Amazon Web Services ブログ
プレビューに参加 — AWS Glue Data Quality
私は、かつて 1980 年に、2 つ目の専門的なプログラミングの仕事で、米国のさまざまな州の運転免許証データを分析するプロジェクトに取り組んでいました。当時、この種のデータは通常、値が各フィールドに注意深くエンコードされた (またはエンコードされていない) 固定長のレコードに格納されていました。データのスキーマは提供されましたが、デベロッパーは事前に予想されていなかった値を表現するためにトリックに頼らざるを得ないことが必然的に明らかになりました。例えば、左右の目が異なる色をしている異色症の人のためのコーディングです。既知のデータを扱っていることを確認するために、実際に時間と費用のかかる分析を実行する前に、データのフルスキャンを行うことになりました。これがデータ品質、あるいはその欠如についての手ほどきでした。
AWS では、あらゆる規模のデータレイクとデータウェアハウスを簡単に構築できます。私たちは、取り込み、処理、そして共有するデータの望ましい品質レベルをこれまで以上に簡単に測定し維持できるようにしたいと考えています。
AWS Glue Data Quality のご紹介
本日は、AWS Glue の新しい機能セットで、プレビュー形式でリリースしている AWS Glue Data Quality についてお伝えします。これは、テーブルを分析し、見つかった内容に基づいて自動的にルールセットを推奨します。必要に応じてこれらのルールを微調整したり、独自のルールを作成したりすることもできます。このブログ記事では、いくつかの注目点を紹介し、これらの機能がプレビュー版から一般公開版に移行した場合は、完全な記事の詳細を確保しておきます。
各データ品質ルールは Glue テーブルまたは Glue テーブルで選択された列を参照し、特定のタイプのプロパティ (適時性、正確性、整合性など) をチェックします。例えば、ルールによって、テーブルには必要な数の列が必要であり、列名は必要なパターンと一致していなければならず、特定の列をプライマリキーとして使用できることが示されます。
開始方法
Glue テーブルの 1 つで新しい Data quality (データ品質) タブを開いて開始できます。そこからルールセットを手動で作成することも、Recommend ruleset (推奨ルールセット) をクリックして開始することもできます。
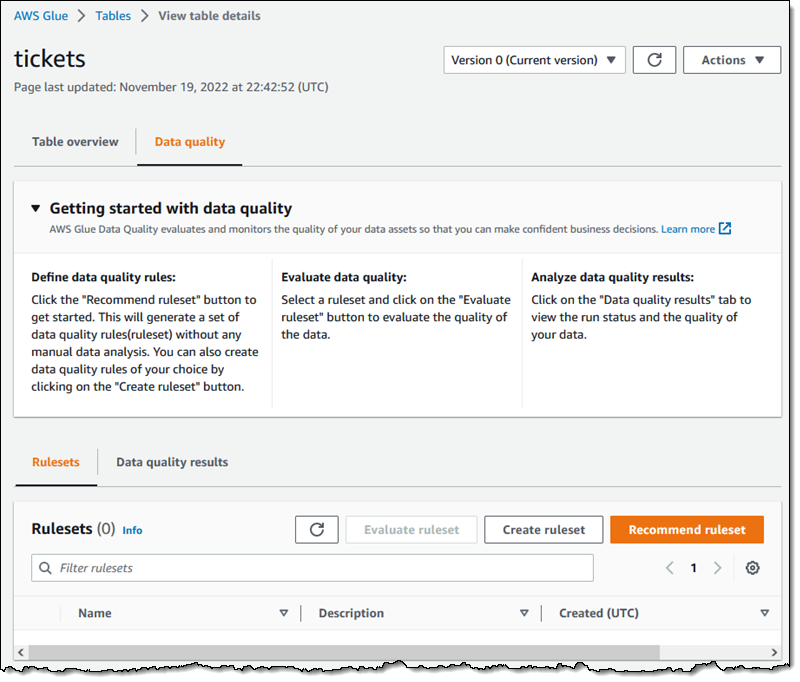
次に、ルールセット (RS1) の名前を入力し、そのルールセットへのアクセス許可を持つ IAM ロールを選択して、Recommend ruleset (推奨ルールセット) をクリックします。
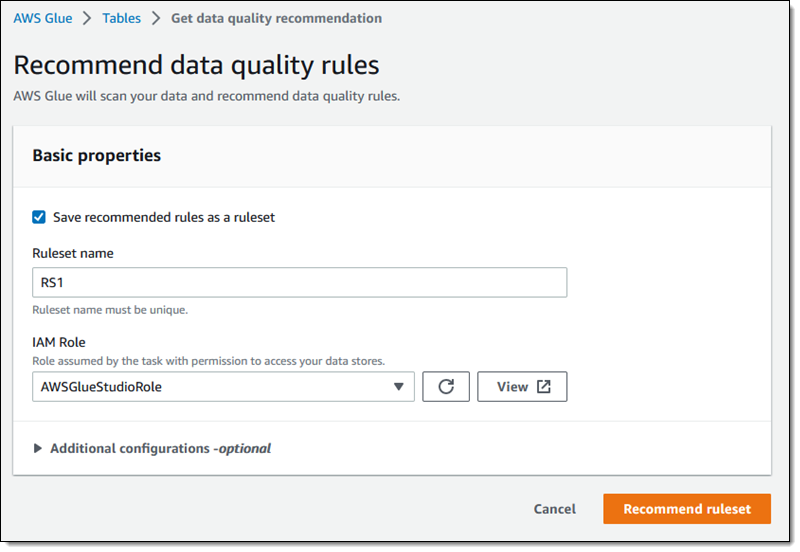
クリックすると、データをスキャンしてレコメンデーションを行う Glue Recommendation タスク(特殊なタイプの Glue ジョブ)が開始されます。タスクが完了したら、レコメンデーションを確認できます。

Evaluate ruleset (ルールセットを評価) をクリックしてデータの品質を確認します。
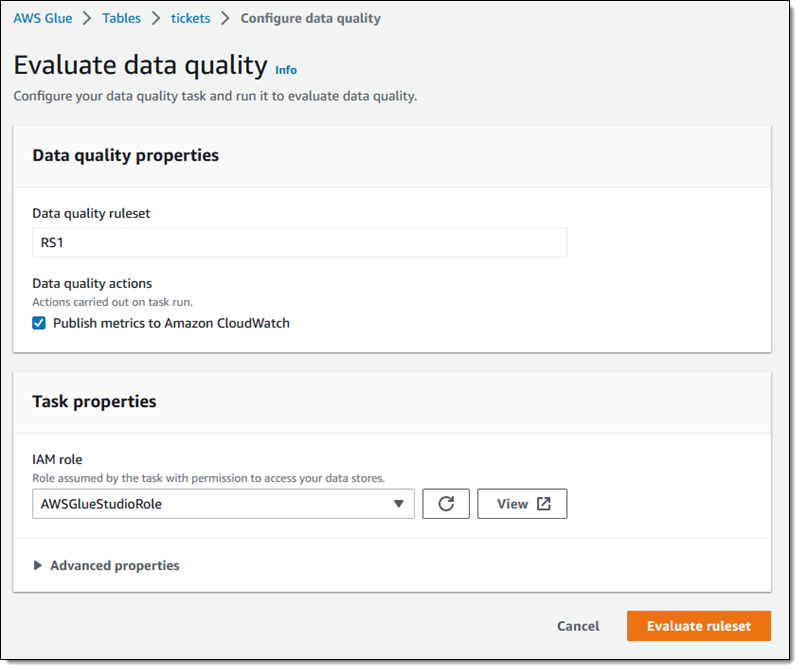
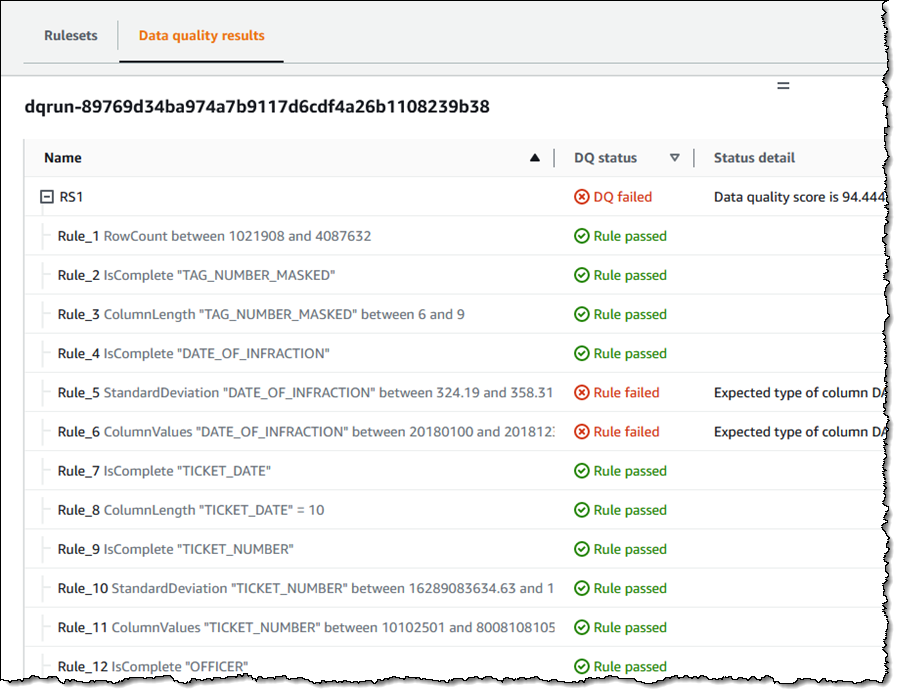
データ品質タスクが実行され、結果を確認できます。
テーブルにアタッチするルールセットを作成するだけでなく、Glue ジョブの一部としても使用できます。通常どおりジョブを作成してから、データ品質評価ノードを追加します。

次に、データ品質定義言語 (DDQL) ビルダーを使用してルールを作成します。20 種類のルールタイプから選択できます。

このブログ記事では、これらのルールを必要以上に厳しくして、データ品質評価を満たさなかった場合に何が起こるかをお見せできるようにしました。
ジョブオプションを設定し、変換の出力として元のデータまたはデータ品質結果を選択できます。データ品質の結果を S3 バケットに書き込むこともできます。

ルールセットを作成したら、ジョブに必要なその他のオプションを設定し、保存してから実行します。ジョブが完了すると、[Data quality] (データ品質) タブに結果が表示されます。いくつか非常に厳しいルールを作成したため、評価ではデータに 0% スコアのフラグが正しく付けられました。

まだまだたくさんありますが、次回のブログ記事のために取っておきます。
知っておくべきこと
プレビューリージョン – これはオープンプレビューであり、現在アクセスできるのは米国東部 (オハイオ、バージニア北部)、米国西部 (オレゴン)、アジアパシフィック (東京)、欧州 (アイルランド) の AWS リージョンです。
料金 – データ品質の評価では、Glue データ処理ユニット(DPU) は、他の Glue ジョブと同じ方法で、同じ DPU 単位の料金で消費されます。
— Jeff;
原文はこちらです。