AWS Big Data Blog
Introducing the Data Lake Solution on AWS
NOTE: The solution in this post is in the process of being updated. For the most current information, please visit the What is a data lake? page.
This blog post has been translated into Japanese.
Many of our customers choose to build their data lake on AWS. They find the flexible, pay-as-you-go, cloud model is ideal when dealing with vast amounts of heterogeneous data. While some customers choose to build their own lake, many others are supported by a wide range of partner products.
Today, we are pleased to announce another choice for customers wanting to build their data lake on AWS: the data lake solution. The solution is provided as an AWS CloudFormation script that you can use out-of-the-box, or as a reference implementation that can be customized to meet your unique data management, search, and processing needs.
In this post, I introduce you to the solution and show you why a data lake on AWS can increase the flexibility and agility of your analytics.

Data lake overview
The concepts behind a data lake seem simple: securely store all your data in a raw format and apply a schema on read. Indeed, the first description of a data lake compared it to a ‘large body of water in a more natural state’, whereas a data mart could be thought of as a ‘store of bottled water – cleansed and packaged and structured for easy consumption’.
A data lake is a bet against the future – you don’t know what analysis you might want to do, so why not just keep everything to give the best chance you can satisfy any requirement that comes along?
If you spend some time reading about data lakes, you quickly unearth another term: the data swamp. Some organisations find their lakes are filled with unregulated and unknown content. Preventing a data swamp might seem impossible―how do you collect every bit of data that your company generates and keep it organized? How will you ever find it again? How do you keep your data lake clean?
At Amazon, we use a working backwards process when developing our products and services. You start with your customer and work your way backwards until you get to the minimum product that satisfies what they are trying to achieve. Applying this process when you build your data lake is one way to focus your efforts on building a lake rather than a swamp.
When you build a data lake, your main customers are the business users that consume data and use it for analysis. The most important things your customers are trying to achieve are agility and innovation. You made a bet when you decided to store data in your lake, your customers are looking to quickly cash this in when they start their new project.
After your data lake is mature, it will undoubtedly feed several data marts such as reporting systems or enterprise data warehouses. Using the data lake as a source for specific business systems is a recognized best practice. However, if that is all you needed to do, you wouldn’t need a data lake.
Having a data lake comes into its own when you need to implement change; either adapting an existing system or building a new one. These projects build on an opportunity for a competitive advantage and need to run as quickly as possible. Your data lake customers need to be agile. They want their projects to either quickly succeed or fail fast and cheaply.
The data lake solution on AWS has been designed to solve these problems by managing metadata alongside the data. You can use this to provide a rich description of the data you are storing. A data lake stores raw data, so the quality of the data you store will not always be perfect (if you take steps to improve the quality of your data, you are no longer storing raw data). However, if you use metadata to give visibility of where your data came from, its linage, and its imperfections, you will have an organized data lake that your customers can use to quickly find data they need for their projects.
Data lake concepts
The central concept of this data lake solution is a package. This is a container in which you can store one or more files. You can also tag the package with metadata so you can easily find it again.

For example, the data you need to store may come from a vast network of weather stations. Perhaps each station sends several files containing sensor readings every 5 minutes. In this case, you would build a package each time a weather station sends data. The package would contain all the sensor reading files and would be tagged with metadata, for example the location of each station, and the date and time on which the readings were taken. You can configure the data lake solution to require that all packages have certain metadata tags. This helps ensure that you maintain visibility on the data added to your lake.
Installing and configuring the data lake
You can follow the instructions in the installation guide to install the data lake in your own AWS account by running a CloudFormation script. A high-level view of the server-side architecture that is built is shown below:
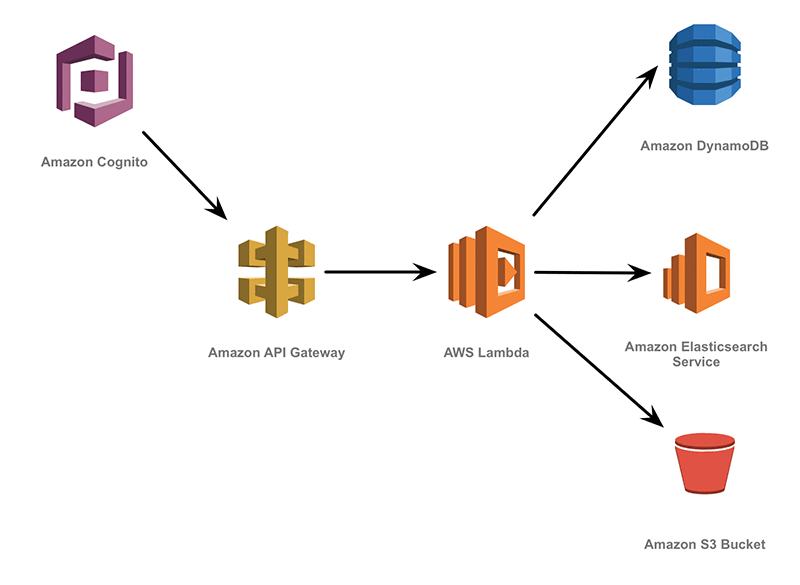
The architecture is serverless; you don’t need to manage any Amazon EC2 instances. All the data is stored in managed AWS services and the processing is implemented by a microservices layer written using AWS Lambda.
When you install the Data Lake Solution, you set yourself up as an administrator by providing your name and email address to the CloudFormation script. During the installation, an AWS Cognito User Pool is created. Your details are added to the pool and you’re sent an activation email. There’s also a link in the email to take you to your data lake web console. The data lake console was also installed into your account by the CloudFormation template; it is hosted as a static website in an Amazon S3 bucket.
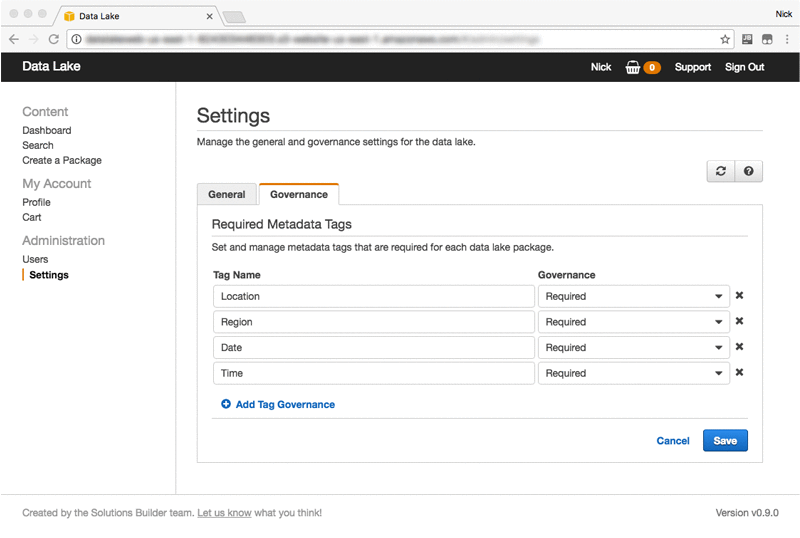
After you’ve logged in to the data lake console as the administrator, your first task is to configure the governance that you’ll enforce on packages. By choosing Settings on the left and then the Governance tab, you can configure the minimum set of metadata tags that must be applied to all new packages.
In the diagram below, you can see the data lake configured to capture the example weather data. All packages must be tagged with the location, region, and date and time. When users create packages, they can always add their own extra tags to provide more context. You can also specify that tags are optional if you want to enforce conformity over the use of metadata that isn’t always present:
As an administrator, you can also create data lake accounts for other people at your organisation. Choose users on the left side to create extra administrators or user accounts. Users can’t change governance settings or create other user accounts.
After you’ve configured your data lake, you are ready to create your first package. You can do this by choosing Create a Package on the left side and filling in the fields:
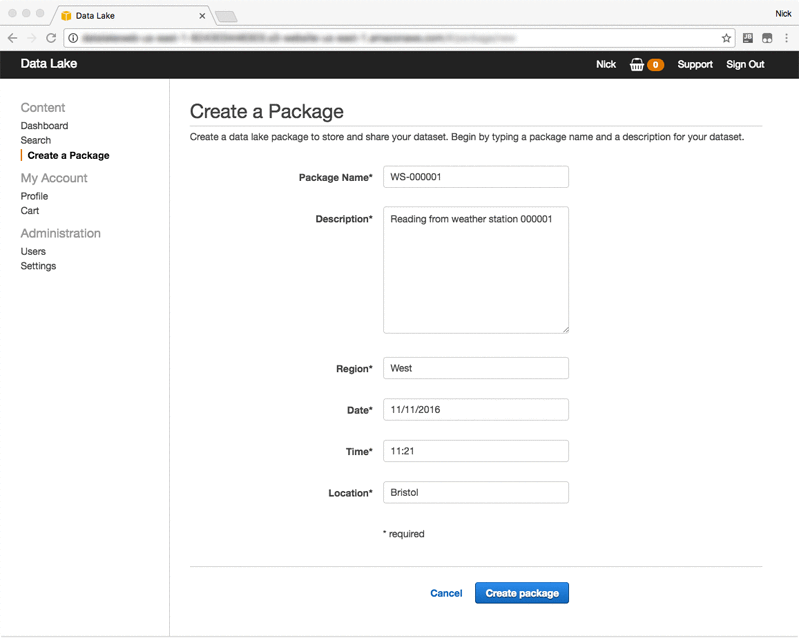
You can see that the metadata tags specified in the governance settings are now required before you can create the package. After it has been created, you can add files to the package to build its contents. You can either upload files that are on your local machine or link to files that are already stored on S3:

In practice, if you are creating lots of packages, you wouldn’t want to create each one using the console. Instead, you can create packages using the data lake Command Line Interface (CLI) or directly against the REST API that is implemented using Amazon API Gateway.
Storing data
When you create a package, the data is stored in S3 and the metadata is stored in both Amazon DynamoDB and Amazon OpenSearch Service. Storing data in S3 has many advantages; you can securely store your data in any format, it is durable and highly scalable, and you pay only for the storage that you actually use. Having your data in S3 also provides integration with other services. For example, you can use your data in an Amazon EMR cluster, load it into an Amazon Redshift data warehouse, visualize it in Amazon QuickSight, or build a machine learning model with Amazon Machine Learning.
Leveraging the S3 integration with other tools is key to establishing an agile analytics environment. When a project comes along, you can provision data into the system that’s most suitable for the task in hand and the skills of the business users. For example, a user with SQL skills may want to analyze their data in Amazon Redshift or load it into Amazon Aurora from S3. Alternatively, a data scientist may want to analyze the data using R.
Processing data
Separating storage from processing can also help to reduce the cost of your data lake. Until you choose to analyze your data, you need to pay only for S3 storage. This model also makes it easier to attribute costs to individual projects. With the correct tagging policy in place, you can allocate the costs to each of your analytical projects based on the infrastructure that they consume. In turn, this makes it easy to work out which projects provide most value to your organization.
The data lake stores metadata in both DynamoDB and Amazon ES. DynamoDB is used as the system of record. Each change of metadata that you make is saved, so you have a complete audit trail of how your package has changed over time. You can see this on the data lake console by choosing History in the package view:
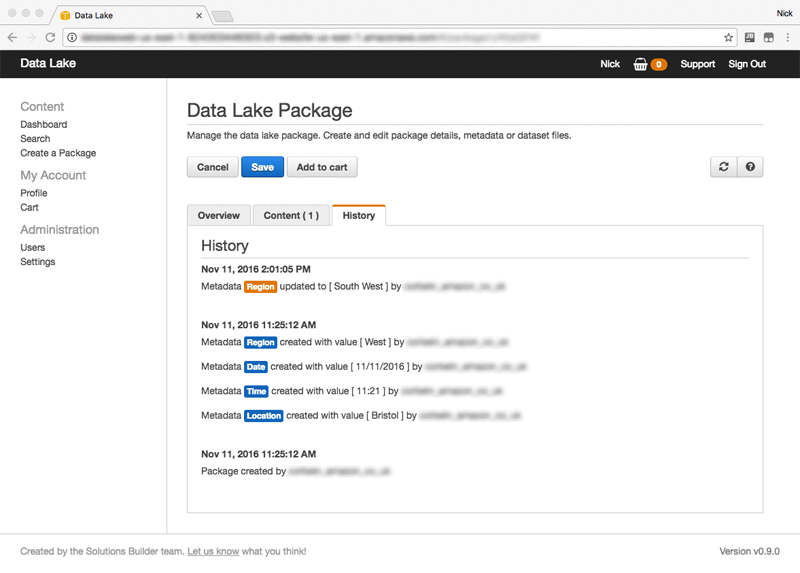
The latest version of a package’s metadata is also written to Amazon ES and is used to power the search, allowing you to quickly find data based on metadata tags. For example, you may need to find all the packages created for weather stations in the Southwest on November 11, 2016:
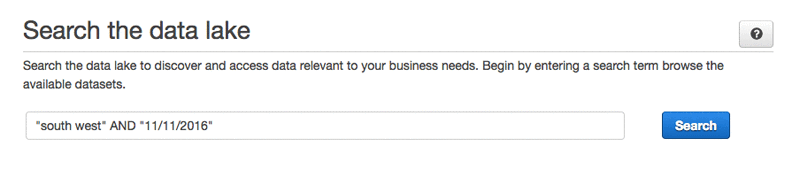
After you’ve found a package that you are interested in, you use the data lake solution like a shopping website and add it to your cart. Choosing Cart on the left shows its contents:
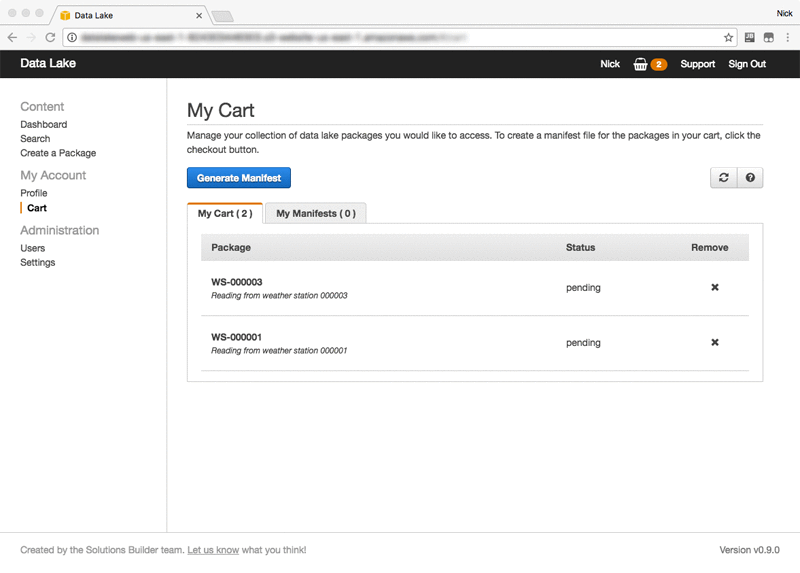
When you are happy with the contents of your cart, you can choose Generate Manifest to get access to the data in the packages. This creates a manifest file that contains either presigned URLs or the S3 bucket and key for each object. The presigned URL allows you to download a copy of the data.
However, creating a copy isn’t always the most efficient way forward. As an alternative, you can ask for the bucket and key where the object is stored in S3. It’s important to remember that you need access to an IAM user or role that has permissions to get data from this location. Like the package creation process, you can use the CLI or API to search for packages, add them to your cart, and generate a manifest file, allowing you to fully automate the retrieval of data from the lake.
Summary
A successful data lake strikes a balance. Although a data lake makes it easy to contribute data and build a vast organisational archive, it never loses control over the information that’s ingested. Ultimately, the lake is built to serve its customers, the business users that need to get to relevant data quickly so that they can execute projects for maximum return on investment (ROI).
By equally managing both data and metadata, the data lake solution on AWS allows you to govern the contents of your data lake. By using Amazon S3, your data is kept in secure, durable, and low-cost storage. S3 integrates with a wealth of other AWS services and third-party tools so that data lake customers can provision the right tool for their tasks.
The data lake solution is available for you to start using today. We welcome the feedback on this new solution and you can join in the discussion by leaving a comment below or visiting the AWS Solutions Forum.
About the author
 Nick Corbett is a Senior Consultant for AWS Professional Services. He works with our customers to provide leadership on big data projects, helping them shorten their time to value when using AWS. In his spare time, he follows the Jürgen Klopp revolution.
Nick Corbett is a Senior Consultant for AWS Professional Services. He works with our customers to provide leadership on big data projects, helping them shorten their time to value when using AWS. In his spare time, he follows the Jürgen Klopp revolution.