Amazon Web Services ブログ
レイクハウスアーキテクチャの構築: Yggdrasil Gaming の BigQuery から AWS への移行
本記事は 2026 年 3 月 3 日 に公開された「Building a modern lakehouse architecture: Yggdrasil Gaming’s journey from BigQuery to AWS」を翻訳したものです。
本記事は、AWS パートナーである GOStack の CEO 兼創設者 Edijs Drezovs、データアーキテクト Viesturs Kols、シニアデータエンジニア Krisjanis Beitans によるゲスト投稿です。
Yggdrasil Gaming は、カジノゲームをグローバルに開発・配信しており、ゲームパフォーマンス分析、プレイヤー行動分析、業界インテリジェンスのために大量のリアルタイムゲームデータを処理しています。システムの成長に伴い、デュアルクラウド環境の管理が運用負荷を増大させ、高度な分析への取り組みを制約していました。マルチクラウド運用の課題は、データ量と複雑性の増加をもたらす Game in a Box ソリューションの AWS Marketplace でのローンチを控え、特に重要になりました。
Yggdrasil Gaming は Google BigQuery から AWS 分析サービスへ移行し、マルチクラウドの複雑性を解消してスケーラブルな分析基盤を構築しました。本記事では、Yggdrasil Gaming がビジネスの成長に対応するためにデータアーキテクチャをどのように変革したかを紹介します。ビジネス継続性を維持しながら、プロプライエタリなシステムから Apache Iceberg などのオープンテーブルフォーマットへ移行する実践的な戦略を学べます。
Yggdrasil は AWS パートナーの GOStack と連携し、Apache Iceberg ベースのレイクハウスアーキテクチャへ移行しました。レイクハウスへの移行により運用の複雑性が軽減され、リアルタイムのゲーム分析と機械学習が可能になりました。
課題
Yggdrasil が AWS への移行を決断した背景には、いくつかの重要な課題がありました。
- マルチクラウドの運用負荷: AWS と Google Cloud にまたがるインフラ管理が大きな運用負荷を生み、俊敏性を低下させ、メンテナンスコストを増加させていました。データチームは両環境の専門知識を維持し、クラウド間のデータ移動を調整する必要がありました。
- アーキテクチャの制約: 既存の構成では高度な分析や AI の取り組みを効果的に支えられませんでした。さらに重要なのは、Yggdrasil の Game in a Box ソリューションのローンチに、データ量の増加に対応でき高度な分析を実現できる、近代的でスケーラブルなデータ環境が必要だったことです。
- スケーラビリティの制約: オープン標準と自動化を備えた統合データ基盤がなく、効率的なスケーリングが困難でした。データ量の増加に比例してコストも増加し、大規模な分析に対応できる環境が求められていました。
ソリューション概要
Yggdrasil は AWS APN パートナーの GOStack と連携し、新しいレイクハウスアーキテクチャを設計しました。以下の図はアーキテクチャの全体像を示しています。
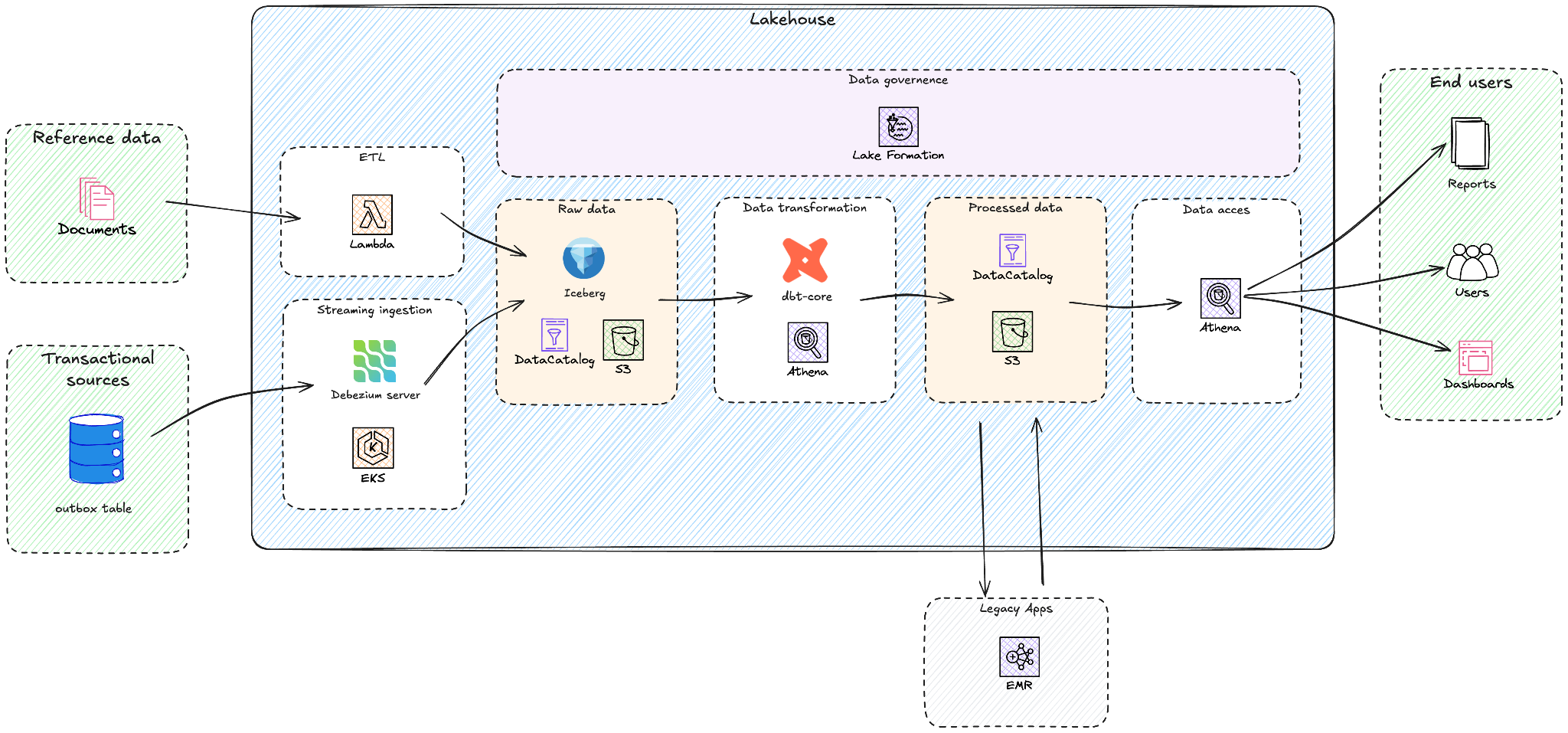
Yggdrasil は Google BigQuery から、Amazon Athena、Amazon EMR、Amazon Simple Storage Service (Amazon S3)、AWS Glue Data Catalog、AWS Lake Formation、Amazon Elastic Kubernetes Service (Amazon EKS)、AWS Lambda を活用したデータレイクハウスアーキテクチャへの移行に成功しました。マルチクラウドの複雑性を軽減しつつ、Game in a Box ソリューションや、パーソナライズされたゲームレコメンデーション、不正検知といった AI/ML に向けたスケーラブルな基盤の構築を目指した移行です。
Amazon S3、Apache Iceberg、Amazon Athena の組み合わせにより、Yggdrasil はプロビジョニング済みの常時稼働コンピューティングモデルから脱却できました。Amazon Athena のクエリ単位課金はスキャンしたデータ量のみに課金されるため、オフピーク時のアイドルコンピューティングコストがなくなります。評価フェーズで実施した内部コストモデリングでは、特にゲームローンチ、トーナメント、季節的なトラフィックによるバースト型ワークロードにおいて、コンピューティングベースのウェアハウス課金モデルと比較して分析システムコストを 30〜50% 削減できる見込みが示されました。AWS ネイティブの分析サービスを採用することで、AWS Identity and Access Management (AWS IAM)、Amazon EKS、AWS Lambda とのネイティブ統合を通じて運用の複雑性が軽減され、分析システム全体のセキュリティ、ガバナンス、自動化が簡素化されました。
ソリューションの中心は、Amazon S3 上に構築されたレイクハウスアーキテクチャです。Amazon S3 は Iceberg テーブルを Apache Parquet 形式で格納する耐久性とコスト効率に優れたストレージを提供します。Apache Iceberg テーブルフォーマットは、オープン標準を維持しながら ACID トランザクション、スキーマエボリューション、タイムトラベル機能を提供します。AWS Glue Data Catalog は技術メタデータの一元リポジトリとして機能し、Amazon Athena は dbt-athena やアドホックなデータ探索に使用されるサーバーレスクエリエンジンです。Amazon EMR は Yggdrasil のレガシー Apache Spark アプリケーションをフルマネージド環境で実行し、AWS Lake Formation はデータレイクの一元的なセキュリティとガバナンスを提供して、データベース、テーブル、列、行レベルでのきめ細かなアクセス制御を実現します。
移行は段階的に進められました。
- レイクハウス基盤の構築 – Amazon S3 と AWS Glue Data Catalog を使用した Apache Iceberg ベースのアーキテクチャをセットアップ
- リアルタイムデータ取り込みの実装 – EKS および Google Kubernetes Engine (GKE) クラスターからのリアルタイム変更データキャプチャ用に Debezium コネクタをデプロイ
- 処理パイプラインの移行 – AWS Lambda を使用した ETL パイプラインの再構築、レガシーデータアプリケーションの Amazon EMR への移行
- 変換レイヤーの近代化 – モジュール式で再利用可能なモデルのために dbt と Amazon Athena を導入
- ガバナンスの有効化 – データガバナンス全体を AWS Lake Formation で管理
レイクハウス基盤の構築
移行の最初のフェーズでは、AWS 上の新しいデータレイクハウスアーキテクチャの基盤構築に注力しました。目標は、オープンデータフォーマットとサーバーレスクエリ機能を備えた、スケーラブルで安全かつコスト効率の高い環境を構築することでした。
GOStack は中央ストレージレイヤーとして Amazon S3 ベースのデータレイクをプロビジョニングし、高いスケーラビリティときめ細かなコスト管理を実現しました。ストレージとコンピューティングの分離により、取り込み、変換、分析の各プロセスを切り離し、それぞれが最適なコンピューティングエンジンを使用して独立にスケーリングできます。
データセットの相互運用性と発見性を確立するため、チームは AWS Glue Data Catalog を統合メタデータリポジトリとして採用しました。カタログは Iceberg テーブル定義を格納し、Amazon Athena や Amazon EMR 上の Apache Spark ワークロードなどのサービス間でスキーマにアクセスできるようにします。バッチとストリーミングの両方を含むほとんどのデータセットがここに登録され、レイクハウス全体で一貫したメタデータの可視性を実現しています。
データは Amazon S3 上の Apache Iceberg テーブルに格納されます。Iceberg はオープンテーブルフォーマット、ACID トランザクションサポート、柔軟なスキーマエボリューション機能を理由に選定されました。Yggdrasil は、一貫した財務レポートと不正検知のための ACID トランザクション、急速に変化するゲームデータモデルに対応するスキーマエボリューション、規制監査要件に沿ったタイムトラベルクエリを必要としていました。
GOStack はカスタムのスキーマ変換・テーブル登録サービスを構築しました。スキーマ変換・テーブル登録サービスはソースシステムの Avro スキーマを Iceberg テーブル定義に変換し、raw レイヤーテーブルの作成とエボリューションを管理します。スキーマ変換とテーブル登録を直接制御することで、メタデータがソースシステムと一貫性を保ち、取り込みニーズに沿った予測可能でバージョン管理されたスキーマエボリューションを実現しています。
初期セットアップでは以下のコンポーネントを構成しました。
- Amazon S3 バケット構造の設計: データライフサイクルのベストプラクティスに沿ったマルチレイヤーレイアウト (raw、curated、analytics ゾーン) を実装しました。
- AWS Glue Data Catalog の統合: Athena のパフォーマンスに最適化されたパーティショニング戦略でデータベースとテーブルスキーマを定義しました。
- Iceberg の設定: ストレージ効率とクエリの柔軟性のバランスを取るため、バージョニングとメタデータ保持ポリシーを有効化しました。
- セキュリティとコンプライアンス: AWS Key Management Service (AWS KMS) による保存時の暗号化を設定し、AWS IAM と Lake Formation によるアクセス制御を適用し、最小権限の原則に従った Amazon S3 バケットポリシーを実装しました。
以前の GCP 構成の再設計により、コストパフォーマンスが向上しました。Yggdrasil は、より直接的なイベント駆動パイプラインへの移行を通じて、取り込みと処理のコストを約 60% 削減し、運用負荷も軽減しました。
リアルタイムデータ取り込みの実装
レイクハウスアーキテクチャの構築後、次のステップでは Yggdrasil のオペレーショナルデータベースからレイクハウスの raw データレイヤーへのリアルタイムデータ取り込みの実現に注力しました。目的は、トランザクションの変更を発生時にキャプチャして配信し、下流の分析やレポートに最新の情報を反映させることでした。
GOStack は Debezium Server Iceberg をデプロイしました。これは変更データキャプチャ (CDC) を Apache Iceberg テーブルに直接統合するオープンソースプロジェクトです。Amazon EKS 上に Argo CD アプリケーションとしてデプロイされ、Argo の GitOps ベースモデルにより再現性、スケーラビリティ、シームレスなロールアウトを実現しています。
Debezium Server Iceberg のアーキテクチャは効率的な取り込み経路を提供します。ソースシステムのアウトボックステーブルからデータ変更を直接ストリーミングし、AWS Glue Data Catalog に登録され Amazon S3 に物理的に格納された Apache Iceberg テーブルに書き込みます。中間ブローカーやステージングサービスが不要です。Iceberg テーブルフォーマットでデータを書き込むことで、取り込みレイヤーはトランザクション保証と Amazon Athena による即時クエリ可用性を維持しました。
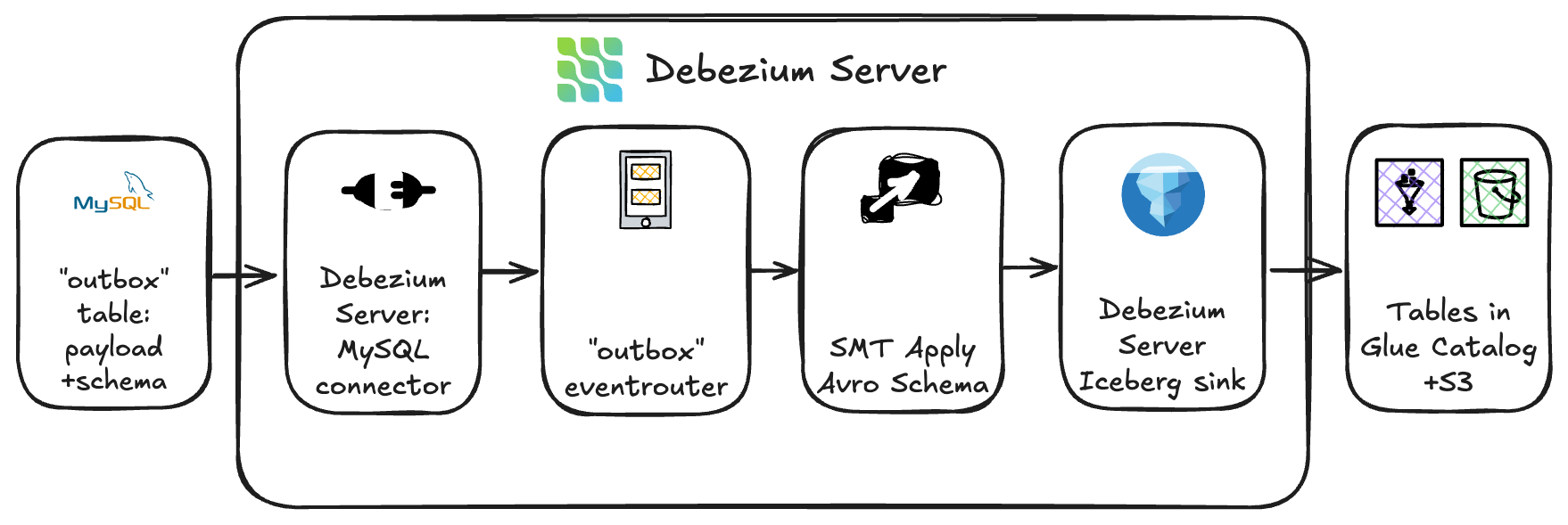
Yggdrasil のソースシステムは Avro レコードを含むアウトボックスイベントを発行していたため、チームは Debezium 内にカスタムのアウトボックスから Avro への変換を実装しました。アウトボックステーブルには 2 つの主要コンポーネントが格納されていました。
- Avro スキーマ定義
- 各レコードの JSON エンコードされたペイロード
カスタム変換モジュールは Avro スキーマ定義とペイロードを有効な Avro レコードに結合してから、ターゲットの Iceberg テーブルに永続化しました。Avro からの変換によりスキーマの忠実性が保たれ、下流の処理ツールとの互換性が確保されました。
受信した変更イベントを動的にルーティングするため、チームは Debezium のイベントルーター設定を活用しました。各レコードはトピックとメタデータルールに基づいて適切な Apache Iceberg テーブル (Amazon S3 上) にルーティングされ、テーブルスキーマとパーティショニングは AWS Glue 側で管理され、レイクハウスのデータ編成標準との安定性と整合性が維持されました。
Debezium と Iceberg の組み合わせにより、低レイテンシーの取り込みとデータベースアウトボックスから S3 ベースの Iceberg テーブルへのほぼリアルタイムのエンドツーエンドストリーミングが実現しました。チームは Amazon EKS 上で Helm チャートを使用し、GitOps モデルで Argo CD 経由でデプロイすることで、完全に宣言的でバージョン管理された運用を実現しました。ACID 準拠の Iceberg 書き込みにより、部分的に書き込まれたデータが下流の分析を破損することはありません。モジュール式の変換ロジックにより、取り込みパイプラインを再設計することなく、将来的に新しいソースシステムやイベントフォーマットへの拡張が可能です。
Debezium Server による高速なリアルタイムデータ取り込みは、GOStack が暫定的なアーキテクチャと位置付けています。長期的には、取り込みパイプラインは Amazon Managed Streaming for Apache Kafka (Amazon MSK) を中央イベントバックボーンとして使用する形に進化する予定です。Debezium コネクタがプロデューサーとして変更イベントを Apache Kafka トピックに発行し、Apache Flink アプリケーションがデータを消費、処理して Iceberg テーブルに書き込みます。
Kafka ベースのストリーミングアーキテクチャへの計画的な進化により、Yggdrasil のレイクハウスは現在スケーラブルでコスト効率が高いだけでなく、将来にも対応できます。組織の成長に伴い、より高度なストリーミング分析や幅広いデータ統合シナリオをサポートできる構成です。
処理パイプラインの移行
リアルタイムデータ取り込みの確立後、GOStack はデータ変換レイヤーの近代化に注力しました。目標は変換ロジックの簡素化、運用負荷の軽減、新しい AWS ベースのレイクハウス内での分析ワークロードのオーケストレーション統合でした。
GOStack は GCP からの迅速かつ低リスクな移行を支えるため、Yggdrasil の一部のデータパイプラインにリフトアンドシフトアプローチを採用しました。ファイル共有、SharePoint、Google Sheets、各種サードパーティ API からのデータ抽出を担っていた軽量な Cloud Run functions は、AWS Lambda で再実装されました。再実装した Lambda 関数は同じ外部システムと連携し、データを直接 Iceberg テーブルに書き込みます。
より複雑な処理については、Dataproc 上で実行されていた Apache Spark アプリケーションを最小限のコード変更で Amazon EMR に移行しました。既存の変換ロジックを維持しながら、EMR のマネージドスケーリング機能と AWS でのコスト管理の向上を活用できるようになりました。
今後、移行したパイプラインは段階的にリファクタリングされ、EKS クラスター上のコンテナ化されたワークフローに統合され、Argo Workflows で完全にオーケストレーションされる予定です。段階的な移行により、Yggdrasil はワークロードを迅速に AWS に移行して GCP リソースを早期に廃止しつつ、データシステムの継続的な改善と近代化の余地を残しています。
最後に、以前 BigQuery のストアドプロシージャやスケジュールクエリとして存在していた多くの分析変換は、dbt-athena で実行されるモジュール式の dbt モデルとして再構築されました。dbt への移行により変換ロジックの透明性、保守性、バージョン管理が向上し、開発者体験と長期的なガバナンスの両方が改善されました。
変換レイヤーの近代化
取り込みパイプラインの AWS への移行が完了し、GOStack は Yggdrasil の分析変換の簡素化と近代化に注力しました。以前のストアドプロシージャ駆動のアプローチを再現するのではなく、保守性、リネージの可視性、オーケストレーション、長期的なガバナンスの向上のために dbt を使用して変換レイヤーを再構築しました。再設計の一環として、いくつかのデータモデルは新しいレイクハウスアーキテクチャに合わせて再構成されました。最も大きな取り組みは、重要な Spark ベースの財務変換を SQL 駆動の dbt モデルセットに書き換えることでした。SQL 化によりロジックがレイクハウス設計に沿うだけでなく、長時間稼働する Spark クラスターが不要になり、運用とコストの削減につながりました。レガシーウェアハウスに代わるキュレーションデータレイヤーでは、GOStack は多数のスケジュールクエリとストアドプロシージャを構造化された dbt モデルに統合しました。分析スタック全体で標準化されバージョン管理された変換と明確なリネージが提供されます。
オーケストレーションも簡素化されました。以前は Spark ワークロード用の Apache Airflow と分析変換用のスケジュールクエリに分かれており、運用上の摩擦と依存関係のリスクが生じていました。新しいアーキテクチャでは、Amazon EKS 上の Argo Workflows が dbt モデルを一元的にオーケストレーションし、変換ロジックを単一のワークフローエンジンに統合しています。現在ほとんどの変換はタイムベースのスケジュールで実行されていますが、Argo Events によるイベント駆動実行もサポートしており、変換レイヤーの進化に合わせてトリガーベースのワークフローを段階的に採用できます。
統合オーケストレーションフレームワークのメリットは次のとおりです。
- 一貫性: 取り込みと変換にまたがるデータワークフローを単一のオーケストレーションレイヤーで管理。
- 自動化: イベント駆動の dbt 実行により手動スケジューリングが不要になり、運用負荷が軽減。
- スケーラビリティ: Argo Workflows は EKS クラスターとともにスケーリングし、並行する dbt ジョブをシームレスに処理。
- 可観測性: 一元化されたログとワークフローの可視化により、ジョブの依存関係とデータの鮮度の把握が向上。
dbt と Argo Workflows の導入を通じて、Yggdrasil はデータレイクとウェアハウスを、オープンデータフォーマット、サーバーレスクエリエンジン、モジュール式の変換ロジックを活用したレイクハウスアーキテクチャに統合しました。dbt と Athena への移行は運用を簡素化しただけでなく、データ環境全体でのイテレーションの高速化、ガバナンスの簡素化、開発者の生産性向上への道を開きました。
レイクハウスのパフォーマンス最適化
パフォーマンスチューニングは継続的な取り組みですが、変換の再設計の一環として、GOStack は Athena クエリの高速化とコスト効率の向上のためにいくつかのパフォーマンス調整を行いました。Apache Iceberg テーブルは ZSTD 圧縮の Parquet で格納され、優れた読み取りパフォーマンスと Athena がスキャンするデータ量の削減を実現しています。
パーティショニング戦略も Iceberg のネイティブパーティショニングを使用して実際のアクセスパターンに合わせました。raw データゾーンは取り込みタイムスタンプでパーティショニングされ、効率的な増分処理を実現しています。キュレーションデータはプレイヤーやゲーム識別子、日付ディメンションなどのビジネス駆動のパーティションキーを使用し、分析クエリの最適化に役立てています。パーティショニング設計により、Athena は不要なデータを刈り込み、関連するパーティションのみを一貫してスキャンできます。
Iceberg のネイティブパーティショニング機能 (バケッティングやタイムスライスなどの変換を含む) は、従来の Hive パーティショニングパターンに代わるものです。Iceberg はメタデータレイヤーでパーティションを内部的に管理するため、Glue や Athena のパーティション構成がすべて適用されるわけではありません。Iceberg のネイティブパーティショニングに依存することで、レガシーな Hive の動作を導入することなく、レイクハウス全体で予測可能なプルーニングと一貫したパフォーマンスが得られます。
リアルタイム取り込みで生成される大量の小さなファイルに対処するため、GOStack は AWS Glue Iceberg コンパクションを有効化しました。小さな Parquet ファイルを自動的に大きなセグメントにマージし、手動介入なしでクエリパフォーマンスの向上とメタデータ負荷の削減を実現しています。
ガバナンスの有効化
チームはレイクハウスのキュレーションゾーンの主要なガバナンスレイヤーとして AWS Lake Formation を採用し、Lake Formation ハイブリッドアクセスモードを活用して、既存の IAM ベースのアクセスパターンと並行してきめ細かな権限を管理しています。ハイブリッドアクセスモードは、レガシー権限や内部パイプラインロールの完全な移行を強制することなく Lake Formation を段階的かつ柔軟に採用できるため、Yggdrasil の段階的な近代化戦略に最適です。
Lake Formation は一元的な認可を提供し、データベース、テーブル、列、そして Yggdrasil にとって特に重要な行レベルの権限をサポートしています。行レベルの権限は、同社のマルチテナント運用モデルで特に重要です。
- ゲーム開発パートナーは自社のゲームに関するデータとレポートのみにアクセスでき、パートナー契約に沿ったセキュリティとコンプライアンスを実現しています。
- Yggdrasil のシステムと統合する iGaming オペレーターは、キュレーションされた Iceberg テーブルに基づくレポートツールを通じて、自社データに限定した運用・財務インサイトを自動的に受け取ります。
Lake Formation ハイブリッドアクセスモードにより、テナント固有の行レベルアクセスポリシーが Amazon Athena、AWS Glue、Amazon EMR 全体で一貫して適用され、既存の IAM ベースのワークロードに破壊的な変更を加えることはありません。Yggdrasil は外部コンシューマーに対して適切なガバナンスを実装しつつ、内部運用の安定性と予測可能性を維持できました。
内部的には、Lake Formation は分析チームと BI ツールにキュレーションデータセットへの対象を絞ったアクセスを付与するためにも使用されています。シンプルですが一元管理されており、一貫性の維持と管理負荷の軽減に役立っています。
取り込みと変換のワークロードについては、チームは引き続き IAM ロールとポリシーを使用しています。Debezium、dbt、Argo Workflows などのサービスは raw および中間ストレージレイヤーへの広範だが制御されたアクセスを必要とし、IAM は内部パイプラインパスに Lake Formation を関与させることなく、最小権限で必要な権限を付与する簡潔なメカニズムを提供します。
Lake Formation をハイブリッドアクセスモードで採用し、内部サービスには IAM を組み合わせることで、Yggdrasil はセキュリティと運用の柔軟性を両立するガバナンスモデルを確立しました。ビジネスの成長に伴い、レイクハウスを安全にスケーリングできる構成です。
成果とビジネスへの影響
Amazon Athena、Amazon S3、AWS Glue Data Catalog 上に構築された新しいレイクハウスは、プレイヤー行動モデリング、予測的なゲームレコメンデーション、不正検知といった高度な分析や AI/ML のユースケースを支えています。
最適化されたレイクハウス設計により、Yggdrasil は新しい分析ワークロードやビジネスユースケースを迅速にオンボードでき、測定可能な成果を実現しています。
- 運用の複雑性の軽減: AWS 分析サービスへの統合による簡素化
- コスト最適化: データ処理コストの 60% 削減
- データ鮮度の向上: 分析結果のレイテンシーが 75% 改善 (2 時間から 30 分に短縮)
- ガバナンスの強化: AWS Lake Formation のきめ細かな制御の活用
- 将来に対応したアーキテクチャ: オープンフォーマットとサーバーレス分析の活用
まとめ
Yggdrasil Gaming の移行事例は、プロプライエタリな分析システムからオープンで柔軟なレイクハウスアーキテクチャへの移行を成功させる方法を示しています。AWS Well-Architected Framework の原則に基づいた段階的なアプローチにより、Yggdrasil はビジネス継続性を維持しながらデータニーズに対応する基盤を構築しました。
Yggdrasil の移行から、レイクハウス構築に役立つ教訓が得られました。
- 現状を評価する: 既存のデータアーキテクチャの課題を特定し、近代化の明確な目標を設定します。
- 小さく始める: AWS 分析サービスを使用したパイロットプロジェクトから始め、特定のユースケースでレイクハウスアプローチを検証します。
- オープン性を重視した設計: Apache Iceberg などのオープンテーブルフォーマットを活用し、柔軟性を維持してベンダーロックインを回避します。
- 段階的に実装する: Yggdrasil と同様の段階的な移行戦略に従い、価値の高いワークロードを優先します。
- 継続的に最適化する: Amazon Athena のパフォーマンスチューニング手法を活用し、効率の最大化とコストの最小化を図ります。
レイクハウスアーキテクチャ構築に関する詳細は、Amazon SageMaker のレイクハウスアーキテクチャを参照してください。
著者について
この記事は Kiro が翻訳を担当し、Solutions Architect の Takayuki Enomoto がレビューしました。