Amazon Web Services ブログ
Amazon EMR で Amazon EC2 スポットインスタンスを使用して、Apache Spark アプリケーションを実行するベストプラクティス
Apache Spark は、分析ジョブの実行に使用する最も一般的なツールの 1 つになりました。その使いやすさ、速いパフォーマンス、メモリとディスクの使用率、および組み込みのフォールト トレランスが人気の理由です。これらの機能は、インスタンスが使い捨てや一時的に使用できる状態になっているクラウド コンピューティングの概念と強く関連付けられます。
Amazon EC2 スポットインスタンスは、オンデマンド料金に比べて大幅な割引料金で、AWS クラウドで利用可能な予備コンピューティング容量を提供します。 EC2 が容量を元に戻す必要がある場合、EC2 は 2 分間の通知でスポットインスタンスを中断できます。スポットインスタンスは、さまざまなフォールト トレラントで柔軟なアプリケーションに使用できます。例としては、分析、コンテナー化されたワークロード、ハイパフォーマンス コンピューティング (HPC)、ステートレス ウェブサーバー、レンダリング、CI/CD、その他のテストと開発ワークロードがあります。
Amazon EMR は、EC2 インスタンスを使用して膨大な量のデータ処理を簡単かつ高速で、そして費用対効果の高い方法で行う、マネージド Hadoop フレームワークを提供します。Amazon EMR を使用するときは、Spark ソフトウェア (または Hadoop フレームワークの他のツール) のインストール、アップグレード、およびメンテナンスについて心配する必要はありません。基となるハードウェアやオペレーティング システムのインストールとメンテナンスについても、ご心配は要りません。代わりに、ビジネス アプリケーションに集中し、Amazon EMR を使用して、区別されていない手間がかかる処理を取り除くことができます。
このブログ記事では、スポットインスタンスを使用してコストを最適化し、Amazon EMR で Spark アプリケーションを効率的に実行することに焦点を当てます。Spark アプリケーションのフォールト トレランスを高め、スポットインスタンスを使用するベストプラクティスをいくつかお勧めします。これらは、可用性を犠牲にしたり、パフォーマンスやジョブの長さに大きな影響を与えたりすることなく機能します。
スポットインスタンス アドバイザーを使用して、適切な中断率でインスタンスタイプをターゲットにする
前述のように、EC2 が容量を元に戻す必要がある場合は、スポットインスタンスが中断される可能性があります。このブログ記事では、スポットの中断により基になる EC2 インスタンスの不定期な損失に耐えるために、Spark アプリケーションのフォールト トレランスを向上させる方法に関するベストプラクティスを紹介します。ただし、その場合も、中断率の低い EC2 スポットインスタンスをターゲットにするとさらに効果的です。この方法は、中断が発生したときに Spark が作業の一部をやり直す必要があるため、ジョブが長くなる頻度を減らす場合に役立ちます。
スポットインスタンス アドバイザーを使用して中断率を確認し、履歴で中断率が低いインスタンスタイプを使用して Amazon EMR クラスターを作成してみてください。例えば、この記事を書いている時点での米国東部 (オハイオ) リージョンにおける r4.2xlarge の中断頻度は 5% 未満です。これは、過去 30 日間に起動されたすべての r4.2xlarge スポットインスタンスで EC2 によって中断されたものが 5% 未満だということを意味します。
一連の多様なインスタンスタイプでスポット ワークロードを実行する
EC2 インスタンスでワークロード (分析など) を実行し、オンデマンドまたはリザーブドインスタンスの購入オプションを使用する場合は、通常、クラスター全体で単一のインスタンスタイプを使用できます。ベンチマークの後で、アプリケーションの要件に合った適切なインスタンスタイプを見つけることができます。ただし、スポットインスタンスでは、クラスターで複数のスポット容量プール (アベイラビリティーゾーン内のインスタンスタイプ) を使用することが重要です。このプラクティスにより、スケールを達成し、ジョブを実行する容量を維持することができます。
例えば、オンデマンド r4.xlarge インスタンス (30.5 GiB メモリと 4 つの vCPU) を使用して Spark アプリケーションを実行したとします。スポットインスタンスを使い始めるときに、Amazon EMR クラスターのコアまたはタスク インスタンスのフリートを、vCPU とメモリの比率が似ている複数のインスタンスタイプ (vCPU あたり約 7 GB) で構成し、EMR がクラスターで実行する適切なインスタンスタイプを選択します。これらは、r4.2xlarge、r5.xlarge、i3.2xlarge、i3.4xlarge を含みます。この方法を使用すると、クラスターの起動に十分なスポット容量を得られる可能性が高くなります。また、クラスター容量の一部が EC2 スポットの中断によって終了された場合に、Amazon EMR が (他の容量プールから) 実行し続けるために必要な容量を補充できる可能性も高くなります。
| インスタンスタイプ | vCPU の数 | RAM (GB 単位) |
| R4.xlarge | 4 | 30.5 |
| R4.2xlarge | 8 | 61 |
| R5.xlarge | 4 | 32 |
| I3.2xlarge | 8 | 61 |
| I3.4xlarge | 16 | 122 |
複数のインスタンスタイプを使用できるように Spark 実行プログラムのサイズを設定する
直前に説明したように、スポットインスタンスで実行するうえで重要な要素は、インスタンスの分散されたフリートを使用することです。スポットの中断がジョブに与える影響を減らす場合も役立ちます。この方法は Spark アプリケーションのアーキテクチャをディクテーションします。
メモリを集中的に使用する実行プログラム (RAM 20 GB 以上) で実行すると、アプリケーションは特定インスタンスタイプのセットに関連付けられます。これらは、クラスターの立ち上げに十分なスポット容量を持たない可能性があります。また、スポット中断率が高く、実行中のジョブに影響を与える可能性があります。
例えば、RAM が 90 GiB で実行プログラム 1 つあたり 15 コアの Spark アプリケーションの場合、ハードウェア要件を満たすインスタンスタイプは 11 種類のみで、スポット中断率は 20% を下回ります。実行プログラム 1 つあたり 2 コアに対して、1 コアあたり RAM 6 GiB の比率を維持しながら、実行プログラムを分割するとします。その場合、(中断率 20% 以下) で実行できるジョブの追加インスタンスタイプを最大 20 まで開くことができます。
実行プログラムのサイズを変更する正当な方法は、アプリケーションを実行する最小コア数を決めることです。まず、2 つから始めましょう。その後、次の計算を使用してメモリを割り当てます。
NUM_CORES * ((EXECUTOR_MEMORY + MEMORY_OVERHEAD) / EXECUTOR_CORES)
この例では、2 * (( 90 + 20 ) / 15) = 15GB になります。
memoryOverhead 設定の詳細については、「Spark ドキュメント」を参照してください。
Spark で大きなシャッフルを避ける
Amazon EMR クラスターでスポットインスタンスが中断された場合に Spark が再処理する必要があるデータの量を減らすには、大きなシャッフルを避ける必要があります。
GroupBy や一部種類の結合のような幅広い依存関係操作は、膨大な量の中間データを生成する可能性があります。中間データはローカル ディスクに保存された後、クラスター内の他の実行プログラムに転送 (シャッフル) されます。
常に行えるわけではありませんが、シャッフル操作を回避するか、シャッフル データの量を最小限に抑えることをお勧めします。お勧めする理由は 2 つです。
- シャッフルは負荷のかかる操作であるため、一般的な Spark のベストプラクティスです。
- スポットインスタンスのコンテキストで実行すると、ジョブのフォールト トレランスが低下します。シャッフル データを含んでいるか、計算のシャッフル データに依存している (通常は両方) ノードを 1 つ失うと、シャッフル プロセスの一部を再実行する必要があるためです。
次に説明するように、不必要な量のシャッフル データを生成するパターンがいくつかあります。
グループ パターンへの展開
開発者の観点から、複雑なデータ型に対して展開を使用することは、(配列を複数の行に展開する) 一部のユースケースに対する迅速なソリューションになることがあります。このように行数を増やし、後でジョブの中からそれらを結合することができます。
例えば、データにユーザー ID と、ウェブサイトへの訪問を表す日付の配列が含まれているとします。
| A | B | |
| 1 | user_id | visit_dates_array |
| 2 | 0 | [ “28/01/2018”29/01/2018”, “01/01/2019”] |
| 3 | 100000 | [ “01/11/2017”, “01/12/2017”] |
| 4 | 999999 | [ “01/01/2017”, “02/01/2017”, “03/01/2017”, “04/01/2017”, “05/01/2017”, “06/01/2017”] |
ウェブサイトでユーザーの合計訪問数を計算する Spark アプリケーションを実行したとします。この場合、次のように、展開を使用してデータを集計する簡単なソリューションがあります。
データを展開します。
データを再度集計します。
この方法は迅速かつ簡単ではありますが、データが元のデータの 3 倍に肥大化されてしまいます。各 user_id の合計訪問数を正確に計算するには、また、データをネットワーク経由で他の実行プログラムに送信する必要があります。
展開やグループ化の代わりにできることは何ですか?
オプションの 1 つは、計算を適切に実行し、シャッフルを回避または最小化する UDF を作成することです。次の例は Scala です。
最近 Spark 2.4 で導入されたもう 1 つのオプションは、集計関数です。この関数は、シャッフル データの量を減少させ、user_id とその訪問数を最小限に抑えることもできます。
巨大なデータ結合 (バケット)
結合操作を実行するとき、Spark は結合キーによってデータを再分割 (シャッフル) します。
同じテーブル、または同じキーを使用するテーブルで複数の結合を実行する場合は、バケットを使用してデータを 1 回だけシャッフルすることができます。データを保持するとき、同じキーへのその後の結合ではシャッフルは必要ありません。Amazon S3 ではデータがすでに「事前シャッフル」されています。
データをバケット化するには、データを分割するバケット数と、バケット化が発生する列を決定する必要があります。
データ スキューを処理する
場合によっては、データがパーティション間で均等に配布されないことがあります。これはいくつかの理由によって問題になります。
- 一般的に、ほとんどの実行プログラムは時間内に終了します。ただし、大きな異常値を処理する場合は、より長い時間実行されます。これにより、スポットインスタンスが中断され、ジョブ全体を再計算しなければならないリスクが高まります。また、全体的なパフォーマンスに悪影響を及ぼし、ジョブの長さを延ばしたり、リソースの利用率を低下させたりします。
- データ スキューは、大量のシャッフル データの原因となることもあり、前述のように問題を引き起こす可能性があります。
データ スキューの処理には、ローカルの実行プログラムで興味のある計算を実行することをお勧めします。次に結果を計算します。この方法は結合操作としても知られています。
データ スキューを取り扱う一般的な手法は、キーの salt 処理です。
回復性を高めるために、巨大な Spark ジョブをより小さなジョブに分割する
遭遇するアンチパターンの 1 つは、完了するまでに数時間または数日かかることがある、多数のジョブを実行する大規模なアプリケーションです。
この種のジョブは全か無かの状況を生み出します。ここでは、ジョブのランタイム全体にわたる問題によって、失敗が時間とお金の損失を引き起こす可能性があります。
当たり前のように聞こえるかもしれませんが、ジョブをより小さなジョブの連鎖に分割すると、失敗とスポット中断を扱う回復力が増します。また、ジョブを分割することは、ジョブが正常に終了することを妨げる問題を修正できることを意味します。さらに、それはプロセスに既に投資した努力が実を結ばないおそれを減らします。
Amazon EMR インスタンスのフリートを操作する
Amazon EMR インスタンスのフリートをいくつかの手法で使用して、Spark と効果的に連携できます。
クラスターの EC2 インスタンスタイプを分散する
Amazon EMR インスタンスのフリートを設定することで、各 Amazon EMR ノードタイプ (マスター、コア、タスク) に対して最大 5 つの EC2 インスタンスタイプのフリートを設定できます。前述したように、インスタンスに柔軟に対応できることが、Amazon EMR クラスターのスポット容量を起動し維持するキーとなります。
マスターノード グループの場合、Amazon EMR によって選択から 1 つのインスタンスが選択されます。コアおよびタスク ノードグループで、容量の可用性と低い料金に基づいて、Amazon EMR はクラスターで使用する最適なインスタンスタイプを選択します。また、異なるアベイラビリティーゾーンに複数のサブネットを指定できます。この場合、Amazon EMR はクラスター全体を起動するターゲット容量に最も適した AZ を選択します。
ジョブのハードウェア要件に従って Amazon EMR インスタンスのフリート サイズを決定する
Amazon EMR インスタンスのフリートを使用すると、アプリケーションに適合させるインスタンスタイプを指定して、リソース プールを定義できます。各インスタンスタイプがターゲット容量に対して、プール内で担う重みを指定することもできます。
デフォルトでは、インスタンスに vCPU の数と同等の重みが与えられます。ただし、このセクションで説明しているように、メモリなど、他のインスタンス特性に応じて重みを指定することもできます。
CPU によるサイズ設定:
例えば、実行プログラムごとに 4 コア、コアごとに RAM 1 GB を必要とするジョブがあるとします。その場合、Spark の設定は次のようになります。
このジョブは実行プログラム 20 個で実行する必要があります。つまり、80 コアが必要です (20*4):
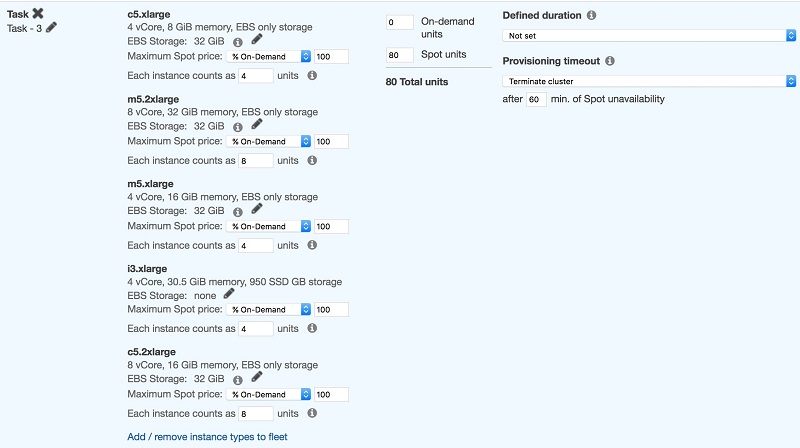
このスクリーンショットは、ジョブを実行するために必要な 80 コアを表すスポット単位 80 を示しています。また、ハードウェア要件に合う、さまざまなインスタンスタイプの選択も示しています。
Amazon EMR は、スポット単位 80 というターゲット容量を満たすために、インスタンスタイプにおける任意の組み合わせを選択しますが、より大きなインスタンスタイプの中には複数の実行プログラムを実行するものもあります。
メモリによるサイズ設定
Spark のアプリケーション要件の中にはメモリを集中的に使用するものがあるため、異なる重み戦略が必要です。
例えば、ジョブが 4 コアでコアあたり 6 GB で実行されている場合 (--executor-cores 4 --executor-memory 24G)、最初に少なくとも RAM が 28 GB あるインスタンスを選択します。
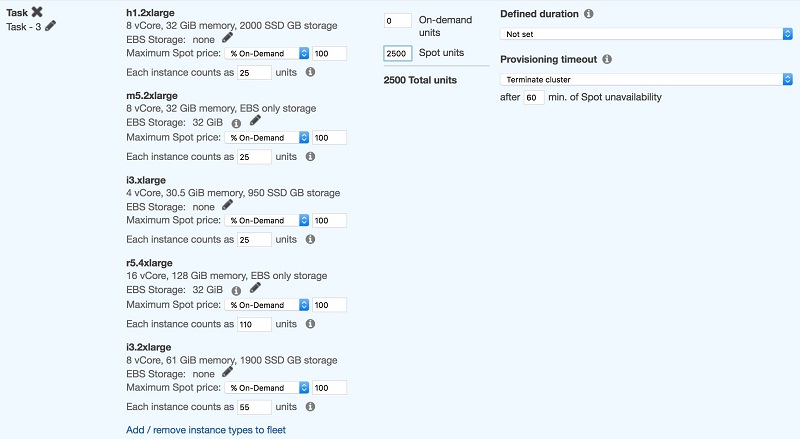
スクリーンショットからわかるように、この構成ではインスタンスタイプの選択がメモリ要件を満たすように設定されています。これにより、インスタンスのオペレーティング システム内で実行されている他のプロセス用に約 15~20% のメモリが解放されます。
次に、適格な最小インスタンスの単位数に、必要な実行プログラム数 (25*100) を掛けて計算した合計単位数を計算します。
CPU 集中型のジョブと同様に、インスタンスタイプによっては実行プログラムを 1 つのみ実行するものもあれば、複数の実行プログラムを実行するものもあります。
インスタンス世代間にあるパフォーマンスの差を補償する
一部のワークロードでは、新しいインスタンスタイプで実行するだけでパフォーマンスが最大 50% まで向上する場合があります。この効果は、AWS Nitro テクノロジー、速い CPU クロック速度、異なる CPU アーキテクチャ (Haswell/Broadwell から Skylake への移行)、またはこれらの組み合わせによって引き起こされます。
アプリケーションの実行時間を短縮することが主な要件である場合は、古いインスタンスの世代に小さい重みを指定することで、インスタンスタイプの世代間にあるパフォーマンスの差を相殺できます。
例えば、10 r5.2xlarge インスタンスの場合は 1 時間、10 r4.2xlarge インスタンスの場合は 2 時間、ジョブが実行されるとします。この場合、インスタンスのフリートを次のように定義することをお勧めします。
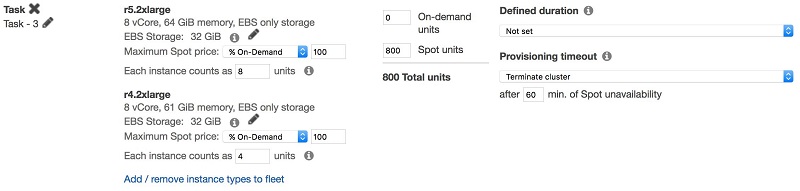
各ノードタイプに適した購入オプションを選択する
スポットブロックは定義された期間のスポットインスタンスで、最大 6 時間まで中断することなく実行できるため、スポットインスタンスに比べて割引率が小さくなります。ただし、クラスターの実行時間が 6 時間未満になると予測され、ジョブがスポット中断の影響を受けない場合は、スポットブロックを使用することもできます。
マスターノード: クラスターを短時間しか利用できず、実行にコストがかかる場合を除いては、スポットインスタンスでマスターノードを実行してはいけません。マスターノードでのスポット中断によってクラスター全体が終了します。オンデマンドの代わりに、スポットブロックにマスターノードを設定することもできます。そのためには、ノードに定義された期間を設定し、スポットブロックの容量が利用できない場合はオンデマンドにフェイルオーバーします。
コアノード: クラスターのジョブが HDFS を使用している場合は、コアノードにスポットインスタンスを使用してはいけません。スポットの中断によってインスタンスの HDFS ボリュームに書き込まれたデータが失われることを防ぎます。
タスクノード: ハードウェア要件に一致するインスタンスタイプを最大 5 つ選択して、コアノードにスポットインスタンスを使用します。Amazon EMR は、料金と容量の可用性によって最も適切な容量を満たします。
EC2 スポット中断の通知を受け取る
EC2 がスポットインスタンスを中断する必要がある場合、中断される予定の各インスタンスに対して 2 分間の警告を発します。プログラムで警告に対処する方法は 2 つあります。インスタンスのメタデータ サービスをポーリングすることと、Amazon CloudWatch Events を使用することです。詳細はドキュメントにあります。
この警告の用途は、ワークロードの種類によって異なります。例えば、インスタンスがシャットダウンされる前に、近いうちに中断される予定のインスタンスを Elastic Load Balancer から切り離して、動作中の接続を実行することを選択できます。あるいは、ログを集中管理された場所にコピーするか、アプリケーションを適切にシャットダウンすることもできます。
EMR が EC2 スポットの中断を処理する方法については、AWS ビッグデータ ブログの記事を参照してください
Amazon EMR の伸縮性と回復力を高める Spark の機能強化。
Amazon EMR のジョブ失敗とスポット中断またはジョブの長さとの関連付けを調べるために、スポット中断を追跡することをお勧めします。この場合、AWS Lambda 関数をトリガーして中断をデータストアにフィードするように、CloudWatch Event を設定できます。この方法で、アカウントの中断履歴をクエリできます。小規模または初期テストの場合でも、E メールと Amazon SNS を使用して、E メールで簡単に中断通知を受け取ることができます。
Amazon EMR クラスターにタグ付けして、コストを追跡する
AWS クラウドでリソースにタグ付けすることが基本的なベストプラクティスです。タグ付け戦略の詳細については、この「AWS Answers」ページをご覧ください。Amazon EMR ではクラスターにタグ付けすると、基となる EC2 インスタンスと、クラスターによって作成された Amazon EBS ボリュームに、タグが伝達されます。これにより、Amazon EMR クラスターの実行にかかるコストの全体像を把握できるようになり、AWS Cost Explorer を使用して簡単に視覚化することができます。
まとめ
このブログ記事では、スポットインスタンスを使用して Amazon EMR で Spark アプリケーションのコストを最適化するベストプラクティスを紹介します。Spark アプリケーションを使用してベストプラクティスをテストし、ワークロードのコスト最適化にこれらの内容が役に立てれば幸いです。
著者について
 Ran Sheinberg 氏は、アマゾン ウェブ サービスを使用する EC2 スポットインスタンス専門のソリューション アーキテクトです。彼は AWS のお客様と協力して、ステートレス ウェブアプリケーション、キュー ワーカー、コンテナー化されたワークロード、分析、HPC など、さまざまな種類のワークロードでスポットインスタンスを利用して、コンピューティング費用を最適化しています。
Ran Sheinberg 氏は、アマゾン ウェブ サービスを使用する EC2 スポットインスタンス専門のソリューション アーキテクトです。彼は AWS のお客様と協力して、ステートレス ウェブアプリケーション、キュー ワーカー、コンテナー化されたワークロード、分析、HPC など、さまざまな種類のワークロードでスポットインスタンスを利用して、コンピューティング費用を最適化しています。
 Daniel Haviv 氏は、アマゾン ウェブ サービスを使用した分析専門のソリューション アーキテクトです。
Daniel Haviv 氏は、アマゾン ウェブ サービスを使用した分析専門のソリューション アーキテクトです。