Amazon Web Services ブログ
Deep Dive: Amazon ECS マネージドインスタンスのプロビジョニングと最適化
この記事は Deep Dive: Amazon ECS Managed Instances provisioning and optimization (記事公開日: 2025 年 11 月 4 日) を翻訳したものです。
Amazon Elastic Container Service (Amazon ECS) マネージドインスタンスは、完全マネージドのコンピューティングオプションで、インフラストラクチャ管理のオーバーヘッドを排除しながら、Amazon Elastic Compute Cloud (Amazon EC2) の幅広い機能にアクセスできます。これには、インスタンスタイプの選択、リザーブドキャパシティへのアクセス、高度なセキュリティと監視設定の活用などの柔軟性が含まれます。ECS マネージドインスタンスは Amazon Web Service (AWS) にオペレーションを委託することでお客様の迅速な開始を支援します。総所有コストを削減し、チームがイノベーションをもたらすアプリケーションの構築に専念できるようします。
この記事では、ECS マネージドインスタンスが EC2 インスタンスを自動的にプロビジョニングして最適化し、ワークロードの高可用性とコスト効率のバランスを取る方法について詳しく説明します。
Amazon ECS マネージドインスタンスキャパシティープロバイダー
Amazon ECS の「キャパシティープロバイダー」はワークロードのコンピューティング能力を定義するインターフェースです。ECS クラスターには、サーバーレスコンピューティングでワークロードを起動するための AWS マネージドの FARGATE と FARGATE_SPOT キャパシティプロバイダーが自動的に含まれています。また EC2 インスタンス上でワークロードを実行するための独自の EC2 Auto Scaling グループ (ASG) キャパシティプロバイダーも作成できます。Amazon ECS マネージドインスタンス は、AWS Fargate のフルマネージドの体験と Amazon EC2 の柔軟性を組み合わせた新しいキャパシティプロバイダーで、両者の長所を兼ね備えています。ECS は、ワークロードの要件に応じて、AWS アカウント内でフルマネージドの EC2 インスタンスを迅速にプロビジョニングおよびスケーリングします。ECS マネージドインスタンスキャパシティプロバイダーは、コスト最適化された汎用インスタンスを自動的に選択します。vCPU とメモリの最小/最大、希望のインスタンスタイプ、CPU メーカー、アクセラレータタイプ、その他のインスタンスの仕様を指定することで、インスタンスの要件をカスタマイズできます。インスタンスの選択の詳細については、ドキュメントを参照してください。
プロビジョニングワークフロー
ECS マネージドインスタンスは、ワークロードを継続的に監視し、ワークロードの要件に基づいてタイムリーに新しい EC2 インスタンスを起動します。構成済みのサブネット内の Availability Zone (AZ) 間でタスクを自動的に分散することで、アプリケーションの可用性を高めます。新しいインスタンスを起動する際、ECS は最初に適切な AZ 分散を確保してから、各インスタンス内でタスクをビンパッキングし、コストを最適化します。これにより、高可用性とコスト効率のバランスが実現されます。さらに、複数のタスクを同じインスタンス上に配置することで、ECS マネージドインスタンスはインフラストラクチャコストを最適化するだけでなく、後続のタスクがインスタンスプロビジョニングの待ち時間を回避し、インスタンス上のコンテナイメージキャッシュの恩恵を受けるため、タスクの起動が高速化されます。ここでは、まず、インスタンスプロビジョニングのワークフローを説明し、その後、可用性とインフラストラクチャの最適化の側面について詳しく説明します。
次の図は、インスタンスのプロビジョニングワークフローを示しています。マネージドインスタンスキャパシティプロバイダーを通して 4 つの新しいタスクが起動されると、ECS は既存の管理対象インスタンスを評価して、利用可能な容量を判断します。ECS はタスクサイズと利用可能なインスタンスリソースに基づいて、できるだけ多くのタスクを現在実行中のインスタンスに配置します。この場合、2 つのタスクが他のタスクをホストしている既存の EC2 インスタンスに正常に配置されています。既存のインスタンスで収容できない残り 2 つのタスクについては、ECS が自動的に新しい EC2 インスタンスを起動します。この新しいインスタンスは、残りのタスクに十分な CPU とメモリを確保するためにタスクのリソース要件に基づいてプロビジョニングされ、タスクを AZ 間で均等に配置します。このビンパッキングアプローチは、タスクを効率的に共存させながら可用性を高めるために複数の AZ に分散させることで、リソースの利用を最大化し、インフラストラクチャコストを最小限に抑えます。
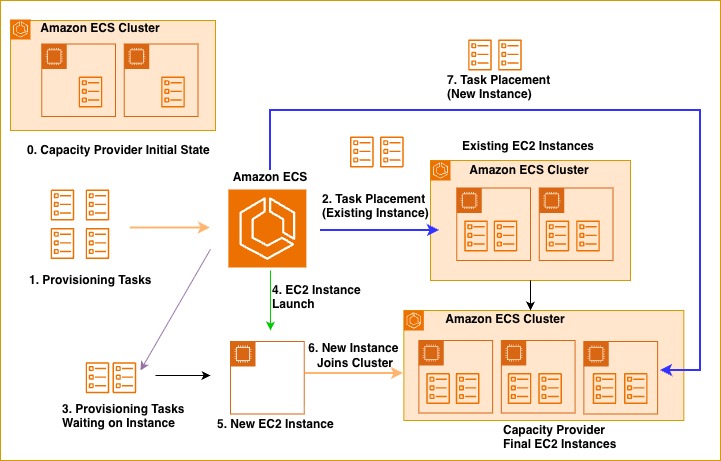
図 1: ECS マネージドインスタンスキャパシティプロバイダーにおける新規 ECS タスクの Run Task フロー
既存インスタンスの選択
ECS はインスタンスごとに正確なリソース管理を行い、CPU、メモリ、その他のリソースをリアルタイムに追跡します。インスタンスが ECS に登録されると、利用可能な容量は EC2 インスタンスのリソース合計から ECS エージェントに予約されたメモリを差し引いた値になります。ECS はインスタンスの登録時に、インスタンスタイプごとの実績データに基づいてエージェントが消費するリソース量を推定し、複数の並行タスクに十分なリソースを確保します。タスクの起動と終了に伴い、ECS はインスタンスの利用可能なリソース容量を動的に更新します。新しいタスクの配置では、ECS は既存のインスタンスにリソースが十分にあるかどうかを最初にチェックします。複数の適切なインスタンスが存在する場合、ECS はマネージドインスタンスキャパシティプロバイダーで構成されたサブネットによって AZ 分散を制御しながら、最大の回復力を得るために AZ 間でタスクを分散させることを優先します。既存のインスタンスでは最適な AZ 分散ができなくても、現在の AZ に容量がある場合、ECS は新しいインスタンスをプロビジョニングするのではなく、サービスの目標タスク数に早く到達するために既存の容量を使用することを優先し、可用性を高めます。その後、ECS は継続的な AZ 間での ECS サービスの調整によってワークロードを調整し、可用性をさらに高めるための最適な AZ 分散を実現します。
新規インスタンスの登録
ECS マネージドインスタンスが新しいタスクを既存のインスタンスに配置できない場合、そのタスクは新しいキャパシティを待つ間 PROVISIONING 状態になります。ECS は個々のインスタンスをプロビジョニングするのではなく、複数のアプリケーションから起動要求されたタスクをインテリジェントにバッチ処理します。これにより、レスポンス性と最適化の機会のバランスを取ることができます。ECS はリソース要件を全体的に分析し、最適なインスタンスタイプを選択しながら、タスクを AZ 間に分散させます。CPU、メモリ、ストレージの要件が異なるタスクを数百種類の利用可能なインスタンスタイプに配置することは、NP 完全な多次元ビンパッキング問題となります。ECS は First Fit Decreasing(FFD)アルゴリズムを採用しており、効率的なリソース使用率を維持しながら、数学的な完全性よりもシステムの応答性を優先し、多項式時間で最適に近い結果を提供ます。
インフラストラクチャの最適化
ECS マネージドインスタンスは、キャパシティプロバイダーの構成とワークロード要件に基づいて適切なサイズの EC2 インスタンスを起動します。時間の経過とともに、トラフィックパターンの変化や動的スケーリングにより、EC2 インスタンスがワークロード要件から外れる可能性があります。ECS マネージドインスタンスは、インフラストラクチャを継続的に最適化し、利用率の低いインスタンスをドレインし、タスクを既存の利用可能なリソースを持つインスタンスか、新たに適切なサイズでプロビジョニングされたインスタンスに再配置します。次の図は、利用率の低いインスタンスの最適化の動作を示しています。2 つのタスクが停止すると、ECS はリソースの非効率性を認識し、利用率の低いインスタンスを DRAINING としてマークします。これにより、インフラストラクチャが 3 つのインスタンスから 2 つに減り、サービスの可用性を維持しながら、不要なコンピュートコストを排除します。
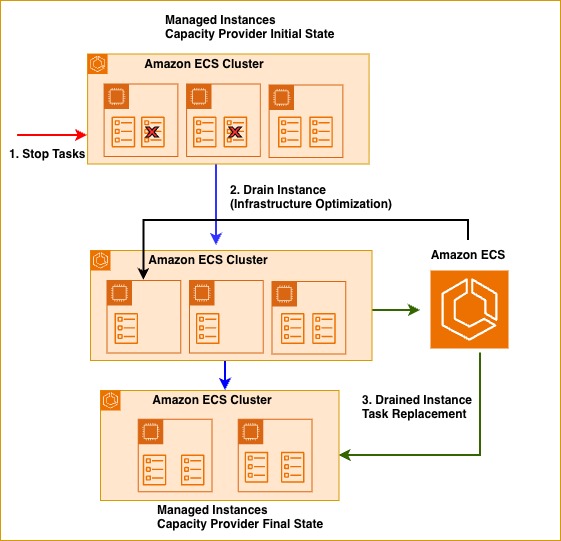
図 2: ECS マネージドインスタンスキャパシティプロバイダーが、リソース活用率を向上させるために、利用率の低いインスタンスをドレインする
ECS マネージドインスタンスは、実行中のタスクがないアイドル状態のインスタンスを自動的に削除するため、アクティブなリソースのみの支払いで済みます。次の図は、2 つのタスクがインスタンス上で停止した際の動作を示しています。ECS はアイドル状態のインスタンスを特定し、登録を解除します。これによりインスタンスの終了が開始され、2 つのインスタンスから 1 つのインスタンスにスケールダウンされます。同じメカニズムにより、以前ドレイン (タスクの移行) されたインスタンスも、空になった時点で自動的に登録解除と終了が行われます。
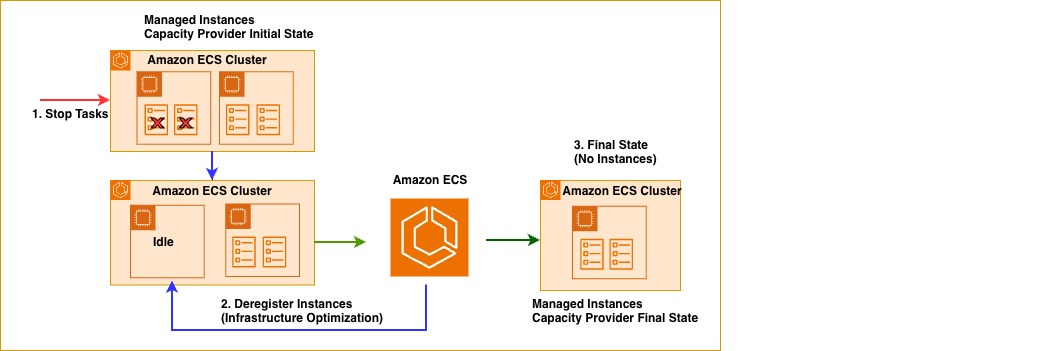
図 3: ECS マネージドインスタンスキャパシティプロバイダーが、リソース活用率を向上させるためにアイドル状態のインスタンスをドレインする
可用性
ECS マネージドインスタンスは、事前に設定されたサブネットに対して ECS サービスのタスクを AZ 間で自動的に分散させることで、アプリケーションの可用性を向上させます。ECS は新しいインスタンスを起動する際、まずインスタンスを事前に設定された全ての AZ に分散させ、その後それらのインスタンス上にタスクを配置して可用性を最大化します。複数のスケーリング操作を経て、ECS サービスがタスクが完全に AZ 間でバランスされていない状態に達した場合、AZ 間での ECS サービスの調整機能がインスタンス間でタスクを再分散するのに役立ちます。これには、インスタンスのスケールイン・アウトが必要になる場合があります。最終的な利点は、ECS がサービスタスクを主に AZ 間でバランスされた状態に保ち、次にインスタンス上で効率的にビンパッキングを行うことで、可用性とコスト最適化のバランスを最適化することです。
デモのウォークスルー
このウォークスルーでは、マネージドインスタンスキャパシティプロバイダーで構成された Amazon ECS クラスターをデプロイすることで、ECS マネージドインスタンスの実践的なデモを作成します。このセットアップには、CPU とメモリの要件が異なる 2 つの個別の ECS サービスが含まれています。ECS リソースをプロビジョニングするために、Amazon Virtual Private Cloud (Amazon VPC)、IAM、EC2 リソースもプロビジョニングします。AWS CLI を使用し、AWS CloudFormation 経由で初期リソースセットをプロビジョニングします。次に、ECS API に対する AWS CLI コマンドを使用してサービス内の ECS タスクの数を更新し、ECS が内部で EC2 インスタンスを管理する様子を観察します。このデモ全体を完了するのに約 40 分かかります。
前提条件
- CloudFormation、ECS、EC2 の操作権限を持つユーザー
- AWS CLI
手順
- この GitHub リポジトリから CloudFormation テンプレートをダウンロードします。
- vpc-stack.json、ecs-stack.json、nested-stack-coordinator.json - CloudFormation テンプレートを配置する S3 バケットを作成し、テンプレートを S3 バケットに配置します。
- CloudFormation テンプレートを上記の S3 バケットに配置します。
nested-stack-coordinator.jsonテンプレートで CloudFormation スタックを作成します。これにより、アカウントに 3 つの CloudFormation スタック (Coodinator Stack, VPC Stack and ECS stack) が作成されます。Coodinator Stack が VPC Stack と ECS stack を作成します。VPC Stack には VPC リソースが含まれ、ECS stack には ECS リソースが含まれます。- CloudFormation によって作成されるリソースは以下の通りです。
- マネージドインスタンスキャパシティプロバイダーを持つ 1 つの ECS クラスター
- 2 つの ECS サービス:
- ManagedInstancesService1: タスクあたり 1 vCPU、5.5GB メモリ
- ManagedInstancesService2: タスクあたり 1 vCPU、9.5GB メモリ
- AZ 間で分散された合計 4 つのタスク (サービスごとに 2 つ)
- マネージドインスタンスキャパシティプロバイダー内の 2 つの マネージドインスタンス
ECS クラスターと ECS サービス
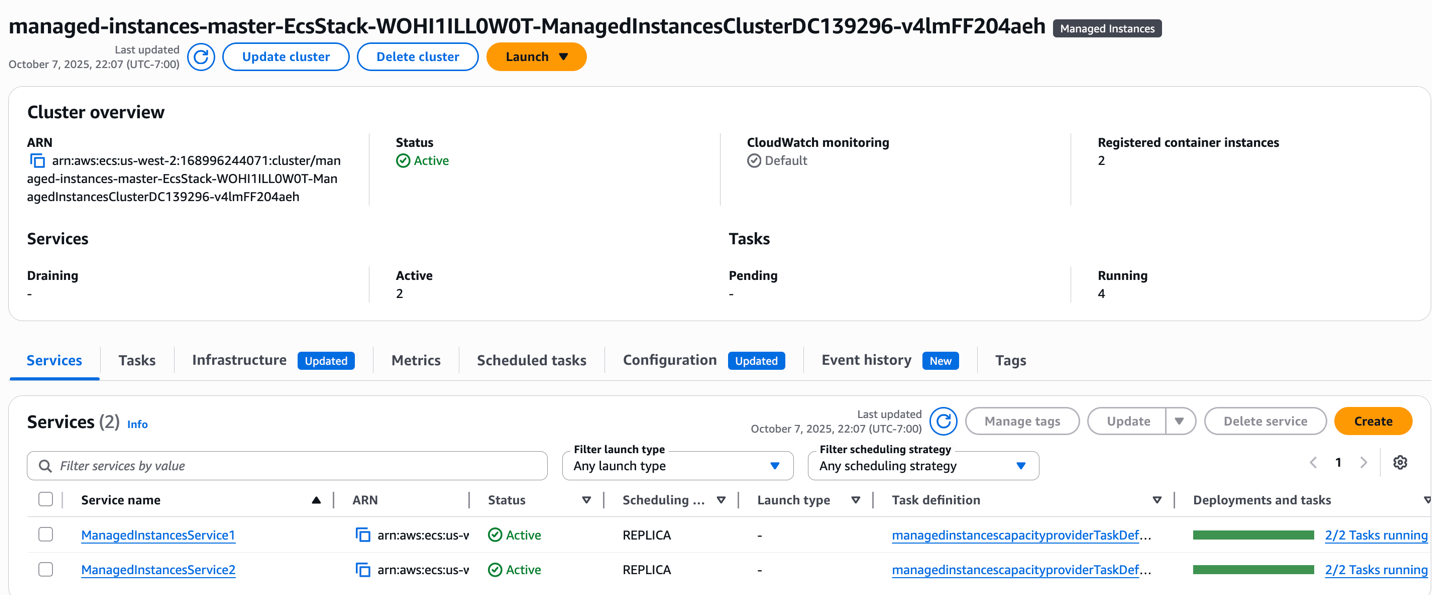 図 4: 1 つのクラスターで、サービスごとに 2 つのタスクが実行されている 2 つの ECS サービス
図 4: 1 つのクラスターで、サービスごとに 2 つのタスクが実行されている 2 つの ECS サービス
ECS タスク
アプリケーションは、高可用性を実現するために 2 つの AZ (us-west-2a と us-west-2b) に分散して 4 つの ECS タスクを実行しています。1 つの AZ で問題が発生した場合でも、アプリケーションは他の AZ から実行を継続するため、単一障害点がなくなり、サービスの可用性が一貫して確保されます。
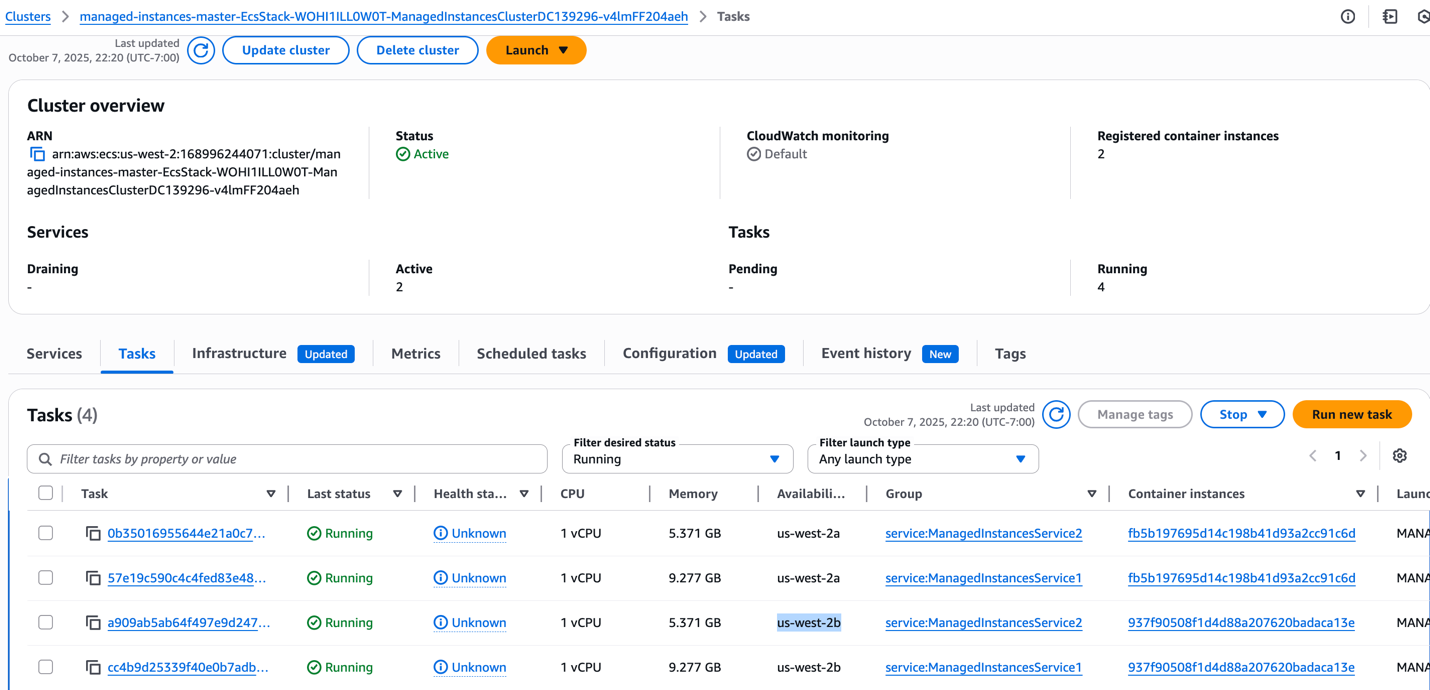 図 5: サービスごとにタスクのリソース設定が異なる 2 つの ECS サービスに対する 4 つの ECS タスク
図 5: サービスごとにタスクのリソース設定が異なる 2 つの ECS サービスに対する 4 つの ECS タスク
Amazon ECS マネージドインスタンス キャパシティプロバイダー
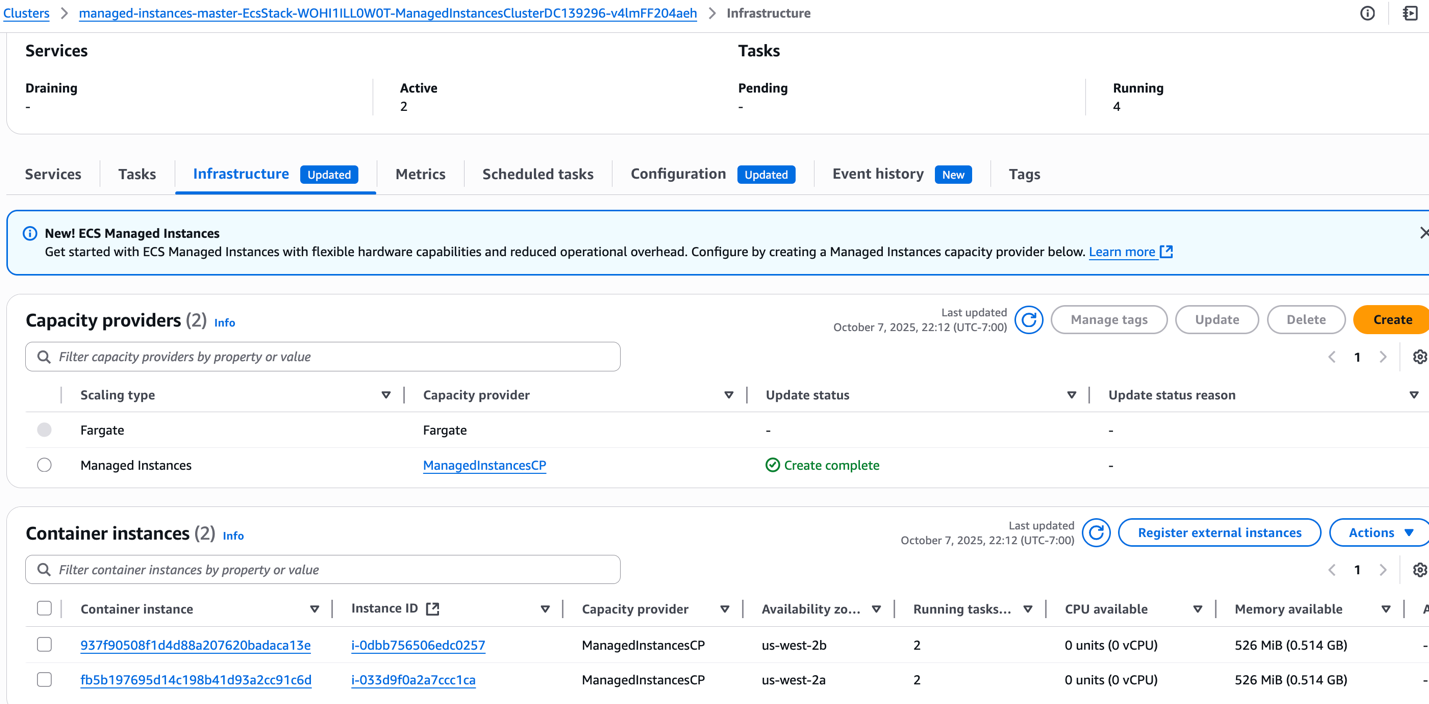 図 6: 2 つの AZ にまたがる 2 つのインスタンスで実行されているマネージドインスタンスキャパシティプロバイダー。リソースの利用が最適化される
図 6: 2 つの AZ にまたがる 2 つのインスタンスで実行されているマネージドインスタンスキャパシティプロバイダー。リソースの利用が最適化される
マネージドインスタンスキャパシティプロバイダーは、正確なリソース要件を分析しました。インスタンスごとに合計 15GB のメモリ (9.5GB + 5.5GB) と 2 つの vCPU が必要でした。ECS は、2 つの AZ で最適な r5a.large インスタンス (2 vCPU、16GB メモリ) をプロビジョニングし、高可用性を確保しつつリソース効率を最大化しました。各インスタンスでは、両方のサービスタスクが効率的に実行されています。16GB のメモリのうち 15GB が使用され、両方の vCPU も積極的に使用されています。この結果、手動による推測作業を排除し、効率的なリソース割り当てによってコストを削減しながら、アプリケーションに必要なパフォーマンスを維持する、インテリジェントな容量管理が実現されました。
- 次に、ManagedInstancesService1 の希望タスク数を 0 に設定して、ECS マネージドインスタンスのインテリジェントなリソース管理を実演します。この操作により、現在 2 つの r5a.large インスタンス上で実行中の 2 つのタスク (それぞれ 9.5GB のメモリ、1 vCPU) が停止します。ManagedInstancesService1 のタスクが削除されると、各インスタンスでは残りの ManagedInstancesService2 のタスク (それぞれ 5.5GB のメモリ、1 vCPU) のみが実行されます。これにより、r5a.large インスタンス (16GB、2 vCPU) で単一の 5.5GB タスクが実行され、未使用の容量が生じるリソース利用状況が作られます。
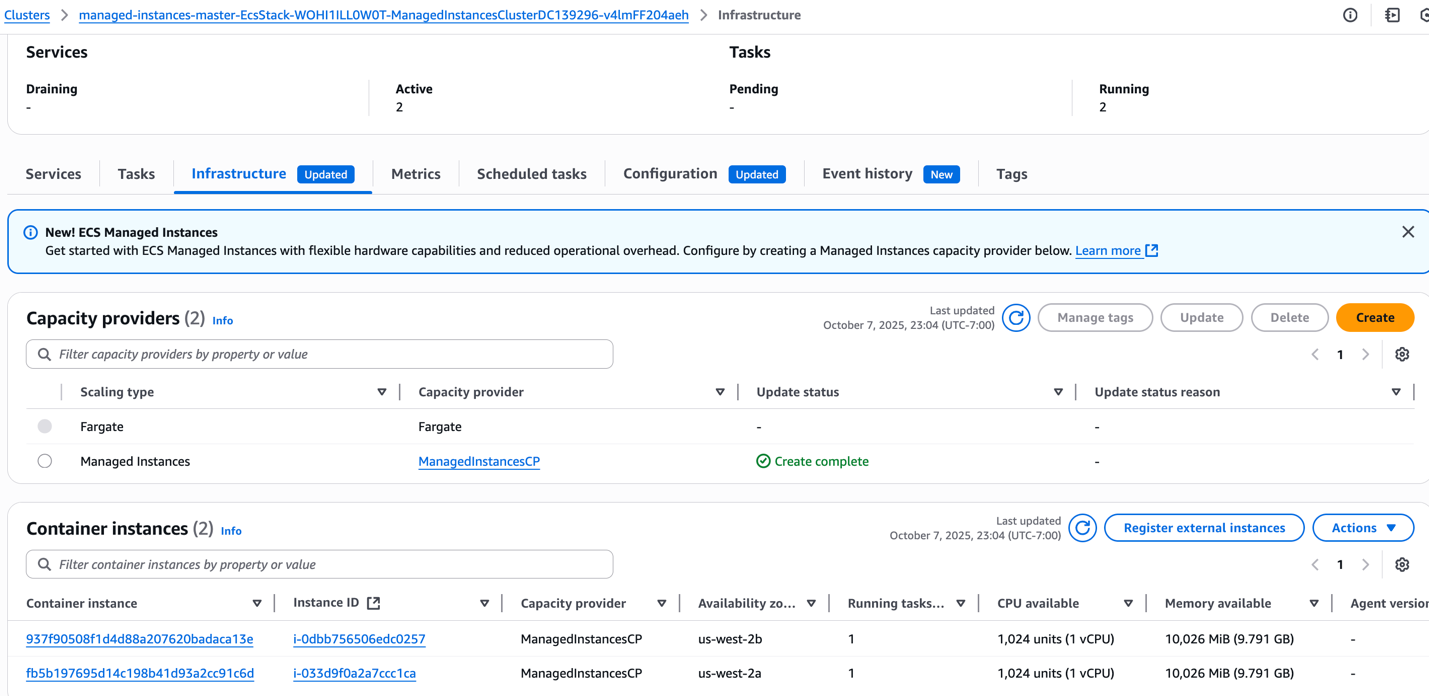
図 7: ECS タスクを停止すると、マネージドインスタンスキャパシティプロバイダーのインスタンスが過小利用になる
- ECS マネージドインスタンスキャパシティプロバイダー は、このようなリソースの非効率を素早く検出し、利用率の低いインスタンスの 1 つをドレインすることで対処します。現在のワークロードに対して両方のインスタンスが最適ではなくなりますが、システムはサービスの可用性を損なうリスクがあるため、同時にドレインすることはありません。代わりに、ECS は可用性を最優先するアプローチを取り、インスタンスを段階的にドレインします。最適化プロセス中に十分なアクティブ容量を維持することで、新しいタスクの配置や予期しないスケーリングイベントに対して常に容量を確保できます。
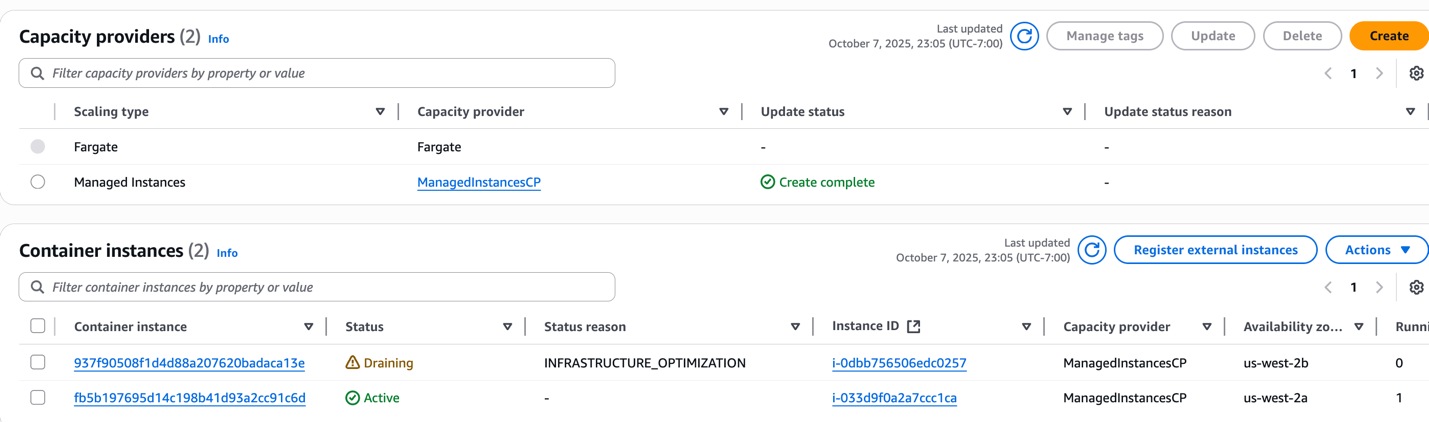 図 8: マネージドインスタンスキャパシティプロバイダーが利用率の低いインスタンスをドレインする
図 8: マネージドインスタンスキャパシティプロバイダーが利用率の低いインスタンスをドレインする
- ドレイン処理が完了すると、排除されたタスクは残りの us-west-2a のインスタンスに移動します。このインスタンスには十分なリソースが残っています。ECSマネージドインスタンスは、サービスの安定化を早めるため、新規プロビジョニングよりも既存の容量を優先します。両方の ManagedInstancesService2 タスクは、リソース活用を最大化するため、単一のインスタンス上で実行されます。一方で、ドレインされたインスタンスは空になります。ECS は自動的にこの空のインスタンスを登録解除し、終了させます。これにより、インフラストラクチャは 2 つのインスタンスから 1 つに縮小されます。これは、実際の需要に基づく継続的な適正化を示しています。ECS は、後の最適化ステップで AZ の分散を処理し、効率性と高可用性のバランスを取ります。
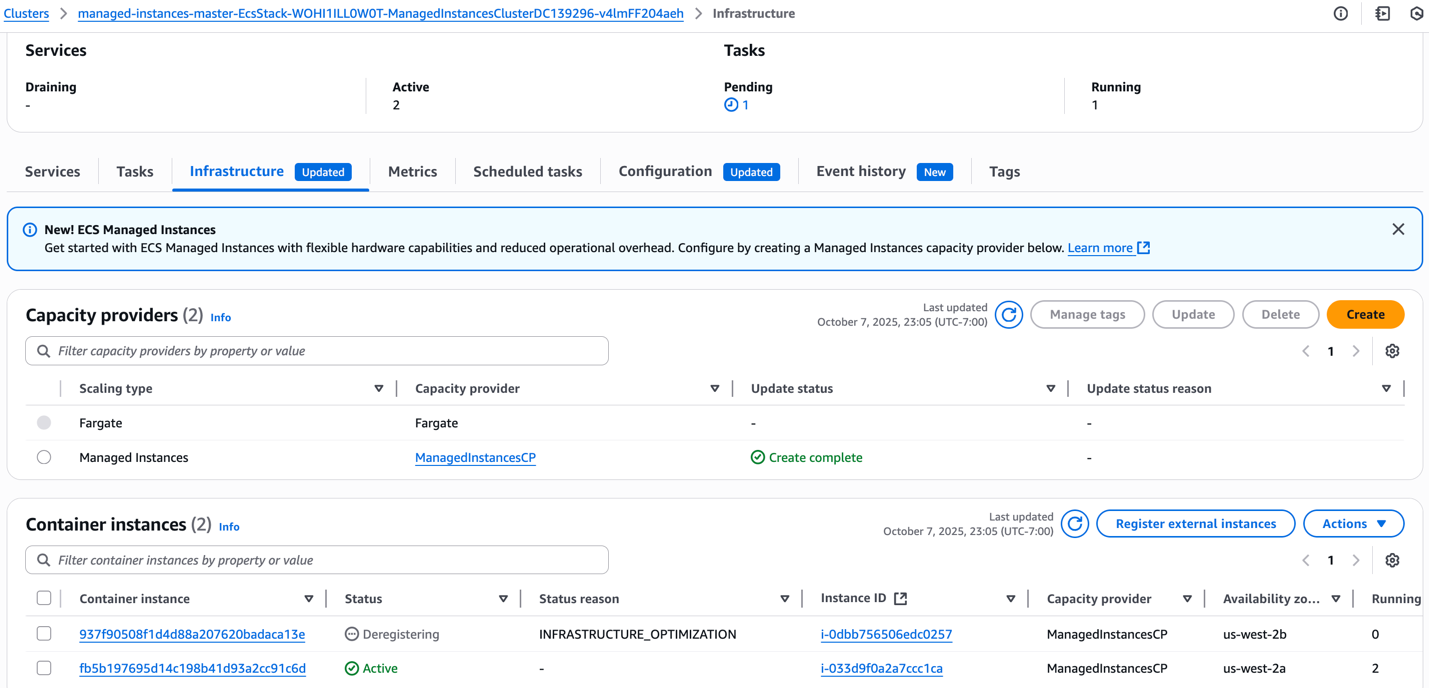 図 9: マネージドインスタンスキャパシティプロバイダーが、タスクのないアイドル状態のインスタンスを登録解除する
図 9: マネージドインスタンスキャパシティプロバイダーが、タスクのないアイドル状態のインスタンスを登録解除する
- ECS クラスターが安定した後、ECS は新しい AZ でタスクの置換を開始しながら、既存のタスクを停止することで、AZ 間でワークロードを自動的に再分散します。これにより、5.5GB のタスクに対して、2 番目の AZ に適切なサイズの r7a.medium インスタンス (1 vCPU、8GB) がプロビジョニングされ、一方で元の r5a.large インスタンスは 1 つのタスクを実行するには過剰なリソースとなります。ECS マネージドインスタンスキャパシティプロバイダーはこの非効率性を検出し、過小利用のインスタンスをドレインすることで、AZ 間の高可用性と費用対効果のバランスを取った継続的な最適化を実現します。
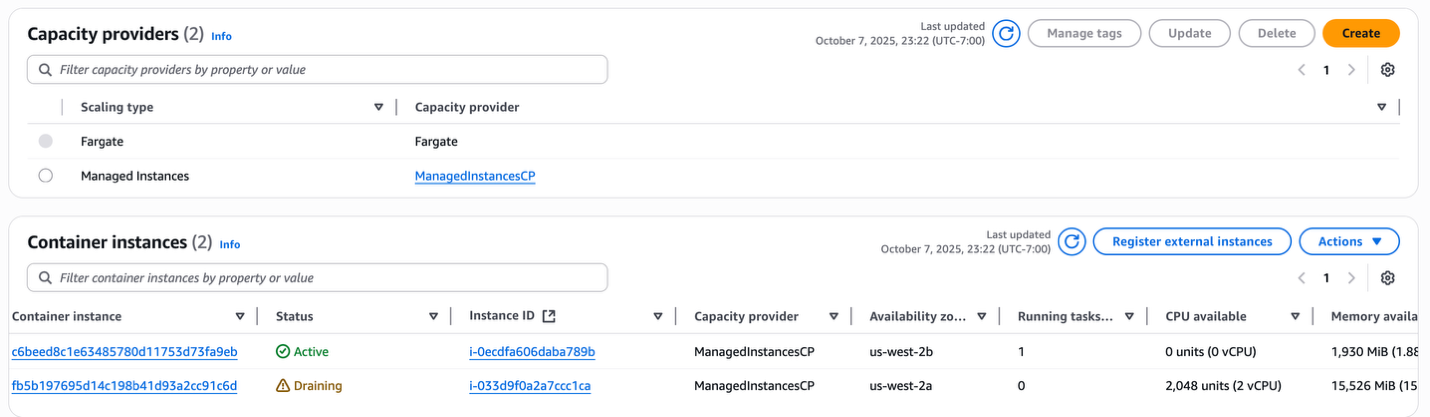 図 10: マネージドインスタンスキャパシティープロバイダーの AZ 再分散と継続的な最適化
図 10: マネージドインスタンスキャパシティープロバイダーの AZ 再分散と継続的な最適化
- 最終的に、マネージドインスタンスキャパシティプロバイダーは、2 つの AZ にまたがって、それぞれ 1 つのタスク (1 vCPU、5.5 GB) を実行する 2 つの r7a.medium インスタンス (1 vCPU、8 GB) を実行する最適な状態になります。
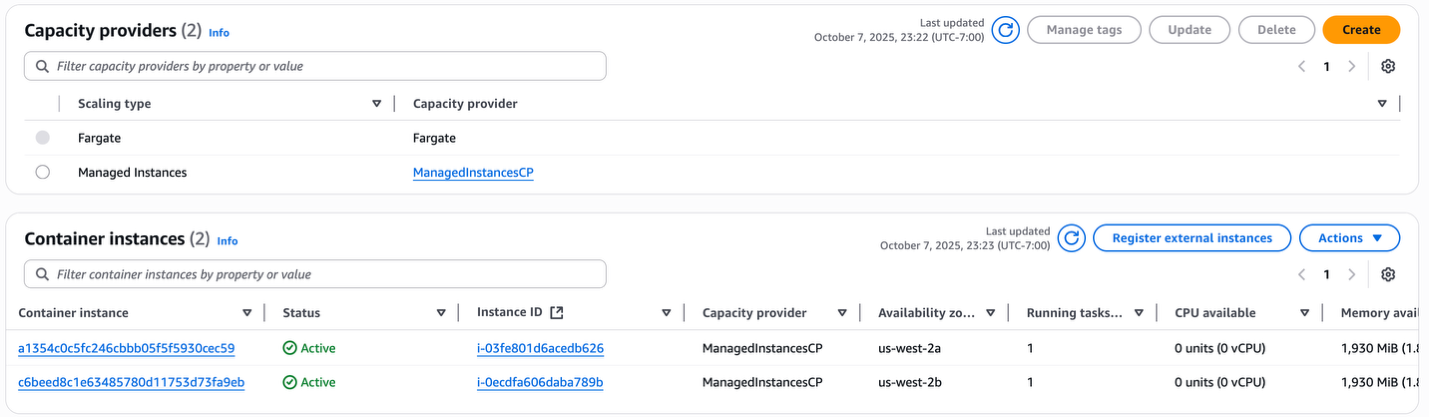 図 11: インフラストラクチャの最適化後、最適な容量で実行されているマネージドインスタンスキャパシティプロバイダー
図 11: インフラストラクチャの最適化後、最適な容量で実行されているマネージドインスタンスキャパシティプロバイダー
長時間実行のワークロード
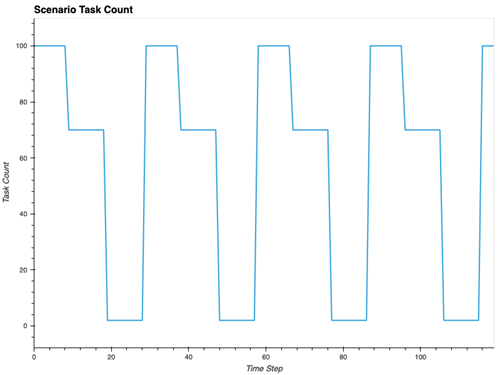
図 12: ECS タスクの予測可能なスケーリングを伴う長時間実行テスト
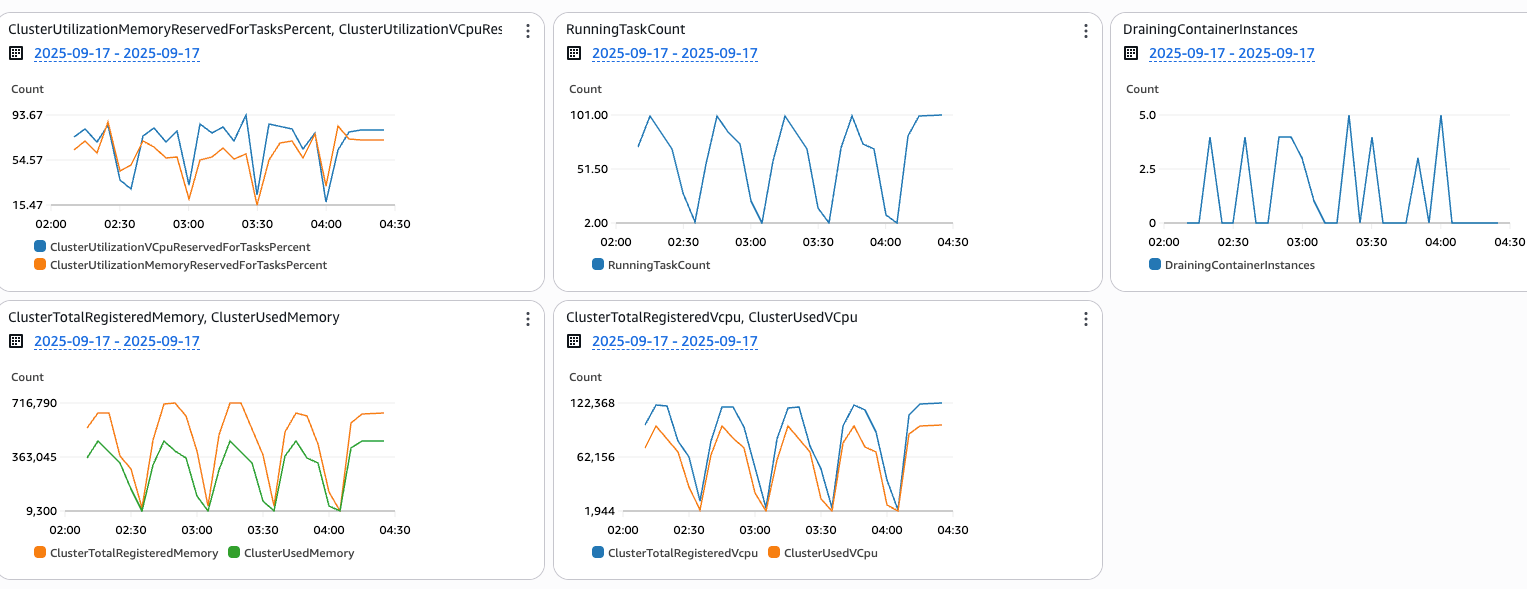 図 13: 周期的なスケーリングパターンのキャパシティプロバイダーメトリクス
図 13: 周期的なスケーリングパターンのキャパシティプロバイダーメトリクス
ECS マネージドインスタンスキャパシティプロバイダーは、リソースを実際の需要に合わせてマッチングします。別のテストシナリオ (図 12) では、2 つの ECS サービスがワークロードの変更を 30 分ごとに繰り返し、合計 100 タスクから 70 タスクに、さらに 2 タスクにスケーリングしています。これは 2 時間にわたって行われ、1 分間隔でデータを取得することで、キャパシティプロバイダーがこれらのワークロード変更にどのように対応しているかを詳細に確認できます。
ここでの重要なインサイトは、ECS マネージドインスタンス が、リソース割り当てと実際の需要の間の強力な整合性を維持し、vCPU とメモリ使用率のメトリクスが正確に ECS タスクのサイクルパターンを反映していることです。DrainingContainerInstancesメトリクスは、バックグラウンドで継続的に最適化が行われていることを示しています。手動による介入を待つのではなく、ECS マネージドインスタンスはクラスター全体のリソース効率を継続的に監視し、タスクがスケールダウンすると、すぐに未活用のインスタンスをドレインし、残りのワークロードを適切に移動させて ECS クラスターの密度を最適化します。この自動化されたプロセスにより、リソースが必要以上に長くアイドル状態になることはありません。
クリーンアップ
このウォークスルーを完了した後は、継続的な課金を防ぎ、きれいな AWS 環境を維持するために、デプロイしたすべてのリソースをクリーンアップする必要があります。このステップにより、予期しない課金を防ぎ、使用されていないリソースを削除することで AWS 環境を整頓できます。
- CloudFormation スタックを削除します
- CloudFormation テンプレートと S3 バケットを削除します
まとめ
この記事では、Amazon ECS マネージドインスタンスのインフラストラクチャプロビジョニングとワークフローの最適化について説明しました。初期リリースでは、可用性とコスト効率のバランスを取るために AWS の運用ベストプラクティスが実装されていますが、さまざまなワークロードではコスト、パフォーマンス、可用性の側面でそれぞれ異なるトレードオフが必要になることを理解しています。今後は、プロビジョニングと最適化ワークフローを強化し、最適化ワークフローの設定可能な期間、 capacity headroom やターゲット利用率レベル、カスタム配置戦略、Disruption Budgets など、お客様のコントロールを導入する予定です。
今後のアップデートについては、GitHub の ECS ロードマップを参照してください。Amazon ECS の未来を形作るのに役立つフィードバックをお待ちしています。はじめに、ドキュメントを参照してください。
翻訳はソリューションアーキテクトの加治が担当しました。原文はこちらです。