AWS Partner Network (APN) Blog
Storing Multi-Tenant SaaS Data with Amazon OpenSearch Service
By Madhukar Thumma, Manager, Partner Solutions Architect – AWS SaaS Factory
By Ujwal Bukka, Sr. Partner Solutions Architect – AWS SaaS Factory
Amazon OpenSearch Service is frequently used by software-as-a-service (SaaS) providers to address a broad range of use cases. The use of Amazon OpenSearch Service in a multi-tenant environment, however, introduces a collection of new considerations that will influence how you partition, isolate, deploy, and manage your solution.
You’ll have to consider how to effectively scale your OpenSearch Service clusters with continually shifting workloads. You’ll need to think about how tiering and noisy neighbor conditions could impact your partitioning model.
In this post, we’ll explore the strategies and patterns that are used to address these common multi-tenant issues. We’ll look at the specific models used to represent and isolate each tenant’s data with Amazon OpenSearch Service constructs.
Data Partitioning Models in a Multi-Tenant System
When you look at storing multi-tenant data in any database, think about how you’ll partition the tenant data. There are three common data partitioning models used in multi-tenant systems: silo, pool, and hybrid. The model you choose will vary based on the compliance, noisy neighbor, operations, and isolation needs of your solution.
Silo Model
You can choose this model if your tenants want their data and resources to be separated from other tenants because of compliance or regulatory or data separation requirements. In these cases, you’ll create a separate set of resources specific to a tenant.
In the silo model, you store each tenant’s data in a distinct storage where there is no commingling of tenant data. There are multiple ways you can implement silo model with Amazon OpenSearch Service. The following is a breakdown of the silo options:
- Domain per tenant: You can implement a silo model with OpenSearch Service by having a separate domain (synonymous with an OpenSearch cluster) per tenant. By placing each tenant in their own domain, you’ll get all of the benefits associated with having your data in a standalone construct. This approach provides a natural way to address issues like noisy neighbor, where one tenant may impose a load that could adversely affect the experience of other tenants.
.
While domain per tenant has strengths, it also introduces management and agility challenges. The distributed nature of this model makes it harder to aggregate and assess the operational health across all tenants and activity of tenants. Deployment also becomes more challenging. Updates, like scaling up or scaling down the cluster of each domain, must be applied separately to each domain, and onboarding now requires the provisioning of a separate domain as you add each tenant to the system.

Figure 1 – Data access flow in domain per tenant model.
The figure above shows the basic flow of how to implement a domain per tenant model. Let’s inspect what’s happening at each step:
-
- Our application microservice receives a request from a tenant.
- Our microservice can use an AWS Identity and Access Management (IAM) role with polices that restrict access to a tenant-specific domain.
- Our microservice can query a database table which holds the tenant’s Amazon OpenSearch Service domain information and then sends the request to that tenant-specific OpenSearch Service domain to perform the requested operation. If the tenant has necessary permissions, OpenSearch Service performs the requested operation on the indices and returns the results to the calling microservice.
- The results are sent back to the client.
- Tenant isolation for domain per tenant silo model: IAM policies are used to isolate the domains that hold each tenant’s data. These policies prevent one tenant from accessing another tenant’s data. To implement your domain per tenant silo isolation model, you can create a resource-based policy that controls access to your tenant resource. This is often a domain access policy that specifies which actions a principal can perform on the domain’s sub-resources, including OpenSearch indices and APIs.
.
This domain access policy accepts or rejects requests at the “edge” of the domain. If the request is accepted, then based on fine-grained access control configuration, the request is evaluated and authenticated.
The code snippet below shows a sample resource-based policy used to isolate a tenant to their respective domain when you implement the “domain per tenant” silo strategy. The “Principal” element specifies the role of tenant; in our case, “tenant-role-1”. The “Allow” effect grants “Tenant-1” to get and post access (es:ESHttpGet, es:ESHttpPost) to the sub-resources on “tenant-1 domain” only.
.
The trailing “/*” in the resource element shows this policy applies to the domain’s sub-resources, not the domain itself. With this policy in effect, tenants are not only restricted to this domain but are not allowed to create a new domain or change settings on an existing domain.
- Index per tenant: Tenant data can also be stored in a silo model by placing tenant data in separate indexes within an Amazon OpenSearch Service domain. With this approach, you use a tenant identifier when creating and naming the index. It’s advised to have a database table to hold tenant index information, such as index name and cluster name. Having this database table provides you the flexibility in moving tenant indices and/or have multiple indices per tenant.
.
The index per tenant model can allow you to achieve your silo goals without introducing a completely separate domain for each tenant. At the same time, it still provides the isolation that silo requires and tuning the index for each tenant tier. This strategy simplifies the cluster management, often improving the overall agility of your multi-tenant system.
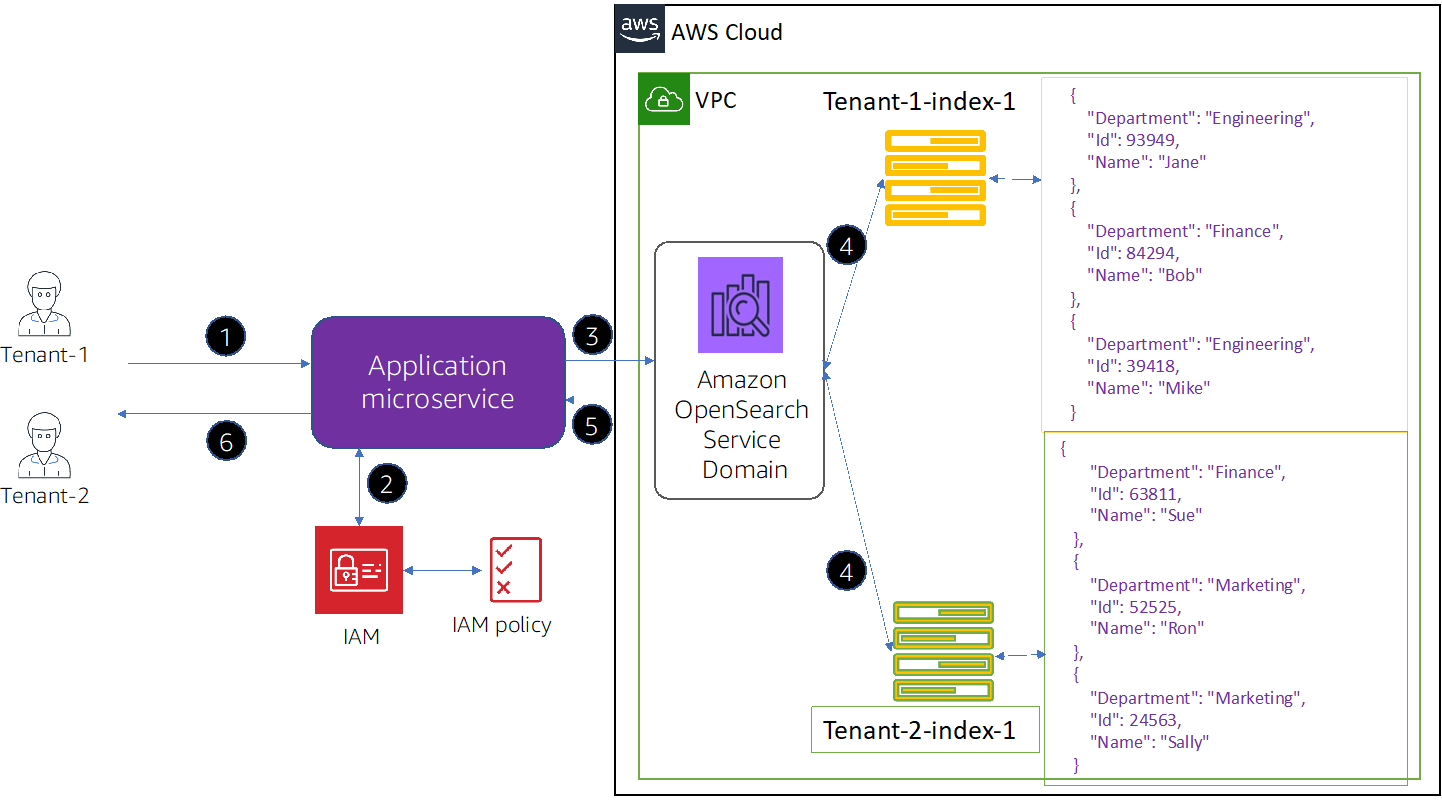
Figure 2 – Data access flow in index per tenant model.
The figure above shows the basic flow of an index per tenant model. When compared to the domain per tenant model, you will create index per tenant under the same Amazon OpenSearch Service domain.
.
Based on your performance requirements, there are recommendations on how many OpenSearch indices you can create for an Amazon OpenSearch Service domain. Each OpenSearch index is divided into one or more shards. The total number of shards you can create inside your OpenSearch Service domain depends on the number of nodes in the cluster, node instance size, and shard size. It’s recommended to keep the total number of shards in any OpenSearch Service domain to less than 30,000 and OpenSearch 7.x and later have a limit of 1,000 shards per node.
.
The number of shards and shard size affects the performance of the OpenSearch Service domain. The shard size should be small enough that the underlying OpenSearch Service instance can handle them, but not so small they place a needless strain on the hardware. Refer to the AWS documentation on choosing the number of shards for more detailed information on this topic.
.
Given these considerations, you might cap how many indices you can create inside your OpenSearch Service domain. So, the index per tenant model may not be suitable if you have hundreds and thousands of tenants. Also, if you have small-sized tenants, having a dedicated index per tenant will lead to resource under-utilization.
- Tenant isolation for index per tenant silo model: IAM policies can be used to isolate the indices that hold each tenant’s data. To implement the tenant isolation for the “tenant per index” silo model, you’d need to change the resource policy defined in this post’s earlier code snippet to further restrict the “Tenant-1” to the specified index or indices, by specifying the index name.
.
The code below shows a sample resource policy which restricts “Tenant-1” to “tenant-index-1” index only.
The preferred approach here is to implement tenant isolation for index per tenant silo model is by using fine-grained access control (FGAC) supported by OpenSearch Security plugin to restrict a tenant to a specified index or indices. FGAC allows you to control permissions at an index, document, or field level (Since OpenSearch 6.7). It achieves this through role mapping, as you can map IAM users/roles or OpenSearch users to OpenSearch roles with desired permissions.
.
With each request, FGAC evaluates the user credentials and either authenticates the user or denies the request. If FGAC authenticates the user, it fetches all roles mapped to that user and uses the complete set of permissions to determine how to handle the request.
.
To achieve the required isolation in the index per tenant silo model, you can make use of FGAC’s index permissions to restrict a specific users/roles to a specific index of the tenant.
Pool Model
You can choose this model if your tenants are OK having their data commingled with other tenants’ data and to use shared resources. This model reduces the management overhead and improves the operational model.
In the pool model, all of your tenant data is stored in a shared index (within the same domain). By introducing the tenant identifier into the data (document), you can determine which data belongs to which tenant.
With the tenant data commingled within the same index, you lose the natural tenant isolation that came with the silo model. This also affects the noisy neighbor profile of your application. You can use FGAC to implement isolation in pool model.
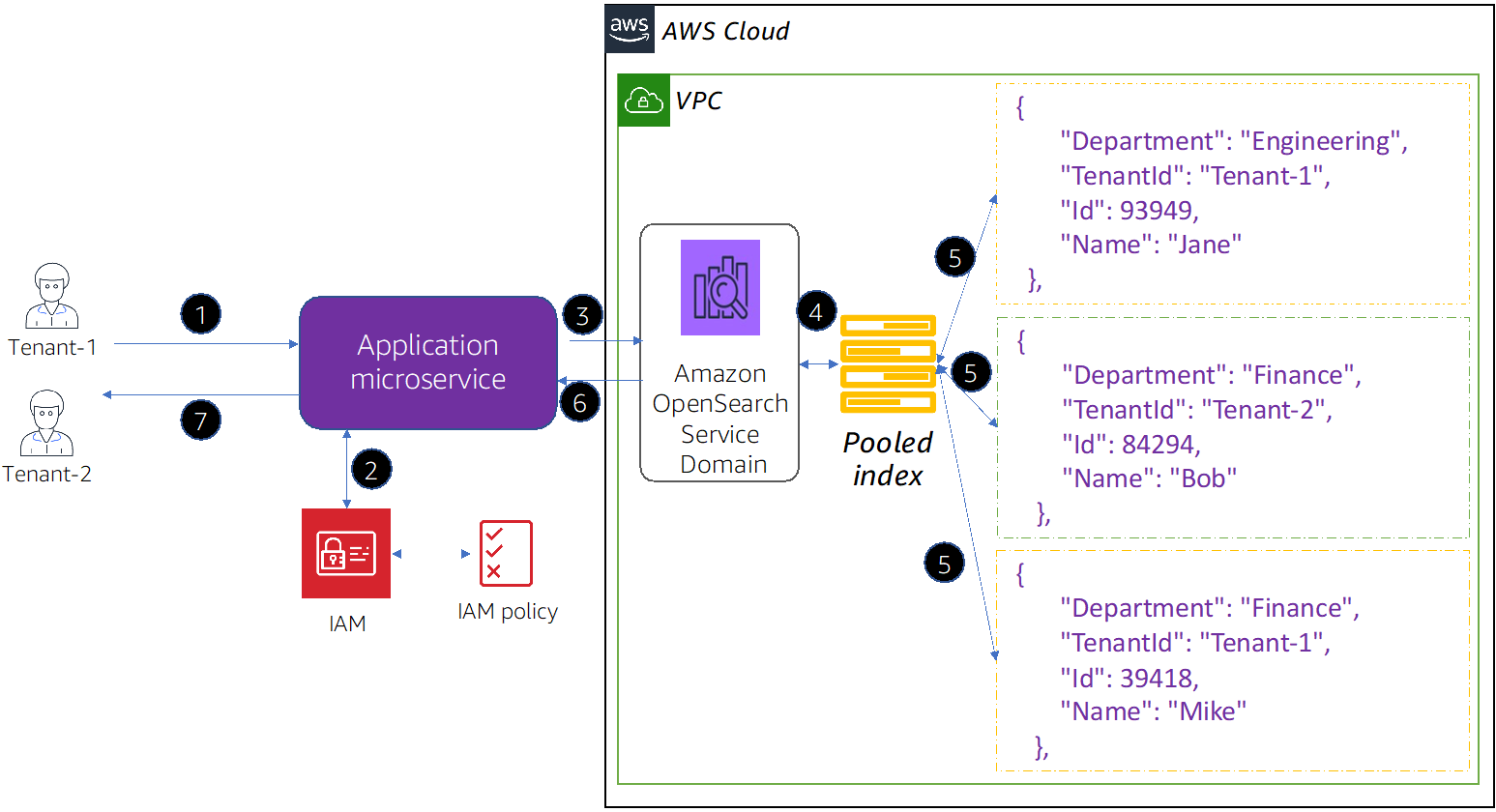
Figure 3 – Data access flow in pooled model.
In the figure above, you’ll notice there is only one pooled index created under an Amazon OpenSearch Service domain and the tenantId has been added to each document in the pooled index. Based on request operation and fine-grained access controls, Amazon OpenSearch Service restricts the results.
If you plan to onboard tens of thousands of tenants using this approach, you need to scale this approach to a multiple Amazon OpenSearch Service clusters where you can have multiple pooled indices with tenant documents. Then, you need to introduce a database table which will hold tenant index information such as pooled index name and cluster name. The application microservice can query this database table to get tenant index information and direct the tenant request to the cluster, pooled index under which tenant documents are created.
- Tenant isolation in pool model: The IAM mechanism used with the silo model does not allow you to describe isolation based on the tenantId stored in your document. You need to use FGAC supported by OpenSearch Security plugin to implement tenant isolation.
.
To achieve the required isolation in the pool model, you make use of FGAC’s document-level security, which lets you restrict a role to a subset of documents in an index. The sample role in the code below restricts the queries to tenant id “Tenant-1”. By applying this role to the Tenant-1, you achieve the isolation.
In pool model where tenants are sharing resources, as your tenants grow in both data and traffic, you may run into what we call a noisy neighbor issue, where one tenant is consuming all of the resources and degrading the performance for other tenants. To address this concern, you can scale up (scale vertically) by adding more memory and vCPUs with bigger node types to the cluster, or scale out (scale horizontally) by adding additional nodes.
.
You can also use index alias (a virtual index name that can point to one or more indices) as a scaling mechanism for shared pooled index. You’d have to define an alias for the shared pooled index and as tenants grow; if you need more indices, you can add them under this alias.
.
Another option to consider is to reindex tenant data or move tenant data into its own index or domain. For implementing this option, you can use a database table to hold tenant index information such as index name, cluster name, and read and write flags which allow or deny read and/or write operations on tenant data on the index.
.
When an application wants to access a tenant data, it can query this table to get tenant index name, cluster on which it is, whether read and/or write is enabled/disabled, and then route/allow the request accordingly.
.
When you want to reindex tenant data, you can disable write flag and allow only reads, and then you can reindex from the source tenant’s data to a different index or to a different cluster and finally update the database table with new index information for the tenant and enable write flag. If you have an update request while the write flag is disabled, you can put that request in a queue and process it once the write flag is enabled. Refer to this video to understand this approach in more detail.
Hybrid Model
It’s not uncommon to find SaaS solutions that rely on a combination of silo and pool models. There are several factors that may shape how/when you leverage silo and pool in the same environment.
Some SaaS solutions offer unique experiences to each tier of tenant such as Free, Standard, and Premium. You could use the hybrid model to offer unique experiences to each tier. For example, all of your Free tier tenant data could live in shared indices (pool model), while your Standard tier tenants align with index per tenant and Premium tier tenants could be given their own domain.
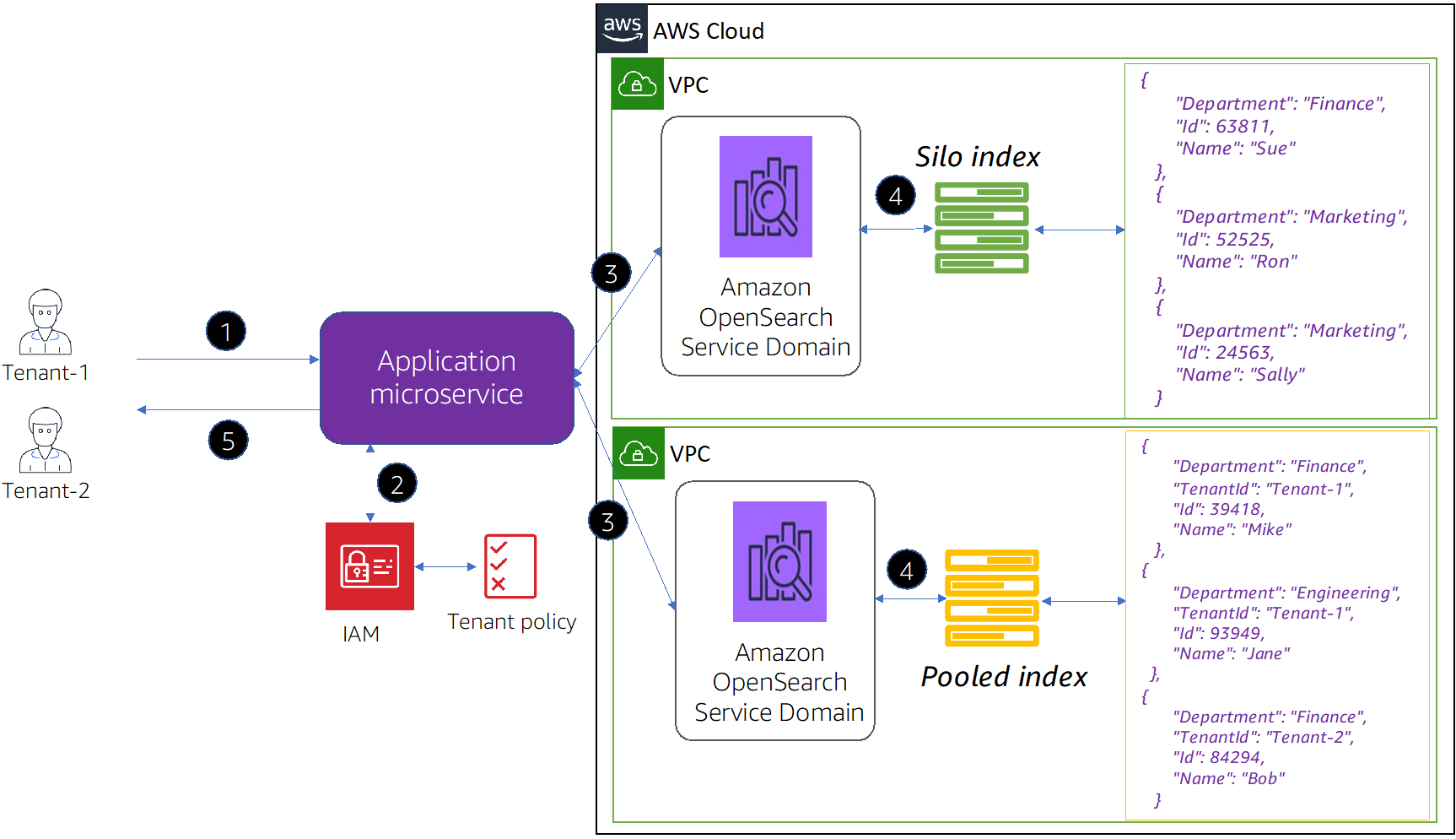
Figure 4 – Data access flow in hybrid model.
- Tenant isolation in the hybrid model: In the hybrid model, for silo tenants you’d use domain access policy and/or FGAC to implement tenant isolation as described above. For pooled tenants, you’d follow the same security profile that was described earlier in this post as well, where you achieve tenant isolation using the FGAC security model at the document-level.
.
While this strategy simplifies cluster management and offers agility, it complicates other aspects. For example, you have now introduced additional complexity into your code to determine which model is associated with each tenant.
OpenSearch Dashboards
Amazon OpenSearch Service provides an installation of OpenSearch dashboards with every OpenSearch Service domain. You can implement multi-tenancy in OpenSearch dashboards, and the dashboards multi-tenancy is distinct from the data tenancy we discussed in this post.
Tenants in OpenSearch dashboards are spaces for saving index patterns, visualizations, dashboards, and other OpenSearch dashboards objects. To control access to objects in these tenant space, you can use FGAC and define roles for tenants with specific cluster permissions, index permissions (index pattern from where you can read/write data), and tenant permissions (tenant pattern where you can read/write visualizations, dashboards, and other OpenSearch Dashboards objects).
For more insights on this topic, refer to the AWS documentation on OpenSearch dashboards multi-tenancy. Amazon OpenSearch Service offers various ways to control access to OpenSearch dashboards; learn more about controlling access to OpenSearch dashboards.
Conclusion
In this post, we looked at some key SaaS strategies you must consider when building a multi-tenant solution using Amazon OpenSearch Service.
It’s important to note there is no single preferred model for the solutions that are outlined in this post. Each variation outlined highlights some of the natural tension that exists in SaaS design. In picking a partitioning strategy, you must balance the simplicity and agility of a fully shared model with the security and variability offered by more isolated models.
Amazon OpenSearch Service supports all of the mechanisms you’ll need to implement each of the common partitioning models. As you dig deeper into OpenSearch Service, you’ll find it aligns nicely with many of the core SaaS values.