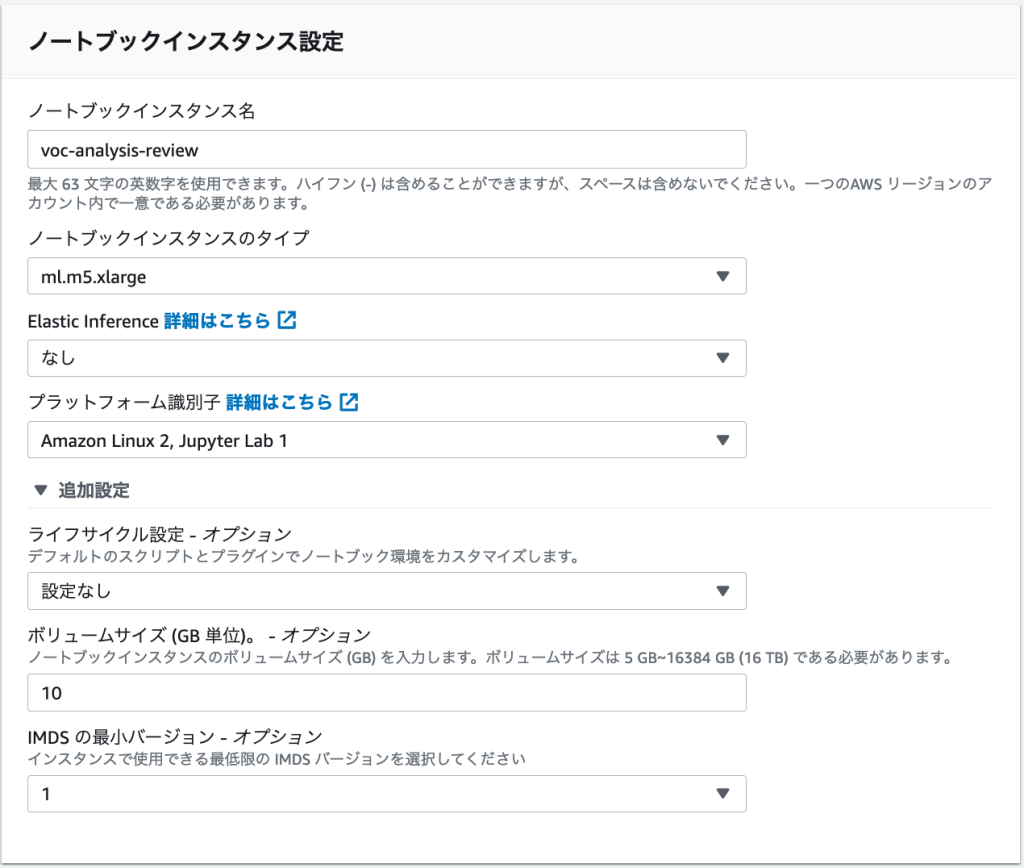
ノートブックインスタンスのタイプは ml.m5.xlarge、ボリュームサイズは10(GB) を指定します。
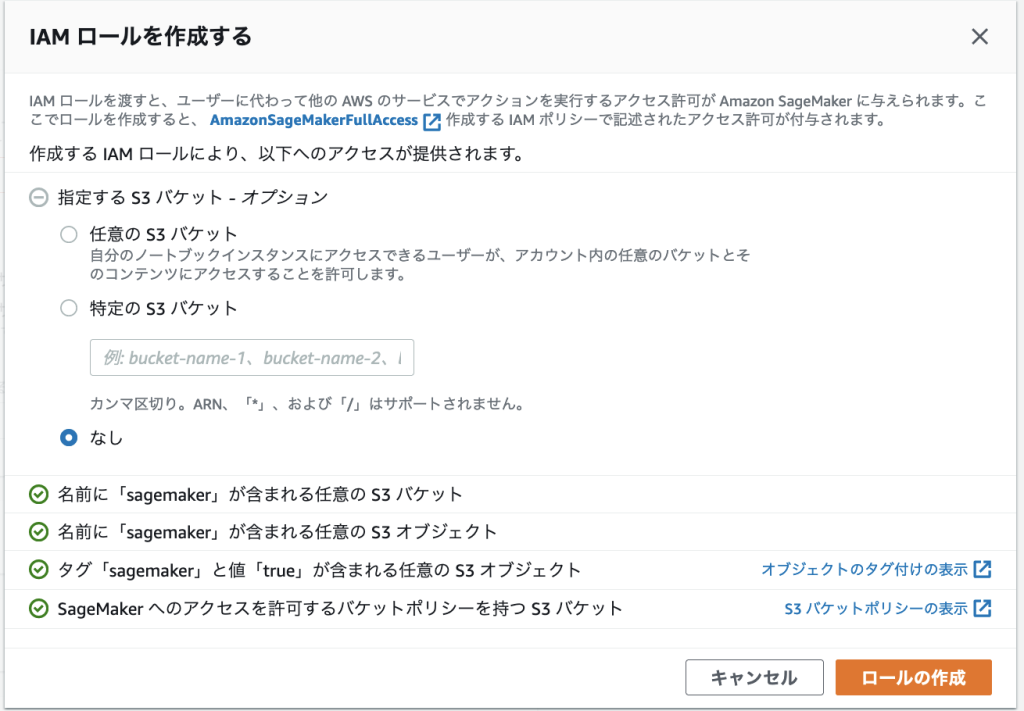
IAM ロールは「新しいロールの作成」と選択し、以下のようにロールを作成します。
注:今回の設定ではノートブックインスタンスはデフォルトの「非 VPC」となりインターネットアクセスが提供される環境となります。本番環境で使用する場合は VPC の使用をご検討ください。
ノートブックの実行
作成したノートブックインスタンスでこちらのノートブックを開きます。ノートブックの記載に従って、順番にセルを実行していきます。
「1. データの取得」ではアマゾンのレビューデータをサンプルとしてダッシュボードを作成します。データは Amazon Customer Reviews Dataset の index file に記載の日本語データセットをダウンロードします。データを Pandas のデータフレームとして取得すると以下のような形式となっており、review_body フィールドのテキストを自然言語処理の対象とします。
marketplace customer_id product_id product_parent product_title product_category star_rating helpful_votes total_votes vine verified_purchase review_headline review_body review_date
0 JP 65317 R33RSUD4ZTRKT7 B000001GBJ 957145596 SONGS FROM A SECRET GARDE Music 1 1 15 N Y 残念ながら… 残念ながら…趣味ではありませんでした。ケルト音楽の範疇にも幅があるのですね… 2012-12-05
1 JP 65317 R2U1VB8GPZBBEH B000YPWBQ2 904244932 鏡の中の鏡‾ペルト作品集(SACD)(Arvo Part:Spiegel im Spiegel) Music 1 4 20 N Y 残念ながら… 残念ながら…趣味ではありませんでした。正直退屈…眠気も起きない… 2012-12-05
2 JP 65696 R1IBRCJPPGWVJW B0002E5O9G 108978277 Les Miserables 10th Anniversary Concert Music 5 2 3 N Y ドリームキャスト 素晴らしいパフォーマンス。ミュージカル映画版の物足りない歌唱とは違います。 2013-03-02
「2. 初期設定項目」ではデータを必要な形式に変換します。本サンプルでは1つのテキストフィールドと、タイムスタンプフィールド、5つの定型フィールドのデータを前提としており、同様の形式であればデータを入れ替えて、ノートブックを実行するだけでダッシュボードを作成可能です。ここではテキストフィールドの列名を txt、日付フィールドの列名を ts、定型フィールドの列名を col0〜4 に変換します。
id ts txt col0 col1 col2 col3 col4
0 0 2012-12-05 残念ながら…趣味ではありませんでした。ケルト音楽の範疇にも幅があるのですね… B000001GBJ 957145596 SONGS FROM A SECRET GARDE Music 1
1 1 2012-12-05 残念ながら…趣味ではありませんでした。正直退屈…眠気も起きない… B000YPWBQ2 904244932 鏡の中の鏡‾ペルト作品集(SACD)(Arvo Part:Spiegel im Spiegel) Music 1
2 2 2013-03-02 素晴らしいパフォーマンス。ミュージカル映画版の物足りない歌唱とは違います。 B0002E5O9G 108978277 Les Miserables 10th Anniversary Concert Music 5
「3. ワード、係り受けの抽出」ではGiNZAを使用して、テキストフィールドからワード、係り受けを抽出します。処理は「3.1. Notebook インスタンスで実行」か、「3.2. SageMaker Processing で実行」のどちらかを使用することができます。データの件数が多い場合は後者を使用することで、並列で高速に処理を完了することができます。
「3.1. Notebook インスタンスで実行」の以下のセルではノートブックインスタンスで GiNZA による処理を実行し、品詞が名詞、動詞、形容詞、副詞のワードと、副詞修飾子、形容詞修飾子、名詞修飾子、主語名詞となる係り受けを抽出しています。データ数を 20,000件 とした場合、14分弱で処理が完了しました。
%%time
pos_id = []
pos_token_no = []
pos_word = []
pos_pos = []
dep_id = []
dep_token_no_1 = []
dep_token_no_2 = []
dep_words_pair = []
dep_dep = []
deptypes = {'advmod':'副詞修飾子', 'amod':'形容詞修飾子', 'nmod': '名詞修飾子', 'nsubj':'主語名詞'}
for index, row in df2.iterrows():
doc = nlp(row['txt'])
id = row['id']
for sent in doc.sents:
for token in sent:
lemma = token.lemma_
pos = token.tag_.split('-')[0]
dep = token.dep_
if pos in ('名詞','動詞','形容詞','副詞'):
pos_id += [id]
pos_token_no += [token.i]
pos_word += [lemma]
pos_pos += [pos]
if dep in deptypes.keys():
dep_id += [id]
dep_token_no_1 += [token.i]
dep_token_no_2 += [token.head.i]
dep_words_pair += [token.lemma_+' - '+token.head.lemma_]
dep_dep += [dep]
df_pos = pd.DataFrame(
data = {'id':pos_id, 'token_no':pos_token_no, 'word':pos_word, 'pos':pos_pos},
columns= ['id','token_no', 'word', 'pos']
)
df_dep = pd.DataFrame(
data = {'id':dep_id, 'token_no_1':dep_token_no_1, 'token_no_2':dep_token_no_2, 'words_pair':dep_words_pair, 'dep':dep_dep},
columns= ['id', 'token_no_1', 'token_no_2', 'words_pair', 'dep']
)
CPU times: user 13min 33s, sys: 3.57 s, total: 13min 37s
Wall time: 13min 37s
続くセルでは抽出したワード、係り受けと元のデータを結合しています。
df_dep2 = pd.melt(df_dep, id_vars=['id', 'words_pair','dep'], value_vars=['token_no_1','token_no_2'], value_name='token_no' )
df_pos_dep = pd.merge(df_pos, df_dep2, how='left', on=['id','token_no'])
df3 = pd.merge(df2, df_pos_dep, how='right', on=['id'])
df3.head()
SageMaker Processing を使用する場合は、「3.2. SageMaker Processing で実行」を使用します。こちらは 260,000 件のデータを 40,000 件毎のジョブに分割し、7並列で実行した場合、60 分程度で完了しました。
ProcessingJobName ProcessingJobArn CreationTime ProcessingEndTime LastModifiedTime ProcessingJobStatus
0 job20221114100718-2022-11-14-10-07-59-410 arn:aws:sagemaker:ap-northeast-1:770096638482:... 2022-11-14 10:08:00.516000+00:00 2022-11-14 10:40:21.927000+00:00 2022-11-14 10:40:22.592000+00:00 Completed
1 job20221114100718-2022-11-14-10-07-58-596 arn:aws:sagemaker:ap-northeast-1:770096638482:... 2022-11-14 10:07:59.287000+00:00 2022-11-14 11:06:05.243000+00:00 2022-11-14 11:06:05.682000+00:00 Completed
2 job20221114100718-2022-11-14-10-07-57-405 arn:aws:sagemaker:ap-northeast-1:770096638482:... 2022-11-14 10:07:58.432000+00:00 2022-11-14 11:02:03.486000+00:00 2022-11-14 11:02:03.951000+00:00 Completed
3 job20221114100718-2022-11-14-10-07-55-996 arn:aws:sagemaker:ap-northeast-1:770096638482:... 2022-11-14 10:07:57.246000+00:00 2022-11-14 10:57:53.783000+00:00 2022-11-14 10:57:54.185000+00:00 Completed
4 job20221114100718-2022-11-14-10-07-54-689 arn:aws:sagemaker:ap-northeast-1:770096638482:... 2022-11-14 10:07:55.879000+00:00 2022-11-14 11:00:50.446000+00:00 2022-11-14 11:00:50.917000+00:00 Completed
5 job20221114100718-2022-11-14-10-07-53-239 arn:aws:sagemaker:ap-northeast-1:770096638482:... 2022-11-14 10:07:54.493000+00:00 2022-11-14 10:49:02.515000+00:00 2022-11-14 10:49:02.945000+00:00 Completed
6 job20221114100718-2022-11-14-10-07-52-103 arn:aws:sagemaker:ap-northeast-1:770096638482:... 2022-11-14 10:07:53.048000+00:00 2022-11-14 10:45:22.064000+00:00 2022-11-14 10:45:22.479000+00:00 Completed
QuickSightデータセットの作成
Amazon QuickSight のサインアップ
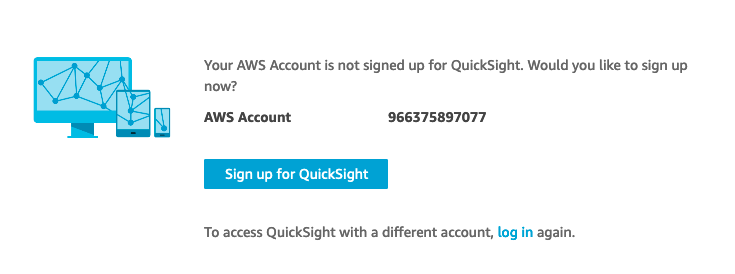
Amazon QuickSight のダッシュボードを作成する前に、サインアップを実施します。QuickSight に初めてアクセスする際には以下の画面で「Sing up for QuickSight」をクリックします。
続く画⾯で Enterprise を選択して次に進みます。なお、画⾯が英語表⽰の場合は、画⾯右上のメニューから、⽇本語表⽰に変更することができます。

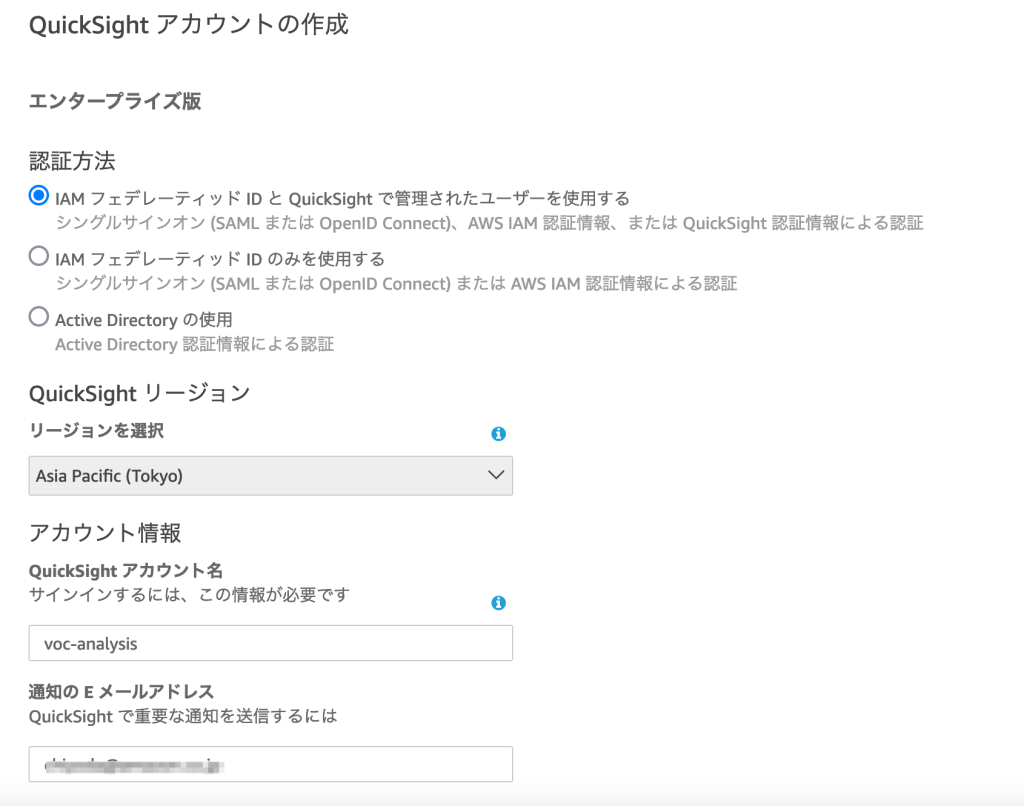
アカウント作成画⾯では、リージョンは「Asia Pacific(Tokyo)」を選択し、アカウント名は任意の⽂字列を⼊⼒します(全世界でユニークな文字列)。通知の E メールアドレスにはご⾃分の email アドレスを⼊⼒してください。
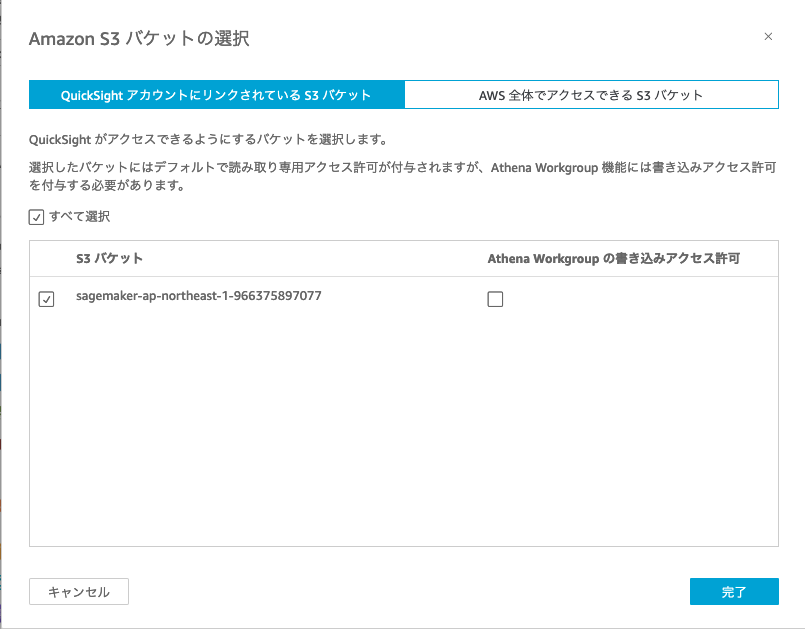
続く「Allow access and autodiscovery for these resources」では「S3 バケットを選択する」をクリックし、「sagemaker-リージョン名-アカウント名」のS3 バケットを選択します。

「完了」ボタンをクリックすると QuickSight アカウントが作成されます。
SPICEの追加
右上のメニューから「QuickSight の管理」->「SPICE 容量」→ 「さらに容量を購入」で、40 GB の SPICE 容量を追加します。(前述の手順でアマゾンのレビューデータを 260,000件取り込んでいる場合)

ポリシーの作成
SageMakerノートブックからQuickSightの操作を行うためにポリシーを作成します。マネージメントコンソールのメニューから 「IAM」→ 「ポリシー」→「ポリシーの作成」を選択します。
JSONタブを選択し、以下のポリシーを入力します。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"quicksight:CreateAnalysis",
"quicksight:PassDataSet",
"quicksight:CreateDataSet",
"quicksight:PassDataSource",
"quicksight:CreateDataSource",
"quicksight:DescribeTemplate"
],
"Resource": "*"
}
]
}
「ポリシーの確認」画面まで進み、名前(ここでは sagemaker-quicksight-policy)を入力し、ポリシーを作成します。
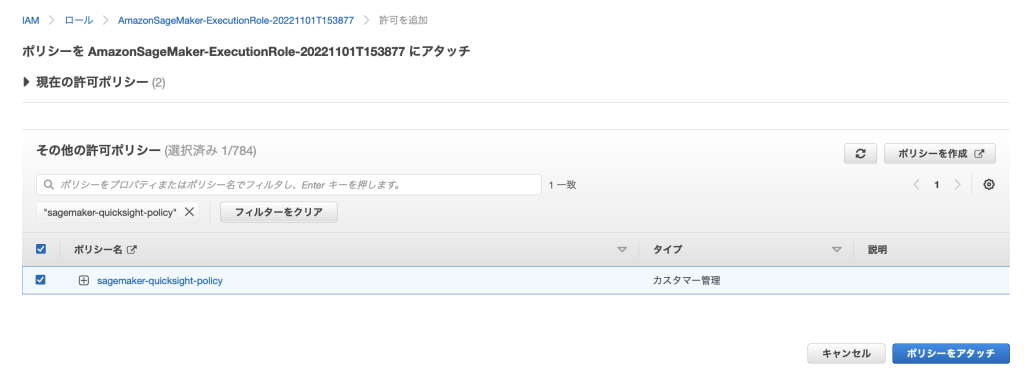
次に作成したポリシーを SageMaker ノートブックの IAM ロール(AmazonSageMaker-ExecutionRole-xxxxx)にアタッチします。左側のメニューの「ロール」を選択、ロール一覧から AmazonSageMaker-ExecutionRole-xxxxx を選択し、「許可を追加」→「ポリシーをアタッチ」を選択します。作成した sagemaker-quicksight-policy をチェックして「ポリシーをアタッチ」をクリックします。
ノートブックに戻り、以下の手順を実行します。(権限エラーが出る場合は、ポリシーの適用まで時間がかかることがあるので少し待ってから実行します)
ワード、係り受けの抽出結果は S3 に CSV ファイルとして出力されます。以下のセルではこの CSV ファイルを対象とした データソースを作成します。
manifest = {
"fileLocations": [
{
"URIPrefixes": [
f's3://{bucket}/{project_name}/output/'
]
}
]
}
with open('manifest.json', 'w') as f:
json.dump(manifest, f)
!aws s3 cp ./manifest.json s3://{bucket}/{project_name}/manifest/
response = quicksight.create_data_source(
AwsAccountId=account_id,
DataSourceId=str(uuid.uuid4()),
Name=project_name,
Type='S3',
DataSourceParameters={
'S3Parameters': {
'ManifestFileLocation': {
'Bucket': bucket,
'Key': f'{project_name}/manifest/manifest.json'
}
}
}
)
data_source_arn = response['Arn']
次のセルでは、quicksight_username を指定します。ユーザー名はQuickSightの右上のメニューから確認することができます。データセットを作成すると QuickSight の UI 上で参照可能となります。
quicksight_username = 'XXXXXX'
quicksight_region = 'ap-northeast-1'
date_format = 'yyyy-MM-dd'
response = quicksight.create_data_set(
AwsAccountId=account_id,
DataSetId=str(uuid.uuid4()),
Name=project_name,
PhysicalTableMap={
'phsicalTable': {
'S3Source': {
'DataSourceArn': data_source_arn,
'InputColumns': list(map(lambda x: {'Name': x, 'Type': 'STRING'}, df3.columns))
}
}
},
LogicalTableMap={
'string': {
'Alias': project_name,
'DataTransforms': [
{
'CastColumnTypeOperation': {
'ColumnName': 'ts',
'NewColumnType': 'DATETIME',
'Format': date_format
}
},
{
'CastColumnTypeOperation': {
'ColumnName': 'id',
'NewColumnType': 'INTEGER'
}
},
],
'Source': {
'PhysicalTableId': 'phsicalTable'
}
}
},
ImportMode='SPICE',
Permissions=[
{
'Principal': f'arn:aws:quicksight:{quicksight_region}:{account_id}:user/default/{quicksight_username}',
'Actions': [
'quicksight:PassDataSet',
'quicksight:DescribeIngestion',
'quicksight:CreateIngestion',
'quicksight:UpdateDataSet',
'quicksight:DeleteDataSet',
'quicksight:DescribeDataSet',
'quicksight:CancelIngestion',
'quicksight:DescribeDataSetPermissions',
'quicksight:ListIngestions',
'quicksight:UpdateDataSetPermissions'
]
},
]
)
data_set_arn = response['Arn']
QuickSight 分析の作成
別途作成済みの分析定義をダウンロードします。
!wget -q https://raw.githubusercontent.com/aws-samples/aws-ml-jp/main/nlp/nlp_amazon_review/nlp_voc_dashboard/voc-analysis.json
以下のセルではダウンロードした分析定義を分析対象のデータに合わせて修正します。
source_str = ['$IDENTIFIER', '$DATASETARN', '$COL0', '$COL1', '$COL2', '$COL3', '$COL4']
target_str = [project_name] + [data_set_arn] + structured_fields
with open('voc-analysis.json') as f:
voc_analysis_str = f.read()
for i in range(len(source_str)):
voc_analysis_str = voc_analysis_str.replace(source_str[i],target_str[i])
voc_analysis_dict = json.loads(voc_analysis_str)
最後のセルでは QuickSight の分析を作成します。Definition で分析定義を指定することで、1から画面を作成することなく、すぐに分析を作成することができます。
ダッシュボードの作成
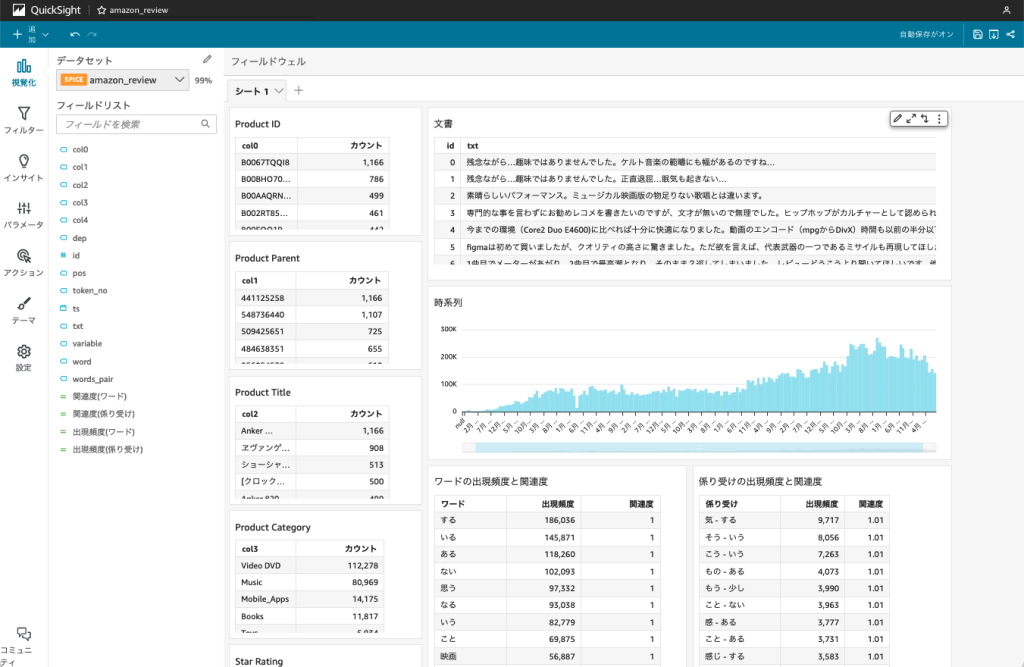
作成した分析は以下のようになります。(以下の画面では各ビジュアルを分かりやすいタイトルに編集しています)
右上のメニューから「ダッシュボードの公開」を選択し、ダッシュボードを公開します。
ダッシュボードからインサイトを得る
ダッシュボードから分析してインサイトが得られるか確認してみます。以下の結果は「3.2. SageMaker Processing で実行」で 260,000 件のデータを対象としており、データ数が少ない場合は異なる結果になります。
「Product Category」で「Video DVD」を選択、「Star Rating」で「5」を選択します。「Product Title」でカウントが最多の「ショーシャンクの空に」が Video DVD カテゴリーでは評価が高いことが分かります。また、選択に応じて、右側のワード、係り受けの出現頻度、関連度の値が変わります。出現頻度は各ワード、係り受けが含まれる文書の数になります。また、関連度は全文書の中での各ワードや係り受けが含まれる割合と、選択された文書の中での各ワードや係り受けが含まれる割合の相対的な比率を QuickSight の計算フィールドで算出しており、関連度が高いほど着目すべきと考えることができます。
さらに深掘りするために、「Product Title」で「ショーシャンクの空に」を選択すると、以下のような結果となります。出現頻度が多く、且つ関連度が高いワード、係り受けに着目すると、「無実の罪で刑務所に入れられた主人公が、それでも希望を持って生きていく様に感動を覚えた」という点が評価のポイントであると推測することができます。
同様の手順で見ていくと、評価の低い DVD は「ヱヴァンゲリヲン新劇場版」であること、「届く」「発送」等が着目すべきポイントとなります。さらに「届く」を選択して、元の文書を見てみると、「商品が届きません」「まだ届きません」「届くはずが今日になってもきません」といった内容を見つけることができ、映画の内容ではなく、発送に関する不満から評価が下がっていると推測することができます。
まとめ
本記事では Amazon SageMaker と Amazon QuickSight による自然言語処理ダッシュボードを紹介しました。シンプルな手順でテキストに埋もれた知見を発見することができる点をご理解いただけたのではないかと思います。提供しているノードブックで簡単にデータを入れ替えることもできるので、ご自身の手持ちのデータでもトライしていただければと思います。







