Amazon Web Services ブログ
より高速かつ正確なエンタープライズ AI アプリケーションを実現する Amazon Bedrock マネージドナレッジベースのご紹介
2026 年 6 月 17 日、Amazon Bedrock マネージドナレッジベースを発表しました。これは、デベロッパーが所有データを使用してエンタープライズグレードの生成 AI アプリケーションを数分で構築できるようにする新しい機能セットです。エージェンティック AI アプリケーションを構築する組織は、正確かつ迅速で信頼性の高い結果をもたらすために、企業全体のデータへの、セキュアで信頼性の高い最新のアクセスを必要とします。マネージドナレッジベースは、検索拡張生成 (RAG) パイプラインの構築と管理の複雑さを抽象化し、デベロッパーがインフラストラクチャ管理ではなく、ビジネス成果の実現に注力できるようにします。
今日、エージェント向けのナレッジベースを構築するデベロッパーは、3 つの主要な課題に直面しています:
- エンタープライズデータへの接続 – エンタープライズナレッジは、コンテンツタイプ、アクセスコントロールリスト、ドキュメント形式が異なる、さまざまなシステムに分散して存在しています。各ソースごとにカスタムコネクタを構築および維持することは、開発の複雑さを増大させ、開発速度を低下させます。
- RAG 精度の最適化 – 検索拡張生成に関するベストプラクティスは進化し続けています。デベロッパーは、データから正確な回答を得るために、さまざまな解析戦略、チャンキングアプローチ、埋め込みモデル、エージェンティック検索動作を実験する必要があります。
- インフラストラクチャの大規模な管理 – 組織は、数百万のドキュメントを含む大規模なナレッジベースを運用したり、チーム間で数千の小規模なナレッジベースを管理したりする必要があります。いずれのパターンでも、信頼性の高いインフラストラクチャ、セキュリティ対策、コスト管理が不可欠です。
これらの課題により、デベロッパーは、アプリケーションに注力するのではなく、差別化につながらない作業を繰り返し実行せざるを得なくなります。
Amazon Bedrock マネージドナレッジベースは、デベロッパーが従来自らアセンブルおよび維持しなければならなかった複数のインフラストラクチャコンポーネント (ストレージ、検索、埋め込み、再ランキング、基盤モデルの選択など) を単一のマネージドプリミティブに抽象化することで、これらの課題を解決します。デフォルトでは、サービスがデフォルトの埋め込みモデル、再ランキング付けモデル、基盤モデルを自動的に選択および管理するため、お客様は、モデルを選択したり、管理したりすることなく、すぐに使用を開始できます。このマネージド基盤に加えて、使いやすさと精度をさらに高める 3 つの主要なイノベーションがあります:
- ネイティブデータコネクタ – エンタープライズデータと許可を SaaS アプリケーションからネイティブにプルする 6 つの事前構築済み取り込みコネクタにより、デベロッパーがアプリケーション固有の要件を管理する際のオーバーヘッドがなくなります。リリース時点では、Amazon S3、SharePoint、Confluence、Web Crawler、Google Drive、OneDrive がサポートされています。
- Smart Parsing – コンテンツのタイプやソースによって、正確な検索を実現するために必要なアプローチは異なります。Smart Parsing は、この複雑さを自動的に処理し、各データタイプとコネクタに適したパーシング戦略を選択することで、エージェントのために極めて高い精度を提供します。
- Agentic Retriever – 単一のナレッジベース内、または複数のナレッジベースにまたがる、マルチターン、マルチホップの検索を必要とする複雑なクエリ向けに最適化されています。Agentic Retriever は、エンドユーザーの意図を自動的に推測し、複数のデータソースやモダリティにわたって分散した組織のナレッジから関連するコンテキストを抽出します。
わずか数行のコードで、Amazon Bedrock マネージドナレッジベースは、エンタープライズナレッジエージェントを支えるエンドツーエンドの RAG パイプラインを自動的に管理およびスケールします。エージェントビルダー向けに、Amazon Bedrock AgentCore Gateway で事前構築済みのターゲットタイプとして利用可能となっています。これにより、統合はわずか数行のコードで済むほか、ロールベースの許可が自動生成され、AgentCore Observability ダッシュボードでオブザーバビリティと評価メトリクスが提供されます。
Amazon Bedrock マネージドナレッジベースの開始方法
マネージドナレッジベースの作成は簡単です。Amazon Bedrock AgentCore コンソールまたは Amazon Bedrock コンソールに移動し、[ナレッジベース] ページを開いて、[マネージド KB を作成] を選択します。操作感はいずれのコンソールでも同じです。既に慣れ親しんでいるかもしれない他のナレッジベースのタイプに加えて、推奨オプションとして [非構造化ベクトルストア KB] が利用可能になっています:
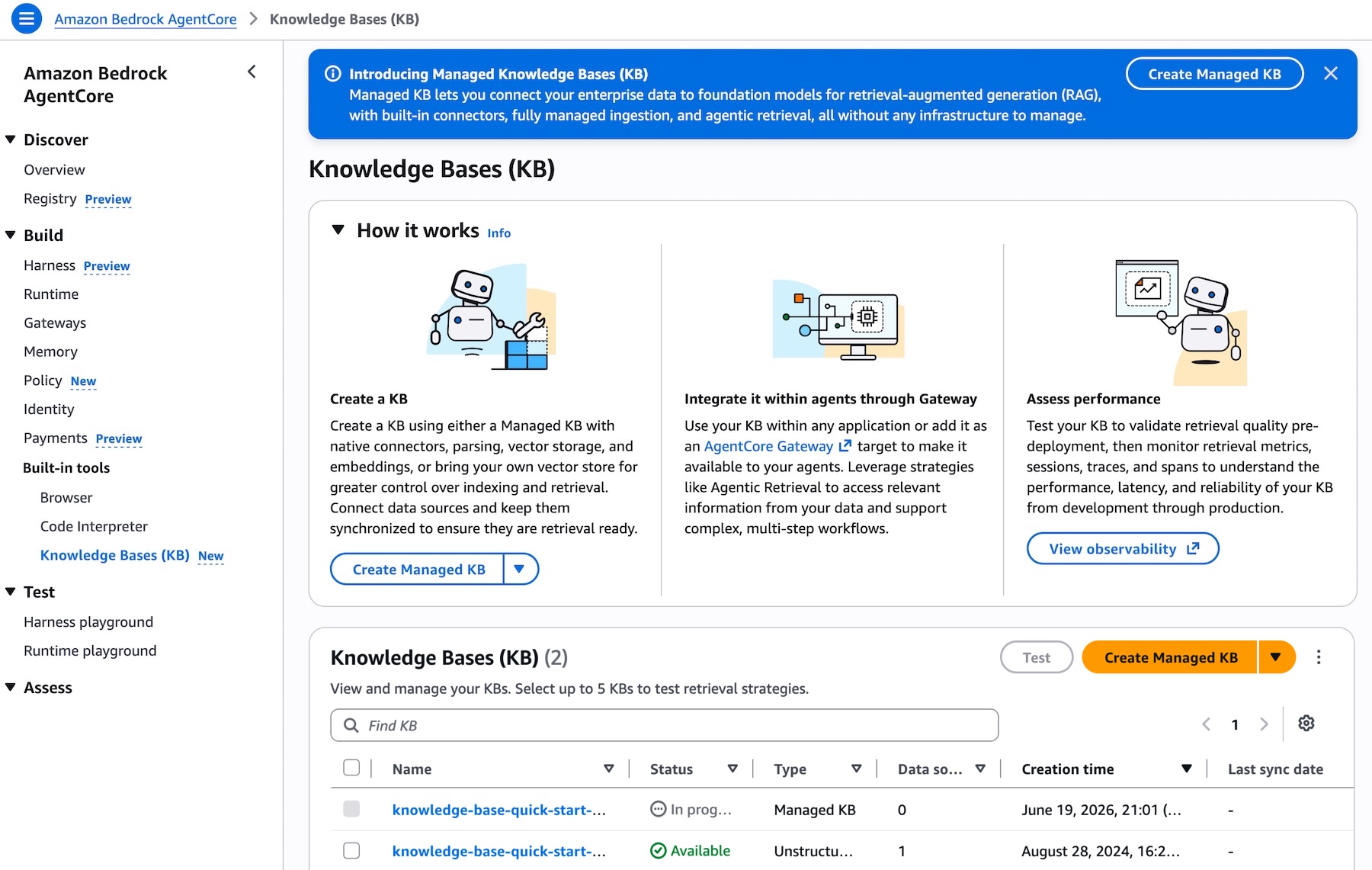
図 1 – Amazon Bedrock AgentCore コンソールのナレッジベースのリストページ。[タイプ] 列にさまざまな KB タイプが表示されており、[マネージド KB を作成] ボタンも確認できます
新しいナレッジベースを作成する際には、ドロップダウンで直接、サポートされているコネクタのリストから選択することで、エンタープライズデータソースに直接接続できます。AWS Identity and Access Management (IAM) ロールが自動的に作成され、必要に応じてこれらの許可を編集することを選択できます:
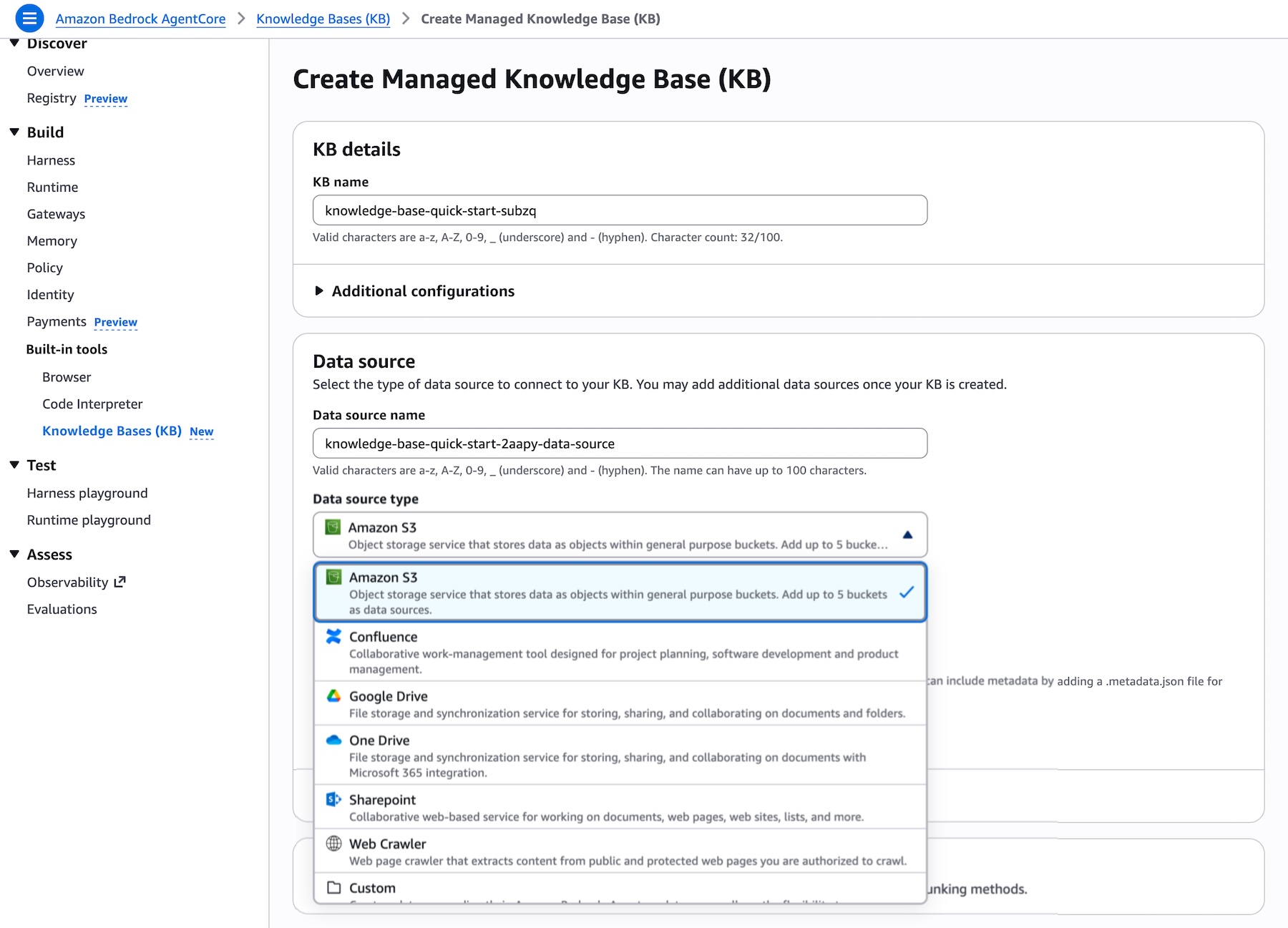
図 2 – [ナレッジベースを作成] ページ。データソースのドロップダウンリストが展開されており、Amazon S3、Confluence、カスタム、Google Drive、OneDrive、SharePoint、Web Crawler といったサポートされているすべてのコネクタが表示されています
最適化されたデフォルト設定セットが表示されるため、わずか数回のクリックでナレッジベースを作成できます。データが同期されたら、ナレッジベースをエージェントと統合したり、基盤モデルのツールとして指定してクエリを開始したりできます。
正確なデータインジェストのための Smart Parsing
ナレッジベースの構築における主要な課題の 1 つは、多様なデータタイプを正確に検索できるように準備することです。マネージドナレッジベースをデータソースにポイントすると、Smart Parsing が各データタイプとコネクタに最適なパーシング戦略を自動的に決定します。追加の設定は不要です。
Smart Parsing は、次の複数の手法を組み合わせています:
- コネクタ固有のデータモデル – 各データソースのために最適化された処理。例えば、Web Crawler コネクタは、埋め込み画像やテーブルを含む HTML 構造を保持し、取り込み中にリッチコンテンツが失われないようにします。SharePoint コネクタは、ドキュメントの階層とファイル間の関係を維持します。
- マルチモーダル処理 – ドキュメント内のさまざまなコンテンツタイプの自動検出と処理。システムはドキュメント内のバウンディングボックスを識別し、データ抽出、キャプション生成、動画ファイルのシーン記述のために基盤モデルに送信します。
- 最適化されたチャンキング – Smart Parsing は、基盤モデルを活用してドキュメント構造を理解し、意味のあるコンテンツを抽出します。これにより、複数のフォーマットが混在する複雑なドキュメントも適切にインデックス化されます。インテリジェントなデフォルト設定はドキュメントのタイプとコンテンツ構造に基づいて検索の精度とパフォーマンスのバランスを取り、上級ユーザーは必要に応じてチャンキング戦略をカスタマイズできます。
この自動化されたアプローチにより、通常、本番レベルの質の検索精度を実現するために必要となる数週間に及ぶ実験が不要になり、必要に応じてカスタマイズできる柔軟性も維持されます。
複雑なクエリでの Agentic Retriever の使用
データの取り込みが完了したら、ナレッジベースへのクエリを開始できます。生成 AI アプリケーションは、推論、再帰的な複数ステップの検索、および結果の中間評価を必要とする複雑なユーザークエリの処理に苦慮することがよくあります。ユーザーが「ML プラットフォームチームのクラウドインフラストラクチャ予算はどうなっていますか?」と「当社の経費ポリシーでは、年間契約の事前払いは認められていますか?」という 2 つの関連する質問をする場合を考えてみましょう。 単一の検索ステップでは、ML プラットフォームチームに関するドキュメントは見つかるかもしれませんが、質問に完全に答えるために必要な予算に関する情報と経費ポリシーを結びつけることができない場合があります。
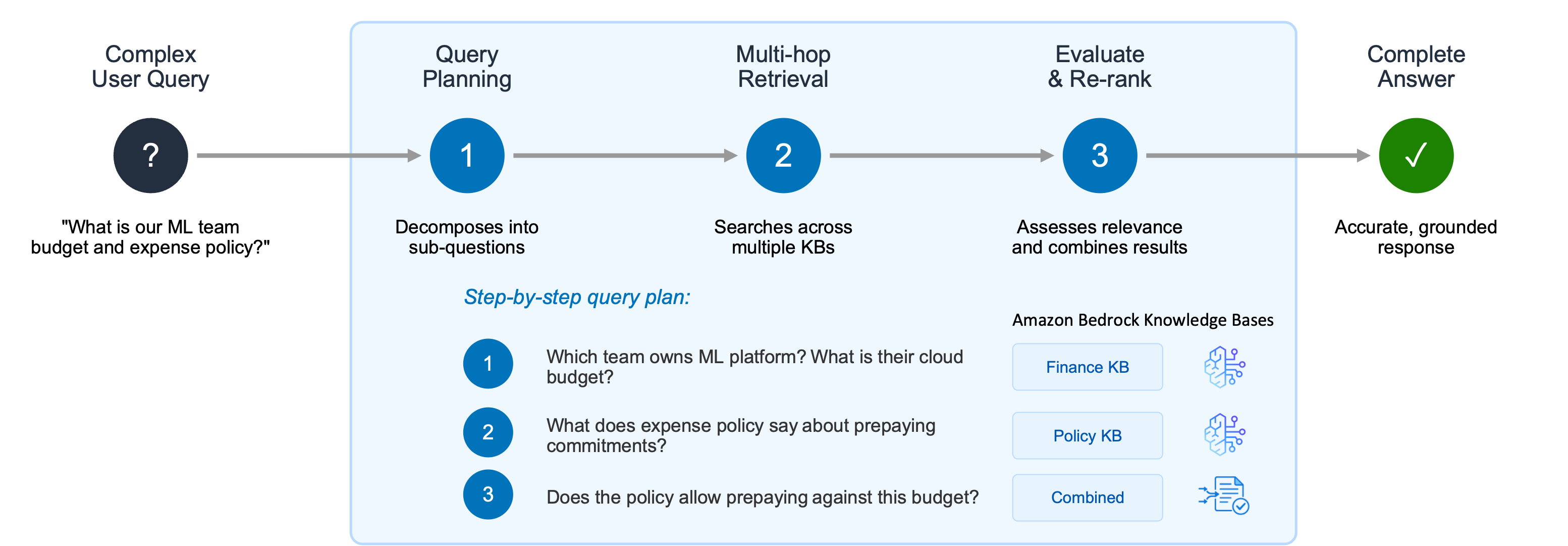
図 3 – Agentic Retriever は、複雑なユーザークエリをステップバイステップのプランに分解し、複数のナレッジベースでマルチホップ検索を実行して結果を組み合わせ、根拠がある正確な応答を提供します
Agentic Retriever は、ステップバイステップのクエリプランを作成することでこれを解決します: 1.どのチームが ML プラットフォームを所有しているか? また、そのチームのクラウドインフラストラクチャの予算はどうなっているか? 2.年間契約の事前払いに関する経費ポリシーはどうなっているか? 3.ML プラットフォームチームがこの予算から事前払いすることはポリシーで認められているか?
システムは各ステップでマルチホップ検索と推論を実行し、十分な関連パッセージが収集されたら検索プロセスを停止して、上位の結果を返します。このアプローチは、個別のマルチホップ推論パイプラインを構築する複雑さを抽象化することで、複雑なクエリの精度を劇的に高めつつ、デベロッパーがオーケストレーションロジックではなく、エージェンティック検索アプリケーションに注力できるようにします。
Amazon Bedrock AgentCore コンソールのナレッジベースのテストパネルから、Agentic Retriever を直接お試しいただけます。ナレッジベース全体にわたる複数ステップのクエリをシステムが自動的に計画および実行できるようにするには、検索タイプとして [エージェンティック検索のみ] を選択します:
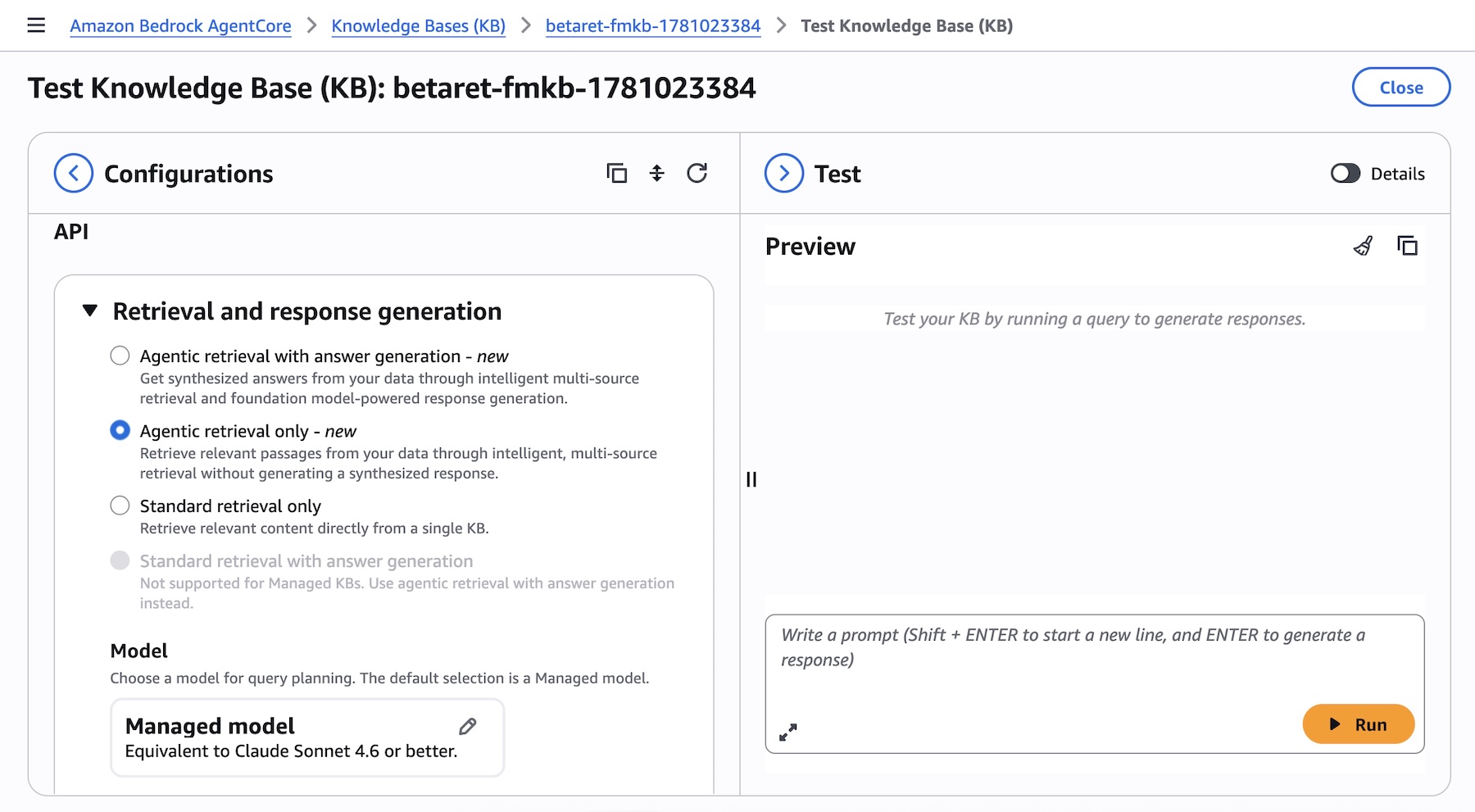
図 4 – [ナレッジベースをテスト] パネル。検索タイプとして [エージェンティック検索 (回答生成あり)] が選択されており、モデルの選択、および最大エージェンティックイテレーションオプションが表示されています
Bedrock AgentCore で MCP を有効にする
Amazon Bedrock マネージドナレッジベースは、ネイティブターゲットタイプとして AgentCore Gateway とシームレスに統合します。この統合により、手動での統合が不要になり、組み込みのオブザーバビリティ、ポリシーの強制適用、および自動許可管理が提供されます。
Amazon Bedrock AgentCore コンソールまたは SDK に移動して、AgentCore Gateway を作成したり、既存のゲートウェイを選択したりできます。ゲートウェイにターゲットを追加する際、MCP サーバー、Lambda ARN、REST API、および他の統合オプションとともに、新しい事前構築済みターゲットタイプとして [ナレッジベース] が表示されます。ゲートウェイを通じて公開するために必要なのは、ナレッジベース ID を選択することだけです:
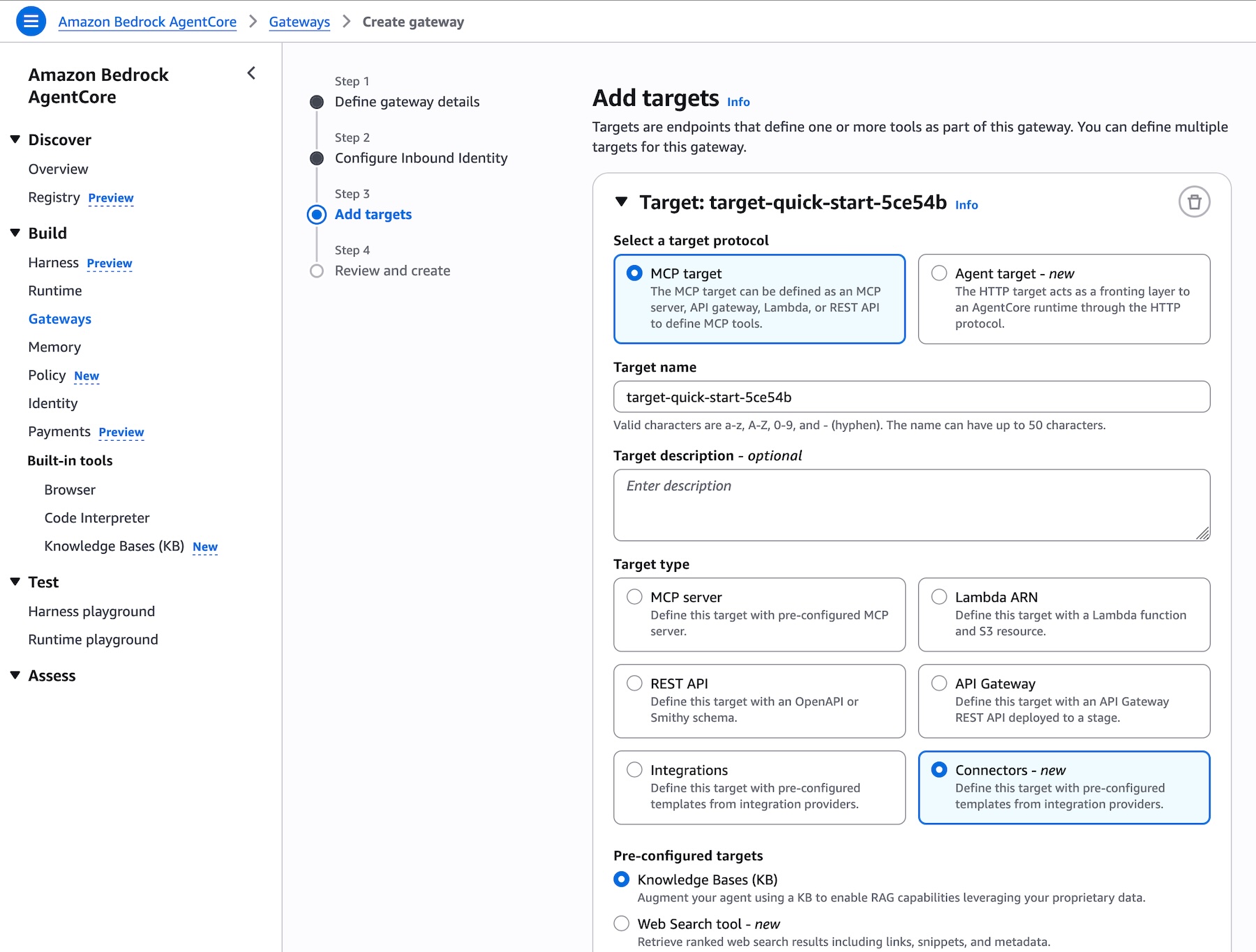
図 5 – AgentCore Gateway の [ターゲットを追加] ページ。ナレッジベース ID セレクタとランタイム検索モードオプションを備えた、新しい事前構築済みターゲットタイプとしてナレッジベースが表示されています
AgentCore Gateway の [ターゲットを追加] ページ。ナレッジベース ID セレクタとランタイム検索モードオプションを備えた、新しい事前構築済みターゲットタイプとしてナレッジベースが表示されています
ゲートウェイは標準のモデルコンテキストプロトコル (MCP) を公開するため、ナレッジベースツールは、Strands Agents、LangChain、CrewAI、LlamaIndex、LangGraph など、MCP 互換フレームワークのクライアントによって自動的に検出されます。カスタム統合コードは不要です。
モデルの選択と柔軟性
Amazon Bedrock マネージドナレッジベースは、デベロッパーが Amazon Bedrock に期待する柔軟性を維持します。Bedrock で使用可能なすべての基盤モデルは生成ステップで使用でき、デベロッパーはさまざまな埋め込みモデルと再ランキングモデルから選択して、特定のユースケースに合わせて検索を最適化できます。これにより、チームはインフラストラクチャを変更することなく、精度とコストパフォーマンスをファインチューニングできます。
特定のモデルプロバイダーにロックインされるマネージドソリューションとは異なり、Amazon Bedrock マネージドナレッジベースは、インフラストラクチャ管理 (コネクタ、解析、ストレージ、検索オーケストレーション) とモデル選択を分離します。これは、次が可能であることを意味します:
- 最新モデルを活用する – 最新の埋め込みモデル、再ランキングモデル、基盤モデルが利用可能になり次第、それらを採用することで、RAG パイプラインを再構築することなく、アプリケーションの精度、レイテンシー、コストを改善できます。
- 料金パフォーマンスを最適化する – 同じナレッジベースインフラストラクチャを使用して、シンプルなクエリにはより小型で高速なモデルを、複雑な推論タスクにはより高性能なモデルを選択できます。
- Bedrock 埋め込みモデルを使用する – Smart Parsing は最適化されたデフォルト設定を提供しますが、ドメインで特殊な意味論的理解が必要な場合は、Bedrock 埋め込みモデルを設定できます。
- 既存アプリケーションとの一貫性を維持する – Bedrock ナレッジベース API (
Retrieve、StartIngest、StopIngest、IngestKnowledgeBaseDocuments) を既に使用している場合、マネージドナレッジベースは同じ API を使用するため、移行にはコードの変更は不要で、新しいナレッジベース ID をポイントするだけで済みます。
このアプローチにより、進化する要件や新しいモデル機能に基づいてモデルを変更する能力を失うことなく、生成 AI アプリケーションに時間を割けます。
今すぐ始めましょう
Amazon Bedrock マネージドナレッジベースは、米国東部 (バージニア北部)、米国西部 (オレゴン)、アジアパシフィック (シドニー、東京)、欧州 (ダブリン、フランクフルト、ロンドン)、および AWS GovCloud (米国西部) リージョンで現在利用可能です。リージョンごとの提供状況や今後のロードマップについては、「AWS Capabilities by Region」にアクセスしてください。
Bedrock マネージドナレッジベースでは前払いの義務はなく、お支払いいただくのは使用した分の料金のみです。料金は、保存されるインデックス付きデータのサイズと、実行される検索回数 (オンデマンド) の 2 つの要素に基づきます。料金の詳細については、Amazon Bedrock の料金ページにアクセスしてください。また、Bedrock は AWS 無料利用枠の一部でもあり、AWS の新規のお客様は無料で利用を開始し、主要な AWS サービスを試すことができます。
これらの機能は、CreWAI、LangGraph、LlamaIndex、Strands Agents などのあらゆるオープンソースフレームワークと、あらゆる基盤モデルで動作します。Bedrock サービスは一緒に使用することも、単独で使用することもできます。AgentCore オープンソース MCP サーバーを使用して、お気に入りの AI 支援開発環境の使用を開始できます。
詳細を確認し、すぐに使用を開始するには、「Bedrock ナレッジベースデベロッパーガイド」にアクセスしてください。
Daniel Abib
原文はこちらです。