Amazon Web Services ブログ
Integral Ad Science における Amazon OpenSearch Service を使った日次 1 億件超のドキュメント処理の紹介
本記事は 2025 年 10 月 5 日 に公開された「Integral Ad Science scales over 100 M documents with Amazon OpenSearch Service」を翻訳したものです。
ソーシャルメディアプラットフォーム全体でコンテンツ量が急増し、リアルタイムの機械学習 (ML) モデルトレーニングが求められる中、Integral Ad Science (IAS) にはソリューションが必要でした。コンテンツ分類器の継続的な開発を支え、手動アノテーションによる遅延を解消し、ピーク時の処理スループットを最大化できるソリューションです。
IAS はデジタルメディアの計測と最適化におけるグローバルリーダーであり、デジタルメディア品質の信頼性と透明性の基準を確立しています。データドリブンなテクノロジーでリアルタイムのインサイトと包括的なデータを提供し、広告が安全で適切な環境で実際のオーディエンスに届くようにしています。
本記事では、IAS が Amazon OpenSearch Service を活用し、スケーラブルな SaaS 型 ML プラットフォームを構築した事例を紹介します。プラットフォームは日次 1 億件以上のドキュメントを処理し、プロジェクト開始時と比較して複雑な検索オペレーションで 40〜55% のパフォーマンス向上を達成しました。
課題
従来、データサイエンスチームは手動および半自動のアノテーションワークフローに数日から数週間を費やしていました。目標は、パフォーマンスとコンプライアンスの要件を満たしつつ、データサイエンティストやエンジニアが組織全体でセルフサービスで利用できる統合 ML プラットフォームの構築でした。
主な要件は以下のとおりです。
- 高次元ベクトル埋め込みの類似検索処理
- リアルタイムのインデキシングとクエリ
- 数百の ML 分類器の自動再トレーニング
ベクトルデータベースの評価
Apache Spark™ と Databricks プラットフォーム上に構築したカスタムベンチマークフレームワークで、ベクトルデータベースソリューションを広範に評価しました。
チームは以下のパフォーマンス指標で複数のソリューションを評価しました。
- 毎秒の類似検索クエリ数
- 一括書き込みスループット
- 一括読み取りスループット
- Spark とのネイティブ統合
結果として、優れたパフォーマンス、コスト効率、Amazon Web Services (AWS) との統合、活発なコミュニティサポートを理由に OpenSearch Service が選定されました。
カスタムベクトルインデキシングを備えた従来型データベース、専用ベクトルデータベースサービス、オープンソースソリューションなど、他のアプローチも検討しました。それぞれ強みはあったものの、コスト効率とスループットの要件を満たしつつ、チームが求める ML 体験を提供するソリューションは OpenSearch 以外にありませんでした。
ソリューション概要
広範な評価の結果、IAS は Amazon OpenSearch Service と Amazon Managed Streaming for Apache Kafka (Amazon MSK) を戦略的基盤として採用しました。アーキテクチャはホットストレージとコールドストレージの両階層にわたり、リアルタイム処理と履歴分析の両方に対応します。ベクトルとメタデータは Amazon MSK を通じてストリーミングされ、信頼性の高いスケーラブルな取り込みを実現します。Spark ベースのコンシューマーがマイクロバッチを処理し、リアルタイムベクトル検索用の Amazon OpenSearch Service (ホットレイヤー) と長期分析用の Databricks 上の Delta テーブル (コールドレイヤー) に送信します。
以下がソリューションの全体像です。
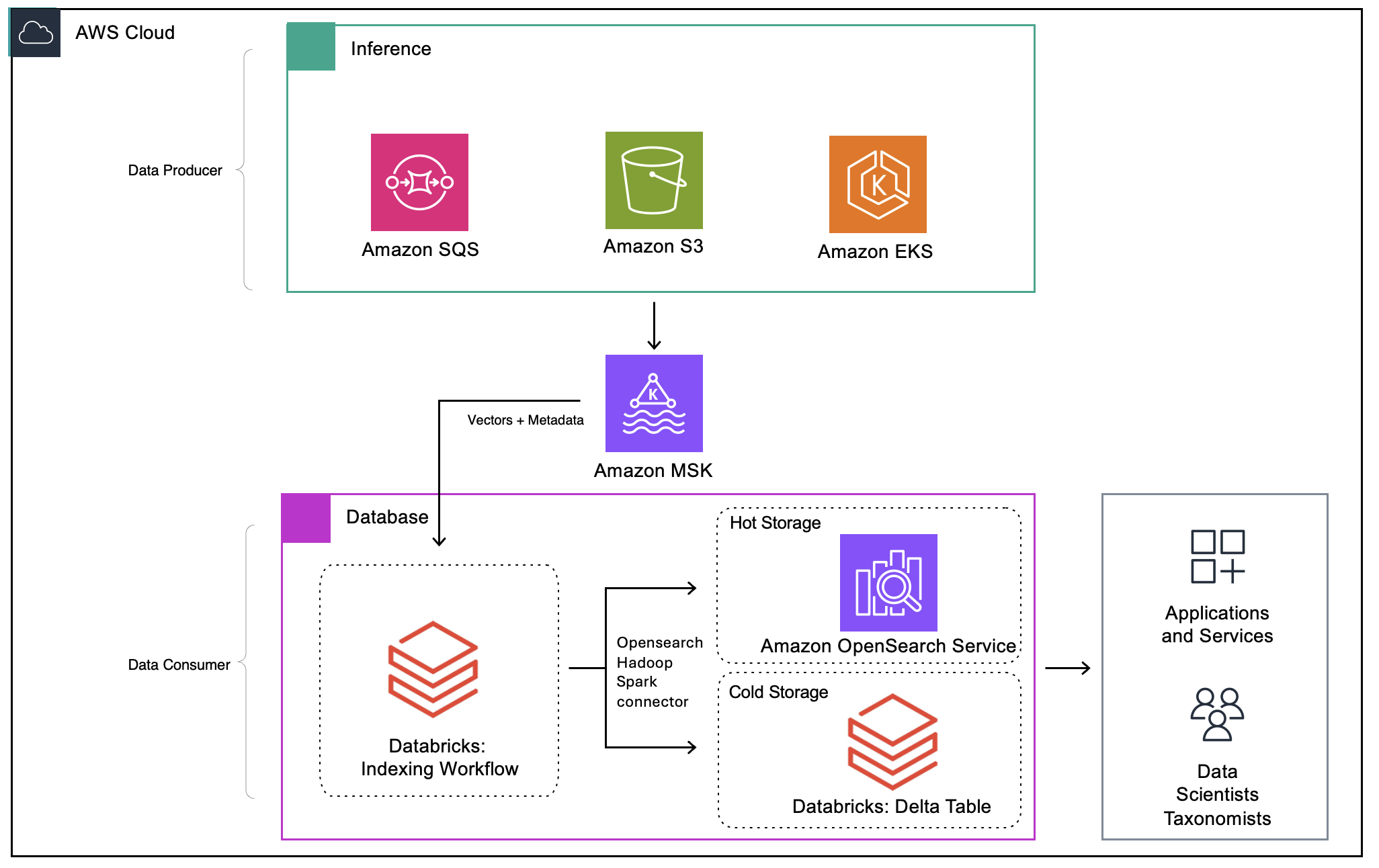
図 1: ソリューションアーキテクチャ
OpenSearch Service のベクトル検索機能と豊富なフィルタリング API により、データサイエンティスト、ナレッジワーカー、開発者がノートブック、カスタムアプリケーション、ワークベンチやポータルなどの GUI から利用できるようになりました。
ソリューションの最適化
OpenSearch Service クラスター構成は、目標パフォーマンスの達成に向けて複数の最適化フェーズを経ました。AWS チームの支援により、初期のパフォーマンスボトルネックと構成上の課題を克服しています。チームは AWS Graviton3 プロセッサの r6g から r7g インスタンスへ移行し、OpenSearch Service のバージョンを 2.13 から 2.19 にアップグレードし、Concurrent Segment Search 機能を有効化しました。
OpenSearch Service のインデックスマッピングは、高次元ベクトル埋め込みと効率的な k 近傍法 (k-NN) 検索に対応するよう最適化しました。具体的には、Hierarchical Navigable Small Worlds (HNSW) アルゴリズムと内積類似度を使用した 1,024 次元のベクトルフィールドを構成し、フィルタリング用のメタデータフィールドマッピングも設定しました。ベクトルフィールドでは構築と検索のパフォーマンスに最適化したパラメータ設定も行っています。IAS は OpenSearch Service の Scalar Quantization 機能でコスト削減も実現しました。
パフォーマンス最適化には、効率的な k-NN フィルタリング、シャード数とサイズの調整によるシャード最適化、Java Virtual Machine (JVM) ヒープ設定の調整と Concurrent Segment Search の有効化によるメモリ管理が含まれます。通常の検索では 40〜55% のパフォーマンス改善を達成しました。複雑なフィルタ付きオペレーションでは最大 80% の改善が見られ、最も大きな改善では 20 分以上かかっていた複雑なフィルタ検索が 1 分未満に短縮されました。
今後、IAS は OpenSearch Service 3.0 への移行を検討しています。集約パフォーマンスの最大 20% 向上、高カーディナリティ集約のレイテンシー大幅削減、GPU アクセラレーション対応の可能性を含むベクトルデータベース機能の強化が期待されます。
インデキシングの最適化
データ取り込みパイプラインは、Amazon MSK をストリーミング基盤として活用し、高可用性のために 10 パーティション、レプリケーションファクター 3 で構成しています。パイプラインは複数のステージでデータを処理し、信頼性の高い高スループットなドキュメント処理を実現します。継続的に実行される Spark ジョブが Kafka トピックを消費し、スループットとレイテンシーを最適化します。マイクロバッチは OpenSearch Service と Delta テーブルの両方に同時書き込みされ、ストレージレイヤー間の整合性を維持します。
アーキテクチャ変更により、IAS はクラスターに過負荷をかけることなく大量のドキュメントストリームを OpenSearch Service に安全にインデキシングでき、インデキシングプロセスのスロットリング制御が向上しました。
OpenSearch Hadoop コネクタ の統合により、knn-vector フィールドの Spark 連携が可能になり、処理量が大幅に向上しました。ホットレイヤーとコールドレイヤーへの書き込みの並列化により、ベクトルドキュメントのインデキシングパフォーマンスは日次 6,000 万件から 1 億件以上に向上しました。
IAS は knn-vector フィールドの Spark 連携をサポートするプルリクエストを OpenSearch Hadoop コネクタに提出しました。このコントリビューションは OpenSearch のオープンソースコミュニティとの協業を示す好例であり、IAS 固有の技術要件を満たすソリューションの実現にもつながりました。OpenSearch Hadoop コネクタとの統合は、システムの安定性を維持しつつ目標処理量を達成するうえで不可欠でした。
メリット
これらの工夫によって、IAS のデータサイエンティスト、エンジニア、ナレッジワーカーにスケーラブルな SaaS 型 ML 機能を提供するソリューションを実現しました。社内ユーザーは好みのツールで分類器のトレーニングとデプロイを行いながら、大規模環境で高いパフォーマンスを維持できます。Amazon OpenSearch Service をベクトル検索に活用するアプローチにより、インフラストラクチャの複雑さと手動プロセスが削減されます。
その他のメリットは以下のとおりです。
- 新しいデータの到着に基づく分類器の継続的な再トレーニング
- アノテーションサイクルを数日〜数週間からわずか数時間に短縮
- スパイクのあるトラフィックパターンでも日次 1 億件以上のドキュメントを効率的に処理
- 異なるチームやビジネスユニット間のマルチテナンシー対応
- 高いインデックスチャーンでのデータ保持コンプライアンスの維持
- データサイエンスチームが新しい ML モデルや実験をデプロイするまでの時間を短縮
アーキテクチャの柔軟性も重要なポイントです。IAS のベクトルデータベーススタックは柔軟な構成により、新しいユースケースに素早く対応できます。AWS Cloud Development Kit (AWS CDK) を使い、チームごとの一貫したコスト配分を維持しつつ、ソリューションをチーム間で複製できます。
まとめ
IAS は取り組みの当初、厳しいパフォーマンスとコスト要件を満たしつつベクトルデータベース機能を実現するスケーラブルなソリューションを求めていました。Amazon OpenSearch Service は、データサイエンスチームへの約束を果たすために必要な機能を提供しました。ベクトル検索の最適化と Amazon Managed Streaming for Apache Kafka の統合を含むアーキテクチャ改善により、コスト効率を維持しつつ大幅なパフォーマンス向上を達成しています。
IAS は複数のビジネスユニットへのプラットフォーム展開を続けており、SaaS 型 ML ソリューションのスケールに合わせてより多くの分類器をサポートする計画です。パイプラインにはさらに多くのユースケースが追加される見込みです。
ビジネスの加速を支援する方法については、AWS の担当者にお問い合わせください。
関連情報
- Amazon OpenSearch Service vector database capabilities revisited
- Amazon OpenSearch Service Resources
- Amazon OpenSearch Service Documentation
著者について
この記事は Kiro が翻訳を担当し、Solutions Architect の Sotaro Hikita がレビューしました。