Amazon Web Services ブログ
新しい Amplify AI Kit で、フルスタックの AI アプリを数分で構築
2024 年 11 月 29 日、私たちはフルスタックの開発者が会話型検索やチャット、要約などの AI 機能を備えたウェブアプリを構築する最も早い方法である、AWS Amplify AI Kit の一般提供を開始しました。Amplify AI Kit を使えば、クラウドアーキテクチャや機械学習の経験がなくても、フルスタックの生成 AI 機能を構築することができます。リソースのプロビジョニングやセキュアなフロントエンドへのアクセスを心配する必要はなく、すべてがサーバーレスなので迅速なイテレーションが可能で、使った分だけの料金を支払えば済みます。
AWS Amplify では TypeScript を全面採用しており、Amplify Gen 2 の場合、アプリのクラウドバックエンドのすべての部分が TypeScript で定義されています。認証バックエンド、データバックエンド、ストレージバックエンド、生成 AI 、これら全てを TypeScript で定義することができるのです。
このブログでは、Amplify AI Kit の中身とそれが Amplify および Amazon Bedrock を使って安全なフルスタック AI アプリケーションを構築する作業をどのように簡素化するかについて説明します。すぐに始めたい場合は、入門ガイドまたはサンプルリポジトリをご覧ください。
セットアップ
ローカル開発用にセットアップ済みの AWS アカウントが必要で、使用したい Amazon Bedrock の基盤モデルにアクセスできる権限が必要です。Amazon Bedrock コンソールに移動してアクセス権を要求できます。
フロントエンドのプロジェクトがセットアップされていない場合は、Next.js または Vite を使ってセットアップできます。その後、プロジェクトディレクトリ内で create amplify スクリプトを実行してください。
npm create amplify@latest次のコマンドを実行すると、TypeScript で書かれたバックエンド定義が含まれる amplify フォルダが作成されます。
npx ampx sandboxこれにより、Amplify サンドボックスが起動し、実際の AWS リソースを使ってテストできるクラウド サンドボックス環境が用意されます。
AI 機能の追加
Amplify AI Kit に AI 機能を追加するには、データモデルやカスタムクエリと同様に、Amplify データスキーマに AI ルートを定義します。AI ルートは、バックエンドの AI 機能と対話するための API エンドポイントのようなものです。現在、AI ルートには 2 種類あります。
- Conversation: Conversation ルートはリアルタイム、マルチターンの API です。会話とメッセージは自動的に DynamoDB に保存され、応答がリアルタイムにクライアントにストリーミングされます。チャットベースの AI エクスペリエンスや会話型 UI などがこれにあたります。
- Generation: シンプルなリクエスト・レスポンス API です。Generation ルートは、定義に従って構造化データを生成する AWS AppSync クエリです。一般的な用途は、非構造化入力から構造化データを生成したり、要約することです。
Amplify のデータリソース定義では、スキーマ定義内で AI ルートを定義できます:
import { a, defineData, type ClientSchema } from '@aws-amplify/backend';
const schema = a.schema({
// This will add a new conversation route to your Amplify Data backend.
chat: a.conversation({
aiModel: a.ai.model('Claude 3 Haiku'),
systemPrompt: 'You are a helpful assistant',
})
.authorization((allow) => allow.owner()),
// This adds a new generation route to your Amplify Data backend.
generateRecipe: a.generation({
aiModel: a.ai.model('Claude 3 Haiku'),
systemPrompt: 'You are a helpful assistant that generates recipes.',
})
.arguments({
description: a.string(),
})
.returns(
a.customType({
name: a.string(),
ingredients: a.string().array(),
instructions: a.string(),
})
)
.authorization((allow) => allow.authenticated()),
});
export type Schema = ClientSchema;
export const data = defineData({
schema,
authorizationModes: {
defaultAuthorizationMode: "userPool",
},
});ここでは、2 つの AI ルートを作成しています。1 つは ‘chat’ という名前の Conversation ルート、もう 1 つは ‘generateRecipe’ という名前の Generation ルートです。コードを 1 ステップずつ見ていきましょう。
chat: a.conversation({ここでは新しい「chat」という Conversation ルートを作成しています。ルートの名前は任意に付けられ、定義できる AI ルートの数の制限は、AWS AppSync スキーマのサイズの制限のみです。
aiModel: a.ai.model('Claude 3.5 Sonnet'),次に、使用したい大規模言語モデル (LLM) を定義します。Amplify AI Kit は、ツール使用とストリーミングをサポートする Bedrock の任意の LLM をサポートしています。ここでは、Anthropic の Claude 3.5 Sonnet モデルを使用しています。
systemPrompt: 'You are a helpful assistant',システムプロンプトは、LLM に対して、その役割と応答の仕方を指示します。
.authorization((allow) => allow.owner()),Amplify Data には組み込みの認証方式があります。Conversation ルートの場合、特定の会話の所有者のみがアクセスできるようにしたいと思います。つまり、ユーザーは他のユーザーの会話履歴にアクセスできません。
generateRecipe: a.generation({ここでは、generateRecipe と呼ばれる Generation ルートを作成しています。Generation は、入力に基づいて特定の型のデータを生成したい場合に使用する同期リクエスト/レスポンス API です。
.arguments({
description: a.string(),
})これにより、クライアントがレスポンスを受け取るためにどのような入力型を送る必要があるかを定義します。
.returns(
a.customType({
name: a.string(),
ingredients: a.string().array(),
instructions: a.string(),
})
)これが生成したいデータの出力形式です。
Conversation と Generation のルートが定義できたので、Amplify クライアントライブラリで接続できます。
リアルタイム更新機能付きの型安全クライアント
Amplify では、フルスタックアプリケーションのコードベースの中にある amplify フォルダにバックエンドリソースを定義します。これによって、データスキーマとフロントエンドクライアントが型を共有できるので、データスキーマと常に同期する型安全なクライアントを手に入れることができます。
import { generateClient } from "aws-amplify/api";
import type { Schema } from "../amplify/data/resource";
const client = generateClient();
// new generations / conversations namespace
client.generations.generateRecipe({ }); // type-safe based on schema
client.conversations.chat.create();Amplify AI Kit には、React フックも含まれているので、ネットワーク要求や UI の状態を管理する心配はいりません。UI にフックするだけで、リアルタイム、セキュア、永続的な生成 AI との会話を利用できます。
import { generateClient } from "aws-amplify/api";
import { Schema } from "../amplify/data/resource";
import { createAIHooks } from "@aws-amplify/ui-react-ai";
const client = generateClient();
const { useAIGeneration, useAIConversation } = createAIHooks(client);
function Chat() {
const [
{
data: { messages },
isLoading,
hasError,
},
sendMessage,
] = useAIConversation('chat');
//...
}
function RecipeGenerator() {
const [ { data, isLoading }, handleGenerate] = useAIGeneration('generateRecipe');
//...
}生成 AI をデータとして活用
データに適切なアクセスができることは、意味のある生成 AI 機能を構築するために重要であり、私たちはデータを LLM に接続することをできるだけ簡単にしたいと考えました。Amplify では、データモデルを厳密に型付けされたスキーマで定義し、生成 AI 機能を追加することは、データモデルやカスタムクエリを追加するのと同じくらい簡単です。TypeScript でデータモデルとクエリの形状を定義しているため、Amplify AI Kit は、Bedrock の LLM がアクセスできるデータとそのアクセス方法を正確に知ることができるように、必要な部分をフックアップします。さらに、データスキーマで定義されたアクセス制御により、LLM はエンドユーザーがアクセスできるデータにのみアクセスできます。すべてのデータリクエストは、クライアントからのリクエストでも LLM からのデータリクエストでも、AWS AppSync を経由します。
「Post」というデータモデルを持つアプリケーションがあると仮定します。このデータにアクセスするには、Conversation ルートにツールを使用します。
import { a, defineData, type ClientSchema } from '@aws-amplify/backend';
const schema = a.schema({
Post: a.model({
title: a.string(),
body: a.string()
})
.authorization((allow) => allow.owner()),
chat: a.conversation({
aiModel: a.ai.model('Claude 3 Haiku'),
systemPrompt: 'You are a helpful assistant',
// This allows the LLM to query for your data
tools: [
a.ai.dataTool({
name: 'PostQuery',
description: 'Searches for Post records',
model: a.ref('Post'),
modelOperation: 'list',
}),
]
})
.authorization((allow) => allow.owner()),
//...
});このコードを分解しましょう。
tools: [ツールは、LLM がデータを照会し、アクションを実行する手段です。Amplify AI Kit は、LLM へのリクエストでインプットを記述し、ツールの呼び出しと LLM への結果の送信を処理します。
a.ai.dataTool({
name: 'PostQuery',
description: 'Searches for Post records',
model: a.ref('Post'),
modelOperation: 'list',
}),LLM にスキーマで定義したデータモデルへのアクセスを提供できます。これにより、LLM はデータモデルの属性に基づいてレコードを照会できます。さらに所有者ベースの承認では、LLM はユーザーが作成したレコードにのみアクセスできます。LLM にカスタムクエリの呼び出しも許可できます!
サーバーレス AI アーキテクチャ
Amplify AI スタックはフルマネージドのサーバーレスです。すばやくスピンアップでき、Amplify サンドボックスを使えば、バックエンドのコードを反復しながら更新を実際のクラウド環境で確認できます。Amplify のサンドボックスを使うと、クラウドリソースにローカル開発環境を作れます。機能開発時にフロントエンドとバックエンドを同時に更新できるので、開発の分断なくエンドツーエンドの機能構築ができます。デプロイする準備ができたら、Amplify Hosting にブランチをプッシュすると、バックエンドとフロントエンドが同時にデプロイされます。
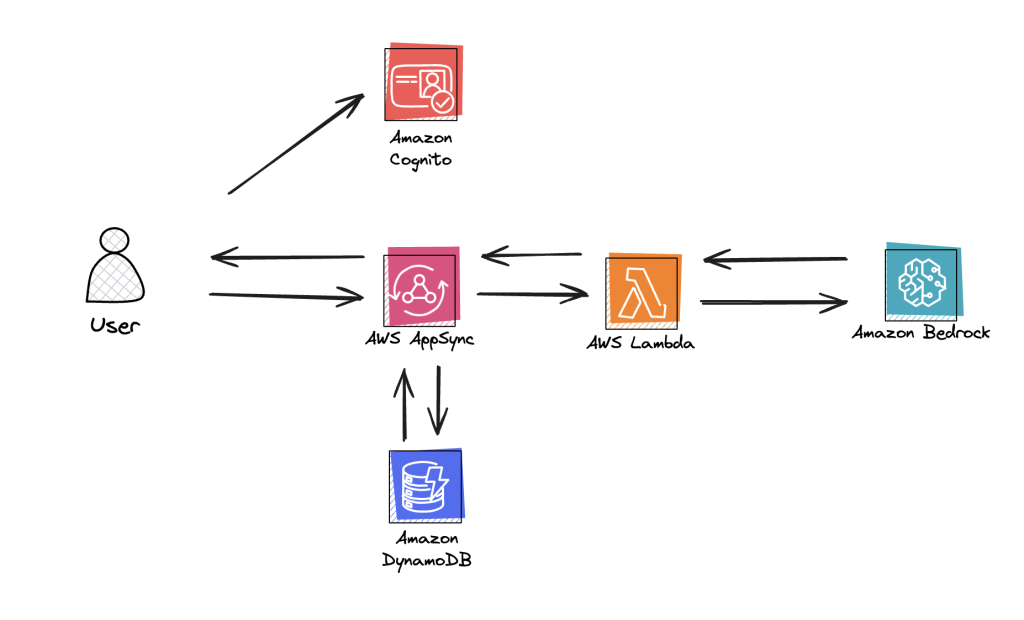
Amplify AI kit architecture
- AWS AppSync API: クライアントと安全にリアルタイム接続するための AI ゲートウェイ。AppSync API はハブとして機能し、すべてのデータリクエスト (クライアントまたは LLM からのリクエスト) が AppSync を通過します。
- Lambda 関数: AppSync と Amazon Bedrock の間の橋渡し役。会話履歴を取得し、Bedrock のストリーミング会話 API を呼び出し、AppSync クエリに基づきツールの呼び出しをハンドリングします。
- DynamoDB: 特定のアプリケーションユーザーに対する会話履歴とメッセージデータを保存します。
Generative UI の紹介
Amplify AI Kit でもう 1 つ行いたかったことは、生成 UI を構築することを簡単にすることでした。AI アシスタントが、テキストのみならず、カスタム UI コンポーネントで応答できるようにすることです。これにより、より豊かな体験が可能になり、会話型検索などの構築が可能になります。
Amplify AI Kit には、<AIConversation /> React コンポーネントと useAIConversation React フックが用意されており、カスタマイズ可能なインターフェースを AI ルートで簡単に構築できます。このコンポーネントには、AI アシスタントが応答可能な responseComponents (コードで定義した React コンポーネント) を指定できます。コンポーネントの説明と props を定義すれば、Amplify AI Kit が残りの処理を行います。
function Chat() {
const [
{
data: { messages },
isLoading,
},
sendMessage,
] = useAIConversation('chat');
return (
<AIConversation
messages={messages}
handleSendMessage={sendMessage}
isLoading={isLoading}
allowAttachments
responseComponents={{
WeatherCard: {
description: 'Used to display the weather of a given city to the user',
// any React component can be used
component: ({ city }) => {
return <Card>{city}</Card>;
},
props: {
city: {
type: 'string',
required: true,
},
},
},
}}
/>
);
}本番環境への移行
本番環境に移行する準備ができたら、Amplify コンソールで Git リポジトリを追加できます。ブランチにコードを push すると、フルスタックアプリケーション用の完全な継続的デプロイメントパイプラインが実行されます。アプリケーションが公開されると、アプリケーション内で会話データを確認できます。

クリーンアップ
Amplify サンドボックスコマンドは ctrl + c で終了できます。その後、npx ampx sandbox delete コマンドでクラウドサンドボックスリソースを削除できます。
まとめ
私たちは、Amplify AI Kit でみなさんが何を構築するのか非常に楽しみにしており、みなさんからのフィードバックを心待ちにしています。この 1 週間、毎日新しい記事を投稿し、Amplify AI Kit の異なる機能を紹介していきます。Amplify AI Kit の使用開始方法の詳細については、docs.amplify.aws/ai をご覧ください。
問題がある場合は、GitHub リポジトリでお問い合わせいただくか、私たちのコミュニティ Discord で質問してください。
本記事は「Build fullstack AI apps in minutes with the new Amplify AI Kit」を翻訳したものです。