Amazon Web Services ブログ
Pagely が、カスタマーサポートの分析を容易にするために AWS でサーバーレスデータレイクを実装
Pagely は、マネージド型 WordPress ホスティングサービスを提供する AWS アドバンスドテクノロジーパートナーです。当社の顧客は、使用、請求、サービスのパフォーマンスの可視性を向上させるために継続的に当社にプレッシャーをかけています。こうした顧客により良いサービスを提供するため、サービスチームは、アプリケーションサーバーが作成したログに効率的にアクセスする必要があります。
以前から、当社ではオンデマンドで基本的な統計を集めるシェルスクリプトを利用していました。最大の顧客のログを処理する場合、Amazon EC2 インスタンスで実行される最適化されていないプロセスを使用して 1 件のレポートを作成するのに 8 時間以上かかりました—時には、リソースの制限のためにクラッシュすることがありました。そこで、従来のプロセスの修正にさらに力を注ぐのではなく、適切な分析プラットフォームを実装する時が来たと判断しました。
当社の顧客のログはすべて、圧縮された JSON ファイルとして Amazon S3 に保存されています。Amazon Athena を使用して、これらのログに対して直接 SQL クエリを実行しています。データを準備する必要がないため、このアプローチは優れています。単にテーブルとクエリを定義するだけです。JSON は Amazon Athena でサポートされているフォーマットですが、パフォーマンスやコストに関して最も効率的なフォーマットというわけではありません。JSONファイルは、データの各行から 1 つまたは 2 つのフィールドを返すだけであってもその全体を読み取る必要があるので、必要以上に多くのデータをスキャンしなくてはなりません。さらに、JSON を処理するのが非効率であるため、クエリ時間が長くなります。
30 分のクエリタイムアウト限度に達したため、Athena で最大の顧客のログを照会することは理想的ではありませんでした。この制限を増やすことはできますが、クエリは既に必要以上に時間がかかるようになっていました。
この記事では、Pagely が AWS アドバンスドコンサルティングパートナーである Beyondsoft とどのように協力して、Beyondsoft が開発したオープンソースツールである ConvergDB を使用して DevOps 中心のデータパイプラインを構築したかについて説明します。このパイプラインでは、AWS Glue を使用してアプリケーションログを最適化されたテーブルに変換し、Amazon Athena を使用して迅速かつ費用対効果の高いクエリを実行できます。
Beyondsoft との協力
当社は、できるだけ少ないオーバーヘッドで、エンジニアがデータに簡単にアクセスできるようにするために何かを行う必要があることを知っていました。クエリ時間を短縮するために、データをより最適なファイル形式にしたいと考えていました。無駄のない企業なので、当社には技術を深く掘り下げる余裕はありませんでした。このギャップを克服するために、Beyondsoft と協力して、データレイクの最適化と管理に最善のソリューションを決定しました。
ConvergDB とは?
ConvergDB は、データレイクの作成と管理のためのオープンソースソフトウェアです。ユーザーは、ソーステーブルとターゲットテーブルの構造を定義し、それらを具体的なクラウドリソースにマップします。そうすると、ConvergDB が、AWS で必要なリソースを構築および管理するために使用するすべてのスクリプトを作成します。ConvergDB によって作成されたスクリプトは、コードとしてのインフラストラクチャを管理するためのオープンソースのツールである HashiCorp Terraform を使用してデプロイされます。
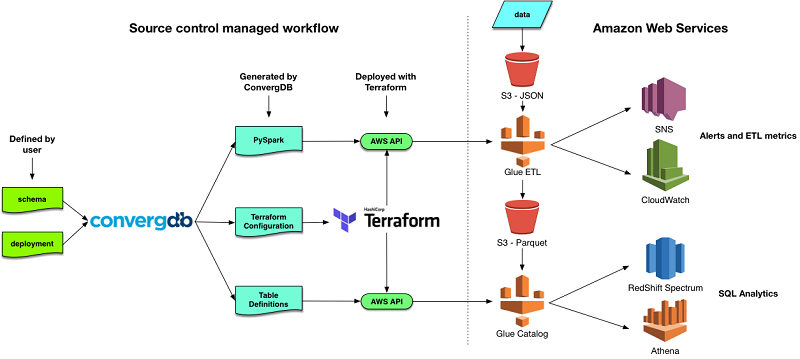
ConvergDB を使用すると、データレイクをメタデータで定義して、テーブル作成と ETL (抽出、変換、ロード) プロセスを推進することができます。スキーマファイルは、ロードされる際に受信データを変換するために使用されるフィールドレベルの SQL 式を含むテーブルの定義に使用されます。これらの式は、データのパーティショニングに使用されるフィールドに加えて、計算フィールドを導出するために使用されます。
スキーマが定義されると、デプロイメントファイルを使用して、管理するために使用される ETL ジョブにそのテーブルを配置できます。ETL ジョブのスケジュールは、デプロイメントファイルおよび実行時に使用するターゲット S3 バケットや AWS Glue DPU の数などのオプションのフィールドで指定します。
ConvergDB はコマンドラインバイナリであり、サーバーにインストールする必要はありません。すべてのアーティファクトは、ソースコントロールを使用して管理できるファイルです。ConvergDB バイナリは、すべての設定ファイルを取り込み、データレイクのデプロイに必要なすべてのアーティファクトを含む Terraform 設定を出力します。これらのアーティファクトは、ETL スクリプト、テーブルおよびデータベースの定義、およびジョブを実行するために必要な IAM ポリシーのいずれかです。また、Amazon SNS 通知トピックや、ConvergDB ETL ジョブによって処理されるデータの量を示す Amazon CloudWatch ダッシュボードさえも含まれます。
スピードバンプ
どんな実装も完全ではありません。以下のセクションでは、Beyondsoft のエンジニアである Jeremy Winters 氏が、遭遇した問題とその対処方法について説明します。
パーティショニングとカラムナ形式
Amazon S3 で SQL アナリティッククエリのデータを構造化するための主なベストプラクティスの 2 つは、パーティショニングとカラムナファイル構造です。
パーティショニングは、データを効率的に取得するのに最も適した命名規則によって、S3 の異なるプレフィックスまたはフォルダにデータを分割するプロセスです。これにより、Athena は、実行中の特定のクエリに関連しないデータをスキップすることができます。
Apache Parquet は、Hadoop エコシステムのツールで定評があるカラムナ形式です。Parquet は、ファイルの別々の連続した領域にデータの列を保存します。Athena などのツールは、メタデータのフッターによる指示で、クエリを実行するために必要なファイルのセクションだけを読み込みます。このプロセスは、I/O とネットワークデータ転送の大部分を排除するのに役立ちます。
パーティショニングと Parquet ファイルによる I/O の削減は、クエリのパフォーマンスを向上させるだけでなく、Athena の使用コストを劇的に削減します。
データレイクの最適化のベストプラクティスの詳細については、ブログ記事「Top 10 Performance Tuning Tips for Amazon Athena」を参照してください。
小さなファイルの問題
Hadoop エコシステムのツールで発生する従来からの問題は、「小さなファイルの問題」と呼ばれています。 多数の小さなファイルを処理すると、システムのオーバーヘッドが大きくなり、ジョブの実行時間が急増し、失敗する可能性があります。Pagely は、3,000 万のファイルにわたって約 4TB のデータがあります。こうしたファイルのうち、2,950 万のファイルが占める S3 のデータはわずか 1.2 TB です。
この問題を分析するため、ソースデータバケットに関する S3 インベントリレポートを有効にしました。このレポートは、毎日 ORC (最適化された行の列) 形式で配信されます。そこから、SQL を使用してバケットの内容を分析する Athena テーブルを作成するのは非常に簡単です。
Athena を使用して、「ホットスポット」である S3 プレフィックス、つまり多数の小さなファイルを持つプレフィックスを特定しました。1 GB 未満のデータに統合できる、14,000 のプレフィックスを特定することができました。つまり… 2,950 万のファイルが 14,000 のファイルに統合できたのです。
以下のクエリが、小さなファイルのホットスポットを識別する方法です。GROUP BY 式は、データに合わせることができます。この例は、バケット内の最初の「フォルダ」でグループ化する方法を示しています。
結果は、統合することができ、統合する必要があるオブジェクトパス内のプレフィックスを示します。8 以上のファイルがあり 1GB 未満のものは、1 つのオブジェクトに統合して、元のものと置き換えることができます。

ホットスポットが特定されたら、小さなファイルを統合する必要があります。上の画像にある結果は、プレフィックスが 14184 であるファイルは、502 のファイルで合計 33.7 MB を占めていることを示しています。この多数の小さなファイルのオーバーヘッドを減らすために、すべてのファイルを 1 つのファイルにまとめます。私たちのファイルでは gzip 圧縮を使用しているので、未加工の JSON データを解凍、連結したり、再圧縮するのではなく、簡単な連結で組み合わせることができます。これを実現するには、次の例に示す Linux の cat コマンドのように多くの方法があります。
gzip ファイルでこれらのコマンドを実行し、ファイルを解凍する -d フラグを使って結果のファイルが有効な gzip であることをテストします。一部のユースケースでは、Amazon S3 マルチパートコピー API を使用することもできますが、このアプローチでは、小さなファイルのサイズが少なくとも 5 MB であることが必要です。
Pagely データセットについては、与えられたプレフィックスを持つすべてのファイルをプルダウンし、単一の gzip に連結し、連結されたファイルをアップロードし、アップロードを検証し、小さなファイルを削除するシェルスクリプトを作成しました。このスクリプトは AWS Fargate コンテナを使用して実行され、それぞれが単一のプレフィックスを処理します。このプロセスの詳細は別のブログ記事でまとめますが、AWS Batch のようなサービスを使用すると、このようなジョブをより簡単に管理できます。すべての小さな履歴ファイルを連結するための総コストは 27 USD でした。
履歴データ
Pagely のログの毎日のデータ量は、1 日当たり数十ギガバイトであり、最小の AWS Glue 設定で簡単に処理できます。圧縮された 4 TB の履歴データ (圧縮されていない状態で 〜 28 TB) を変換するのは、もう少し難しい作業でした。
ConvergDB は、データをより小さなチャンクにバッチ処理します。非常に長時間実行される履歴変換ジョブが失敗した場合、最後のバッチだけが失われ、結果として約 1 時間の計算が失われます。ConvergDB は独自の状態追跡メカニズムを使用して、障害をジョブの次の実行に伝えるので、バッチを再度処理しようとする前の混乱がなくなります。バッチ処理は、AWS Glue クラスターのサイズに基づいて、ConvergDB によって作成される ETL ジョブの自動機能です。
Pagely でのデプロイメント後
中規模のアプリケーション (S3 では数ギガバイト) のレガシーレポートを実行すると、91 秒かかりました。データレイクが本稼働となった今、中規模のアプリケーションの同じレポートは Athena で 5 秒かかります—18 倍のパフォーマンス向上です。最大のデータセット (S3 で〜 1 TB) は、レガシープロセスでは失敗します。Athena を使用して未加工の JSON を直接照会するときも、十分なパフォーマンスは得られません。ただし、Athena を使用した新しい Parquet ベースのテーブルでは、24 秒で分析が完了します。
| レガシープロセス | Athena と JSON | Athena と Parquet | |
| 中規模の顧客 | 1 分、31 秒 | 1 分 | 6 秒 |
| 最大の顧客 | > 8 時間 | > 30 分 | 24 秒 |
これらの数値は明らかに重要ですが、最大の利点はパフォーマンスとコストを心配する必要がなくなり、エンジニアが問題の解決に集中できるようになったことです。クエリを書くわずか 15 分で、チーム全体が新しいデータにアクセスできるようになりました。AWS SDK を使用して Athena にディスパッチされたクエリによって、レガシープロセスをアップグレードすることができました。Athena が過酷な作業をしてくれるので、このプロセスは現在、(私のラップトップのような) 軽量マシンでも実行できます。
Pagely について
Pagely は、同社の説明によれば「Pagely は AWS アドバンスドテクノロジー、SaaS、パブリックセクターの各パートナーであり、マネージド型の WordPress ホスティングを提供しています。BMC、ユニセフ、ノースウェスタン大学、ボストン市などのエンタープライズレベルの顧客にサービスを提供し、当社のソリューションと業界最高レベルのエキスパートだけが可能なティアレスサポートを通じて柔軟性を提供しています。Pagely は、独自の ARES™ ウェブアプリケーションゲートウェイ、PressCACHE™ および PressCDN™ テクノロジー、ならびに Redis や NGINX などのオープンソースツールを使用して WordPress サイトを高速化する独自のテクノロジスタックを活用しています。」
Beyondsoft Consulting, Inc. について
Beyondsoft Consulting, Inc. は、同社の説明によれば「Beyondsoft Consulting, Inc. は、アマゾン ウェブ サービスのアドバンスドコンサルティングパートナーであり、米国およびアジアに配送センターを保有しています。Beyondsoft は、多くの分野で業界をリードするテクノロジー企業や一流企業に IT ソリューションとサービスを提供しています。当社の高度に熟練した専門家チームは、お客様の成功に重点を置いて、多くのお客様にとって望ましい AWS パートナーとして当社を際立たせています。」
ご質問またはご提案については、以下でコメントを残してください。
その他の参考資料
この記事が参考になった場合は、「Build a Data Lake Foundation with AWS Glue and Amazon S3」および 「Work with partitioned data in AWS Glue」もぜひご覧ください。
著者について
 Joshua Eichorn 氏は、Pagely の CTO です。大小さまざまな規模のチームを率いた経験を持つエンジニアリングリーダーです。個人の寄稿者、マネージャ、ディレクターとして、彼は新しいアプリケーションの最初の 1 行目を書くことから、大規模なサイトの 6 か月間に及ぶ書き直しまで、すべての作業を完了してきました。Josh は新しい課題を解決し、すばらしい製品を作ることが大好きです。
Joshua Eichorn 氏は、Pagely の CTO です。大小さまざまな規模のチームを率いた経験を持つエンジニアリングリーダーです。個人の寄稿者、マネージャ、ディレクターとして、彼は新しいアプリケーションの最初の 1 行目を書くことから、大規模なサイトの 6 か月間に及ぶ書き直しまで、すべての作業を完了してきました。Josh は新しい課題を解決し、すばらしい製品を作ることが大好きです。
 Jeremy Winters 氏は、ConvergDB の創始者であり、さまざまな業界のビジネスインテリジェンスで 18 年間働いています。過去 8 年間にわたり、AWS におけるデータレイク、データウェアハウスおよびその他のアプリケーションの構築に注力してきています。
Jeremy Winters 氏は、ConvergDB の創始者であり、さまざまな業界のビジネスインテリジェンスで 18 年間働いています。過去 8 年間にわたり、AWS におけるデータレイク、データウェアハウスおよびその他のアプリケーションの構築に注力してきています。