Amazon Web Services ブログ
CyberZ が Amazon DynamoDB を使用してフォロータイムラインの表示に必要な Read-Light 方式を実現した方法
CyberZ について
CyberZ はスマートフォンに特化した広告マーケティング会社として 2009 年に設立しました。スマートフォン広告における運用・効果検証、交通広告やウェブ CM の制作など、幅広いマーケティング事業を展開しています。日本に加えて、サンフランシスコ、韓国、台湾にも支社を構え、国内広告主の海外進出および海外広告主の日本展開支援も行っています。また、メディア事業として動画配信プラットフォーム「 OPENREC.tv 」、 e スポーツ事業として、国内最大級のeスポーツイベント「 RAGE 」を運営しています。 CyberZ 100 % 子会社としては、オンラインエンタテインメント事業、プロダクション事業をおこなう「株式会社 eStream 」、 e スポーツに特化した広告マーケティング事業「株式会社 CyberE 」の事業展開をしています。

OPENREC.tv はゲーム配信を中心とした高画質・低遅延のライブ配信プラットフォームサービスです。 Wowza Streaming Engine / Low Latency HLS を使用した遅延の少ない配信基盤や、 Redis / Socket.io を利用したリアルタイムチャット機能などを AWS 上で構築しており、リレーショナルデータベースは Amazon Aurora を、 NoSQL は Amazon DynamoDB や Amazon ElastiCache (Redis) を使用しています。
この投稿では、 OPENREC.tv のフォローしている配信者の配信一覧を表示するタイムライン機能を、リレーショナルデータベースの代わりに DynamoDB ベースを使って再設計した方法について説明します。
OPENREC.tv が DynamoDB を採用した理由
一般的な SNS では、ユーザーは他のユーザーをフォローして、自分のタイムライン (フィード) に表示させる機能があり、同様に OPENREC.tv でも、自分がフォローしている配信者のライブ配信を時系列順に追うことができるページ・機能が設けられています。
この機能について、以前からリレーショナルデータベースによる Read Heavy / Write Light な方式のタイムライン参照を提供していましたが、サービスの成長とともに多くの配信者をフォローしているヘビーユーザーや、フォロワー全員にフォローを返している配信者などのフォロー件数が増えてきて、タイムライン取得 API のレスポンスタイムの悪化が顕著になってきました。数百件ほどのフォロー数で、ページが表示できるまでに 3 秒~ 7 秒ほどかかる状態でした。一部にはフォロー数が数万を超えるユーザーもいたため、かなりの負荷がかかっていたと推測できます。
サービスとして主要な機能であるにも関わらずリレーショナルデータベースや Web サーバーへの負荷が非常に高い構成だったため、負荷軽減とユーザー体験の向上を目的として、 Read Heavy / Write Light な方式から Read Light / Write Heavy な方式の設計へ移行する必要がありました。
Read Heavy / Write Light な方式
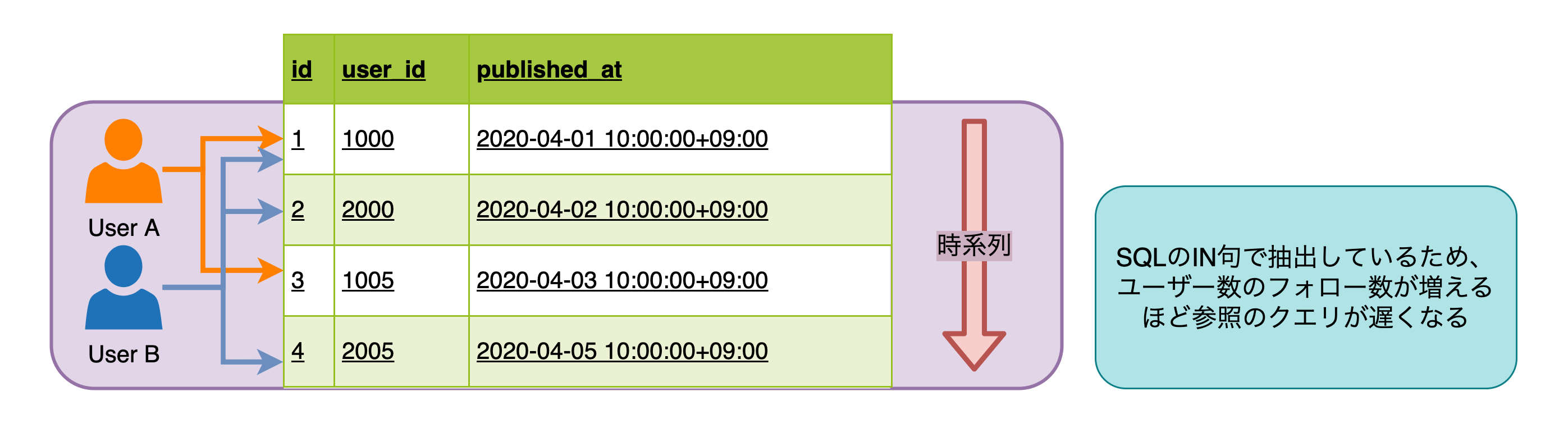
Read Heavy / Write Light な構成はとてもシンプルで、フォローしているユーザーのリストでデータを探索する方式です。
SQL で記述した場合、下記の通りです。
この方式の利点は、単一のテーブルで管理されており実装コストが低いことです。ほとんどの場合において、この SQL は高速に実行されますが、フォローしているユーザー数が増えるにつれて速度は低下していきます。この速度低下を回避するには参照クエリの負荷が高まらないようにフォローできるユーザー数を制限する必要があります。次の図はこの方式を図で示したものです。
Read Light / Write Heavy な方式
Read Heavy / Write Light の方式では、フォロー数が多いユーザーのタイムライン参照は遅くなります。この問題に対する解決策としては、ユーザーごとにタイムラインのレコードを追加することが挙げられます。つまり、配信者が配信を開始したときに自分のフォロワーの数のレコードを挿入し、フォロワーはユーザー ID ごとに時系列順にソートされたレコードセットを取得する、といった流れになります。次の図はこの方式を図で示したものです。

この方式のメリットは、ユーザーが自分のタイムラインのデータを取得する際の負荷を抑えられることです。ユーザーのフォロー数が多かったり、タイムラインのデータ取得リクエスト数が多かったりする場合はこの方式が好ましいでしょう。
一方で、この方式では、参照の負荷が抑えられる代わりに、配信開始時などのデータ更新時に、フォロワー数と同じ数のレコード書き込みが発生します。 2020 年 6 月現在、最もフォロワーが多い配信ユーザーでおよそ 22 万のフォロワーを有しているため、一度の配信開始処理で最大 22 万レコードの書き込みが発生し得る計算になります。
この方式を採用するには、不均衡な書き込みリクエストに瞬時に対応できる高いスループットを擁したデータストアが必要でした。そのため OPENREC.tv では、このタイムライン用のデータストアとして、高いスループットと柔軟なデータ構造を持ち合わせた Amazon DynamoDB を採用することにしました。
DynamoDB への移行
タイムライン機能には次の要件がありました。
- 配信者が配信するとフォロワー分のユーザー毎のタイムラインレコードが生成される。そのため、人気配信者が配信すると書き込みがスパイクする
- 同時アクセスに耐えられるだけの書き込み/読み込み性能を担保
- タイムラインに表示される情報はユーザー毎に異なる
- 時系列順で表示できること
キー設計
DynamoDB はパーティションキーとソートキーという 2 つの値からプライマリキーを構成する複合キーのテーブルを作ることができます。複合キーを持つテーブルに query を実行すると、パーティションキーごとにソートされたアイテムを取得することができます。この複合キーテーブルを使うことで時系列タイムライン機能を実現しています。
DynamoDBは事実上無制限にスケーラブルな NoSQL データベースサービスですが、これらのキー設計を間違えてしまうとスケーラビリティが損なわれてしまうため、適切なキー設計を行う必要があります。詳細については、DynamoDB 開発者ガイドの「パーティションとデータ分散」を参照してください。
パーティションキー
パーティションキーは、その名のとおり DynamoDB のパーティション (内部シャード) を決定するハッシュ関数に渡されるパラメータとなるキーです。
複合キーでないテーブルの場合は、このパーティションキー単体でプライマリーキーとして他の KVS と同じように動作します。複合キーテーブルの場合は、後述するソートキーと組み合わせてアイテムを一意に特定します。
注意したい点として、当然のことながら複合キーテーブルにおいてパーティションキーは重複し得ます。パーティションキーが同一ということは、アイテムが存在するパーティションも同一ということなので、そのパーティションが例えば配信者のユーザー ID のようなスパイクアクセスの可能性があるパラメータの場合は、 1 つのパーティションへのアクセスが集中してしまいます。テーブルのアクセス特性に応じて、ユーザー数が増えてもパーティションへのアクセスが分散するようなキーを設計する必要があります。次の図はこのアーキテクチャを示したものです。

OPENREC.tv では、参照するユーザー(配信者のフォロワー)の ID をパーティションキーとしました。 1 ユーザーの参照リクエストがスパイクすることは基本的に起こりえないため、フォロワーに対するアイテムの追加も各パーティションに満遍なく分散されます。次の図はこのアーキテクチャを示したものです。

ソートキー
複合キーテーブルにおいて、同一のパーティションキーを持つアイテムのソートに使われるキーがソートキーです。このソートキーを使って、 DynamoDB では昇順降順・範囲検索が可能です。
ただし、複合キーテーブルはパーティションキーとソートキーで一意にアイテムを判断するため、重複は許されません。時系列順に並べる必要があるタイムラインテーブルのソートキーに単純な時刻データを指定した場合同じ値が入り得るため、重複しない値が必要です。
アクセスパターンは次のとおりです。
- 書き込み時に表示ユーザー ID ごとにアイテムを生成できる
- ロード時に、タイムライン情報を各視聴者が時系列で読み取ることができる
- 同時に配信されても個別の情報を取得できる
OPENREC.tv では、日時に参照先の ID を連結したものを保持するようにしました。次のスクリーンショットは、このテーブルのメタデータのサンプルです。
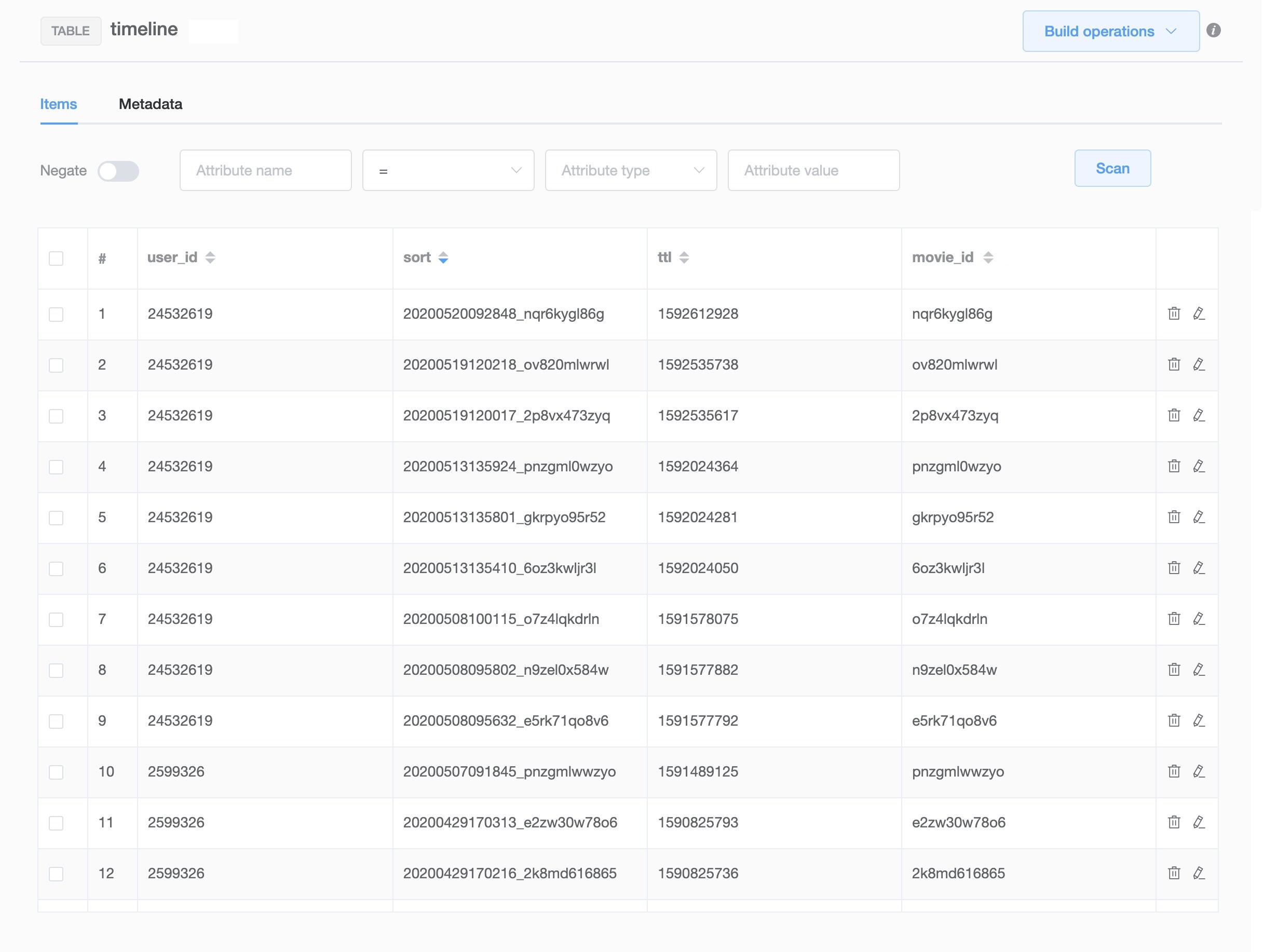
データを参照するときは、 DynamoDB の query を利用して参照しています。 2 ページ目以降の参照は、ページの末尾の sort_key を受け渡しその値よりも大きい (もしくは少ない) sort_key のアイテムを query 句で抽出してページングを実現しています。文字列型の比較は ASCII 文字コード値に基づいて行われるため、 sort_key BETWEEN '20200501' AND '20200508' という指定で範囲検索をすることも可能です。次のコードをご覧ください。
タイムラインテーブルには配信の ID と時間などしかデータを保持していないため、 DynamoDB からアイテムを取得した後に ID のリストを使い配信情報を保存しているリレーショナルデータベースのテーブルからデータを取得します。データがリレーショナルデータベースと DynamoDB で二重に管理される状態になるため、データの整合性を正しく定義しておく必要があります。 OPENREC.tv では、配信の削除などが行われても DynamoDB のテーブルからの削除は行わずに、アプリケーションの実装で除外するようにしています。
Time to Live の設定
DynamoDB のレコードには、Time to Live (TTL) の情報を付与してアイテムを自動削除することができます。時系列タイムラインのような機能はアイテムが古くなるにつれアクセスが減る特性があるため、古いデータを参照する必要がないのであれば TTL を設定することを検討するとよいでしょう。詳細については、 DynamoDB 開発者ガイドの「有効期限 (TTL) を使用して項目を失効させる」を参照してください。
TTL を使用する事でストレージ使用料とコストを削減しました。アイテム数・ストレージ使用量は配信数やフォロー数などによって変化しますが、 2020 年 6 月現在の OPENREC.tv での実際のアイテム数は 1 日あたり 100 〜 300 万アイテム、 1 ヶ月でおよそ 6,000 万アイテムと少なくありません。そのため、 TTL として 1 ヶ月を設定しており、ストレージサイズが増えすぎないようにしています。
キャパシティモードの設定
DynamoDB では、 1 パーティションあたり 3,000 RCU (RRU) / 1,000 WCU (WRU) がサポートされていますが、そのキャパシティユニット (リクエストユニット) の課金体系にはプロビジョニングキャパシティモードとオンデマンドキャパシティモードの 2 つが存在します。
(訳者注記: DynamoDB では処理の単位をプロビジョンモードではキャパシティユニット、オンデマンドモードではリクエストユニットと表記しています。詳細については、 DynamoDB 開発者ガイドの「読み込み/書き込みキャパシティーモード#読み取りリクエストユニットと書き込みリクエストユニット」を参照してください。)
プロビジョニングキャパシティモード
プロビジョニングキャパシティモードは、消費するキャパシティを事前に予約しておく方式です。テーブルのアクセス頻度などによって、そのキャパシティを見積り、コストとパフォーマンスを最適化しておく必要があります。消費量や時間で AutoScaling を設定することができるため、ユーザー数に比例して増加する傾向があったり、アクセスされる時間が決まっているようなテーブルは、プロビジョニング キャパシティモードを使用することで、コストを節約できるでしょう。ただし、リクエストがバーストした時にスロットリングを招いてしまう可能性がある点は注意が必要です。詳細については、 DynamoDB 開発者ガイドの「プロビジョニングモード」を参照してください。
オンデマンドキャパシティモード
オンデマンドキャパシティモードは、消費されたキャパシティに対して課金がされる従量制の料金体系です。テーブルにキャパシティの指定をする必要はなく、過去の最大値の 2 倍までスループットが出るように自動的に対応されます。詳細については、 DynamoDB 開発者ガイドの「オンデマンドモード」を参照してください。
このモードの最大のメリットは、スパイクアクセス耐性が高いということです。プロビジョニングキャパシティモードでスパイクアクセス耐性を高めるためには、純粋に予約するキャパシティを増やすこととなります。
特に今回の場合だと、フォロワーの多い配信者が配信するだけで数十万の書き込みリクエストが発生するため、これを踏まえたキャパシティをプロビジョニングモードで予約してしまうと、そのほとんどは消費されないまま課金され、かなりの額になることが予想されます。
今回のような、時間帯などに左右されないスパイクアクセスの発生が予測される場合は、オンデマンドモードに切り替えることでコスト節約が期待できます。また、過去の最大値の 2 倍までスループットが出るように自動的に対応してくれるため、キャパシティの引き上げを意識しなくて済みます。
オンデマンドキャパシティモードでテーブルを作成した場合のデフォルトのキャパシティは、最大 12,000 RRU または 4,000 WRU のため、 OPENREC.tv では、あらかじめ数万の高いキャパシティを指定したプロビジョニングテーブルを作成して、オンデマンドキャパシティモードに変更してリリースを行いました。リリース直後にフォロワーの多い配信者が配信することで書き込みリクエストがスパイクした場合にも対応できるように、キャパシティの暖機運転を行ったのです。
リトライ設計
DynamoDB のスロットリングや予期せぬエラーが発生した場合に備えて、適切にリトライされるように設計しておく必要があります。詳細については、DynamoDB 開発者ガイドの「DynamoDB でのエラー処理」を参照してください。
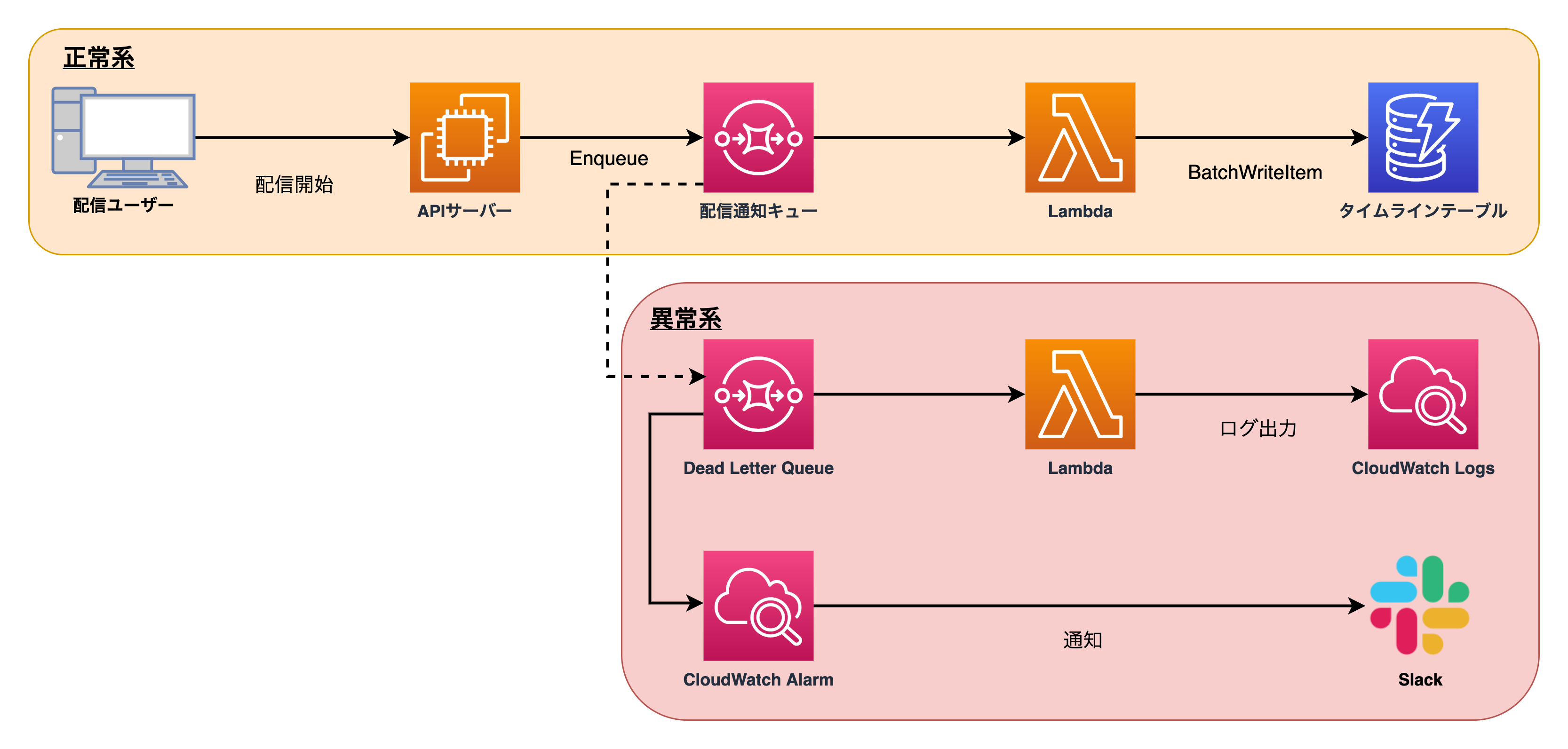
OPENREC.tv では Amazon SQS に配信開始などのタイムライン書き込みメッセージをキューイングして、 AWS Lambda で DynamoDB へ 25 件ずつに加工して BatchWriteItem を並列に実行して書き込んでいます。
Lambda 内では Retryable なエラーが返ってきたときや、 UnprocessedItems の項目をアプリケーションレベルでリトライしています。それに加えて前段の SQS で、 Lambda のリトライ回数を設定しています。 SQS のメッセージは仕様上複数回実行されうるので、 Lambda 内のアプリケーションでの処理は冪等にしておく必要があります。 DynamoDB の PUT リクエストは存在しているアイテムに対して実行されたとき上書きする挙動をするため、複数回実行されても問題ありません。
また、失敗したメッセージが無限にリトライされることを避けるために、一定回数失敗したメッセージは Dead-letter queues (DLQ) に送られるように指定しています。 DLQ に積まれたメッセージは Amazon CloudWatch Logs に出力して、 CloudWatch Alarms によって Slack に通知されます。次の図はこのアーキテクチャを示したものです。
パフォーマンス
改修前の構成では、およそ 300 件フォローしている状態で 1,500 ms ほどのレスポンスタイムだったのが、 100 ms 前後まで短縮することができました。
また、書き込み時のスパイクアクセスについて、実際におよそ 21 万のフォロワーを持つユーザーが配信を開始した時の DynamoDB のメトリクスを見ると、書き込みキャパシティーのグラフに瞬間的に 3,500 ほどが計上されています。次のスクリーンショットは、実際のパフォーマンスメトリクスです。

このメトリクスは 1 分間の平均値が表示されるため、計算すると 1 分間に合計でおよそ 210,000 WRU (3,500 WRU * 60 sec) 消費されていることがわかります。書き込みに消費した Lambda の実行時間は 10,800 ms だったため、 21 万件の瞬間的な書き込みリクエストに対して、平均 21,000 WRU/s のスループットでリクエストを処理していることが考えられます。
オンデマンドキャパシティモードのデフォルトのスループット制限は、 40,000 RRU または 40,000 WRU のため、これ以上のスループットが必要になる可能性がある場合は上限緩和リクエストによって制限を引き上げることができます。
まとめ
この投稿では、 OPENREC.tv のフォローしている配信者の配信一覧を表示するタイムライン機能を、リレーショナルデータベースの代わりに DynamoDB を使って再設計した方法について説明しました。
タイムラインなどのユーザーによって IN 句内の件数が増える機能は、ユーザーごとにデータを用意して参照を最適化することができます。負荷が書き込み時に集中するため、適切に分散・キューイングする必要があります。また、 DynamoDB を利用するときはパーティションキーとソートキーを適切に設計する必要があり、アクセスの頻度やその特性によってはオンデマンドモードが適している場合もあります。とりわけスパイクアクセスの想定されるテーブルでは、 DynamoDB の特徴である高いスループットを損なわないまま、費用とスロットリングエラー両方の削減が期待できます。
DynamoDB の詳細については、 Amazon DynamoDB 開発者ガイド および AWS Black Belt Online Seminar 2017 Amazon DynamoDB を参照してください。
著者について
株式会社 CyberZ 藤井貴大 (@toro_ponz)

OPENREC.tv の SRE チームに所属するソフトウェアエンジニアです。負荷試験や DynamoDB のキャパシティプランニング、 EKS の運用などを中心にサービス開発を行っています。
翻訳は SA 成田、SA 木村 (悠) 、SA 廣瀬が担当しました。原文はこちらをご覧ください。