Amazon Web Services ブログ
画像分析を活用した医薬品製造業での「インダストリー4.0」推進
このブログは2021年9月9日にAsha D’Souza,Karim Afifi, Misha St. Lorantによって投稿された“Driving Life Sciences Manufacturing “Industry 4.0” using Image Analytics”をソリューションアーキテクトの吉川が翻訳したものです。
はじめに
このブログでは、医薬品製造業でのITによる画像認識の使用について、クラウドへの移行を加速し、「Industry 4.0」ビジョンに向けた基礎となるステップとして予測的なプラント機能を実現するための概要をまとめています。 AWS のコンピュータビジョンサービスは、画像分析を使用して、個々の処理ステップを自動化します。 また、このブログでは、画像分析で製造プロセスを最適化するための、主要なビジネス課題と機会、ターゲットユースケース、AWS アーキテクチャパターンを紹介します。 さらに、これらのワークフローを自動化することで、プロセスのコストが削減され、品質保証に関連しているかに関わらず、重要なプロセス領域に、希少な人員を割り当てることができます。 最後に、皆さんが画像分析の実現を加速させるため、デジタル戦略の重要性を説明し、サンプル異常検出アプリケーションを提供します。
デジタル接続されたスマートマニュファクチャリング
製薬会社と医薬テック企業は、新しい治療手法の開発から、スマートマシンの提供、高度な分析の提供、デジタル処理とのプロセス統合に至るまで、イノベーションの波を経験しています。 分業化された製造と迅速な対応能力を実現するには、より大きな仕組みに拡大するために、自動化していくことが必要です。
人工知能は、あらゆる領域において大きな変革をもたらす強力な手段へと変貌しています。 現在、この変化は生産と製造の分野に進んでおり、ディープラーニングの力を活用して、より速く、コスト効率が高く、より優れた自動化を実現しています。
外観検査はいつどこで必要とされるのか?
DruryとFoxが行った調査によると、 外観検査の誤りは通常20%から30%の範囲です。 原因のいくつかはヒューマンエラーによるものですが、他の不完全さは検査スペース上の制約によるものです。
作業者へのトレーニングや実習を通して特定の誤りを削減することは効果的ですが、すべての誤りを排除できる保証はありません。 製造における外観検査の誤りは、存在する欠陥を見逃す(検出漏れ)か、存在しない欠陥を誤って検出する(誤検出)という2つの形態のいずれかを取ります。 検出漏れは、誤検出よりもずっと頻繁に発生する傾向があります。 検出漏れは品質の低下につながり、誤検出は不必要な生産コストや全体的な無駄を引き起こす可能性があります。 手動による外観検査は、(複数の)訓練を受けた人員を雇うため、依然として高価な投資です。
コンピュータービジョン
自動外観検査は、人間が関与せずに外観検査の全手順を行うことで、これらの問題を克服することができます。 自動化されたシステムを使用すると、手動の外観検査を上回る結果を得られる場合が多いです。
製造画像分析により、プロセス・品質担当の技術者は最先端のコンピュータビジョンを活用して、下流工程での包装や充填ワークフローに特有の画像検査と判別を行い、プラントの効率、歩留まり、プロセスの改善を最新化できます。 バッチ歩留まりを改善するために、製薬メーカーは、測定、スタッフ、オペレーション、機器の校正など、すべての品質プロセス入力におけるばらつきの原因を理解する必要があります。 目標は、常に安全に品質基準を満たしながら生産量を最大化し、生産とパッケージングにおける品質プロセスを最適化することです。
目標は、品質仕様の範囲内での歩留まりが最も高いバッチを間違いなく生産し、バッチ生産と包装のプロセスを最適化することです。
ビジネス上の課題
ビジネス上存在する課題として、QA/QCプロセスに要する人件費削減があります。たとえば、QA/QCプロセス上の他の領域に、希少でコストのかかる人的リソースを再配置できることなどです。 これにより、貴重なリソースを他の価値の高いタスクや活動へ割り当てることができます。 もう 1 つのビジネス上の課題として、機器が校正範囲外になったことを継続的に検出できることが挙げられます。この課題に対し、 校正をプログラムで自動化することで、全体の生産歩留まり値を改善できます。 さらに解決可能なビジネス上のチャレンジとして、サンプル検査の合格/不合格率の予測精度を向上することがあげられます。このステップを実現するには自動化によって製造現場の生産効率を向上させる必要があります。
技術的な課題
「Manufacturing Image Analytics (製造業における画像解析)」で対処可能な技術的課題には、リアルタイムの画像データを取得する機能がないこと、および継続的なプロセスとして画像データを活用できていないことなどがあります。 これらの技術的制約により、組織はスループット、歩留まり、投入時間、品質プロセスなどの運用指標を改善できていません。 画像ベースの検査を取り入れ部分的に最適化できたワークフローならば、今後、画像解析技術や機械学習技術によってさらに進歩することができます。
製造業務は、規制や競争に左右される厳しいビジネス環境を生き抜かねばなりません。 生産プロセスの現代化とリアルタイムのデータ処理、画像分析といった施策を行わなければ、生産性が制限され、運用上の負担とコストが増加します。 既存のデータインフラストラクチャの価値の向上、運用効率によるコストの削減、バッチ生産の一貫性の向上、基準を超えるばらつきによる影響の把握といった課題が差し迫っています。 理想的な品質管理システムは、適切なデータ、適切なソース、適切な時間と場所、適切な人材、適切な意思決定の 5 つの要素で構成されています。 [ McKinseyの記事より ]
自動化を考慮すべき領域
バイオ医薬品業界は、一般に「インダストリー4.0」と呼ばれる第4次革命によって、コンピュータビジョンの使用が普及しています。 上流工程と下流工程の両方の業務で画像検出を使用すると、歩留まりに関する品質プロセスを改善できます。 画像分析の用途は幅広く、バリューチェーン全体の多くの分野に適用可能です。 IT活用方法としての自動検査は、適用範囲が広いため、豊富なユースケースに対応できます。 いくつかの主要な例は次のとおりです。
- 包装材の検査:コアからバイオ医療の下流製造プロセスは、規制に基づいて製造されたワクチン、インスリン、錠剤などの製品に使用される包装材に固有の適切な品質要件を担保する機能です。 例えば、最終充填工程に進む前に、気泡、亀裂、小さなひびなどの不完全性の検証が必要なガラスバイアルなど包装材の検査です。 画像分析では、このような欠陥を高精度で自動化および検出できるため、品質とコンプライアンスの要件を確実に満たすことができます。
- 製品最終充填: バッチ生産は生産プロセスの重要な要素です。 画像分析が効果を生むもう1つの例は、下流工程の製品充填プロセスです。画像分析ワークフローを活用して合否レートを目標とする品質改善を合理化することで、これまで手動で処理されていたステップを自動化し、精度の高い充填レベルが実現します。
- 包装の検証: 規制要件により、ラベルの配置は厳格なガイドラインを満たさなければならないことが規定されています。 画像のキャプチャと解析を使用し、最終充填後のラベルの貼付け作業を自動化して、ラベルの向きと位置が目的の許容範囲内に収まるようにします。 さらに、ラベル配置のパッケージ検証ステップを自動化することで、QA における人的リソースを解放して、他の製造関連タスクに集中できます。
- 防護服着用: 画像分析を使用して、作業現場の従業員が防護服着用手順へ適切に従っていることを確認し、汚染を回避し、防止することができます。 正しい着用と適合する手順パターンを、正しくない手順や一貫性のない手順に照らし合わせるすることで、汚染がラボに侵入するのを防ぎ、製造現場のアクティビティに適切な動作手順が組み込まれるようになります。
- 移動経路: COVID-19パンデミックは、製造の仕組みに大きな変化をもたらしました。 ソーシャルディスタンスの確保と隔離の義務は、現場の作業者の移動経路のルール化を促進しました。 これらの課題に対処し、作業者の移動経路を最適化するために、画像検出と作業者の移動のリアルタイム分析を使用した作業者の監視と経路履歴により、経路を記録したり、ワークフローの有効性を判断できます。 その他のメリットとして、作業時間の短縮や作業者の安全性の向上などが挙げられます。
ソリューションの概要
まず、使用する予定の AWS アカウントに必要なリソースを構築するところからはじめます。 以下の構成図は、このアーキテクチャで活用する AWS サービスを示しています。 下図はリファレンスアーキテクチャであり、最終的な構成はお客様の要件に応じて異なる場合があります。 アカウントチームをはじめとするAWSのメンバーと協力して、要件を最も満たす最終的なアーキテクチャを設計してください。
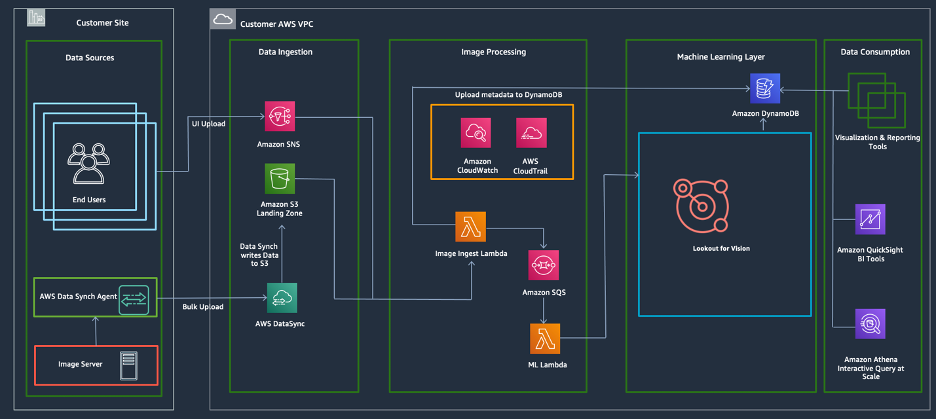
ウォークスルー
以下は、このソリューションの推奨ワークフローです。
- ソリューションをホストする Amazon VPC にお客様の拠点を接続します。
- イメージを S3 にアップロードする適切なサービス/ソリューションを特定します。
- 取り込んだイメージを処理し、メタデータをキャプチャするワークフローを定義します。
- 異常検出モデルを利用して、正常画像と異常画像を判別します。
- 学習/テストデータセットを作成します。
- ML モデルを作成して学習します。
- モデルをホストします。
お客様が希望する AWS リージョンでお客様の拠点と Amazon 仮想プライベートクラウド(Amazon VPC)間の接続を確立することが、まず第一歩です。 接続が確立されると、以下に示すように、さまざまなデータソースからデータを取り込むための方法を利用できます。 このブログでは、 AWS DataSync を活用して、お客様の拠点から AWS アカウントに画像を一括アップロードし、データを S3 バケットに保存します。 AWS DataSync は、オンプレミスのストレージシステムと AWS ストレージ サービス間のデータ移動を簡素化、自動化、高速化するオンラインデータ転送サービスです。 データは、AWS DataSyncを使用して、ネットワークファイルシステム(NFS) 共有またはサーバーメッセージブロック (SMB) から AWS クラウドに転送されます。
Amazon Simple Notification Service(Amazon SNS)とAWS Lambda 関数を利用して、正常画像と異常画像の両方を格納するさまざまな S3 バケットのデータセットを操作します。 Amazon Lookout for Visionでの作業中に、画像の入力場所を追跡する必要があります。
Amazon Lookout for Vision を使用して、正常な画像と異常な画像を検出する異常検出モデルを作成します。 Amazon Lookout for Visionは、コンピュータビジョン(CV)を使用して外観上の欠陥や異常を発見する機械学習(ML)サービスです。 Amazon Lookout for Vision を使用すると、製造業の会社は、物体画像の迅速な差異検出を大規模なスケールで実施し、品質を向上させ、運用コストを削減できます。
概念実証(PoC)を行うために、鋳造製品の画像の異常を検出するアプリケーションを構築します。 次のリンク からデータセットを表示しダウンロード します。 データセットはすでに(正常 対 不良)でラベル付けされており、予めテスト用と学習用に分割されています。 データをダウンロードし、ローカルディレクトリに解凍します。 次に、次の構造の S3 バケットにイメージをアップロードします。
S3バケット
Train
Normal
Anomaly
Test
Normal
Anomaly
以下を確認してください
- 学習用の正常画像は s3://s3_bucket/Train/Normal/ に配置します。
- 学習用の異常画像は s3://s3_bucket/Train/Anomaly/ に配置します。
- テスト用正常画像は s3://s3_bucket/Test/Normal/ に配置します。
- テスト用異常画像は s3://s3_bucket/Test/Anomaly/ に配置します。
Amazon Lookout for Vision には、画像の S3 の場所とJSON 行形式の画像ラベルを記したマニフェストファイルが必要です。 以下のPythonコードは、学習画像とテスト画像のマニフェストファイルを作成します。
from datetime import datetime
import json
now = datetime.now()
dttm = now.strftime("%Y-%m-%dT%H:%M:%S.%f")
datasets = ["train", "test"]
directory=”data” # replace with the name of the local folder where the data is.
bucket = “bucket_name” # replace with the name of the s3 bucket
for ds in datasets:
print(ds)
folders = os.listdir("./{}/casting_data/{}".format(directory,ds))
with open("{}.manifest".format(ds), "w") as f:
for folder in folders:
filecount=0
print(folder)
files = os.listdir("./{}/casting_data/{}/{}".format(directory,ds, folder))
label = 1
if folder == "anomaly":
label = 0
for file in files:
filecount+=1
manifest = {
"source-ref": "s3://{}/lookoutforvision/data/{}/{}/{}".format(directory, bucket, ds, folder, file),
"auto-label": label,
"auto-label-metadata": {
"confidence": 1,
"job-name": "labeling-job/auto-label",
"class-name": folder,
"human-annotated": "yes",
"creation-date": dttm,
"type": "groundtruth/image-classification"
}
}
f.write(json.dumps(manifest)+"\n")マニフェストファイルを同じ S3 バケットにアップロードします。 Amazon Lookout for Vision での作業中に、入力として含めるマニフェストファイルの場所をメモしておきます。
これでS3 に画像とマニフェストファイルを置けましたので、Amazon Lookout for Vision でプロジェクトを作成できます。 次のステップは、AWS マネジメントコンソール、AWS CLI、または API を使用して学習を実行します。 私はPython Boto3 APIを使用してこれを行うためのコードスニペットを貼り付けています。
プロジェクトを作成する
import boto3
project = “project_name” # replace with name of your project
client = boto3.client('lookoutvision')print(boto3.session.Session().region_name)print('Creating project:' + project)
response=client.create_project(ProjectName=project)print('project ARN: ' + response['ProjectMetadata']['ProjectArn'])print('Done!')学習/テストデータセットの作成
import boto3
dataset_type ='train or test' #replace with train or test
manifest_file = ‘prefix and file name for the manifest' #replace with the path to manifest file for train or test on S3
bucket = ‘bucket_name’ #replace with S3 bucket name
project = “project_name” # replace with name of your project
client = boto3.client('lookoutvision')
print('Creating dataset...')
dataset=json.loads('{ "GroundTruthManifest": { "S3Object": { "Bucket": "' + bucket + '", "Key": "'+ manifest_file + '" } } }')
response=client.create_dataset(ProjectName=project, DatasetType=dataset_type, DatasetSource=dataset)
print('Dataset Status: ' + response['DatasetMetadata']['Status'])
print('Dataset Status Message: ' + response['DatasetMetadata']['StatusMessage'])
print('Dataset Type: ' + response['DatasetMetadata']['DatasetType'])
print('Done!')モデルの作成と学習
import boto3
dataset_type ='train or test' #replace with train or test
manifest_file = ‘prefix and file name for the manifest' #replace with the path to manifest file for train or test on S3
bucket = ‘bucket_name’ #replace with S3 bucket name
project = “project_name” # replace with name of your project
client = boto3.client('lookoutvision')
print('Creating dataset...')
dataset=json.loads('{ "GroundTruthManifest": { "S3Object": { "Bucket": "' + bucket + '", "Key": "'+ manifest_file + '" } } }')
response=client.create_dataset(ProjectName=project, DatasetType=dataset_type, DatasetSource=dataset)
print('Dataset Status: ' + response['DatasetMetadata']['Status'])
print('Dataset Status Message: ' + response['DatasetMetadata']['StatusMessage'])
print('Dataset Type: ' + response['DatasetMetadata']['DatasetType'])
print('Done!')モデルのホスティング
モデルの学習が完了したら、先に進んで推論用にモデルをホストすることができます。
import boto3
client = boto3.client('lookoutvision')
project = “project_name” # replace with name of your project
model_version='1'
min_inference_units=1
print('Starting model version ' + model_version + ' for project ' + project )
response=client.start_model(ProjectName=project,
ModelVersion=model_version,
MinInferenceUnits=min_inference_units)
print('Status: ' + response['Status']) ここまで実施した後、モデルがホストされるのを待ちます。 完了したら、モデルにより推論を行うフロントエンドアプリケーションを作成できます。 アプリケーションの作成方法の詳細は、次のリポジトリに記載されています。
https://github.com/aws-samples/amazon-lookout-for-vision-demo
最後のステップは、データ活用のためのBIツールを検討することです。 データの取り込みと処理の各段階で、画像のメタデータを収集して保存すると、お客様は好みの視覚化ツールやレポート作成ツールを導入して、インサイトを得たりダッシュボードを生成できるようになります。
接続性
AWS は、お客様の製造施設やデータセンターを AWS アカウントに接続するためのさまざまな方法を提供しています。 お客様は、 AWS Direct Connect を活用して、お客様のネットワークと 一つのAWS Direct Connect ロケーションの間に専用のネットワーク接続を確立できます。 お客様が AWS Direct Connect で検討できる接続方法は、2 種類あります。 お客様は、専用接続(単一の顧客に関連付けられた物理イーサネット接続)または ホスト接続 (AWS Direct Connect パートナーがお客様に提供する共有型接続)を選べます。 パートナーの詳細については、 AWS Direct Connect デリバリーパートナー をご覧ください。
AWS サイト間 仮想プライベートネットワーク (VPN)は、オンプレミスネットワークと AWS グローバルネットワーク間の安全な接続を確立するもう 1 つの方法です。 AWS サイト間 VPN は、ネットワークと Amazon VPCの間に暗号化されたトンネルを作成します。
では、どの方法を検討すればよいでしょうか? VPN Connections のセットアップには数分で完了するため、すぐに利用開始する必要があり、インターネットベースのばらつく可能性のある接続品質を許容できる場合に適しています。 一方、AWS Direct Connect はインターネットを必要とせず、イントラネットと Amazon VPC 間の専用線を使用します。
AWS Transit Gateway を使用すると、VPC、AWS アカウント、オンプレミスネットワークを簡単に接続することができ、ハブのような役割を果たします。 このアプローチは、ネットワークを簡素化し、過去に多くのケースで必要だった複雑なピアリング関係を解消します。 AWS Transit Gateway はクラウド上に設置されたルーターとして機能し、新しい接続ごとに AWS Transit Gateway に接続します。 詳細については、 AWS Transit Gateway をご覧ください。
このブログ記事の目的のために、今回のソリューションはお客様の拠点とお客様の Amazon VPC 間に敷設された既存のAWS Direct Connectを活用します。 接続オプションと AWS クラウドへ転送するデータ量をよく理解することは重要です。 AWSのメンバーと協力して、要件に最適なアーキテクチャを完成させましょう。
AWSではじめましょう
医薬品業界 のAWS ユーザーは、画像分析の利点を活用して「Industry 4.0」のビジョンを達成すべくイノベーションを進めています。 さらに、製造技術革新の水準が高まるにつれ、高度な画像処理の利用は、革新的な取り組みから、あって当たり前の機能へと位置づけが移行します。 ライフサイエンス分野のお客様にとってこの画像分析の近代化をどこから始めるべきかを把握するのは難しい場合もありますが、AWS では、お客様の工場や施設に応じて、製造ニーズに特化したワークショップを提供し、人材、プラットフォーム、運用、コンプライアンス、ガバナンス、セキュリティ、ビジネスの成果など、いくつかの重要な側面を客観的に評価します。 AWS は、画像分析の分野で完全なソリューションパッケージを提供し、モダナイゼーションを促進します。
始めるのは簡単です。 お客様がすでにAWS のサービスとツールに精通している場合は、学習用のデータセットや、お客様自身の製造現場のデータを用いて、このブログのプロジェクトをすぐに活用できます。 そこからモデルを構築して学習させ、提供されたサンプルコードを使用して AWS アカウントでモデルをホストしアプリケーションから利用できるようにします。 また、AWS プロフェッショナルサービスでは、製造業における成熟度アセスメントを適用することで、画像分析の活用を加速できます。AWSはお客様の製造現場が、効果的な画像分析パイプラインの開発・展開の準備をできているかを評価し、重要なビジネスニーズに基づいてプロジェクトのゴールを逆算して考え、目標を定め、それを達成するための取り組みを支援します。
皆様のAWS 営業担当にお問い合わせいただき、製造と品質領域におけるデジタルトランスフォーメーションを開始、加速するために AWS を使い始めましょう。
著者について

アーシャ・ドゥ・ソウザ
Asha D’Souza PhD は AWS のプリンシパルヘルスケアおよびライフサイエンス業界アドバイザーであり、米国西部でビジネス開発、戦略、アドバイザリーを指揮しています。 Asha は、著名なライフサイエンス企業において、バリューチェーン全体にわたるデジタル変革において 20 年以上の経験を有しています。 テクノロジーを活用することで、患者のケアの質を向上させ、創薬、開発、タイム・トゥ・バリューを加速させることに情熱を注いでいます。

カリム・アフィフィ
Karim Afifi は、AWSのソリューションアーキテクトリーダーです。 グローバル ライフサイエンス ソリューション アーキテクチャ チームの一員です。 彼はニューヨークを拠点に活動しており、お客様のイノベーションを支援しています。

ミーシャ・セントロラント
Misha StloRantは、バイオ医薬品、免疫療法、臨床試験の分野に特化して、ライフサイエンスおよびヘルスケア業界で15年以上の実績があります。 AWS に入社する前は、GE で、バイオ医薬品および細胞治療の開発、医薬品の臨床試験、画像診療のクリニカルパス最適化にフォーカスしたエンジニアリングのソリューションディレクターを務めていました。 また、Misha は 11 年以上にわたり、Microsoft のプログラム、製品、およびエンジニアリングチームで、ヘルスケア IT、プラットフォーム、患者向けアプリケーションに注力してきました。 オレゴン州立大学で経済と金融の学士号、UOPでテクノロジーマネジメントのMBA、ノースウェスタン大学ケロッグ経営大学院で統計分析の認定を取得しました。

ウジワル・ラタン
Ujjwal Ratan は、AWSのグローバルヘルスケアおよびライフサイエンスチームのプリンシパル機械学習スペシャリストです。 医療画像処理、非構造化臨床テキスト、ゲノミクス、精密医療、臨床試験、ケア品質の向上など、産業界での実世界の課題に対して機械学習とディープラーニングの応用に取り組んでいます。 AWS クラウドで機械学習/ディープラーニングアルゴリズムをスケーリングし、学習と推論を促進する専門知識を持っています。 自由な時間には、音楽を聴いたり(演奏して)、家族と一緒に気ままなドライブを楽しんでいます。