Amazon Web Services ブログ
Amazon OpenSearch Service でマルチテナントのヘルスケアシステムを構築する
本記事は 2025 年 8 月 5 日 に公開された「Build a multi-tenant healthcare system with Amazon OpenSearch Service」を翻訳したものです。
ヘルスケアシステムは、規制遵守、セキュリティ、パフォーマンスを維持しながら膨大なデータを管理する必要があります。本記事では、Amazon OpenSearch Service を使用してマルチテナントのヘルスケアシステムを実装する戦略について説明します。
ここでいうテナントとは、共通のプラットフォームを共有しながら、データ環境を分離して維持する個別のヘルスケア組織を指します。病院の部門 (救急、放射線科、患者ケアなど)、クリニック、保険会社、検査機関、研究機関などがテナントの例です。
本記事では、マルチテナント環境の一般的な課題に対処し、多様なヘルスケアテナント全体でのセキュリティ、テナント分離、ワークロード管理、コスト最適化のための具体的なソリューションを紹介します。
マルチテナントヘルスケアシステムとは
ヘルスケアシステムのテナントは多様であり、それぞれ異なる要件を持っています。たとえば、救急部門は患者ケアのために 24 時間体制の高可用性と 1 秒以内のレスポンスタイムが必要であり、機密性の高い外傷データに対する厳格なアクセス制御も求められます。研究部門は、時間的制約は緩いものの、リソースを大量に消費する複雑なクエリを実行し、患者データを扱う際には HIPAA 準拠を維持するための匿名化プロトコルが必要です。外来クリニックは営業時間中心の運用で、負荷の変動が少なく、パフォーマンス要件も中程度です。管理システムは財務データに焦点を当て、スケジュールされたバッチ処理を行い、請求情報と保険の詳細へのアクセスのみを必要とします。放射線科や循環器科などの専門部門は、実行するタスクに固有の要件を持っています。たとえば、放射線科は大容量の医用画像ファイルのための高いストレージ容量と帯域幅、およびメタデータ検索のための専門的なインデックス作成が必要です。
テナントの要件を把握することで、規制遵守を維持しながら、リソース共有と適切な分離のバランスを取るマルチテナントアーキテクチャを設計できます。
分離モデル
OpenSearch の階層構造は、4 つの主要なレベルで構成されています。最上位レベルはドメインで、データを保存および検索する 1 つ以上のノードを含みます。ドメイン内では、インデックスがドキュメントを含み、それらの保存方法と検索方法を定義します。ドキュメントはインデックス内に保存される個々のレコードまたはデータエントリであり、各ドキュメントは特定のデータ型と値を持つ個々のデータ要素であるフィールドで構成されます。
インデックスにはマッピングと設定が含まれます。マッピングはインデックス内のドキュメントのスキーマを定義し、フィールド名とそのデータ型を指定します。設定は、プライマリシャードとレプリカシャードの数など、インデックスのさまざまな運用面を構成します。
マルチテナント OpenSearch システムの分離モデルは、ドメイン、インデックス、またはドキュメントレベルで設定できます。マルチテナントヘルスケアシステムに選択するモデルは、セキュリティ、パフォーマンス、コストに影響します。ヘルスケア組織では、次の図のように、テナントの要件に合わせて分離レベルを調整するハイブリッドアプローチが最適です。
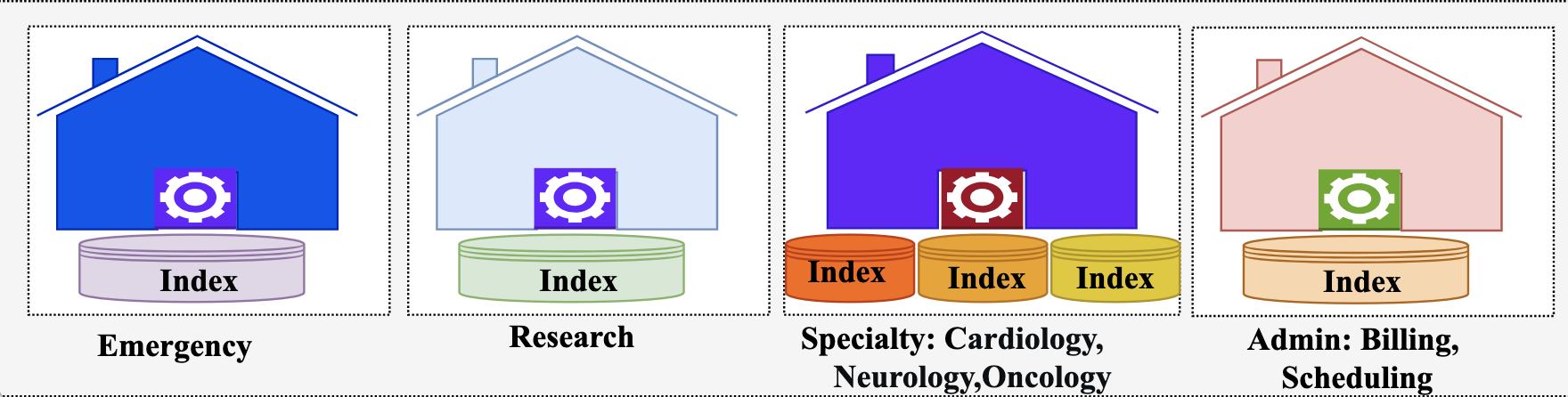
マルチテナント分離モデル
救急部門には、各テナントに個別の OpenSearch ドメインをデプロイして最大限の分離を実現するドメインベースの分離を検討してください。コストは高くなりますが、リソースの競合を減らし、重要なシステムに一貫したパフォーマンスを実現できます。分離により、機密性の高い患者データを物理的に分離することでコンプライアンスが簡素化されます。
同様に、臨床研究テナントについても、コストが高くてもドメインベースの分離を検討してください。研究ワークロードはリソースを大量に消費する性質があり、特にゲノミクスや集団健康分析はテラバイト規模のデータを複雑なアルゴリズムで処理するため、個別のドメインを使用することで、負荷の高い操作が他のテナントに影響を与えることを防ぎます。
循環器科や放射線科などの専門部門では、ワークロードパターンは似ていますがデータアクセスパターンが異なるため、インデックスベースの分離が適しています。専門部門はドメインを共有しますが、個別のインデックスを維持します。インデックスベースの分離は、より効率的なリソース利用を可能にしながら、強力な論理的分離を実現します。
データの機密性が低い管理部門では、ドキュメントベースの分離で十分であり、複数のテナントが同じインデックスを共有できます。
データモデリング
マルチテナントヘルスケアシステムでパフォーマンスと管理性を維持するには、データモデリングが重要です。テナント識別子、データカテゴリ、期間を組み込んだ一貫したインデックス命名規則 ({tenant-id}-{data-type}-{time-period} など) を実装してください。Tenant-id はエンティティを識別します (例: cardiology)。インデックスの例としては、cardiology-ecg-202505 や radiology-mri-202505 があります。構造化されたアプローチにより、データ管理、アクセス制御、ライフサイクルポリシーが簡素化されます。
インデックス戦略を設計する際は、データアクセスパターンを考慮してください。たとえば、バイタルサインやテレメトリ読み取り値などの時系列データの場合、適切なローテーションポリシーを持つ時間ベースのインデックスにより、パフォーマンスが向上し、データライフサイクル管理が簡素化されます。
ドキュメントベースの分離を使用する共有インデックスの場合、効率的なテナントベースのフィルタリングのために、テナント識別子が一貫して適用され、インデックス化されていることを確認してください。
テナント管理
テナント管理により、リソースの競合を防ぎ、ヘルスケアシステム全体で一貫したパフォーマンスを実現できます。重要度に基づくテナント階層化フレームワークを使用して、ハイブリッド分離モデルを実装してください。次の表は階層化フレームワークの概要です。
| 階層 | テナントタイプ | SLA | リソース | 運用制限 | 動作 |
| Tier-1 クリティカル |
救急部門 ICU/集中治療 手術室 |
24 時間 365 日 SLA 99.99% 1 秒以内のレスポンス RPO: ほぼゼロ RTO: 15 分未満 |
CPU 50%、メモリ 50% を保証 専用ホットノード 最低 2 レプリカ |
同時リクエスト 100 リクエストサイズ 20 MB タイムアウト 30 秒 スロットリングなし |
優先クエリルーティング 先行スケーリング 自動フェイルオーバー |
| Tier-2 緊急 |
入院病棟 専門部門 放射線科/画像診断 |
24 時間 365 日 SLA 99.9% 可用性 レスポンスタイム 2 秒未満 RPO: 15 分未満 RTO: 1 時間未満 |
CPU 30%、メモリ 30% を保証 共有ホットノード 1〜2 レプリカ |
同時リクエスト 50 リクエストサイズ 15 MB、タイムアウト 60 秒 ピーク時の限定的なスロットリング |
高優先度クエリルーティング 自動スケーリング 自動リカバリ |
| Tier-3 標準 |
外来クリニック プライマリケア 薬局 検査室 |
営業時間 SLA (8 AM〜8 PM) 99.5% 可用性、レスポンスタイム 5 秒未満 RPO: 1 時間未満 RTO: 4 時間未満 |
CPU 15%、メモリ 15% を保証 共有ノード 1 レプリカ |
同時リクエスト 25 リクエストサイズ 10 MB タイムアウト 120 秒 中程度のスロットリング |
標準クエリルーティング 公平なスレッド割り当て 手動スケーリング 営業時間最適化 |
| Tier-4 研究 |
臨床研究 ゲノミクス 集団健康 |
ベストエフォート SLA、最大 99% 可用性 レスポンスタイム 30 秒未満 RPO: 24 時間未満 RTO: 24 時間未満 |
CPU 5%、メモリ 10% を保証 オフピーク時のバースト容量 0〜1 レプリカ |
同時リクエスト 10 リクエストサイズ 50 MB タイムアウト 300 秒 ピーク時の積極的なスロットリング |
コンピューティング最適化インスタンス 大容量ヒープサイズ 研究専用プラグイン |
| Tier-5 管理 |
請求/財務 人事システム 在庫管理 |
営業時間 SLA (9 AM〜5 PM) 99% 可用性、レスポンスタイム 10 秒未満 RPO: 24 時間未満 RTO: 48 時間未満 |
リソース保証なし バースト可能な容量 履歴データ用 UltraWarm 1 レプリカ |
同時リクエスト 5 リクエストサイズ 5 MB タイムアウト 180 秒 積極的なスロットリング |
最低優先度クエリルーティング バッチ処理推奨 オフピーク時スケジューリング コスト最適化ストレージ |
ワークロード管理
マルチテナント環境で OpenSearch Service を使用する場合、各テナントがデータを取り込み、保存、クエリするために必要なリソースを確保できるよう、テナントのワークロードのバランスを取る必要があります。ルールベースのプロキシと OpenSearch Service ワークロード管理を組み合わせた多層ワークロード管理フレームワークにより、ワークロード管理の課題に対処できます。詳細については、ブログ記事「Workload management in OpenSearch-based multi-tenant centralized logging platforms」を参照してください。
セキュリティフレームワーク
ヘルスケアデータは、その機密性と規制要件のため、保護が必要です。OpenSearch Service セキュリティフレームワークは、ヘルスケアの厳格なセキュリティ要件に適応できるよう設計されています。セキュリティフレームワークは、次の図のように、複数のアクセス制御レイヤーを組み合わせています。
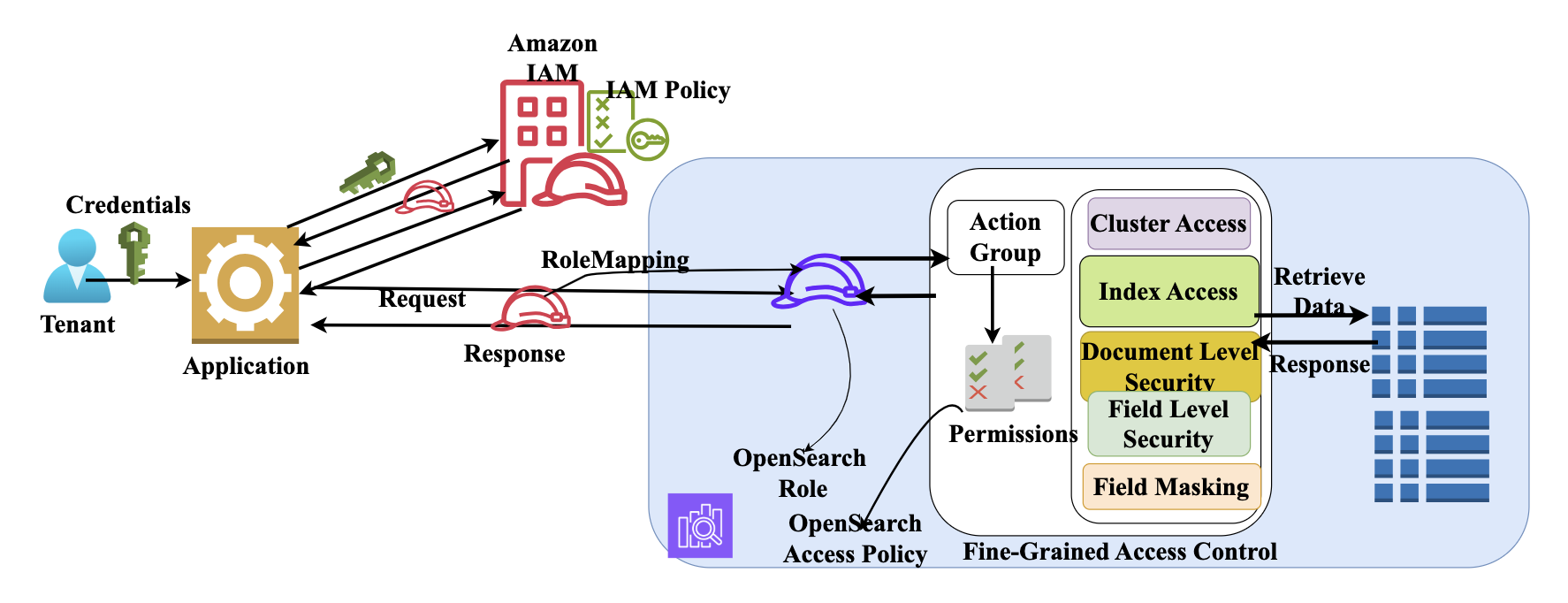
Amazon OpenSearch Service のマルチテナントきめ細かなアクセス制御
セキュリティフレームワークの重要なステップはロールマッピングです。ここでは、AWS Identity and Access Management (IAM) ロールがロールベースのアクセス制御 (RBAC) のために OpenSearch ロールにマッピングされます。たとえば、救急部門では、部門間の患者履歴にアクセスできる ED-Physician ロールと、バイタルサインと投薬データにアクセスできる ED-Staff ロールを設定できます。救急部門のロールを OpenSearch ロールにマッピングできます。
ドキュメントレベルセキュリティ (DLS) を使用すると、救急部門のスタッフをアクティブな救急患者のみに制限し、退院した患者のデータへのアクセスを担当医師のみに制限できます。フィールドレベルセキュリティ (FLS) を使用すると、医療フィールドへのアクセスを許可しながら、請求および保険データをマスキングできます。また、患者のステータスに基づいてアクセスを許可する属性ベースのアクセス制御 (ABAC) ポリシーを設定することもできます。
研究部門では、データセットへの読み取り専用アクセス権を持つ Clinical-Researcher ロールを作成できます。学術ロールを研究ロールに統合して、研究者が承認された研究のデータのみにアクセスできるようにします。DLS では、研究者が承認されたドキュメントのみにアクセスできるようにフィルターを設定します。FLS を使用して HIPAA 識別子を匿名化します。研究部門の ABAC では、研究フェーズと研究者の所在地を評価する必要があります。
外来ケアでは、担当患者の記録への完全なアクセス権を持つ Medical-Provider ロールと、バイタルと予備情報の記録に限定された Medical-Assistant ロールを定義できます。DLS では、患者の担当医師のみにアクセスを制限します。FLS では、医療データのみへのアクセスを制限し、看護師は人口統計、バイタルサイン、投薬フィールドに制限します。営業時間外の患者記録へのアクセスを制限する時間認識 ABAC ポリシーを設定します (オンコールのプロバイダーを除く)。
管理部門では、請求コードと保険情報へのアクセス権を持ち、臨床データへのアクセス権を持たない Financial ロールを設定できます。DLS では、財務スタッフが請求ドキュメントのみにアクセスできるようにします。FLS では、臨床コンテンツをマスキングしながら、請求コード、サービス日、保険フィールドへのアクセスを許可します。
専門部門では、Radiologist などの技師ロールを作成し、技師と紹介医師にデータへのアクセスを制限する DLS フィルターを適用できます。FLS により、技師は専門分野に固有の臨床履歴と以前の所見を確認できます。
保護された医療情報へのアクセスを追跡するために、監査ログを有効にしてください。監査ログは、ユーザー ID、アクセスされたデータ、タイムスタンプ、アクセスコンテキストをキャプチャするように設定します。監査証跡は、規制遵守とセキュリティ調査に不可欠です。
コンプライアンスのためのデータライフサイクル管理
Index State Management (ISM) 機能と OpenSearch Service のストレージ階層化を組み合わせることで、多様なテナントのニーズに合わせてカスタマイズできる高度なデータライフサイクル管理アプローチが可能になります。ISM は、インデックスの経過時間やサイズなどの基準に基づいて Hot、UltraWarm、Cold ストレージ階層間の移行を指示するポリシーを定義することで、インデックスのライフサイクルを自動化する方法を提供します。この自動化は、スナップショットを作成することでアーカイブ階層に拡張できます。スナップショットは Amazon Simple Storage Service (Amazon S3) に保存され、アクセス頻度の低いデータの長期的でコスト効率の高いアーカイブのために Amazon S3 Glacier または Glacier Deep Archive にさらに移行できます。
ISM ポリシーは次のガイドラインに沿って策定してください。
重要な患者データは、即時アクセスをサポートするために 180 日間ホットストレージに保持します。次の 12 か月間はウォームストレージに移行し、その後 2〜7 年目はコールドストレージに移動します。7 年後にレコードをアーカイブします。
研究データの場合は、厳密に時間ベースの移行ではなく、プロジェクトベースのライフサイクルポリシーを使用すると有効です。アクティブなプロジェクトフェーズ中は、データの経過時間に関係なく、研究データセットをホットストレージに維持します。プロジェクトが終了したら、データを 12 か月間ウォームストレージに移行します。研究の重要性に基づいて、その後 5〜10 年間コールドストレージに移動します。その後、レコードをアーカイブします。
外来クリニックデータの場合は、最近の患者記録を 90 日間ホットストレージに保持し、インデックスのロールオーバーを一般的なフォローアップ期間に合わせます。4〜18 か月目はウォームストレージに移行し、一般的な年次受診パターンに合わせます。2〜7 年目はコールドストレージに移動します。7 年後にアーカイブします。
管理データの場合は、現在の会計年度のデータをホットストレージに維持し、年度末の境界で自動移行を行います。前会計年度のデータは、監査とレポートをサポートするために 18 か月間ウォームストレージに移動します。3〜7 年目はコールドストレージに移行します。7 年後に財務記録をアーカイブします。
専門部門データの場合は、最近のメタデータを 90 日間ホットストレージに保持し、画像などの大きなファイルは 30 日後にウォームストレージに移動します。18 か月後に完全なレコードをコールドストレージに移行します。7 年後にアーカイブします。
コスト管理と最適化
ヘルスケア組織は、パフォーマンス要件と予算の制約のバランスを取る必要があります。持続可能な運用には、コスト管理戦略が不可欠です。
インデックス命名規則を反映したタグ付け戦略を導入して、リソース管理とコスト追跡への統一されたアプローチを作成してください。インデックス命名規則と同様に、テナント、アプリケーション、データタイプを識別するようにタグを設計します (例: “tenant=cardiology” や “application=ecg“)。タグを AWS Cost Explorer と組み合わせることで、組織の境界を越えた費用の可視性が得られます。
異なるテナント間で費用を公平に配分するコスト配分メカニズムを開発してください。データ量、クエリの複雑さ、サービスレベル保証に基づく階層型料金体系の導入を検討してください。タグ付けにより、コストと価値が一致し、効率的なリソース利用が促進されます。
テナント固有のメトリクスと使用パターンに基づいてインフラストラクチャを最適化してください。ドキュメント数、インデックス作成レート、クエリパターンを監視して、クラスターとノードタイプを適切にサイジングします。異なるワークロードには異なるインスタンスタイプを使用してください。たとえば、クエリ集約型アプリケーションにはコンピューティング最適化インスタンスを使用します。
OpenSearch Service のストレージ階層化を使用してコストを最適化してください。UltraWarm は、アクセス頻度の低いデータに対して、適切なクエリパフォーマンスを維持しながら大幅なコスト削減を実現します。コールドストレージは、アクセス頻度は低いがコンプライアンス目的で保持する必要があるデータに対して、さらに大きな節約を実現します。
まとめ
OpenSearch Service でマルチテナントヘルスケアシステムを構築するには、慎重な計画と実装が必要です。テナント分離、セキュリティ、データライフサイクル管理、ワークロード制御、コスト最適化に対処することで、ヘルスケア規制への厳格なコンプライアンスを維持しながら、運用効率を向上させるプラットフォームを構築できます。
著者について
 Ezat Karimi は、テキサス州オースティンを拠点とする AWS のシニアソリューションアーキテクトです。データベースアプリケーションのモダナイゼーションソリューションと戦略の設計と提供を専門としています。複数の AWS チームと緊密に連携し、お客様のデータベースワークロードの AWS クラウドへの移行を支援しています。
Ezat Karimi は、テキサス州オースティンを拠点とする AWS のシニアソリューションアーキテクトです。データベースアプリケーションのモダナイゼーションソリューションと戦略の設計と提供を専門としています。複数の AWS チームと緊密に連携し、お客様のデータベースワークロードの AWS クラウドへの移行を支援しています。
 Jon Handler は、カリフォルニア州パロアルトを拠点とする Amazon Web Services のシニアプリンシパルソリューションアーキテクトです。OpenSearch と Amazon OpenSearch Service に深く関わり、ベクトル、検索、ログ分析のワークロードを AWS クラウドに移行したいお客様に幅広くサポートとガイダンスを提供しています。AWS 入社前は、ソフトウェア開発者として大規模な e コマース検索エンジンのコーディングに 4 年間従事していました。ペンシルベニア大学で学士号を、ノースウェスタン大学でコンピュータサイエンスと人工知能の修士号と博士号を取得しています。
Jon Handler は、カリフォルニア州パロアルトを拠点とする Amazon Web Services のシニアプリンシパルソリューションアーキテクトです。OpenSearch と Amazon OpenSearch Service に深く関わり、ベクトル、検索、ログ分析のワークロードを AWS クラウドに移行したいお客様に幅広くサポートとガイダンスを提供しています。AWS 入社前は、ソフトウェア開発者として大規模な e コマース検索エンジンのコーディングに 4 年間従事していました。ペンシルベニア大学で学士号を、ノースウェスタン大学でコンピュータサイエンスと人工知能の修士号と博士号を取得しています。
この記事は Kiro が翻訳を担当し、Solutions Architect の 榎本 貴之 がレビューしました。