Amazon Web Services ブログ
Amazon Bedrock AgentCore でマルチテナントエージェントを構築する
本記事は 2026 年 5 月 21 日 に公開された「Building multi-tenant agents with Amazon Bedrock AgentCore」を翻訳したものです。
マルチテナントのエージェント型アプリケーションを構築する SaaS (Software as a Service) プロバイダーは、セキュリティ、ガバナンス、応答精度といった一般的な懸念事項を超えたアーキテクチャ上の課題に取り組む必要があります。具体的には、テナント分離、テナント ID、テナントのオブザーバビリティ、データ分離、コスト配分、ノイジーネイバーの緩和などです。動作するデモから本番環境へのデプロイまでの隔たりを埋めるには、マルチテナント環境向けに設計されたインフラストラクチャが必要になります。Amazon Bedrock AgentCore は、AWS 上でエージェント型アプリケーションを構築、デプロイし、安全に運用するためのマネージドなサーバーレスサービスです。エージェントのデプロイと MCP サーバーのホスティングのための構成要素を提供し、ID 管理、メモリ、オブザーバビリティ、評価機能を標準で備えています。これらはすべて、マルチテナントのエージェントアーキテクチャを無理なく構築できるように設計されています。
本ブログシリーズの第 1 回となる本記事では、マルチテナントのエージェント型アプリケーションを設計する際の検討事項と、Amazon Bedrock AgentCore で SaaS アーキテクチャの課題に取り組むために必要なフレームワークを解説します。
マルチテナントエージェントを構築する際の設計上の検討事項
強力な分離を備えた安全なマルチテナントのエージェント型アプリケーションを構築するには、図 1 に示すいくつかの主要コンポーネントにわたって、慎重なアーキテクチャ上の判断が必要です。各コンポーネントは、セキュリティとコンプライアンスの基準を維持しながら、テナント分離、運用効率、コスト最適化のバランスを取る必要があります。これらの設計上の検討事項は、3 つのテナント分離パターン (サイロ、プール、ブリッジ) を軸に展開され、これらを選択する際にはティアリング戦略が重要な検討要素になります。
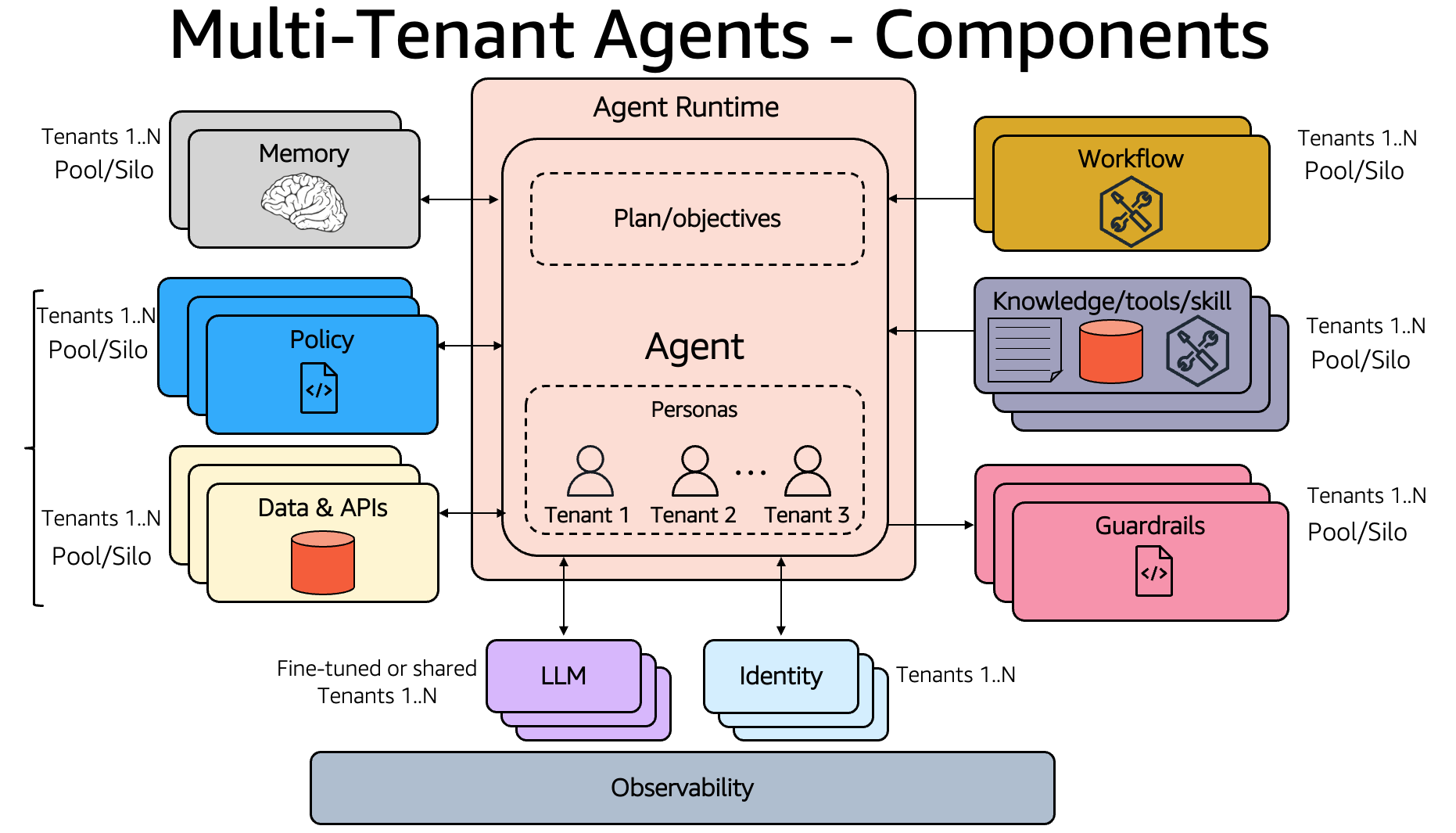
図 1: マルチテナントエージェントの設計上の検討事項
続くセクションでは、マルチテナント化が各コンポーネントにどのような影響を与えるかを詳しく説明します。
1. エージェントランタイムのデプロイ: 専用と共有
マルチテナントのエージェントアーキテクチャにおける重要な判断は、テナントに対してエージェントランタイムをどのようにプロビジョニングするかです。テナントごとの専用ランタイムは、テナントごとに独立した実行環境をインスタンス化し、それぞれが固有のコンテナイメージ、プロセス空間、ライフサイクルを持ちます。このサイロ型のアプローチは、最も強力なノイジーネイバー対策となり、コンプライアンス監査を簡素化します。一方、共有ランタイムは、すべてのテナントのエージェントを同一のコンテナイメージとプロセスプール内でホストするため、インフラストラクチャのコストと運用負荷を抑えられますが、プロセス内でテナントコンテキストを厳密に伝播させる必要があります。
Amazon Bedrock AgentCore Runtime は、セッション分離された microVM ベースのコンピューティングによってこのトレードオフを解決します。AgentCore Runtime は、テナントごとに完全な仮想マシンを起動するコストやレイテンシーを伴わずに、セッション単位で軽量な microVM を起動します。各セッションは独自の永続ファイルシステムを持つため、エージェントはセッションスコープのファイルを読み書きし、中間的な計算結果を保持し、マルチステップのやり取りをまたいで状態を維持できます。これにより、セッション間でのデータ漏洩のリスクを軽減します。このアーキテクチャは、マルチテナントの MCP サーバー、エージェント、AG-UI サーバーをホストするのに適しています。テナントコンテキストは、カスタム HTTP ヘッダーを通じて分離された実行環境に流れ込みます。SaaS プラットフォームが AgentCore Runtime セッションにリクエストを転送する際、標準の認可トークンに加えて、テナント識別子、ティア、リージョンの設定、機能フラグ、エンタイトルメントといったテナント固有のメタデータを持つヘッダーを付与します。エージェントは呼び出し時にこれらのヘッダーを読み取ってテナントを完全に認識できるため、そのテナントのビジネスロジックに合わせたワークフローを実行し、ライセンスされたツールのみを呼び出し、ハードコードされたルーティングロジックなしにテナント固有の API エンドポイントを呼び出せます。
2. 共有モデル、ティア別モデル、ファインチューニング済みモデル
ほとんどのマルチテナントデプロイでは、共有基盤モデル (FM) が推奨される出発点となり、単一のモデルを保守するだけで運用を簡素化できます。テナントは通常、テナントごとのカスタマイズなしに、自動的なモデル更新の恩恵を受けられます。テナントのティアに基づいてモデルを選択する方式 (ティア別モデル) では、柔軟性が得られ、テナントのティア間でコスト、パフォーマンス、精度のバランスを取れます。テナント固有の用語、規制対応、パフォーマンス SLA を必要とする特殊なユースケースでは、テナントごとにファインチューニングしたモデルが必要になりますが、運用が複雑になり、テナントごとのパイプラインが発生します。標準ティアには性能を抑えたモデルを、プレミアムなエンタープライズ顧客にはファインチューニング済みまたは高性能なモデルを使うハイブリッドなアプローチは、コスト効率とカスタマイズの要件のバランスを取れます。Amazon Bedrock は主要プロバイダーの大規模言語モデル (LLM) を幅広く提供しており、SaaS プロバイダーはテナントやティア固有のニーズに合ったモデルを選択できます。Amazon Bedrock のファインチューニングでは、独自のラベル付きデータセットを使って FM をカスタマイズし、ドメイン固有のタスクのパフォーマンスを高められます。Amazon Bedrock Custom Model Import を使えば、独自にファインチューニングしたモデルを持ち込み、Amazon Bedrock のマネージドインフラストラクチャを使ってデプロイできます。
3. ワークフロー: サイロ、プール、ブリッジパターン
マルチテナントのエージェント型アプリケーションでは、各エージェントがテナントの要件とビジネスロジックに基づいて異なる一連のステップを実行する、柔軟なワークフロー管理が必要です。ワークフローは複数の仕組みで実装できます。手順を段階的にカプセル化する MCP ツールとして、ビジネスロジックのフローを定義する API エンドポイントとして、あるいはドメイン固有のワークフローパターンを組み込んだエージェントスキルとして実装できます。
テナント固有のワークフローを管理する主なパターンは 3 つあります。サイロパターンは、テナント固有の専用スキルを使い、ビジネスロジック、検証ルール、統合ステップを含む各テナントの完全なワークフローを、分離されたエージェントスキルに組み込みます。これにより最大限のカスタマイズと完全な独立性が得られますが、テナントごとに個別のスキル保守が必要です。プールパターンは、共有のエージェントスキルを使います。ブリッジパターンは、認証、ロギング、エラーハンドリングといった共通のワークフローステップを共有エージェントスキルに組み込み、ビジネスクリティカルなロジックについては実行時にテナント固有のスキルを呼び出します。その結果、再利用可能なインフラストラクチャとテナント固有のカスタマイズが共存します。
4. マルチテナント RAG
検索拡張生成 (RAG) システムでは、データ分離の判断が必要です。サイロパターンは、テナントごとに専用のベクトルデータベースを使い、最大限のセキュリティと完全なデータ分離を実現します。これは、規制業界や専用インフラストラクチャを必要とするエンタープライズ顧客に推奨されます。プールパターンは、メタデータベースのテナントフィルタリングと名前空間ベースのアクセス制御を備えた共有ベクトルデータベースを使い、多数の中小規模テナントにサービスを提供する SaaS プラットフォームでコスト効率の高い運用を実現します。検索操作には、テナント間でのデータ漏洩を防ぐため、自動的なテナントフィルターの注入と結果のサニタイズを含めるべきです。
Amazon Bedrock Knowledge Bases は、FM をデータソースに接続するフルマネージドな RAG 機能を提供し、データの取り込み、チャンキング、埋め込みの生成、ベクトルストレージを自動的に処理します。複数のベクトルデータベースに対応し、(メタデータフィルタリングを使って) サイロ型または共有型のベクトルデータベースを作成できます。
Amazon Bedrock Knowledge Bases でマルチテナント RAG アーキテクチャを実装する詳しい手順については、サイロ、プール、ブリッジのデプロイパターンを扱った Multi-tenant RAG with Amazon Bedrock Knowledge Bases と、共有ナレッジベース内でのメタデータベースのテナント分離を扱った Multi-tenancy in RAG applications in a single Amazon Bedrock knowledge base with metadata filtering を参照してください。
5. テナントコンテキスト、代理実行 (act-on-behalf) パターン、トークン伝播
マルチテナントの ID 管理では、サービスチェーン全体にわたってテナントコンテキストを慎重に扱う必要があります。完全な ID を表すテナントコンテキストと、リクエスト固有の状態は、信頼性が高く安全な仕組みを使ってすべてのアーキテクチャ層を流れる必要があります。実行パスが予測可能な決定論的なソフトウェア API とは異なり、AI エージェントは非決定論的で、自律的に動作する可能性があるため、セキュリティ上の考慮事項が重要な点で異なります。不正なエージェントや侵害されたエージェントは、ダウンストリームのサービスに対して不正な呼び出しを行い、認証情報の盗難、権限昇格、混乱する代理問題 (Confused Deputy) を引き起こす可能性があります。エージェントがユーザーの認証情報をすべて使って動作する (なりすまし) 場合、1 つの侵害されたエージェントが、すべてのダウンストリームシステムにわたるユーザー権限への完全なアクセスを得てしまいます。このリスクは、どのツールをいつどのようなパラメータで呼び出すかをエージェントが自律的に判断するようになるほど大きくなります。代理実行 (act-on-behalf) パターンが重要なのは、ユーザーとエージェントを明確に区別し、エージェントが操作ごとに明示的に制限・スコープされた権限でユーザーに代わって呼び出しを行うようにするためです。
テナントコンテキストは JSON Web Token (JWT) 内にエンコードし、3 つの次元を捉えます。セキュリティコンテキスト (標準クレーム: iss、sub、exp、aud)、テナントコンテキスト (tenant_id とテナント固有のスコープ)、リクエストコンテキスト (ビジネスロジック向けのドメイン固有の属性) です。このようにテナントコンテキストをエンコードすることで、マルチテナント運用の強力で柔軟な基盤が得られます。
セキュリティ上の影響が大きく異なる 2 つのパターンから選択します。なりすまし (Impersonation) はエージェントがユーザーの ID と権限をすべて使って動作できるようにするもので、実装は容易ですが、最小権限の原則に反し、セキュリティリスクを生みます。推奨されるアプローチである代理実行 (Act-on-Behalf、委譲) は、各サービス境界でトークンをスコープ制限された認証情報に変換し、エージェントを識別する act クレーム (OAuth 2.0 RFC 8693 に準拠) を付与する、真の委譲を実装します。AgentCore Identity の On-behalf-of トークン交換を使うと、エージェントや MCP サーバーなどのワークロードが、受信したユーザーアクセストークンを、ダウンストリームのリソースサーバー向けの新しいスコープ付きアクセストークンと交換できます。この交換では、ある対象者 (audience) 向けに発行されたトークンを、別のダウンストリームの対象者向けのトークンに直接変換するため、エージェントは追加の同意フローを発生させることなく、認証済みユーザーに代わって保護されたリソースにアクセスできます。交換されたトークンはエージェント自身の ID と元の呼び出し元の ID の両方を保持するため、リソースサーバーはホップごとにきめ細かなゼロトラスト認可を実施するために必要なシグナルを得られます。
6. MCP ツールと API に対するきめ細かなアクセス制御
マルチテナントのエージェント型アプリケーションでは、ポリシーを使った MCP サーバーアクセスの制限、ツール呼び出し層でのきめ細かなアクセス制御、データアクセス層でのテナント分離が必要です。認可層では、ポリシーが実行時にテナントコンテキストを評価して許可/拒否の認可判断を行い、トークンに埋め込まれた静的な権限だけに頼るのではなく、現在のテナントの状態に基づいて、ツール呼び出しを許可する前にテナントのクォータ、ティアベースの権限、使用制限を評価します。ポリシーストアを分離して一元化することで、再デプロイなしに動的な更新が可能になり、ポリシーのバージョン管理によって監査証跡とロールバックがサポートされます。AgentCore Policy は、ツールアクセスを許可する前に、定義されたポリシーに照らしてすべてのエージェントリクエストをインターセプトして評価し、ユーザー ID とツール入力パラメータに基づくきめ細かな制御を提供します。ポリシーは自然言語または Cedar で直接記述できます。
呼び出し層では、MCP サーバーがテナントのティア、機能フラグ、クォータ制限に基づいて、エージェントが呼び出す前に利用可能なツールをフィルタリングし、きめ細かなアクセス制御を実施します。ツールインターセプターは JWT クレームを検証し、リクエストを行うプリンシパルが特定の操作に対する適切な権限を持っていることを確認します。スキーマ変換機能は、テナントの設定とエンタイトルメントに基づいてツールのインターフェイスを適応させます。AgentCore Gateway は、API や AWS Lambda 関数をエージェント互換のツールに変換し、既存の MCP サーバーに接続することで、エージェントがツールに安全にアクセスできるようにします。Amazon API Gateway、OpenAPI スキーマ、Smithy モデル、Lambda 関数、MCP サーバーに対応しています。カスタムロジックにはゲートウェイインターセプターを通じてアクセス制御を実装することも、標準的な AWS スタイルのアクセス制御にはリソースベースのポリシーを使うこともできます。データアクセス層では、属性ベースのアクセス制御 (ABAC) ポリシーがデータアクセスのテナント分離を実施し、テナントの識別は JWT クレームを通じて行われます。ABAC ポリシーは AWS Identity and Access Management (IAM) の条件を使い、プリンシパルのタグと属性に基づいてデータアクセスを制限します。これにより、エージェントは行レベルセキュリティまたはストレージポリシーを通じて、自身のテナントコンテキストに一致するリソースのみをクエリできます。
7. メモリ: 階層的な名前空間による分離
マルチテナントのメモリ管理では、テナント間のデータ漏洩を防ぎながら、エージェントがコンテキストや学習した情報を保持できるよう、慎重なアーキテクチャ設計が必要です。メモリシステムは 5 つの論理レベルを実装すべきです。
- グローバル (テナント横断で共有される知識)
- ストラテジー (エージェントタイプ固有のパターンと動作)
- テナント (テナントスコープの会話履歴と設定)
- ユーザー (テナント内の個々のユーザーコンテキスト)
- セッション (アクティブな会話のための一時的な短期メモリ)
アクセス制御は、要求された名前空間パスに対してプリンシパルの ID を検証する属性ベースのポリシーを通じて分離を実施し、エージェントは許可されたスコープ内でのみメモリの読み書きができます。プールパターンは、運用効率とコスト効率のために、階層的な名前空間ベースの論理分離を備えた共有インフラストラクチャを使い、すべてのテナントデータを共通のデータストアに保存し、名前空間のプレフィックスに基づいて厳密にフィルタリングします。サイロパターンは、最大限の分離のためにテナントごとに専用のメモリストアをデプロイし、運用コストは高くなるものの、テナント間アクセスのリスクを低減します。実装にあたっては、テナントとユーザーの情報から複合識別子 (例: tenant_123:user_456) を構築し、テナントコンテキストをクレームやタグとして持つスコープ付き認証情報で認証し、すべてのメモリ操作に適切な名前空間パスをプレフィックスとして付けます。
AgentCore Memory は、グローバル、ストラテジー、テナント、ユーザー、セッションの各レベルにわたる階層的な名前空間分離を提供し、マルチターンの会話のための短期メモリと、セッションをまたいで永続する長期メモリの両方によって、コンテキストを意識したエージェント体験をサポートします。きめ細かなアクセスのために、リソースベースのポリシーと属性ベースのアクセス制御に対応しています。
8. エージェントの ID、信頼、ディスカバリ
エージェント型アプリケーションが組織の境界をまたいで外部のエージェントとやり取りするようになると、エージェント ID、エージェントの信頼、エージェントのディスカバリという 3 つの基本的な懸念事項が浮かび上がります。これらは関連していますが、それぞれ異なる問題に対処します。
エージェント ID は「このエージェントは誰で、それを証明できるか」に答えます。組織に紐づく、検証可能で一意な ID を確立します。
エージェントの信頼 は「このエージェントを信頼すべきか」に答えます。単一の認証情報ではなく、複数のシグナルの組み合わせに基づいて信頼性を評価します。
エージェントのディスカバリ は「適切なエージェントをどうやって見つけるか」に答えます。エンドポイントを事前に知らなくても、機能や所属によってエージェントを見つけられます。
AgentCore Identity によるエージェント ID
Amazon Bedrock AgentCore Identity は、クラウドネイティブセキュリティで確立されたパターンであるワークロード ID として、エージェント ID を実装します。各エージェントは、組織の AWS アカウントと IAM インフラストラクチャに紐づいた、暗号的に検証可能な ID を受け取ります。エージェントは OAuth 2.0 フローを使ってユーザーに代わって AWS リソースやサードパーティ製ツールに安全にアクセスでき、AgentCore Identity は Okta、Microsoft Entra ID、Amazon Cognito といった既存の企業 ID プロバイダーと、ユーザーの移行を必要とせずに統合できます。
エージェントの信頼
ID だけでは、エージェントを信頼すべきかどうかには答えられません。業界はこの問題に積極的に取り組んでいます。Agent Naming Service (ANS) v2 は、現在 IETF の Internet-Draft (策定中) であり、すべてのエージェント ID を DNS ドメイン名に紐づけます。クライアントは、Bronze (PKI)、Silver (PKI + DANE)、Gold (PKI + DANE + 透明性ログ) という 3 つの検証ティアから、取引のリスクに見合った保証レベルを選択できます。
AWS Agent Registry によるエージェントのディスカバリ
Amazon Bedrock AgentCore を通じて利用できる AWS Agent Registry は、組織全体にわたってエージェント、スキル、MCP サーバー、カスタムリソースを発見するための一元化されたカタログを提供します。チームは再利用可能なエージェント機能を公開、バージョン管理、共有できます。利用者は、識別子やエンドポイントを事前に知らなくても、自然言語または構造化された検索を通じてエージェントを発見できます。組み込みのガバナンス制御により、利用者がレジストリにどのようにアクセスするか、レコードが発見可能になる前に承認を必要とするかどうかを決定します。まとめると、AgentCore Identity が ID の基礎的な証明を提供し、Agent Registry がディスカバリを解決し、ANS のような新興の信頼フレームワークがマルチシグナルによる信頼評価の隔たりを埋めることを目指しています。
9. テナントごとのコスト追跡とオブザーバビリティ
正確なマルチテナントのコスト配分には、エージェントの呼び出しごとにテナントタグ付きのメトリクスをロギングソリューションに送出し、入出力トークン、ツール呼び出し、実行時間を記録する、アプリケーションレベルの計装が必要です。テナントコンテキストを含む構造化ロギングにより、使用パターン、パフォーマンスのボトルネック、キャパシティプランニングを詳細に分析できます。AgentCore Observability は、Amazon CloudWatch を基盤とする OpenTelemetry 互換の統合により、エージェントのワークフローをリアルタイムで可視化し、エージェント実行の各ステップを詳細に可視化します。
10. ガードレール: コンテンツの安全性
マルチテナントのガードレールは、3 つの実施ポイントで安全性とコンプライアンスを実施します。前処理の入力ガードレールは、エージェントが処理する前にユーザー入力を検証し、悪意のあるプロンプトやプロンプトインジェクションをブロックし、ヘルスケアの HIPAA や金融の PCI-DSS といったテナント固有のコンプライアンス要件に基づいて PII をサニタイズします。後処理の出力ガードレールは、エージェントの応答について事実の正確性を検証し、ハルシネーションを検出し、フォーマットの準拠を確認し、テナント境界を越えた機密データの漏洩をスキャンします。ガードレールはテナントまたはティアごとに適用でき、毒性検出、コンテンツフィルタリング、カスタムのブロック対象用語の設定を提供します。オブザーバビリティのメトリクスでは、トリガー率、カテゴリ別のブロックされたリクエスト、誤検知率を追跡して継続的な改善につなげます。Amazon Bedrock Guardrails は、拒否トピック、コンテンツフィルター、単語フィルター、機密情報の編集に対する設定可能なポリシーを備えたコンテンツフィルタリングと安全性制御を提供し、すべてのモデルとのやり取りにわたって責任ある AI のデプロイをサポートします。
これら 10 個のコンポーネントは、マルチテナントエージェントを設計するための包括的なフレームワークとなります。続くセクションでは、これらの中核コンポーネントを念頭に置きながら、AgentCore でのサイロ、プール、ブリッジの各モデルの実装を解説します。
AgentCore でのサイロモデルの実装
次の図に示すように、サイロモデルでは、各テナントが専用の Bedrock AgentCore Runtime、Bedrock AgentCore Gateway、Bedrock AgentCore Memory を持ち、それぞれが個別の AWS IAM 境界の背後にスコープされた、完全に分離されたスタック内で動作できます。メモリには長期、短期、エピソード記憶など複数の分類があり、テナントの要件に応じて設定する必要があります。
主要なアーキテクチャコンポーネント
- サイロ化されたエージェント層 – テナント固有の権限のために個別の IAM 実行ロールでデプロイされた専用の AgentCore Runtime。
- サイロ化されたゲートウェイ – MCP を使ったツールオーケストレーションのための専用 AgentCore Gateway。実行ロールに基づいてデータ層へのアクセスがスコープされます。
- サイロ化されたエージェントメモリ – 階層的な名前空間分離を備えた専用の AgentCore Memory。すべての名前空間パスにテナント ID を含める必要がなくなります。エージェントは IAM ロールを通じてテナント固有のメモリにアクセスします。
- サイロ化されたデータ層 – 最大限のデータ分離のための専用のツール、ナレッジベース、データベース、バックエンドリソース。
リクエストフロー
- 認証 – ユーザーは ID プロバイダーを使って認証し、テナントコンテキスト (テナント ID とサブスクリプションのティア) を含む JWT トークンを受け取ります。
- SaaS アプリケーションプロキシによるルーティング – SaaS アプリケーションプロキシは、テナントコンテキストに基づいてどのエージェントを呼び出すかを決定します。これには、テナントとエージェントのデプロイの間にマッピング設定を確立する必要があり、これは通常 SaaS コントロールプレーンの一部となる機能です。プロキシは、アプリケーションレベルのリクエストを AgentCore Runtime の API 呼び出し (InvokeAgent) に変換し、テナントの JWT トークンを付与します。
- エージェントの実行 – AgentCore Runtime は AgentCore Identity を使って JWT を検証し、分離された microVM セッションを作成し、エージェントの推論を開始します。さらに、AgentCore Identity の JWT オーソライザーでカスタムクレームを設定することで、テナント ID がこのエージェントの呼び出しを認可されているか (例: 「tenant_id = テナント A の場合のみ許可」) を検証します。エージェントは、ランタイムの IAM 実行ロールを使ってテナント固有の AgentCore Memory にアクセスします。
- AgentCore Gateway を使ったツールアクセス – エージェントがツールを呼び出す必要がある場合、特定のテナントの MCP ツールにアクセスするようにスコープされた専用の AgentCore Gateway を呼び出します。ゲートウェイは次の処理を行います。
- AgentCore Identity を使って JWT を検証します。
- 検証済みのトークンからテナントコンテキストを抽出し、カスタムインターセプターを使って、ゲートウェイが対象のテナントにマッピングされていることを確認します。
- サイロ化されたテナント固有のバックエンドリソース (API、データベース、ナレッジベース) と統合します。
- 応答フロー – ツールの応答はゲートウェイを通じてエージェントに戻り、エージェントは推論を完了します。サイロ化されたエージェントは、SaaS アプリケーションプロキシに返す前にテナント固有のフォーマットを適用します。プロキシは応答をユーザーに返します。
サイロパターンは、各顧客のエージェントセッション、ツールアクセス、メモリが完全に封じ込められ、処理のきっかけとなったアラートを発した顧客にコストが直接配分されるように設計されています。トレードオフは、各顧客がリソースを共有するのではなく専用リソースを実行するため、運用負荷が高くなる点です。しかし、セキュリティが重要でコンプライアンスに敏感なワークフローでは、影響範囲が限定されることから、これが適切な選択になります。
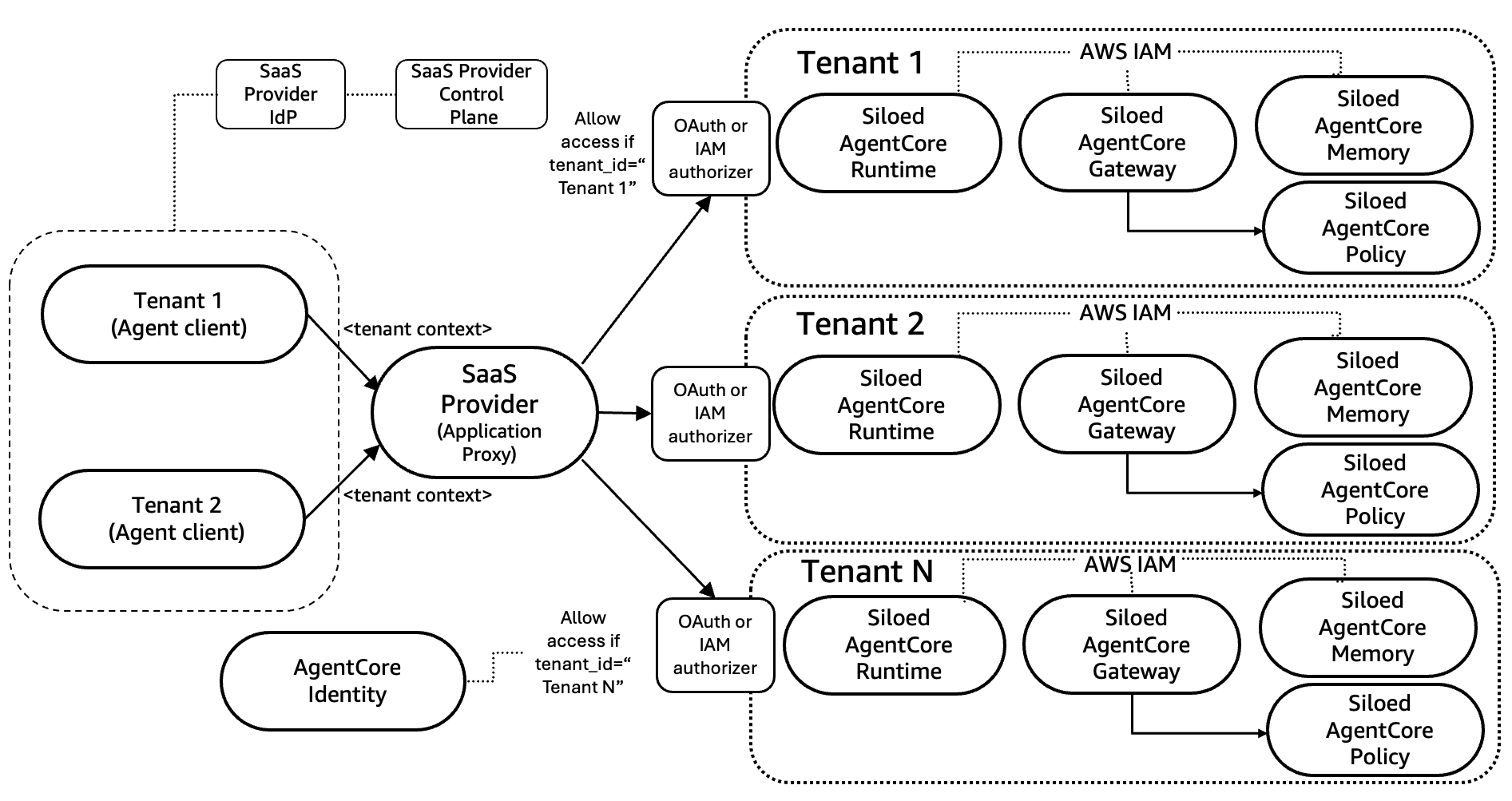
図 2: AgentCore によるサイロモデル
AgentCore でのプールモデルの実装
次の図に示すように、プールモデルでは複数のテナント間でリソースを共有できるため、リソース利用率を最大化し、運用効率を実現するアーキテクチャを設計できます。
主要なアーキテクチャコンポーネント
- プール化されたエージェント層 – 複数のテナント間で共有される AgentCore Runtime とエージェントロジック。
- プール化されたゲートウェイ – MCP を使ったツールオーケストレーションのための一元化された AgentCore Gateway。
- プール化されたエージェントメモリ – テナントコンテキストに基づいて分割された共有 AgentCore Memory。
- プール化されたデータ層 – 共有のツール、ナレッジベース、データベース、バックエンドリソース。
- プール化された ID 管理 – JWT ベースのテナントコンテキスト伝播を備えたプール化された ID プロバイダー。
リクエストフロー
- 認証 – ユーザーは ID プロバイダーを使って認証し、テナントコンテキスト (テナント ID とサブスクリプションのティア) を含む JWT トークンを受け取ります。
- SaaS アプリケーションプロキシによるルーティング – SaaS アプリケーションはパススルーとして機能し、テナントコンテキストを含む入力リクエストを、プール化された AgentCore Runtime で動作するエージェントにルーティングします。SaaS アプリケーションプロキシは、アプリケーションレベルのリクエストを AgentCore Runtime の API 呼び出し (InvokeAgent) に変換し、テナントの JWT トークンを付与します。
- エージェントの実行 – AgentCore Runtime は AgentCore Identity を使って JWT を検証し、分離された microVM セッションを作成し、JWT からテナントコンテキストを抽出してエージェントの推論を開始します。エージェントは、名前空間ベースの分割 (例: actor_id: 「tenant-a:user-123」) を使ってテナントスコープの AgentCore Memory にアクセスします。
- AgentCore Gateway を使ったツールアクセス – エージェントがツールを呼び出す必要がある場合、汎用的なルーティングではなく MCP ツールのオーケストレーション専用に設計されたプール化された AgentCore Gateway を呼び出します。ゲートウェイは次の処理を行います。
- AgentCore Identity を使って JWT を検証します。
- 検証済みのトークンからテナントコンテキストを抽出します。
- ツール呼び出しをプール化されたバックエンドリソース (API、データベース、ナレッジベース) にルーティングします。
- テナントスコープの認証情報と設定を通じてツールレベルの分離を実施します。
- 横断的な関心事に対してポリシーの実施とインターセプターを適用します。
- 応答フロー – ツールの応答はゲートウェイを通じてエージェントに戻り、エージェントは推論を完了します。エージェントの応答はランタイムを通じて、セラー (販売者) が運用するプロキシに戻り、プロキシはユーザーに返す前にテナント固有のフォーマットを適用します。
プールモデルは非常に効率的で、多数の小規模テナントを抱える場合には唯一の選択肢になることもあります。トレードオフは、きめ細かなアクセス制御のテストをより厳密に行う必要があり、コストをテナントに配分するためにより多くの計装が必要になる点です。
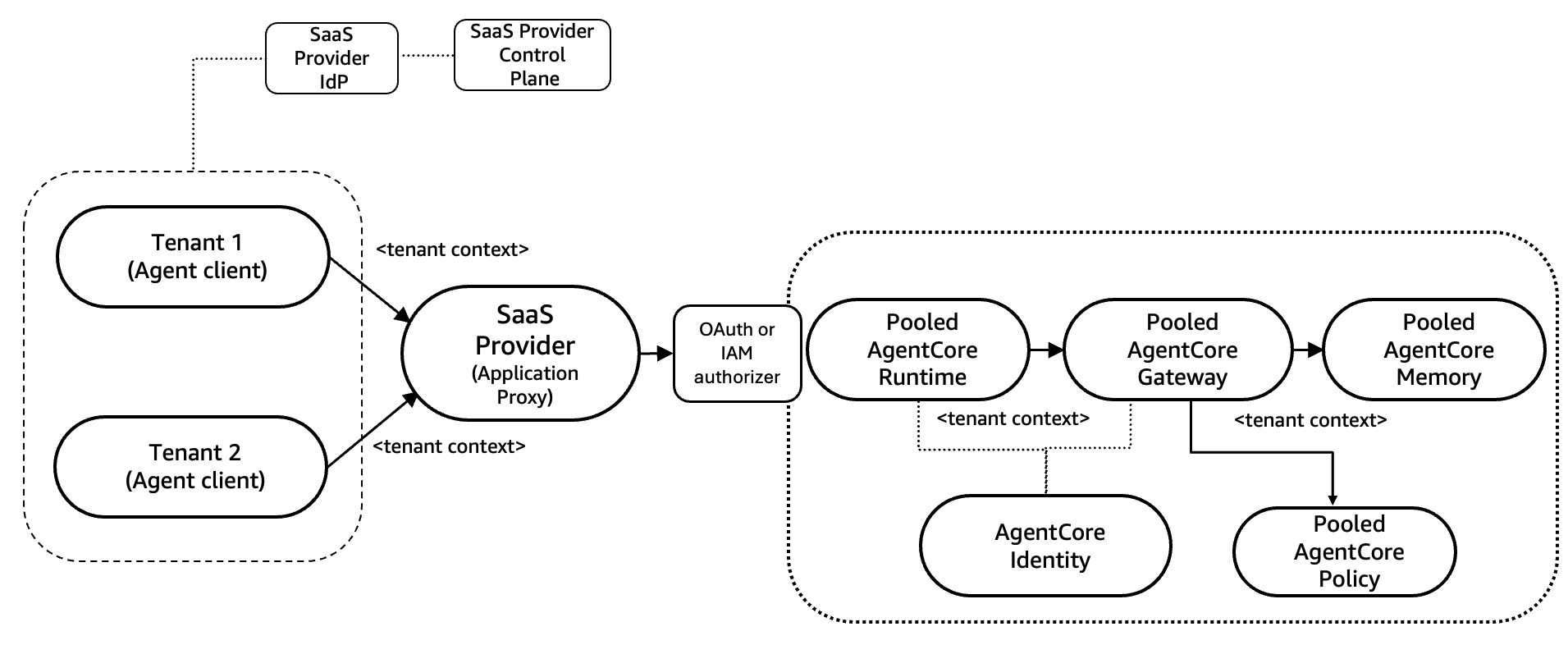
図 3: AgentCore によるプールモデル
AgentCore でのブリッジモデルの実装
ブリッジモデル (ハイブリッドモデル) は、サイロとプールのデプロイパターンの戦略的な中間に位置します。このアプローチは、共有インフラストラクチャのコスト効率と、分離されたデータリソースのセキュリティ上の利点を組み合わせます。
ニーズに応じて、ブリッジパターンはさまざまな方法で実装できます。
- プレミアムティアのテナントにはサイロ化された AgentCore Runtime/ゲートウェイ/ツール/メモリを、標準ティアにはプール化された共有の AgentCore Runtime/ゲートウェイ/ツール/メモリを使う
- サイロ化されたランタイムと、プール化されたゲートウェイ/ツールおよびメモリを使う
- その他
考え方は、特定のテナント分離パターンに縛られるのではなく、各層やコンポーネントごとにテナンシーを選択できるようにすることです。このアプローチは、実装に応じて両方のアプローチの利点を組み合わせます。たとえば SOC アナリストのユースケースでは、各調査が独自の分離された microVM で実行されるため、プール化されたエージェントランタイムがエージェントをホストして推論を行う一方で、ゲートウェイをサイロ化してメール API のやり取りやその他のダウンストリームのテナントリソースを処理する、といった構成が考えられます。
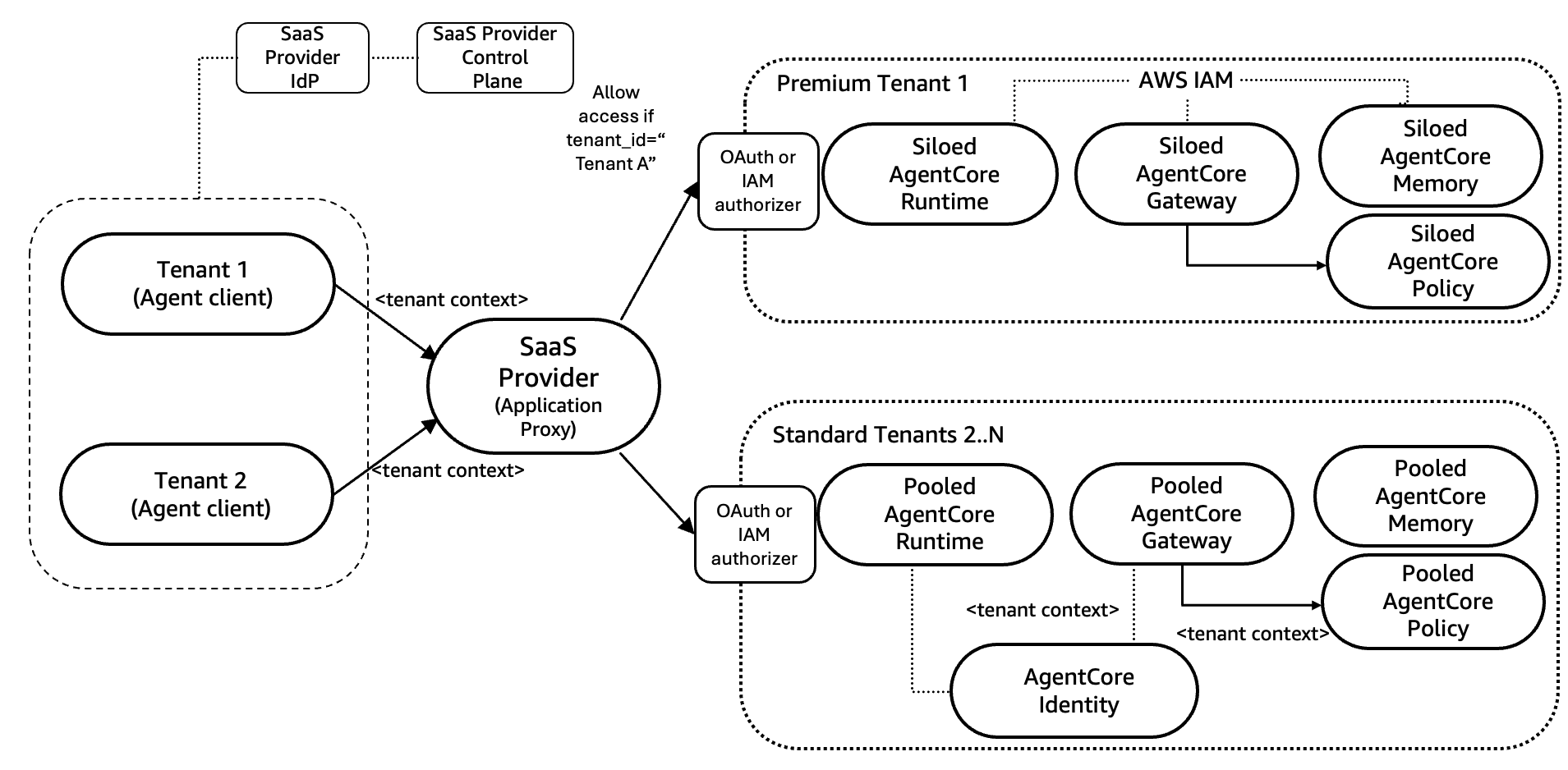
図 4: AgentCore によるブリッジモデル (パターン 1)
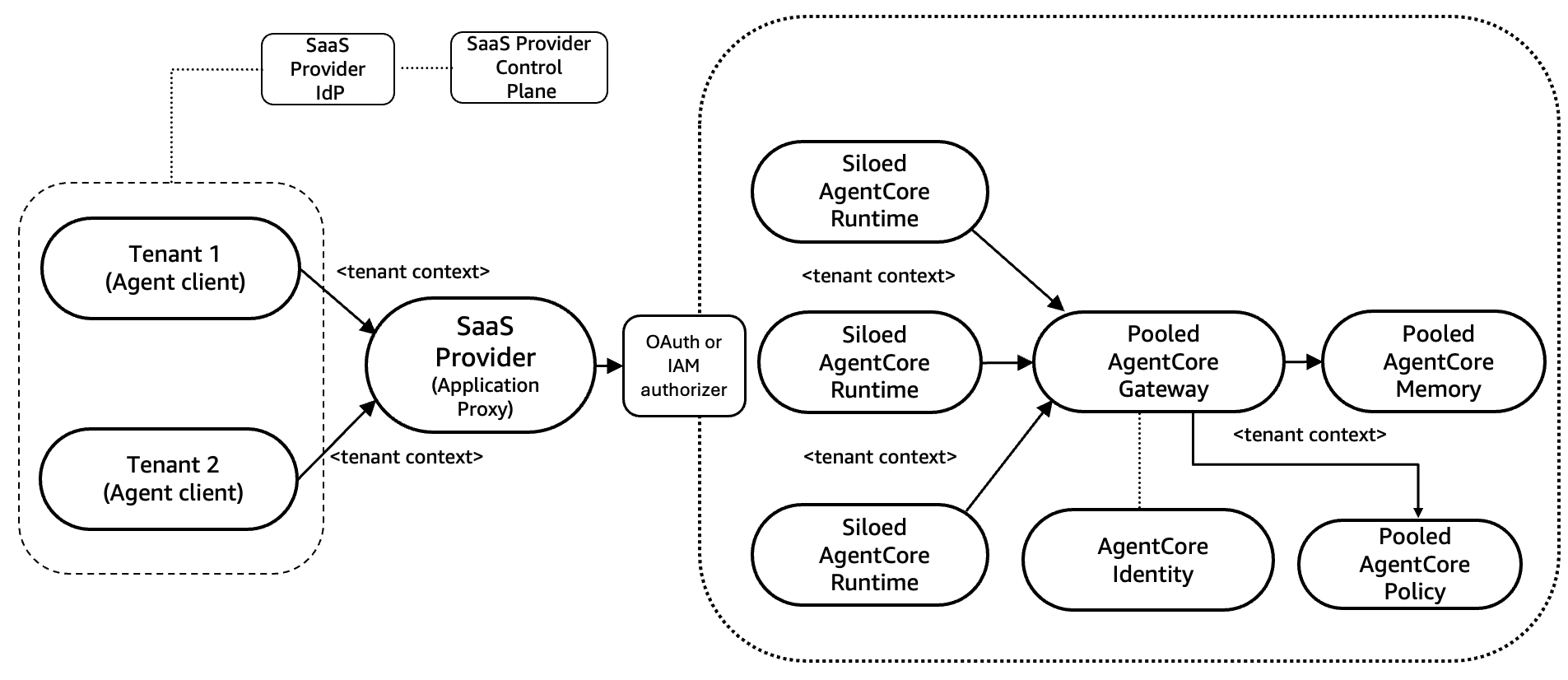
図 5: AgentCore によるブリッジモデル (パターン 2)
次のステップ
本記事では、マルチテナントエージェントを構築するための基礎的な概念を取り上げました。今後の記事では、これらの概念の実装面をより深く掘り下げます。具体的には、設計上の検討事項のセクションで概説したコンポーネントを組み込みながら、プールとサイロの両方のデプロイモデルのエンドツーエンドの実装を順を追って解説します。
まとめ
本番環境に対応したマルチテナントのエージェント型アプリケーションを構築するには、機能する AI エージェントだけでは不十分です。テナント分離、ID 管理、コスト配分、そしてあらゆる層でのセキュリティに対処する、包括的なアーキテクチャのアプローチが求められます。Amazon Bedrock AgentCore は、これらの課題に取り組むために必要な基礎的なプリミティブ (基本要素) を提供し、特定のティアリング戦略やコンプライアンス要件に合わせて調整できる、サイロ、プール、ブリッジの各モデルを通じた柔軟なデプロイパターンを提供します。専用インフラストラクチャを必要とするエンタープライズ顧客にサービスを提供する場合でも、数百もの小規模テナントにわたってコストを最適化する場合でも、AgentCore の統合された Runtime、Gateway、Memory、Identity、Observability の各コンポーネントを使えば、車輪の再発明をせずに、安全でスケーラブルなマルチテナントのエージェント型ワークフローを構築できます。これらのプリミティブは連携して、テナントのデータ分離、スコープされたツールアクセス、正確なコスト配分、セキュリティ境界の維持を支援し、マルチテナントエージェントアーキテクチャの複雑さを、SaaS ビジネスの成長に合わせてスケールする、管理しやすく本番環境に対応したソリューションへと変えます。
Amazon Bedrock AgentCore でこれらのマルチテナントエージェントを構築する実践的な体験のために、マルチテナントエージェントのワークショップをぜひお試しください。
著者について
この記事は Kiro が翻訳を担当し、Solutions Architect の Kensuke Fukumoto がレビューしました。