Amazon Web Services ブログ
Amplitude が Amazon OpenSearch Service をベクトルデータベースとして活用し、自然言語による分析を実現した方法
本記事は 2026 年 3 月 4 日 に公開された「How Amplitude implemented natural language-powered analytics using Amazon OpenSearch Service as a vector database」を翻訳したものです。
本記事は、Amplitude の共同創業者兼チーフアーキテクトである Jeffrey Wang 氏が AWS と共同で執筆したゲスト投稿です。
Amplitude は、プロダクトおよびカスタマージャーニー分析プラットフォームです。お客様はプロダクトの利用状況について深い質問をしたいと考えていました。Ask Amplitude は大規模言語モデル (LLM) を活用した AI アシスタントです。スキーマ検索とコンテンツ検索を組み合わせ、カスタマイズされた正確かつ低レイテンシーの自然言語ベースの可視化体験をエンドカスタマーに提供します。Ask Amplitude はユーザーのプロダクト、分類体系、言語を理解した上で分析のフレームを構築します。一連の LLM プロンプトを使ってユーザーの質問を JSON 定義に変換し、カスタムクエリエンジンに渡します。クエリエンジンが回答をチャートとしてレンダリングする仕組みを次の図に示します。
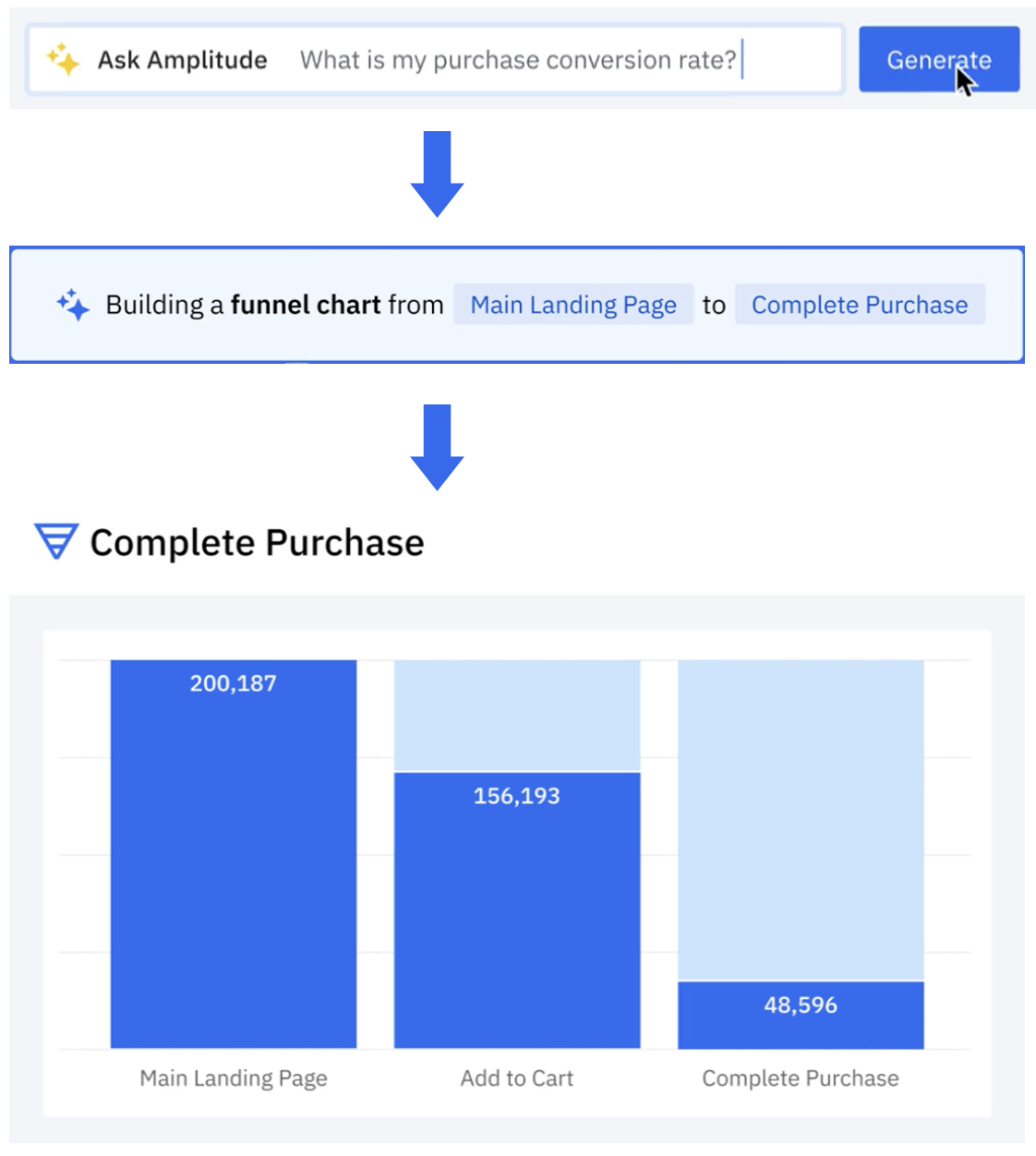
Amplitude の検索アーキテクチャは、Amazon OpenSearch Service を活用したセマンティック検索と Retrieval Augmented Generation (RAG) を実装し、スケーラビリティの向上、アーキテクチャの簡素化、コスト最適化を実現しました。本記事では、Amplitude のアーキテクチャの反復的な進化と、スケーラブルなセマンティック検索・分析プラットフォームの構築における重要な課題への対処方法を紹介します。
主な目標は、セマンティック検索と自然言語によるチャート生成を大規模に実現しつつ、きめ細かなアクセス制御を備えたコスト効率の高いマルチテナントシステムを構築することでした。エンドツーエンドの検索レイテンシーの最適化と迅速な結果の提供も重要でした。また、エンドカスタマーが既存のチャートやコンテンツを安全に検索・活用し、より高度な分析を行えるようにすることも目指しました。さらに、大規模なリアルタイムデータ同期の課題にも対処し、常に流入するデータ更新を処理しつつ、システム全体で低い検索レイテンシーを維持するソリューションを開発しました。
Ask Amplitude における RAG とベクトル検索
Ask Amplitude が RAG を使用する理由を簡単に見てみましょう。Amplitude はオムニチャネルの顧客データを収集します。エンドカスタマーは自社プラットフォーム上でユーザーが行ったアクションのデータを送信します。これらのアクションはユーザー生成イベントとして記録されます。例えば、小売・EC のお客様の場合、ユーザーイベントには「商品検索」「カートに追加」「購入手続き」「配送オプション」「購入」などがあります。これらのイベントがお客様のデータベーススキーマ (テーブル、カラム、リレーションシップ) を定義します。「2 日配送を利用した人は何人ですか?」というユーザーの質問を考えてみましょう。LLM は、キャプチャされたユーザーイベントのどの要素がクエリへの正確な回答に関連するかを判断する必要があります。ユーザーが Ask Amplitude に質問すると、最初のステップとして OpenSearch Service から関連イベントをフィルタリングします。コストと精度の両面から、すべてのイベントデータを LLM に送るのではなく、選択的なアプローチを取ります。LLM の利用料金はトークン数に基づくため、完全なイベントデータを送信するのは不必要にコストがかかります。さらに重要なのは、コンテキストが多すぎると LLM のパフォーマンスが低下することです。数千のスキーマ要素を与えると、モデルは関連情報を確実に特定して集中することが難しくなります。情報過多は LLM を本来の質問から逸らし、ハルシネーションや不正確な回答につながる可能性があります。RAG が好まれるのはこのためです。プロダクト利用スキーマから最も関連性の高い項目を取得するために、ベクトル検索を実行します。お客様のスキーマに含まれる正確な単語を質問が参照していない場合でも効果的です。以降のセクションでは、Amplitude の検索の進化を順を追って説明します。
初期ソリューション: セマンティック検索なし
プライマリデータベースとして Amazon Relational Database Service (Amazon RDS) for PostgreSQL を使用し、ユーザー、イベント、プロパティデータを保存していました。ただし、次の図のように、キーワード検索の実装にはサードパーティの別のストアを使用していました。PostgreSQL からこのサードパーティの検索インデックスにデータを取り込み、最新の状態に保つ必要がありました。
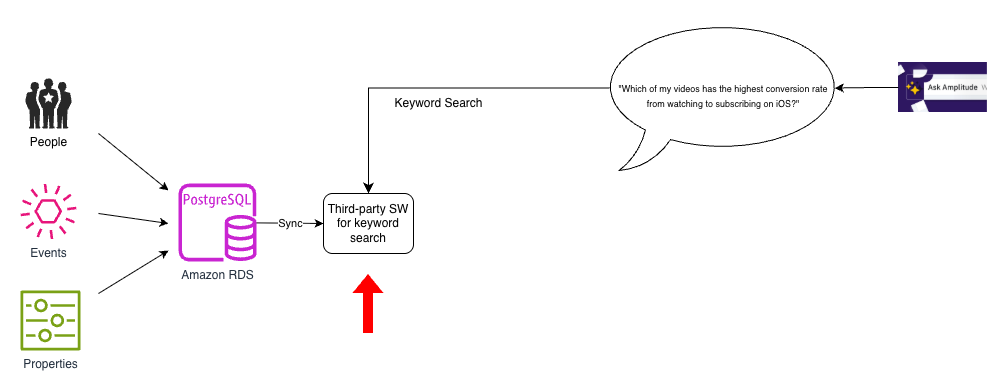
このアーキテクチャはシンプルでしたが、2 つの大きな課題がありました。検索インデックスに自然言語機能がないこと、そしてキーワード検索しかサポートしていないことです。
イテレーション 1: 総当たりコサイン類似度
検索機能を改善するため、いくつかのプロトタイプを検討しました。ほとんどのお客様のデータ量はそれほど大きくなかったため、PostgreSQL を使ったベクトル検索のプロトタイプを素早く構築できました。ユーザーインタラクションデータをベクトル埋め込みに変換し、配列コサイン類似度を使ってデータセット全体の類似度メトリクスを計算しました。カスタムの類似度計算は不要になりました。ベクトル埋め込みは、追加のインフラの負荷なしに PostgreSQL の機能を使って、ユーザー行動の微妙なパターンをキャプチャしました。これは一般に総当たり法と呼ばれ、受信クエリをすべての埋め込みと照合し、距離尺度 (この場合はコサイン類似度) によって上位 K 件の近傍を見つけます。アーキテクチャを次の図に示します。
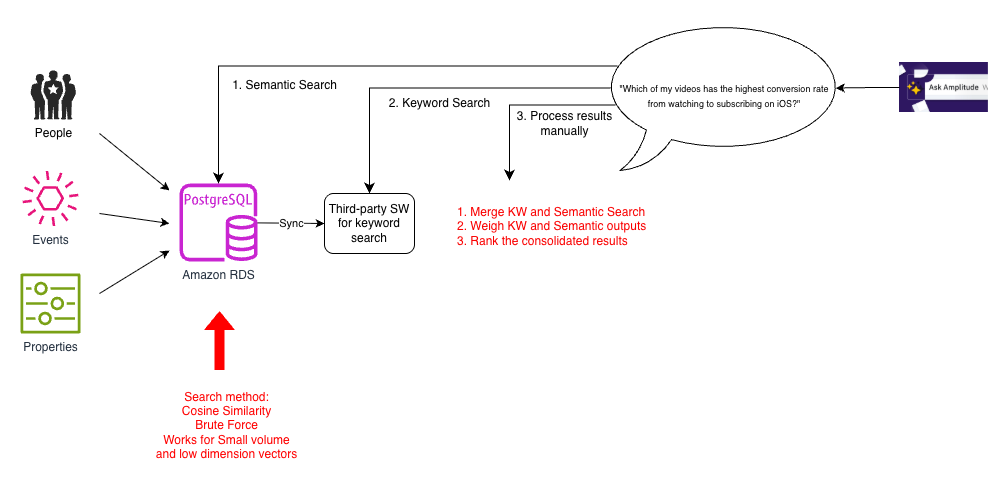
セマンティック検索の導入は、同じ概念を異なる用語で表現するユーザー (「動画視聴時間」と「総再生時間」など) にとって、従来の検索から大きな改善でした。しかし、小規模なデータセットでは機能したものの、総当たり法はすべてのベクトルペアのコサイン類似度を計算する必要があるため低速でした。イベントスキーマの要素数、質問の複雑さ、品質への期待が高まるにつれ、この問題は増幅されました。さらに、Ask Amplitude の回答にはセマンティック検索とキーワード検索の両方を組み合わせる必要がありました。両方の検索を組み合わせるため、各検索クエリは複数のデータベースへの呼び出しを伴う 3 ステップのプロセスとして実装する必要がありました。
- PostgreSQL からセマンティック検索結果を取得する。
- 検索インデックスからキーワード検索結果を取得する。
- アプリケーション内で、セマンティック検索結果とキーワード検索結果を事前に割り当てた重みで結合し、Ask Amplitude の UI に出力する。
複数ステップの手動アプローチにより、検索プロセスは複雑になりました。
イテレーション 2: pgvector による ANN 検索
Amplitude の顧客基盤が拡大するにつれ、Ask Amplitude はより多くのお客様と大規模なスキーマに対応する必要がありました。目標は単に質問に答えるだけでなく、ユーザーを反復的にガイドしてエンドツーエンドの分析を構築する方法を教えることでした。そのため、埋め込みにはコンテキストが豊富なセマンティックコンテンツを保存しインデックス化する必要がありました。チームはより大きく高次元の埋め込みを試し、ベクトルの次元数が検索の有効性に影響するという経験的な観察を得ました。多言語埋め込みのサポートも要件でした。
よりスケーラブルな k-NN 検索をサポートするため、チームは高次元空間でのベクトル操作に強力な機能を提供する PostgreSQL 拡張機能の pgvector に切り替えました。アーキテクチャを次の図に示します。
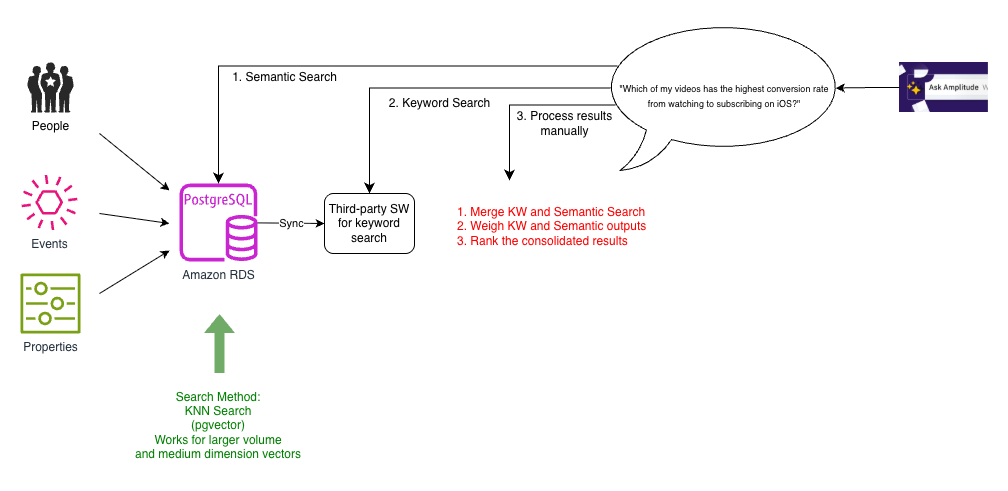
pgvector は高次元ベクトルの k 最近傍 (k-NN) 類似度検索をサポートできました。ベクトル数が増加するにつれ、HNSW や IVFFlat などの近似最近傍 (ANN) 検索を可能にするインデックスに切り替えました。
大規模なスキーマを持つお客様では、総当たりコサイン類似度の計算は低速でコストがかかりました。pgvector による ANN に移行したことでパフォーマンスの改善が見られました。しかし、PostgreSQL でのセマンティック検索、別の検索インデックスでのキーワード検索、そしてそれらを統合するという 3 ステップのプロセスの複雑さには依然として対処が必要でした。
イテレーション 3: OpenSearch Service によるキーワード検索とセマンティック検索のデュアル同期
お客様の数が増えるにつれ、スキーマの数も増加しました。データベースには数億のスキーマエントリがあったため、パフォーマンスが高くスケーラブルでコスト効率の良い k-NN 検索ソリューションを求めていました。OpenSearch Service と Pinecone を検討した結果、キーワード検索とベクトル検索の機能を統合できる OpenSearch Service を選択しました。選択の理由は 4 つあります。
- シンプルなアーキテクチャ – OpenSearch Service のように、セマンティック検索を既存の検索ソリューションの機能として位置づけることで、専用サービスとして扱うよりもシンプルなアーキテクチャになります。
- 低レイテンシーの検索 – 検索データを効果的に整理・分類する機能は、回答生成の基盤でした。セマンティック検索を既存のパイプラインに追加し、両方を 1 つのクエリに統合することで、低レイテンシーのクエリを実現しました。
- データ同期の削減 – データベースと検索インデックスの同期維持は、回答の精度と品質に不可欠でした。検討した他の選択肢では、キーワード検索インデックス用とセマンティック検索インデックス用の 2 つの同期パイプラインを維持する必要があり、アーキテクチャが複雑化し、キーワード検索とセマンティック検索の結果が不整合になるリスクが高まりました。1 か所に同期する方が、複数の場所に同期してクエリ時にシグナルを結合するよりも容易です。OpenSearch Service のキーワード検索とベクトル検索の統合機能により、PostgreSQL のプライマリデータベースと検索インデックスの同期が 1 つだけで済むようになりました。
- ソースデータ更新へのパフォーマンス影響の最小化 – 別の検索インデックスへのデータ同期は、データセットが常に変化するため複雑な問題でした。新しいお客様が増えるたびに、毎秒数百の更新がありました。同期プロセスによってこれらの更新のレイテンシーが影響を受けないようにする必要がありました。検索データとベクトル埋め込みを同じ場所に配置することで、複数の同期プロセスが不要になりました。同期プロセスがデータベース更新トラフィックに干渉することによるプライマリデータベースの追加レイテンシーも回避できました。
以前のサードパーティ検索エンジンは高速な EC 検索に特化していましたが、Amplitude の特定のニーズには合致していませんでした。OpenSearch Service への移行により、2 つの同期プロセスを 1 つに削減してアーキテクチャを簡素化しました。既存の検索プラットフォームは段階的に廃止しました。つまり、次の図のように、既存プラットフォームへの同期と OpenSearch Service 上の統合キーワード・セマンティック検索インデックスへの同期の 2 つのプロセスが一時的に並行して存在しました。
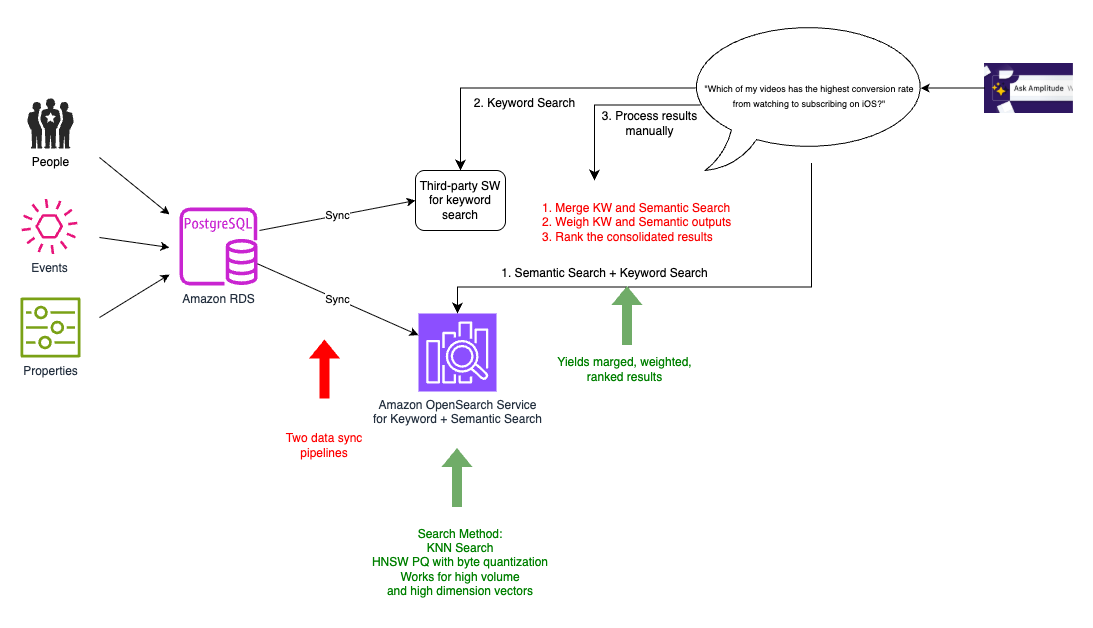
前のイテレーションで特定した k-NN 検索の利点に加え、OpenSearch Service への移行で 3 つの主要なメリットを実現しました。
- レイテンシーの削減 – 埋め込みをプライマリデータと同じ場所に配置する代わりに、検索インデックスと同じ場所に配置できました。検索インデックスは、質問に関連するユーザーイベントを抽出して LLM にコンテキストとして送信するためにクエリを実行する場所です。検索テキスト、メタデータ、埋め込みがすべて 1 か所にあるため、すべての検索要件に対して 1 回のホップで済み、レイテンシーが改善しました。
- コンピューティングリソースの削減 – ユーザーイベントスキーマには 5,000〜20,000 の要素がありました。各ユーザークエリに必要なのは 20〜50 の関連要素だけなので、スキーマ全体を LLM に送る必要はありませんでした。OpenSearch Service の効率的なフィルタリング機能により、テナント固有のメタデータを使ってベクトル検索空間を絞り込み、マルチテナント環境全体のコンピューティング要件を大幅に削減できました。
- スケーラビリティの向上 – OpenSearch Service では、HNSW プロダクト量子化 (PQ) やバイト量子化などの追加機能を活用できました。バイト量子化により、リコールの低下を最小限に抑えつつ、数百万のベクトルエントリを処理でき、コストとレイテンシーが改善しました。
ただし、この暫定ソリューションでは、データの OpenSearch Service への完全な移行はまだ完了していませんでした。旧パイプラインと新パイプラインが並行して存在し、デュアル同期が必要でした。旧検索インデックスを段階的に廃止する一時的な過程であり、旧パイプラインはパフォーマンスとリコールの比較基準として機能しました。
イテレーション 4: OpenSearch Service によるハイブリッド検索
最終アーキテクチャでは、次の図のように、すべてのデータを OpenSearch Service に移行し、ベクトルデータベースとしても機能させました。
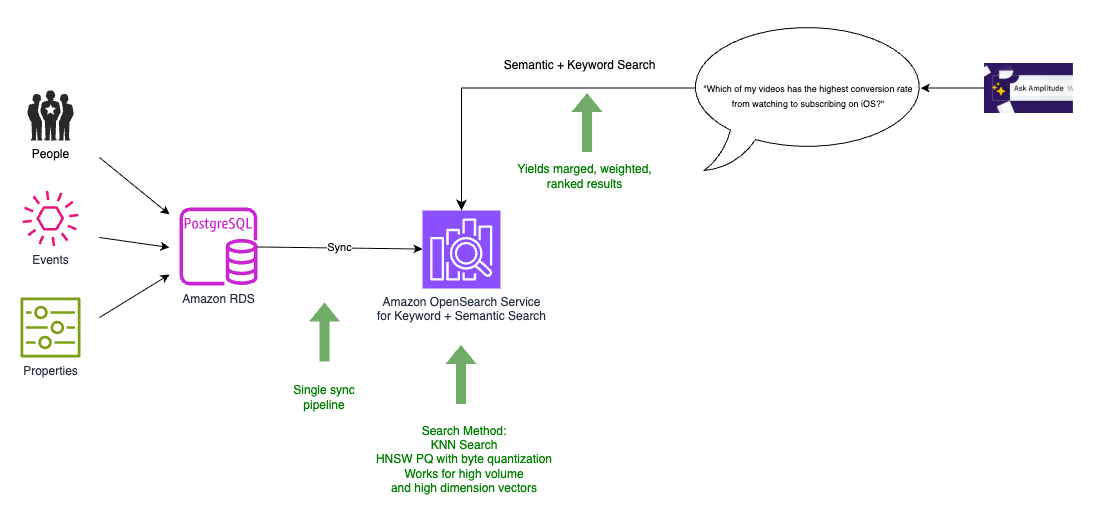
PostgreSQL データベースから統合検索・ベクトルインデックスへのデータ同期が 1 つだけで済むようになり、データベースのリソースをトランザクショントラフィックに集中できるようになりました。OpenSearch Service は検索結果のマージ、重み付け、ランキングを同一クエリ内で提供します。アプリケーション内で別モジュールとして実装する必要がなくなり、単一のスケーラブルなハイブリッド検索 (キーワードベース (字句) 検索とベクトルベース (セマンティック) 検索の統合) を実現しました。OpenSearch Service では、Amazon Personalize との新しい統合も試すことができました。
ユーザー生成コンテンツを活用した RAG の進化
お客様は、スキーマ (データカラムの構造と名前) だけでは答えられない、プロダクト利用状況に関するより深い質問をしたいと考えていました。データベースのカラム名を知っているだけでは、データの意味、値、適切な解釈が必ずしも明らかになりません。スキーマだけでは不完全な情報しか得られません。単純なアプローチとしては、スキーマだけでなくすべてのデータ値をインデックス化して検索する方法がありますが、Amplitude はスケーラビリティの理由からこれを避けています。イベントデータのカーディナリティとボリューム (潜在的に数兆のイベントレコード) を考えると、すべての値のインデックス化はコスト的に現実的ではありません。Amplitude は全お客様で約 2,000 万のチャートとダッシュボードをホストしています。ユーザー生成コンテンツは貴重で、他のユーザーが過去にデータをどのように可視化したかを分析することで、データの意味とコンテキストをより深く理解できることがわかりました。例えば、ユーザーが「2 日配送」について質問した場合、Amplitude はまずデータスキーマに「shipping」や「shipping method」のような関連するカラム名があるかを確認します。該当するカラムがあれば、そのカラムの潜在的な値を調べて 2 日配送に関連する値を見つけます。さらに、ユーザーが作成したコンテンツ (チャート、ダッシュボードなど) を検索し、社内の他のユーザーが 2 日配送に関連するデータを既に可視化しているかを確認します。該当する場合、その既存のチャートをデータのフィルタリングと分析方法のリファレンスとして活用できます。ユーザー生成コンテンツを効率的に検索するため、Amplitude はキーワード検索とベクトル類似度 (セマンティック) 検索を組み合わせたハイブリッドアプローチを採用しています。テナント分離とプルーニングには、メタデータを使ってまずお客様でフィルタリングし、その後ベクトル検索を行います。
まとめ
本記事では、Amplitude が OpenSearch Service をベクトルデータベースとして活用し、プロダクト分析データを自然言語でクエリできる AI アシスタント Ask Amplitude を構築した方法を紹介しました。4 回のイテレーションを経てシステムを進化させ、最終的にキーワード検索とセマンティック検索を OpenSearch Service に統合しました。これにより、複数の同期パイプラインを 1 つに簡素化し、検索オペレーションの統合でクエリレイテンシーを削減し、HNSW PQ やバイト量子化などの機能を活用して大規模なマルチテナントベクトル検索を効率的に実現しました。スキーマ検索を超えて 2,000 万のユーザー生成チャートとダッシュボードをインデックス化し、ハイブリッド検索を使ってプロダクト利用状況に関するお客様の質問に答えるためのより豊富なコンテキストを提供するようシステムを拡張しました。
自然言語インターフェースの普及が進む中、Amplitude の反復的な取り組みは、OpenSearch Service のようなベクトルデータベースを使った LLM と RAG の活用により、豊かな対話型カスタマーエクスペリエンスを実現する可能性を示しています。キーワード検索とセマンティックベクトル検索を統合した検索ソリューションへの段階的な移行により、Amplitude はアーキテクチャの複雑さを軽減しながらスケーラビリティとパフォーマンスの課題を克服しました。OpenSearch Service を使った最終アーキテクチャにより、効率的なマルチテナンシーときめ細かなアクセス制御を実現し、低レイテンシーのハイブリッド検索も可能になりました。Amplitude はより深いインサイトを生成しデータをコンテキスト化することで、お客様により自然で直感的な分析機能を提供しています。
Ask Amplitude が Amplitude 関連の概念や質問を自然言語で表現する方法について詳しくは、Ask Amplitude を参照してください。OpenSearch Service をベクトルデータベースとして使い始めるには、Amazon OpenSearch Service as a Vector Database を参照してください。
著者について
この記事は Kiro が翻訳を担当し、Solutions Architect の Takayuki Enomoto がレビューしました。