Amazon Web Services ブログ
Amazon Redshiftクエリーモニタリングルールでクエリーワークロードを管理する
データウェアハウスのワークロードは多様性で知られています。これは、季節性や、往々にして高コストになりがちな探索的クエリー、SQL開発者のスキルレベルのばらつきなどによるものです。
Amazon Redshiftワークロード管理機能(WLM)を用いて優先度やリソース使用量を柔軟に管理することで、極めて多様なワークロード環境でも高い性能を得ることが可能となります。WLMによって、短時間で完了するクエリーが長時間実行されるクエリーのせいでキューに滞留するような状況を避けることができます。にも拘わらず、あるクエリーが不釣り合いな量のリソースを独占し、システム内のその他のクエリーを圧迫することが依然として起こり得ます。こうしたクエリーは、一般にrogue queryやrunaway queryと呼ばれます(訳者註:rogueはならず者、面倒を起こすといった意味、runawayは暴走の意で、ここでは一方的にリソースを占有し他のクエリーに影響を及ぼすクエリーを指します)
WLMは、メモリー使用量を制限し、タイムアウトを用いてクエリーを別のキューに移動させる機能を持ちますが、ずっと粒度の細かいコントロールができることが望ましいことは論を俟ちません。クエリーモニタリングルールを用いて、リソース使用量のルールを作成し、クエリーのリソース使用量を監視し、それらがルールを犯した時のアクションを決めることが可能になりました。
ワークロード管理における同時並列性とクエリーモニタリングルール
Amazon Redshift環境では、単一クラスターに対し最大500まで同時接続することができます。性能指標であるスループットは一般に一時間あたりのクエリー数として表現されますが、MySQLのような行指向データベースであれば、同時接続数を増やすことによってスケールします。Amazon Redshift環境では、ワークロード管理(WLM)によって、同時接続数とは異なる方法でスループットを最大化します。WLMは二つの部分があります。キューと同時並列性です。キューはユーザーグループまたはクエリーグループのレベルでのメモリー割り当てを可能にします。同時並列性(またはメモリースロット)は、この割り当てをさらにどのように分割し、個々のクエリーにメモリーを割り当てるかを制御します。
例えば、同時並列性10の1つのキューがある(メモリー割り当て100%)と仮定しましょう。これは、個々のクエリーは最大10%のメモリーの割り当てを受けることを意味します。もしクエリーの大半が20%メモリーを必要とした場合、これらのクエリーはディスクにスワップアウトし、スループットの劣化をもたらします。しかし、もし同時並列性を5に下げた場合、個々のクエリーは20%のメモリー割り当てを受けることができるため、トータルのスループットは高くなり、SQLクライアントへのレスポンスも全体的に高速になります。高い同時並列性がよりよいパフォーマンスに繋がると考えてしまうことは、行指向のデータベースを列指向に切り替える時に陥りがちな典型的な落とし穴の一つです。
同時並列性について理解したところで、クエリーモニタリングルールについて掘り下げていきましょう。リソース使用量に基づくルールと、それに違反した場合に取るアクションを定義します。当該クエリーによるCPU使用量、クエリー実行時間、スキャンされた行数、返された行数、ネステッドループ(Nested loop)結合など、12の異なるリソース使用量メトリクスを利用できます。
それぞれのルールは最大3つの条件(述語)と、一つのアクションを持ちます。
述語は、メトリック、比較演算子(=、<または>)、値で構成されます。あるルール内の全ての述語がマッチすると、そのルールのアクションがトリガーされます。ルールアクションには、ログ(記録)、ホップ(次のキューへの移動)、アボート(終了)があります。
これにより、はた迷惑なクエリーを、より深刻な問題が出来する前に捕捉することが可能になります。ルールはアクションをトリガーしてキューを解放し、スループットと応答性を改善します。
例えば、短時間実行クエリー専用のキューのために、60秒を超えて実行し続けるクエリーをアボートするルールを作ることができます。設計のよくないクエリーを追跡するために、ネステッドループを含むクエリーを記録する別のルールを作ることもできます。Amazon Redshiftコンソールには、簡単に始められるよういくつかのテンプレートが事前定義されています。
シナリオ
クエリーモニタリングルールを使って、単純なロギングからクエリーのアボートまで、幅広いクエリーレベルアクションを行うことができます。また、全てのアクションはSTL_WLM_RULE_ACTIONテーブルに記録されます。
- ログ(LOG)アクションは、情報を記録した上でクエリーの監視を継続します。
- ホップ(HOP)アクションは、クエリーを中断し、次に合致するキューで再起動します。
もし合致するキューがない場合、当該クエリーはキャンセルされます。 - アボート(ABORT)アクションは、ルールに違反したクエリーをアボートさせます。
それでは、以下の三つのシナリオを用いて、クエリーモニタリングルールをどのように使うかを見ていきましょう。
シナリオ1:アドホッククエリーに潜む非効率なクエリーを制御するには?
二つの大きなテーブルを結合するようなクエリーは、何十億、あるいはそれ以上の行を返す可能性があります。十億行を超える行を返すクエリーをアボートさせるルールを設定することで、アドホッククエリーの安全性を担保することができます。このルールは、論理的には以下のようになります。
IF return_row_count > 1B rows then ABORT
以下のスクリーンショットの設定では、十億行を超える行を返すBI_USERグループ内のクエリーはすべてアボートします。

シナリオ 2: 非効率で、CPUインテンシブなクエリーを制御するには?
CPUスパイクをもたらすクエリーが、必ずしも問題というわけではありません。しかし、高いCPU使用量と長いクエリー実行時間を併せ持ったクエリーは、実行中の他のクエリーのレイテンシーを悪化させます。例えば、高いCPU使用率を示し続ける非効率なクエリーが長時間実行されている場合、それは誤ったネステッドループ結合のせいかも知れません。
こうしたケースでは、10分間にわたって80%以上のCPU使用率を示しているクエリーをアボートさせるルールを作成することで、クラスターのスループットと応答性を上げることができます。このルールは、論理的には以下のようになります。
IF cpu_usage > 80% AND query_exec_time > 10m then ABORT
以下のスクリーンショットの設定では、10分間にわたってCPU使用率が80%を超えているクエリーはすべてアボートします。

80%以上のCPU使用率を5分以上続けるクエリーを記録し、10分以上続いた場合はアボートするよう、ルールを拡張することもできます。このルールは、論理的には以下のようになります。
IF cpu_usage > 80% AND query_exec_time > 5m then LOG and IF cpu_usage > 80% AND query_exec_time > 10m then ABORT
以下のスクリーンショットの設定では、5分間にわたってCPU使用率が80%を超えているクエリーは記録され、10分間にわたってCPU使用率が80%を超えているクエリーはすべてアボートします。

シナリオ 3:
進捗していないクエリーを監視し、記録するには?
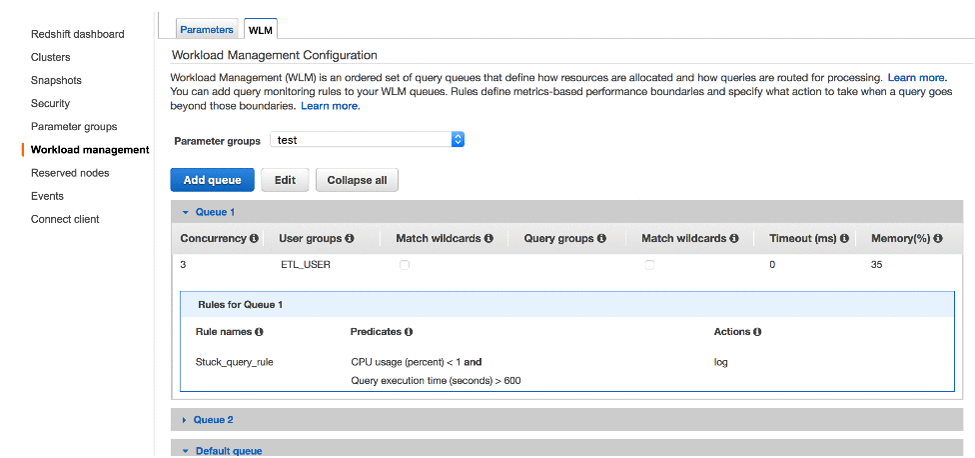
例えば、ミックスワークロード環境では、ETLジョブがS3から大量のデータを抽出し、Amazon Redshiftにロードしているケースがあります。データ抽出中、キューでスタックして、全く進捗していないように見えるCOPYコマンドが見つかるかも知れません。このようなクエリーはデータ抽出を遅延させ、ビジネス上のSLAに悪影響を与える可能性もあります。
クエリーを追跡し記録するルールを作ることで、こうしたクエリーを捕捉することができます。低いCPU使用率のまま長時間実行されているクエリーを見つけ出すルール、例えば1%のCPU使用率で10分間動作しているようなクエリーを記録するルールを作成します。このルールは、論理的には以下のようになります。
IF cpu_usage < 1% AND query_exec_time > 10m then LOG
以下のスクリーンショットの設定では、10分間にわたってCPU使用率が1%未満であるクエリーが記録されます。
まとめ
Amazon Redshiftは強力かつフルマネージドなデータウェアハウスであり、高いパフォーマンスと低いコストの双方をクラウド上でご提供します。しかしながら、クラスターリソースを独り占めするクエリー(rogue queries)はユーザーエクスペリエンスに悪影響を及ぼします。
このポストでは、クエリーモニタリングルールがこの種のクエリーにどのように対処可能かを見てきました。これらの内容は、ミックスワークロード環境でのクラスター性能とスループットを最大化し、円滑なビジネス遂行を実現する上で役立つはずです。
ご質問やご提案がありましたら、以下にコメントを残していただけますと幸いです。
(翻訳はAWS Japanプロフェッショナルサービス仲谷が担当しました。原文はこちら)