Amazon Web Services ブログ
専用の AWS Glue VPC を使用して複数の VPC 間で ETL ジョブに接続し、実行する
多くの組織では、Amazon VPC サービスに基づく複数の VPC を含む設定を使用し、セキュリティ、監査、コンプライアンス目的で個別の VPC で隔離されたデータベースが使用されます。このブログ記事では AWS Glue を使用して、複数の VPC にあるデータベースで、抽出、変換、ロード (ETL)、クローラー操作を実行する方法を示します。
ここで紹介するソリューションは、専用の AWS Glue VPC とサブネットを使用して、異なる VPC に配置されたデータベースに対して次の操作を実行します。
- シナリオ 1: Amazon RDS for MySQL データベースからデータを取り込み、これを AWS Glue で変換し、結果を Amazon Redshift データウェアハウスに出力します。
- シナリオ 2: Amazon RDS for MySQL データベースからデータを取り込み、これを AWS Glue で変換し、結果を Amazon RDS for PostgreSQL データベースに出力します。
このブログ記事では、1 つの VPC の 1 つのソースから消費し、別の VPC の別のソースに出力する ETL パイプラインを構築するために必要なステップを説明します。複数の VPC で設定し、データベースインスタンスがセキュリティ、監査、その他の目的で複数の VPC に分離されている状況を再現します。
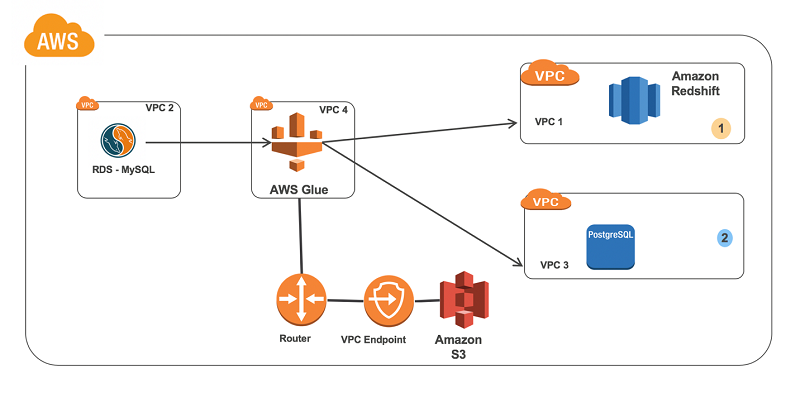
このソリューションでは、AWS Glue 専用の VPC を作成します。次に、AWS Glue VPC と他のすべてのデータベース VPC との間で VPC ピアリングを設定します。その後、AWS Glue が正常に機能するように、Amazon S3 エンドポイント、ルートテーブル、セキュリティグループ、IAM を設定します。最後に、AWS Glue 接続と AWS Glue ジョブを作成して、手元にあるタスクを実行します。
ステップ 1: VPC の設定
これらのシナリオをシミュレートするために、それぞれの IPv4 CIDR 範囲を持つ 4 つの VPC を作成します。(注意: VPC ピアリングを使用する場合、CIDR 範囲は重複できません)。
| VPC 1 | Amazon Redshift | 172.31.0.0/16 |
| VPC 2 | Amazon RDS for MySQL | 172.32.0.0/16 |
| VPC 3 | Amazon RDS for PostgreSQL | 172.33.0.0/16 |
| VPC 4 | AWS Glue | 172.30.0.0/16 |
主な設定の注意事項:
- AWS Glue VPC には、AWS Glue が使用するプライベートサブネットが少なくとも 1 つ必要です。
- DNS ホスト名がすべての VPC で有効化されていることを確認します (後から IP アドレスでデータベースを参照する予定がない限りお勧めしません)。
ステップ 2: VPC ピアリング接続の設定
次に VPC をまとめて、AWS Glue がすべてのデータベースターゲットおよびソースと通信できるようにピアリングします。AWS Glue リソースはプライベートアドレスのみで作成されるため、このアプローチが必要です。したがって、これらはパブリックデータベースエンドポイントなどのパブリックアドレスと通信するためにインターネットゲートウェイを使用することはできません。データベースのエンドポイントがパブリックの場合には、VPC 間のピアではなく、AWS Glue でネットワークアドレス変換 (NAT) ゲートウェイを使用することもできます。
次のピアリング接続を作成します。
| リクエスタ | アクセプタ | |
| ピア 1 | 172.30.0.0/16- VPC 4 | 172.31.0.0/16- VPC 1 |
| ピア 2 | 172.30.0.0/16- VPC 4 | 172.32.0.0/16 -VPC 2 |
| ピア 3 | 172.30.0.0/16- VPC 4 | 172.33.0.0/16- VPC 3 |
これらのピアリング接続は、必要に応じて別々の AWS リージョン間で行うことができます。データベース VPC は一緒にピアリングされません。代わりにすべてが AWS Glue VPC とピアリング接続します。これは AWS Glue が独自の VPC から各データベースに接続するためです。データベースは互いに接続しません。
主な設定の注意事項:
- Amazon VPC ドキュメントの説明に従って、VPC ピアリング接続を作成します。リクエスタに AWS Glue VPC を選択し、アクセプタにデータベース用の VPC を選択します。
- VPC ピアリングリクエストを承認します。別の AWS リージョンにピアリングする場合は、その AWS リージョンに切り替えてリクエストを承認します。
重要: 各ピアリング接続用のドメインネームサービス (DNS) 設定を有効にします。これを行うことで、AWS Glue がデータベースエンドポイントのプライベート IP アドレスを取得できるようになります。それ以外は、AWS Glue はデータベースのエンドポイントをパブリック IP アドレスで解決します。AWS Glue は NAT ゲートウェイなしで、パブリック IP アドレスに接続することはできません。

ステップ 3: AWS Glue サブネット用に Amazon S3 エンドポイントを作成する
Amazon S3 エンドポイントを AWS Glue VPC (VPC 4) に追加する必要があります。設定時、エンドポイントをプライベートサブネットが使用するルートテーブルに関連付けます。AWS Glue の S3 エンドポイント作成の詳細については、AWS Glue ドキュメントの Amazon S3 用の Amazon VPC エンドポイントを参照してください。
AWS Glue は S3 を使用してスクリプトと一時データを保存し、Amazon Redshift にロードします。
ステップ 4: ルートテーブル設定の作成
それぞれのサービスのサブネットで使用される、ルートテーブルに次のルートを追加します。これらのルートは、既存の設定と一緒に構成されます。
| VPC 4—AWS Glue | 宛先 | ターゲット |
| ルートテーブル | 172.33.0.0/16- VPC 3 | ピア 3 |
| 172.31.0.0/16- VPC 1 | ピア 1 | |
| 172.32.0.0/16- VPC 2 | ピア 2 |
| VPC 1—Amazon Redshift | 宛先 | ターゲット |
| ルートテーブル | 172.30.0.0/16- VPC 4 | ピア 1 |
| VPC 2—Amazon RDS MySQL | 宛先 | ターゲット |
| ルートテーブル | 172.30.0.0/16- VPC 4 | ピア 2 |
| VPC 3—Amazon RDS PostgreSQL | 宛先 | ターゲット |
| ルートテーブル | 172.30.0.0/16- VPC 4 | ピア 3 |
主な設定の注意事項:
- AWS Glue VPC のルートテーブルには、すべての VPC へのピアリング接続があります。これにより、AWS Glue はすべてのデータベースへの接続を開始できるようになります。
- すべてのデータベース VPC は、ピアリング接続を AWS Glue VPC に戻します。これらの接続は、リターントラフィックが AWS Glue に到達することを可能にするためにあります。
- S3 エンドポイントが AWS Glue VPC のルートテーブルに存在することを確認します。
ステップ 5: データベースセキュリティグループを更新する
各データベースのセキュリティグループは、AWS Glue の AWS Glue VPC からリスニングポート (3306、5432、5439 など) へのトラフィックをこれに接続できるように許可する必要があります。送信元 IP アドレス範囲をできる限り制限することも良いアイディアです。
これを達成するために、2 つの方法があります。AWS Glue ジョブがリソースと同じ AWS リージョン内にあれば、ソースを AWS Glue で使用するセキュリティグループとして定義できます。AWS Glue を使用して、AWS リージョン間で接続する場合には、代わりに AWS Glue VPC でプライベートサブネットから IP 範囲を指定します。以下の例では、AWS Glue ジョブにセキュリティグループを使用し、データソースはすべて同じ AWS リージョンにあります。
データベースのセキュリティグループを設定するだけでなく、AWS Glue はそれ自身からのすべての受信トラフィックを許可する特別なセキュリティグループが必要です。0.0.0.0/0 からのトラフィックはセキュアではないため、セキュリティグループから発信されたすべてのトラフィックを許可するシンプルな自己参照ルールを作成します。この目的で新しいセキュリティグループを作成することも、既存のセキュリティグループを変更することもできます。次の例では、AWS Glue 接続の作成時に、後で使用する新しいセキュリティグループを作成します。
セキュリティグループ Amazon RDS for MySQL は AWS Glue からのトラフィックを許可する必要があります。

Amazon RDS for PostgreSQL 同じポートからリスニングポートへのトラフィックを許可します。

Amazon Redshift ではこれを次のように行います。

AWS Glue ではこれを次のように行います。

ステップ 6: IAM の設定
Amazon S3 にアクセスする AWS Glue IAM ロール があることを確認してください。特定の Amazon S3 リソースにアクセスするための独自のポリシーを提供したい場合があります。データソースはs3:ListBucketとs3:GetObjectアクセス許可が必要です。データターゲットはs3:ListBucket、s3:PutObject、s3:DeleteObjectアクセス許可が必要です。リソース用の Amazon S3 ポリシー作成についての情報は、IAM ドキュメントの ポリシーとアクセス許可 を参照してください。
ロールは次のようになります。

また、ユースケースに合わせてより制限された S3 ポリシーを作成することもできます。
ステップ 7: AWS Glue 接続の設定
AWS Glue での Amazon RDS for MySQL 接続は次のようになります。

Amazon Redshift 接続は次のようになります。

Amazon RDS for PostgreSQL 接続は次のようになります。

ステップ 8: AWS Glue ジョブの設定
主な設定の注意事項:
- ソースデータベース (Amazon RDS for MySQL) から AWS Glue データカタログにテーブルメタデータをインポートするクローラーを作成します。このシナリオには、カタログ名 gluedb というデータベースが含まれています。クローラーはソースの Amazon RDS for MySQL データベースからのサンプルテーブルをこれに追加します。
- 次に示すように、ソース接続または宛先接続のどちらかを使用して、サンプルジョブを作成します。(このステップは、AWS Glue ジョブがネットワーク接続を確立し、データベースの VPC とピア接続に必要な Elastic Network Interface を作成するために必要です)。
- このシナリオでは pyspark コードを使用して、Amazon RDS for MySQL から Amazon Redshift へのロード操作を実行します。Amazon RDS for MySQL から Amazon RDS for PostgreSQL への取り込みにも、同じようなジョブが含まれます。
- ジョブ実行後、テーブルがターゲットデータベースに存在し、数が一致していることを確認します。
以下のスクリーンショットは、AWS Glue 管理コンソールでジョブを作成するステップを示しています。

![]()


以下は、ソーステーブルからターゲットインスタンスにデータをロードするいくつかの例を示しています。シンプルな 1 対 1 のマッピングがあり、変換は適用されません。データソースとデータシンク (ターゲット) 接続は、1 つの AWS Glue ジョブから複数の VPC にアクセスすることに注意してください。
サンプルスクリプト 1 (Amazon RDS for MySQL から Amazon Redshift へ)
サンプルスクリプト 2: Amazon RDS for MySQL から Amazon RDS for PostgreSQL へ (その他の RDS エンドポイントでも変更可能)
概要
このブログ記事では、複数の VPC に配置されたデータベースのジョブを実行できるように、AWS Glue を個別の VPC で実行するように設定する方法を学びます。
これを行う利点は次のとおりです。
- データベースと計算ノードから分離された、実行中の AWS Glue ジョブの個別の VPC と専用プール。
- 優れたセキュリティ制御とプロビジョニングのための、単一の VPC への専用の ETL 開発者アクセス。
その他の参考資料
この投稿記事が役に立つと思いましたら、リソースレベルの IAM アクセス許可とリソースベースポリシーを使用した AWS Glue データカタログへのアクセス制限と本番環境で Amazon Redshift Spectrum、Amazon Athena、および AWS Glue を Node.js で使用する も確認してください。
著者について
 Nivas Shankar はアマゾン ウェブ サービスのシニアビッグデータコンサルタントです。AWS プラットフォームでのビッグデータアプリケーションの構築において、企業顧客を援助し、密接に連携しています。物理学の修士号を取得している Nivas は、理論物理学概念に情熱を持っています。Nivas の楽しみは、妻と 2 人の可愛い子供たちと時間を過ごすことです。時間があるときは、子供たちをテニスとフットボールの練習に連れて行っています。
Nivas Shankar はアマゾン ウェブ サービスのシニアビッグデータコンサルタントです。AWS プラットフォームでのビッグデータアプリケーションの構築において、企業顧客を援助し、密接に連携しています。物理学の修士号を取得している Nivas は、理論物理学概念に情熱を持っています。Nivas の楽しみは、妻と 2 人の可愛い子供たちと時間を過ごすことです。時間があるときは、子供たちをテニスとフットボールの練習に連れて行っています。
 Ian Eberhart は AWS プレミアムサポートのビッグデータチームのクラウドサポートエンジニアです。彼は日常的に顧客と協力して、AWS プラットフォーム上でデータを移動およびソートするためのソリューションを探しています。時間があるときは、Ian は独立系の怪奇映画を観たり、サイクリングやハイキングを楽しんでいます。
Ian Eberhart は AWS プレミアムサポートのビッグデータチームのクラウドサポートエンジニアです。彼は日常的に顧客と協力して、AWS プラットフォーム上でデータを移動およびソートするためのソリューションを探しています。時間があるときは、Ian は独立系の怪奇映画を観たり、サイクリングやハイキングを楽しんでいます。