Amazon Web Services ブログ
AWS Glue DataBrew の発表 – データのクリーニングと正規化を迅速にするビジュアルデータ準備ツール
分析の実行、レポートの作成、あるいは機械学習の導入を始めるには、使用するデータがクリーンで適切な形式であることを確保する必要があります。このデータの準備ステップでは、データアナリストとデータサイエンティストに対し、カスタムコードの記述や、多くの手動操作が要求されます。そこではまず、データを見て、利用できそうな値を把握し、列同士の間に相関があるかどうかを確認するための簡単な可視化機能を構築する必要があります。その後、想定を外れた通常以外の値をチェックします。たとえば、200℉(93℃)を超えるような気温や、200mph(322 km/h)を超えるトラックの速度、そして欠落しているデータなどを洗い出します。多くのアルゴリズムでは、特定の範囲(たとえば 0 と 1 の間)への値の再スケールや、平均値を中心にした値の正規化が求められます。テキストフィールドは標準的な形式に設定するとともに、ステミングなどの高度な変換が必要な場合もあります。
これは大仕事です。今回、この仕事に対処するための AWS Glue DataBrew が利用可能になったことをお知らせできるのを、喜ばしく思っています。このサービスは、データのクリーンアップと正規化を 80% 高速化できる視覚的なデータ準備ツールであり、ビジネスから得られる価値に、お客様がより集中できるようにするものです。
DataBrew で提供されるビジュアルインターフェースでは、Amazon Simple Storage Service (S3)、Amazon Redshift、Amazon Relational Database Service (RDS) などに保存されたデータや、JDBC でアクセス可能なあらゆるデータストア、または AWS Glue データカタログによってインデックス化されたデータなどに、素早く接続できるようになります。その後、データを探索しパターンを見つけ出した上で、変換を適用できます。たとえば、結合やピボットの適用、異なるデータセットの統合、関数を使用したデータの操作を行います。
準備が終了したデータは、その場で、さらなるインサイトを得るために、AWS とサードパーティが提供するサービスを通じての利用が可能となります。それらのサービスには、機械学習用の Amazon SageMaker、分析用の Amazon Redshift と Amazon Athena、ビジネスインテリジェンス用の Amazon QuickSight と Tableau などがあります。
AWS Glue DataBrew の仕組み
DataBrew を使用したデータの準備作業は、次の手順に従います。
- S3 または Glue データカタログ(S3、Redshift、RDS)で、1 つ以上のデータセットに接続します。あるいは、DataBrew コンソールを使用すれば、S3 にローカルファイルをアップロードすることもできます。これには、CSV、JSON、Parquet、および .XLSX 形式がサポートされています。
- データセット内のデータを視覚的に探索、把握、統合、クリーンアップ、正規化するための、プロジェクトを作成します。複数のデータセットをマージしたり結合したりできます。コンソールからは、値の分布、ヒストグラム、箱ひげ図、その他の画像機能を使用して、データの異常をすばやく特定できます。
- [profile(プロファイル)] ビューからジョブを実行すれば、40 を超える統計情報を持つ、データセット用のリッチなデータプロファイルも生成できます。
- 列を選択すると、データ品質を向上させる方法に関する推奨事項が表示されます。
- データのクリーンアップと正規化には、250 を超える組み込み済みの変換機能が使用できます。たとえば、NULL 値を削除または置換したり、エンコーディングを作成したりできます。それぞれの変換機能は、それを構築するステップとして、レシピに自動で追加されます。
- 構築されたそのレシピでは、保存、公開、バージョン作成が可能です。さらにレシピをすべての受信データに適用し、データ準備のためのタスクを自動化することもできます。大規模なデータセットにレシピを適用したり、そのためのプロファイルを生成したりするには、ジョブを実行します。
- どの段階においても、プロジェクト、レシピ、およびジョブ実行に対し、データセットがどのようにリンクされているかを、視覚的に追跡し探索できます。この手法により、データの流れや変更点を把握できます。こういった情報はデータ系統と呼ばれ、エラーが出力された場合に、根本原因を発見するのに役立ちます。
では、短いデモを通じて、このサービスがどのように機能するかを見てみましょう。
AWS Glue DataBrew を使用したサンプルデータセットの準備
DataBrew コンソールで [Projects(プロジェクト)] タブを表示し、[Create project(プロジェクトの作成)] をクリックします。新しいプロジェクトには Comments という名前を付けます。これで、新しいレシピも作成されています。レシピは、次の手順で適用するデータ変換に合わせ自動的に更新されます。

今回の作業には、New datasetに Commentsという名前を付けて使用します。

ここで、[Upload file(ファイルのアップロード)] をクリックし、開いたダイアログから、このデモ用に準備しておいた comments.csv ファイルをアップロードします。実稼働ユースケースでは、この段階で、おそらく S3 または Glue データカタログにある、既存のソースを接続することになると思います。このデモでは、アップロードされたファイルの保存先として、S3 を指定しています。Encryption(暗号化)は無効のままにします。

comments.csv ファイルは非常に小さいですが、データ準備に関する一般的なニーズと、その作業を DataBrew を使用して迅速に完了する方法を示すのに役立ちます。今回のファイルは、カンマ区切り値を使用する形式(CSV)です。最初の行には、列の名前が含まれます。また、各行にはテキストのコメントと、各アイテム(item_id)に関して顧客(customer_id)が作成した、数値的な評価が含まれます。各項目はカテゴリの一部です。各テキストコメントは、全体についての所感(comment_sentment)を表します。オプションとして、ユーザーはコメントの提供時にフラグ(support_inededd)を有効にすることで、サポートへの連絡を依頼できます。
comments.csv ファイルの内容は次のとおりです。
[Access permissions(アクセス権限)]で、入力 S3 バケットに対する読み取りアクセス権限を DatabRew に付与するための、AWS Identity and Access Management (IAM) ロールを選択します。DataBrew が信頼ポリシーのサービスプリンシパルとなっているロールのみが、DataBrew コンソールに表示されます。ロールを IAM コンソールで作成する際に、[DataBrew] を信頼されたエンティティとして選択します。

大きなデータセットの場合は、[Sampling(サンプリング)] を使用して、プロジェクトで使用する行数を制限できます。これらの行の選択は、開始時、終了時、または、データ全体でランダムに行うように指定できます。ここからは、プロジェクトを使用してレシピを作成し、次にジョブを使用してレシピをすべてのデータに適用していきます。データセットによっては、データ準備レシピを定義するためにすべての行にアクセスする必要がない場合があります。
オプションで Tagging(タグ付け)を使用すると、AWS Glue DataBrewで作成したリソースを管理、検索、またはフィルタリングできます。
この段階で、プロジェクトの準備は完了しており、数分以内にデータセットの探索を開始できるようになります。
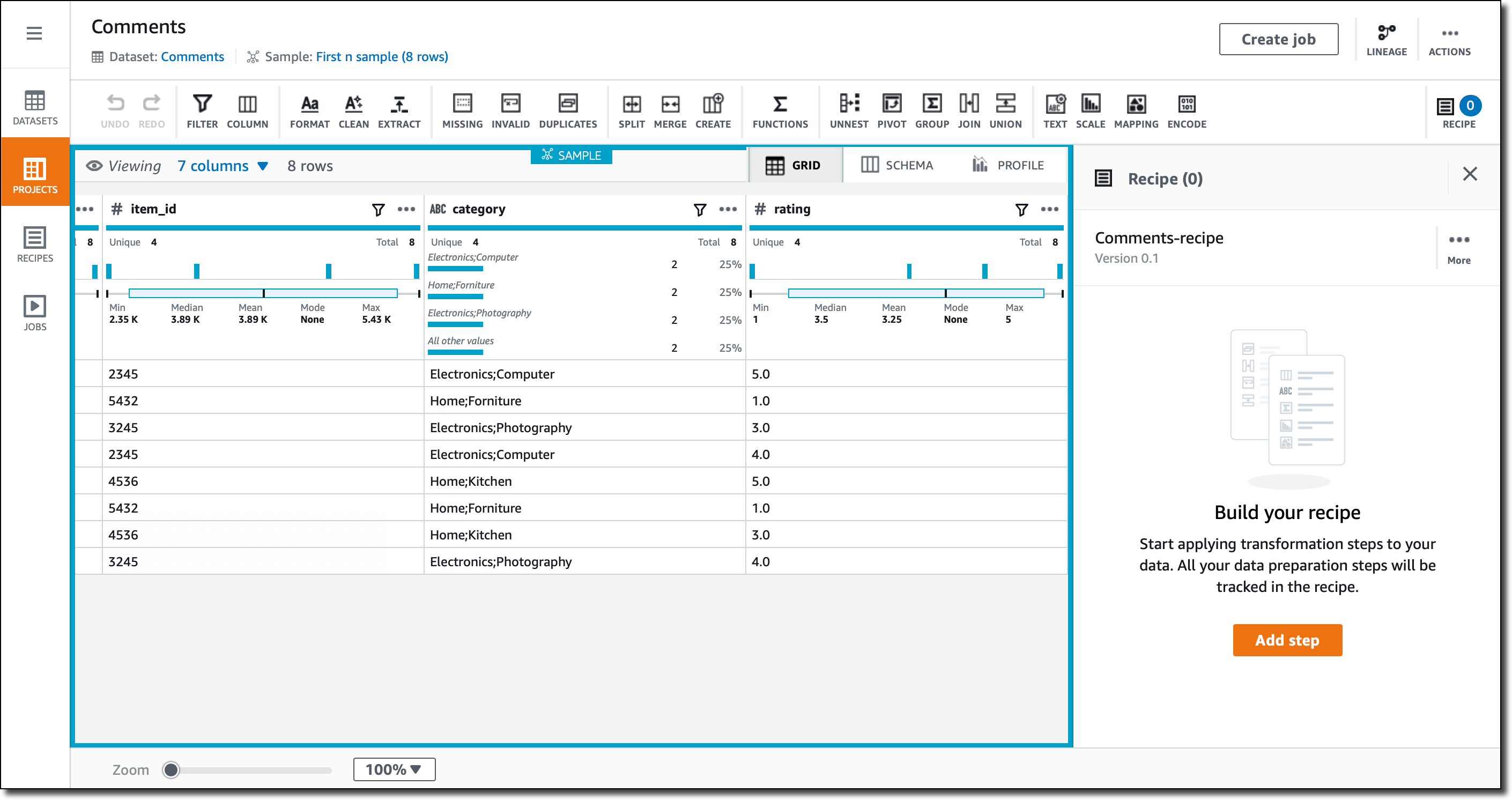
Grid ビュー(新しいプロジェクトを作成するときのデフォルト)では、インポートされたデータが表示されます。各列には、検出された値の範囲の要約が表示されます。統計的分布は、数値列に表示されます。
Schema ビューでは、推定されたスキーマをドリルダウンしたり、必要に応じて列の一部を非表示にすることができます。
Profile ビューでは、データに関する統計サマリーの収集と調査のために、データプロファイルジョブを実行できます。この処理は、構造、内容、関係性、および導出の観点から行う評価です。大規模なデータセットの場合、データを理解するのに、この評価が非常に有効となります。この小さな例では利点は限られていますが、やはりプロファイルジョブを実行します。この処理により出力が、ソースデータの保存に使用したのと同じ S3 バケット内の別のフォルダに送信されます。
プロファイルジョブが成功すると、データセット内の行と列に関する概要が表示されます。この表示からは、有効な列と行の数や、列間の相関を確認できます。
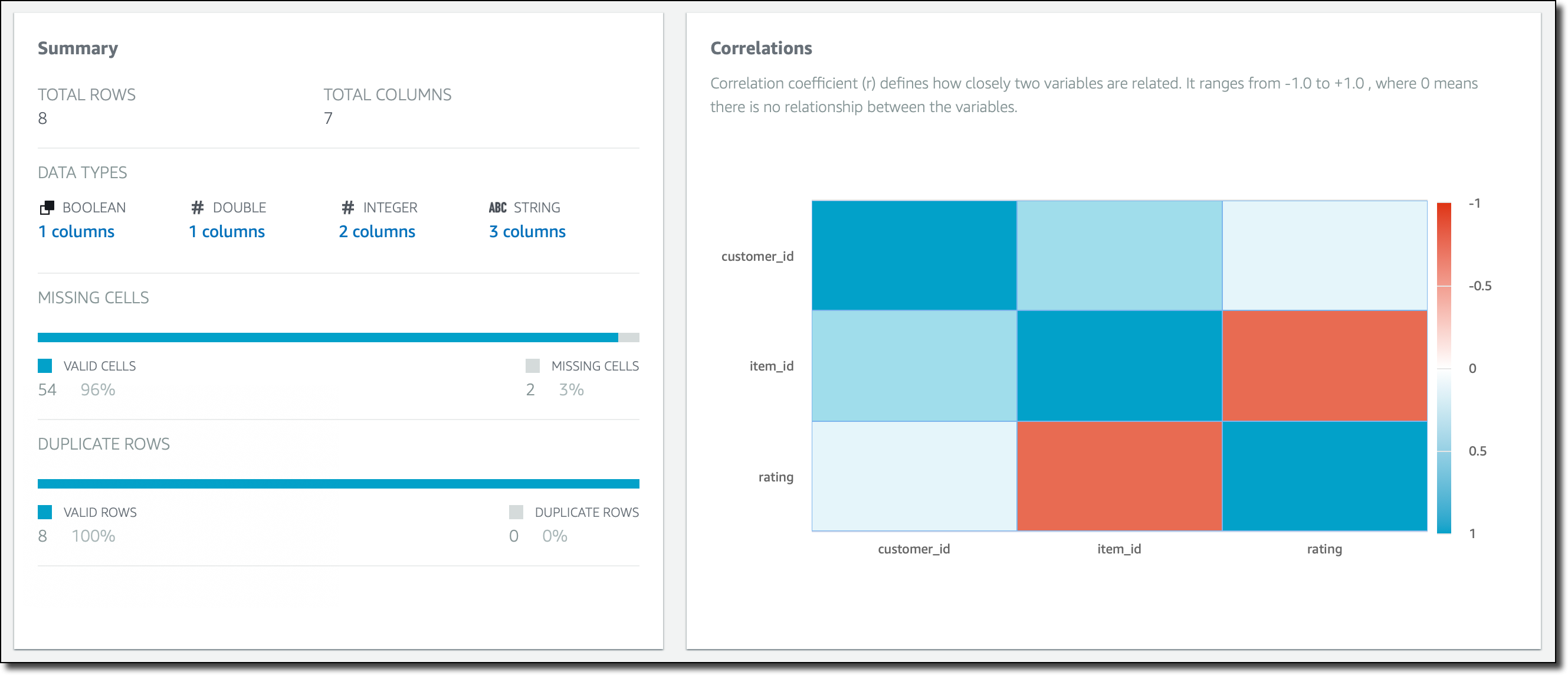
ここで、たとえば rating などの列を選択すると、その列についての特定の統計情報や相関性にドリルダウンしていけます。
それでは、実際のデータの準備を行ってみましょう。Grid ビューで、それぞれの列を見てみます。[category(カテゴリ)] 列は、セミコロンで区切られた 2 つの情報で構成されています。たとえば、最初の行の category は “Electronics;Computers” となっています。 カテゴリ列を選択し、列のアクション(列名の右側にある3つの小さなドット)をクリックすると、その列に適用できる多くの変換処理にアクセスできます。今回の場合、1 つの区切り文字による列の分割を選択します。変更内容を適用する前に、それらをコンソールですばやくプレビューしておきます。

セミコロンを区切り文字として使用することにし、列を category_1 と category_2 の 2つに分割します。もう一度、列アクションを使用して、それぞれの列の名前を、category と subcategory に変更します。ここで、最初の行の category には Electronics が、subcategory には Computers が含まれています。これらの変更はすべて、プロジェクトレシピにステップとして追加されるため、後に同様のデータに対しても適用できます。
rating 列は、1 から 5 までの値が集録されています。多くのアルゴリズムでは、これらの種類の値は正規化した方が便利です。値を 0~1 の間で再スケールするために、列アクションで [min-max normalization] を選択します。[mean(平均)] や [Z-score normalization(Z スコアの正規化)] など、より高度なテクニックも用意されています。再スケールが完了すると、新たに [rating_normalized] という列が追加されます。
DataBrew が [comment] 列に挿入した推奨度合を調べてみます。推奨度合はテキストなので、小文字、大文字、センテンスケースなど、書式を標準化することが推奨されます。ここでは、小文字を使用することにします。
コメントには、顧客が書いたフリーテキストが集録されています。この後の分析を簡素化するために、この列で [word tokenization(単語のトークン化)] を使用し、ストップワード(“a”、“an”、“the” など)の削除と、(“don’t”が“do not”になるように)短縮の展開を行い、ステミング(語幹処理)を適用します。これらの修正結果は、[comment_tokenized] という新しいカラムに集録されます。
ここでもまだ [comment_tokenized] 列には、:-)のような顔文字など、いくつかの特殊文字が残っています。列のアクションで、[remove special characters(特殊文字を削除)] を選択して、クリーンアップしておきます。
次に、[comment_sentiment] 列で推奨度合を調べます。ここでは、いくつかの値が欠落しています。失われている値には、所感としてneutral を埋めることにします。この列には依然として、異なる文字で書かれた値が存在します。小文字を使用するという推奨事項に従い、これらの値を修正します。
現在、[comment_sentement] 列には (positive(肯定的)、negative(否定的)、neutral(中立)の) 3 つの異なる値が含まれていますが、多くのアルゴリズムでは ワンホットエンコーディング(one-hot encoding)を使用する方が便利です。この手法では、適当な値のために列が 1 つ存在し、その列には(一般的な対応であれば) 1、もしくは 0 が集録されます。メニューバーで [Encode(エンコード)] アイコンをクリックし、[One-Hot encode column] を選択します。設定はデフォルトのままで適用します。可能性がある 3 つの値のために、3 つの新しい列が追加されます。
[support_Needed] 列は boolean(ブール値)として認識され、その値は自動的に標準の書式にフォーマットされます。これに関しては、何もする必要はありません。
これで、データセットのためのレシピが公開できるように準備されました。このレシピは、同様のデータを処理する反復的なジョブで使用できます。今回は、データを大量には用意しませんでしたが、このレシピは、はるかに大きなデータセットでも使用が可能です。
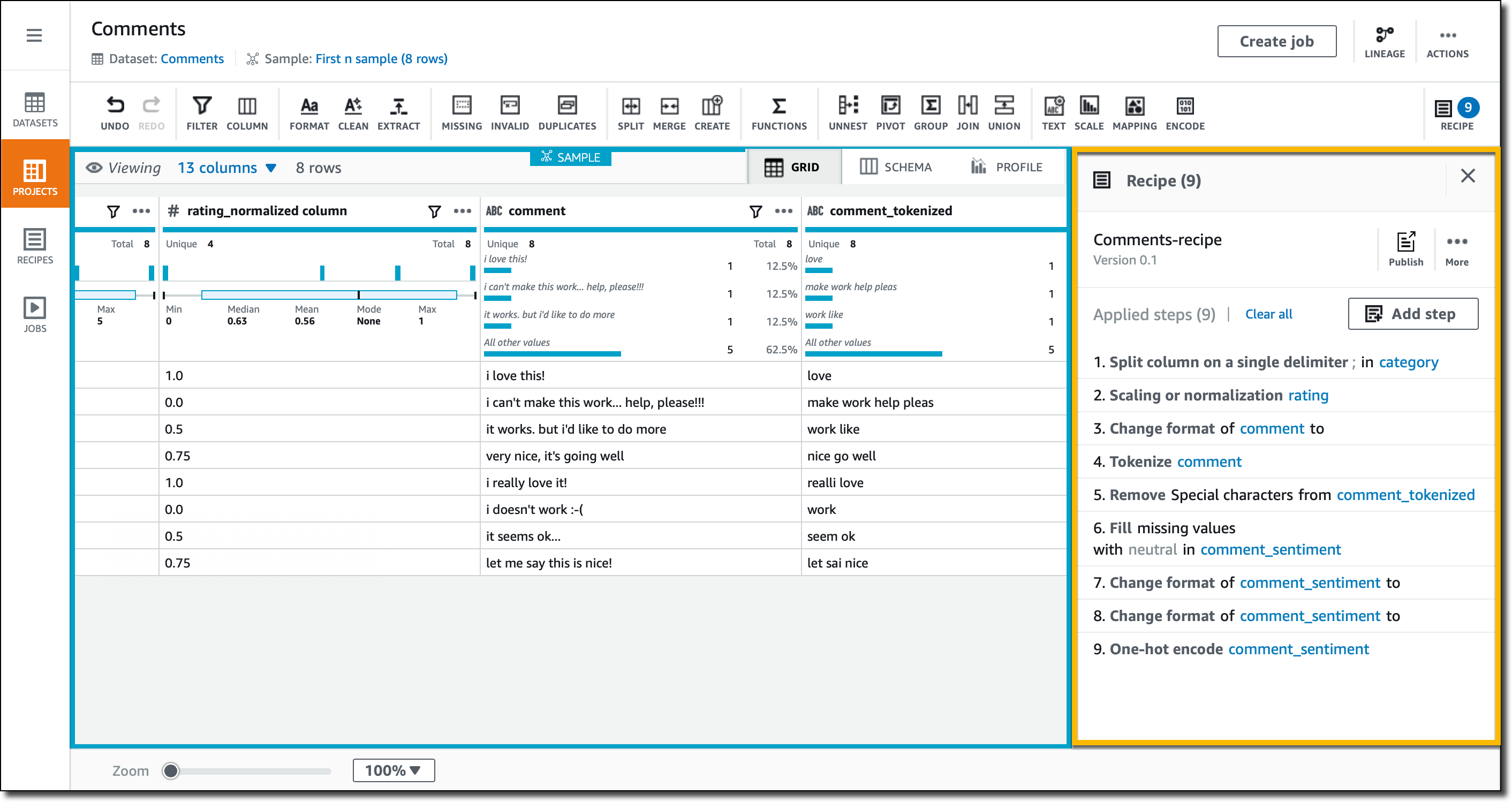
レシピでは、その段階で適用したすべての変換処理を、一覧表示で見ることができます。レシピジョブを実行すると、その出力は S3 に保存されます。このデータは、分析や機械学習のプラットフォームで利用が可能です。あるいは、BI ツールを使用してのレポート作成や視覚化のためにも使用できます。出力は、入力とは異なる形式で記述されています。たとえば、Apache Parquet のような列指向ストレージを使用して保存されます。

このサービスは、今すぐご利用いただけます
AWS Glue DataBrew は現在、米国東部(バージニア北部)、米国東部(オハイオ州)、米国西部(オレゴン)、ヨーロッパ(アイルランド)、ヨーロッパ(フランクフルト)、アジアパシフィック(東京)、アジアパシフィック(シドニー)の、各 AWS リージョンでご利用いただけます。
このサービスで、分析、機械学習、または BI 用のデータの準備が、かつてないほど簡単になりました。維持および更新する必要があるカスタムコードを記述する必要はなく、ビジネスのためのインサイトを得ることに、本当に集中できます。
DataBrew の使用法の練習は、新しいプロジェクトを作成した上で、提供されているサンプルデータセットの 1 つを選択することで始められます。これは、利用可能なすべての機能と、それらをデータに適用する方法を学習するのに最適な方法です。
詳細を確認してから、今すぐ AWS Glue DataBrew の使用を開始してください。
– Danilo