Amazon Web Services ブログ
AWS でのブロックチェーンインデクサーの構築
分散型金融 (DeFi) の取引判断には、ブロックチェーンの価格と流動性データが必要です。
しかし、ブロックチェーンノードへの直接クエリは非効率的でリソースを大量に消費するため、タイムリーな意思決定のボトルネックとなります。
ブロックチェーンは効率的なデータクエリに最適化されておらず、データは順次 (ブロックごとに) 保存されています。
特定の情報を取得するには、多くの場合、ブロックチェーン全体をスキャンする必要があります。
インデクサーは、この問題に対するソリューションを提供します。
インデクサーは新しいブロックとトランザクションを監視し、最適化されたセカンダリデータベース (リレーショナルデータベースなど) にデータを保存するように設計できます。
これらのデータベースには、アプリケーションが直接クエリできる直接アクセス用のインデックスが含まれています。
インデクサーは、ブロックチェーンへの直接クエリと比較して高速な応答時間を提供し、過去および現在のブロックチェーンデータへの効率的なアクセスにより、DeFi アプリケーションのユーザー体験を向上させます。
ブロックチェーンインデクサーは広く利用可能ですが、既存のソリューションがブロックチェーンや必要なデータをサポートしていない場合、AWS 上にカスタムインデクサーを構築する必要があります。
本記事では、ブロックチェーンのシーケンシャルなデータ構造を DeFi アプリケーション向けに効率的にクエリできる形式に変換する、ブロックチェーンインデクサーの重要な役割とアーキテクチャについて説明します。
また、AWS 上でブロックチェーンインデクサーを構築するためのアーキテクチャガイダンスを提供します。
インデックス作成モード
ブロックチェーンインデクサーには 2 つの異なるモードがあり、それぞれ異なる要件が適用されます。
- バックフィル – 初回起動時、インデクサーはジェネシスから現在のヘッドまでのすべての履歴ブロックを並列プロセスで処理し、取り込み速度を最大化しています。ブロックチェーンデータは不変であるため、バックフィル中にチェーンのブロック再編成を考慮する必要はありません。
- フォワードフィル – このモードでは、インデクサーは新しいブロックを発見次第すぐに取り込みます。ただし、ブロック再編成によるブロックチェーン先端の変更により、以前のブロックが無効になる可能性があるため、セカンダリデータストアが実際のブロックチェーンデータと一貫性を保つためのメカニズムが必要です。
ソリューション概要
インデクサーがブロックチェーンノードから直接抽出し、変換ロジックが変更された場合、ブロックチェーン全体を再インデックス化する必要があります (これは時間がかかります)。
代わりに、1 回抽出し、必要に応じて複数回変換とロードを行う方法を提案します。
ブロックチェーンデータを保存する中間ストレージレイヤーを作成することで、変換処理はノードに繰り返しクエリを実行するのではなく、ローカルコピーに対して処理を実行できるようになります。
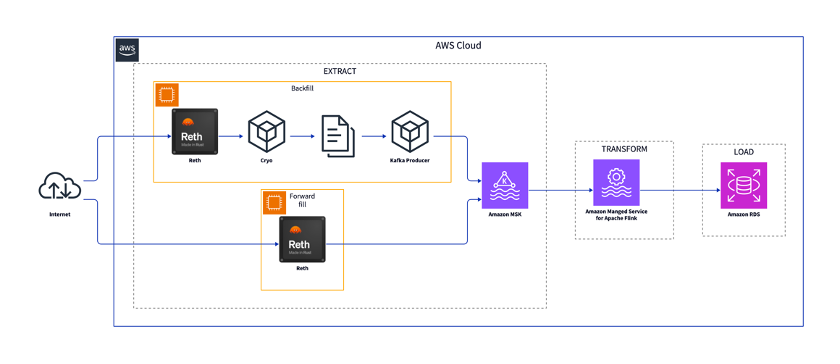
次の図は、インデクサーの主要なコンポーネントを示しています。
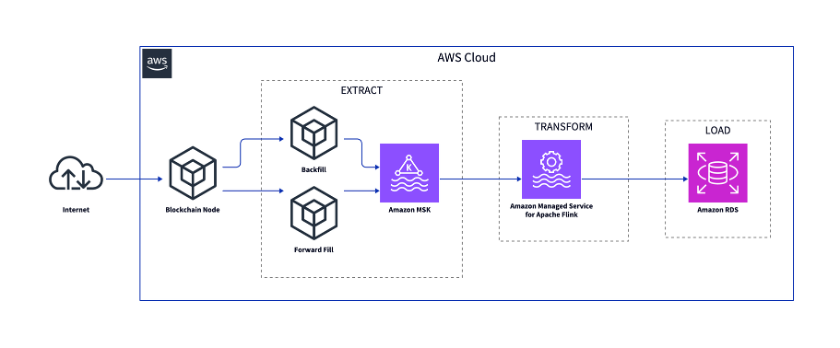
ブロックチェーンノードは Ethereum ブロックチェーンに接続されています。
バックフィル(過去データ取得)とフォワードフィル(新規データ取得)のコンポーネントは、ブロックチェーンノードからデータを取得します。
抽出後、データは中間ストレージとしての Amazon Managed Streaming for Apache Kafka (Amazon MSK) にロードされます。
データは Amazon Managed Service for Apache Flink で変換され、Amazon Relational Database Service (Amazon RDS) のようなデータベースにロードされます。
以下のセクションでは、抽出、変換、読み込み (ETL) プロセスについて詳しく説明します。
抽出
ブロックチェーンノードは、ブロックチェーン自体へのゲートウェイです。
すべてのブロックのローカルコピーを保持し、ブロックチェーンネットワークを通じて伝播される新しいブロックを受信します。
ブロックチェーンノードは、標準化された JSON-RPC 呼び出しを使用してクエリを実行できます。
ブロックチェーンのインデックス作成には、フルノードまたはアーカイブノードのいずれかが必要です。
フルノードはすべてのトランザクションを保持しますが、過去の状態データはプルーニングされます。一方、アーカイブノードは完全な状態履歴を保持します。
提案するアーキテクチャではアーカイブノードを前提としています。これは、フルノードを使用する場合、必要なデータがすべて含まれていることを検証する必要があるためです。
バックフィル
データ取り込みの最初のステップは、ブロックチェーンの開始時点 (ジェネシスブロック) からチェーンの最新ブロックまでの過去データの取り込みです。
この過去データの取り込みコンポーネントは、過去のブロックを処理し、関連データを抽出して、Apache Kafka トピックにプッシュします。
Amazon MSK は中間ストレージとして機能します。
これにより、データを保持しつつ、複数の独立したコンシューマーがデータを処理できます。
この例では、blocks、transactions、logs という 3 つの異なるトピックを使用し、それぞれのデータを保持します。
理論的には、バックフィリングコンポーネントは、インデクサーがゼロから開始する際に一度だけ実行する必要があります。
すべての履歴データを取り込んだ後は、フォワードフィリングコンポーネントのみが、Kafka トピックをブロックチェーンの最新状態と同期させるために必要となります。
しかし、バックフィリングコンポーネントを再実行する必要がある理由はさまざまです。最初の実行時に一部のデータが取りこぼされた可能性がある場合、転送先のデータスキーマの変更、または修正された ETL ロジックのバグなどが考えられます。
バックフィリングコンポーネントを再実行する可能性があるため、高速化に重点を置いています。
バックフィリングコンポーネントの一般的なアーキテクチャは、次の図のようになります。
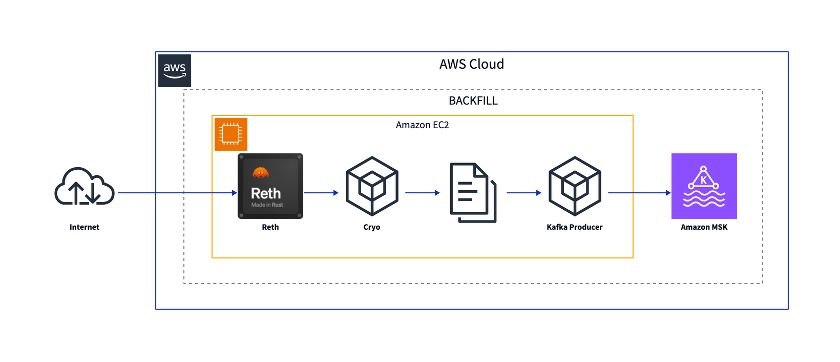
データ抽出には、Paradigm が開発したオープンソースの抽出エンジン cryo を使用します。
これは、並列的な RPC 呼び出しを使用してブロックチェーンノードからデータを抽出し、ローカルファイルとして保存します。その後、これらのファイルを Kafka トピックにプッシュできます。
バックフィル中、インデクサーはブロックチェーンノードにクエリを送信します。
スロットリングを回避し、クエリへの応答を確実にするために、専用ノードを使用することをお勧めします。
ネットワークレイテンシーを削減するために、このノードをインデクサーの近くに配置することをお勧めします。
サンプルアーキテクチャでは、単一の Amazon Elastic Cloud Compute (Amazon EC2) インスタンスを使用して、ノードのホストとインデックス処理ロジックの実行の両方を行っています。
フォワードフィル
バックフィル後、インデクサーはフォワードフィルモードに切り替わります。
フォワードフィルは継続的かつ順次実行され、ノードを監視して新しいブロックを検出します。
このコンポーネントは 2 つの機能を実行します。1/ ブロックチェーンノードを監視し、到着した新しいブロックを取り込む、2/ ブロック再編成 (reorg) を認識し続けます。
多くのブロックビルダーが同時に新しいブロックを作成しているため、生成されたブロックが無効になる可能性があります (より長いチェーンのフォークが存在する場合)。
インデクサーは reorg を認識する必要があります。ブロック reorg が発生した場合、フォークの起点まで遡る必要があります。
ブロック reorg は次のことを検証することで検出されます。1/ 各新しいブロックに前のブロックのハッシュが含まれていること、2/ ブロック番号が順次増加していること。
いずれかの条件が満たされない場合、reorg が発生しており、インデクサーはフォーク前の最後のブロックまで巻き戻す必要があります。
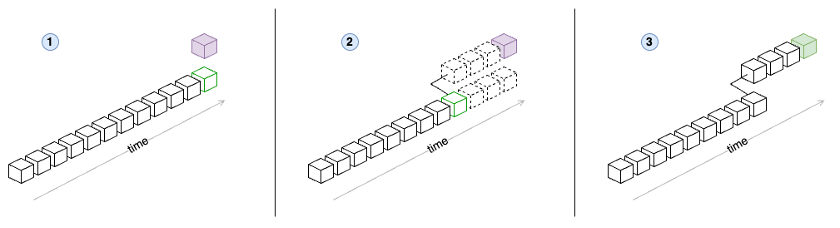
ワークフローには 3 つのステップがあります (上の図に示されています)。
- 現在の正規チェーンの先頭 (緑) に従わない新しいブロック (紫) が出現します。
- インデクサーは新しいブロックから共通の祖先 (緑) まで遡ります。
- インデクサーは共通の祖先までの、以前に保存されたブロックを削除します。インデクサーは新しい正規ブランチから新しいブロックを取り込みます。
次の図は、フォワードフィリングコンポーネントのアーキテクチャを示しています。
これは、ブロックチェーンノードがチェーンの再編成を正しく処理する機能に依存しています。
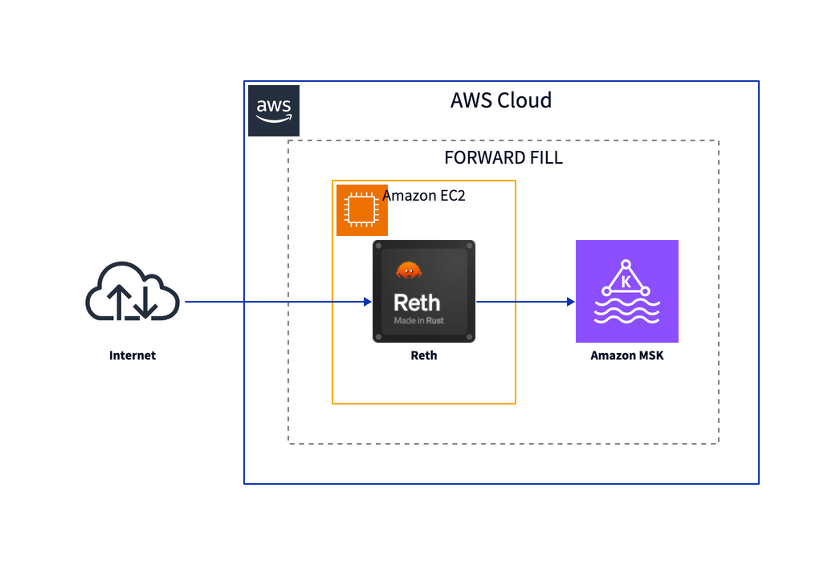
これを実現するために、Reth クライアントの Execution Extensions (ExEx) 機能を使用します。
クライアントは各新しいブロック (およびreorg) を ExEx に通知し、ExEx はデータをカスタムの送信先に送信できます。
reorgを処理するために、ExEx は巻き戻しと新しくコミットされたブロックの両方を Kafka にプッシュします。
Kafka トピックはこれらのブロックを順次保存し、その後変換ロジックが実行されて最終的なデータシンクのデータを更新または削除します。
変換
Apache Flink を使用すると、Kafka トピックに対してコンシューマーを実行し、データのフィルタリングと変換を行うことができます。
Flink アプリケーションは Java で記述されており、データのフィルタリングや変換に適しています。
アドレスまたはイベントデータのデコードによって、特定のスマートコントラクトに対するフィルタリングを実行できます。
変換されたデータは、再び Kafka トピック、Amazon RDS などのデータベース、または Amazon Simple Storage Service (Amazon S3) 上のファイルとして保存できます。
コンシューマーは元のデータを変更しないことに注意することが重要です。
変換ロジックに変更が発生した場合、最初の Kafka メッセージからインデックスを再構築するためにコンシューマーを再起動するだけで済み、データソース(ノード)自体に戻る必要はありません。
データの構造によっては、複数のコンシューマーを並列で実行できる可能性があります。
ロード
コンシューマーは、データをカスタムシンクにロードできます。
Uniswap の例では、データをカスタム PostgreSQL テーブルに保存します。
フロントエンドはテーブルをクエリして、適切なデータを取得できます。
ソリューション全体の最終的なアーキテクチャは、次の図に示されています。
まとめ
AWS ベースのブロックチェーンインデクサーは、単方向データフローと抽出プロセスと変換プロセスの分離により、最適化されたデータアクセスを実現します。
このアーキテクチャは、バックフィルによる効率的な履歴データ処理を可能にしながら、再編成検知機能を備えたフォワードフィルによってリアルタイムデータの整合性を維持します。
このソリューションは、MSK、Managed Flink、RDS を含む AWS サービスを活用して、ブロックチェーンの順次的な構造を効率的にクエリ可能な形式に変換する、スケーラブルで信頼性の高い基盤を構築します。
このソリューションをデプロイすることで、開発者は直接ノードにクエリを実行する際のパフォーマンス制限を回避しながら、貴重なブロックチェーンインサイト(洞察)を得ることができます。
詳細情報
このソリューションをご自身でデプロイするには、GitHub の詳細なデプロイメントガイドに従ってください。
インデクサーのデモでは、デフォルトでアーカイブノードを持つ reth 実行クライアントを使用し、カスタムシンクにデータをストリーミングする方法を提供します。このストリーミング機能はフォワードフィリングプロセスで使用されます。
このソリューションは、バックフィリングのために cryo を使用して履歴データを効率的に抽出し、カスタム reth ExEx を通じてリアルタイムデータを取得し、Flink を使用してこのデータを処理および変換し、分析のために構造化データをリレーショナルデータベースに保存します。
このソリューションは、オンチェーンデータの規模と複雑さに対応できるブロックチェーンのインデックス作成と分析のための信頼性の高い基盤を提供し、ブロックチェーンデータから価値ある洞察を得るのに役立ちます。
これを拡張するには、以下を検討してください。
- 異なるプロトコルやトークンのための Flink アプリケーションの追加
- データ可視化ダッシュボードの実装
- 特定のオンチェーンイベントに対するアラートの設定
- 予測分析のための機械学習モデルとの統合
本記事は、2025 年 11 月 25 日に公開された Building a blockchain indexer on AWS を翻訳したものです。翻訳は Blockchain Prototyping Engineer の 深津颯騎 が担当しました。