Amazon Web Services ブログ
Amazon EKS でコントロールプレーンイベントを管理する
この記事は Managing Kubernetes control plane events in Amazon EKS (記事公開日 : 2022 年 8 月 15 日) の翻訳です。
導入
Amazon Elastic Kubernetes Service (Amazon EKS) は、お客様がコンテナベースのワークロードを AWS クラウドに移行するサポートをします。Amazon EKS は Kubernetes コントロールプレーンを管理するため、etcd や API サーバーなどの Kubernetes コンポーネントのスケーリングやメンテナンスを気にする必要はありません。宣言型かつ reconciliation loop を実現するシステムとして、Kubernetes は Pod、Deployment、Namespace の作成や削除などの様々なイベントを発行し、クラスター内のアクティビティをユーザーに通知します。Amazon EKS は、イベントの TTL (time to live) を Kubernetes のアップストリームのデフォルトである 60 分とし、変更できないようにしています。このデフォルト設定は、etcd データベースが満杯になり API サーバーのパフォーマンス低下を引き起こすリスクを回避しつつ、即座にトラブルシューティングするための十分な履歴を保持するための良いバランスであると言えます。
分散管理システムにおいて、イベントは多くの有用な情報をもたらします。コンテナオーケストレーションの世界、特に Kubernetes において、イベントは、Pod、Namespace、またはコンテナの内部で起こっていることについて、有用な情報を提供するオブジェクトです。そのため、Kubernetes のイベント履歴をデフォルトの 60 分を超えて保持することが有益なユースケースも存在します。また、すべてのタイプの Kubernetes リソースのイベントが長期間必要とされるとは限りません。この記事では、Kubernetes イベントをフィルタリングしつつ (Pod イベントのみ、Node イベントのみなど)、Amazon CloudWatch にエクスポートして永続化する方法について説明します。読者はこの例を参考にし、要件に応じて変更することが可能です。
ソリューション概要
前述のとおり、Amazon EKS のイベント TTL は、アップストリームのデフォルトである 60 分に設定されています。一部のお客様は、デバッグのためにより長期間の履歴を保持するために、この値を増やすことに関心を示しています。しかし、EKS では、イベントは etcd データベースを満杯にし、安定性とパフォーマンスの問題を引き起こす可能性があるため、この値の変更を許可していません。etcd は、60 分後にはイベントを削除します。この記事では、一例として Amazon CloudWatch を保存先とし、イベントを 60 分間以上保持するためのソリューションを紹介します。また、CloudWatch に保存されたイベントを調査するユースケースの例も取り上げます。
前提条件
このウォークスルーを完了するには、以下が必要です。
- AWS アカウント
- AWS CLI バージョン 2
- eksctl
- kubectl
- Helm
- Docker の知識
- Kubernetes の基本的な知識 (Pod、イベント、Namespace、Deployment)
ウォークスルー
Amazon EKS クラスターを作成する
それでは、環境変数を設定することから始めましょう。
eksctl を使用して、クラスターを作成します。
クラスターの作成には、最大で 10 分かかります。クラスターの作成が完了したら、次のステップに進みます。
コントロールプレーンのイベントを管理する
Amazon EKS クラスターが準備できたら、コントロールプレーンイベントを管理しましょう。前セクションで説明したように、この記事では、Amazon EKS でコントロールプレーンイベントを管理する例をいくつか紹介します。そのために、Kubernetes の Deployment を作成し、その Deployment 内の Pod が Amazon EKS コントロールプレーンのアクティビティを追跡し、CloudWatch にイベントを永続化します。ソースコードは公開されているため、必要に応じて適宜修正して利用できます (Python ベースのコントロールプレーンイベントアプリケーションの修正、イベントタイプの変更など)。ソースコードと依存関係は、Dockerfile を使用してコンテナ化します。出来上がったコンテナイメージは、リポジトリ (ここでは Amazon Elastic Container Registry (Amazon ECR) Public) にプッシュします。この記事では、Amazon ECR Public にあるコンテナイメージを Kubernetes クラスターにデプロイします。しかし、前述のように、このソリューションは、必要に応じて関心のあるイベントを選択するようにカスタマイズできます。
ソリューション概要の構成を以下に示します。
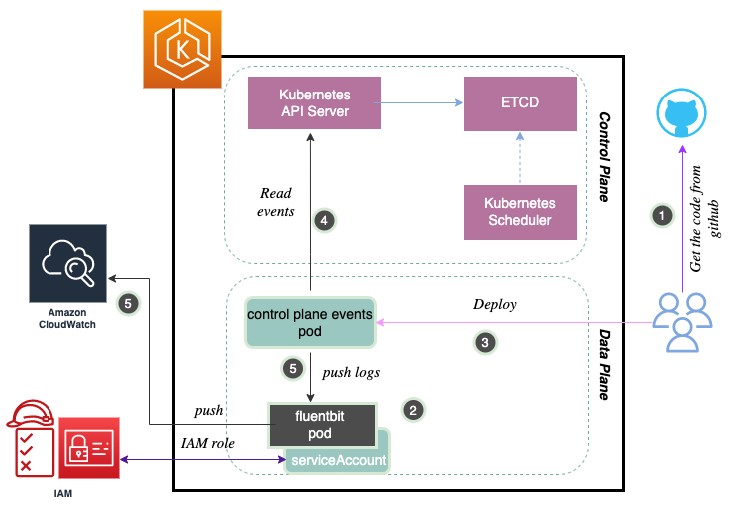 上図に示した、必要な一連の手順は以下の通りです。
上図に示した、必要な一連の手順は以下の通りです。
- GitHub からソースコードを取得します。
- データプレーンから取得したコントロールプレーンイベントを自動的に CloudWatch (訳注 : より正確には CloudWatch Logs) にプッシュするように、Fluent Bit を用いて Container Insights を設定します 。Fluent Bit は軽量でスケーラブルなログアグリゲーター兼プロセッサーであり、コンテナログを CloudWatch にプッシュするサポートをします。CloudWatch Container Insights では、コンテナログを探索、分析、可視化できます。
- 提供された Helm チャートを使用して、Amazon ECR Public リポジトリにあるコンテナイメージを用いたコントロールプレーンイベントアプリケーションを Kubernetes/Amazon EKS クラスターにデプロイします。この際、必要な ClusterRole、ClusterRoleBinding、Deployment が作成されます。
- Amazon EKS クラスターに対する操作を実行します。デプロイされたコントロールプレーンイベント Pod は、Amazon EKS コントロールプレーンからのイベントを取得します。
- デプロイされたコントロールプレーンイベント Pod は、Container Insights を使用してログを CloudWatch にプッシュします。
それでは、順に見ていきましょう。
ステップ 1 : GitHub からソースコードを取得する。
すべてのソースコードは GitHub リポジトリで取得可能です。
ソースコード内で説明されているように、Kubernetes API サーバーに接続し、イベントを監視します。イベントには、Pod、Namespace、Node、Service、および PersistentVolumeClaim のイベントが含まれます。Python スクリプトはイベント結果を出力し、最終的に Container Insights (後述) を用いて CloudWatch にプッシュします。Python スクリプトを必要に応じて変更したい場合は、GitHub リポジトリの Readme ファイルに説明されているように、(訳注 : すでに公開されているコンテナイメージを利用するのではなく) ご自身で Dockerfile を用いてコンテナ化できます。このソリューションには、関心のあるイベントを選択してカスタマイズする柔軟性があります。
このアプリケーションでは、内部でどのようにイベントを捉えているのでしょうか。
event_watcher の Python スクリプトから分かるように、コントロールプレーンイベントアプリケーション (Pod など) は Kubernetes の設定を読み込み、その後スクリプトがデフォルトで 60 分ごとに Pod のイベントをチェックします。GitHub リポジトリにある Helm チャートのデプロイ設定は変更できます。スクリプトはコントロールプレーンイベントを取得し、Container Insights を用いて CloudWatch にプッシュすることで、永続化レイヤーを完成させます。このイベントのルックアップは 1 時間ごとに実行されます。このアプローチのハイレベルなフローを下図に示します。

ステップ 2 : Container Insights を作成する
ここでは、コンテナ化されたアプリケーションからメトリクスとログを収集、集計、要約するために、CloudWatch Container Insights を使用します。Container Insights は Amazon EKS で利用可能であり、パフォーマンススタックの各レイヤーでパフォーマンスデータを収集します。このリンク先の指示に従い、Fluent Bit を使用して Container Insights を有効にしてください。
ステップ 3 : コンテナイメージを Kubernetes クラスターにデプロイし、検証する
以下の Helm コマンドを使用して、コントロールプレーンイベントアプリケーションをデプロイしてみましょう。この際、前セクションで述べたように、デフォルトのサービスアカウントでイベントにアクセス可能にするために必要な ClusterRole、ClusterRoleBinding、および Deployment を作成します。また、Amazon ECR Public からコンテナイメージを取得し、Kubernetes/Amazon EKS クラスターにデプロイします。
これで event_watcher が実行され、1 時間ごとにコントロールプレーンイベントを収集し始めるはずです。デプロイを検証してみましょう。
出力は、以下のようになります。
ステップ4:クラスターを操作する
イベントが永続化されるかどうかを確認するために、クラスター上でいくつかの操作を実施してみましょう。(CloudWatch を使用して Step 5 で確認します。)
まず nginx の Pod をいくつか作成します。
デプロイした Pod のうち 1 つを Service として公開します。
同様に、Pod のうち 1 つを削除します。
また、リソースの制約でデプロイに失敗する巨大な Pod をデプロイします。以下のコマンドで、クラスタノードの CPU カウントを確認してみてください。
ここでは、それぞれ 2 つの vCPU を持つ 3 つの t3.small インスタンスを使用しているので、以下のように出力されていることを確認します。以下の出力では、Node 名が異なる可能性があることに注意してください。
それでは、以下のコードで、5 つの vCPU を要求する巨大な Pod をデプロイしてみます。この Pod は、リソースが不足しているため、永遠に Pending 状態となります。この後のステップで、失敗した理由を確認します。
最後のステップとして、いくつかの Taint と Toleration を試してみましょう。まず、以下のコマンドで、すべての Node を key1=value1 で taint を付与してみます。以下のコマンドの出力をコピーして、ターミナルから実行してみてください。
上記の Taint を許容できない Pod をデプロイしてみましょう。この Pod は永遠に Pending 状態となります。
すべての Pod の状態は、以下のようになります。
ステップ5:CloudWatch Container Insights でコントロールプレーンイベントを検証する
さて、次はステップ 4 で実施した前述の操作イベント (およびクラスターからの他のイベント) が永続化されていることを確認します。前述のように、内部では Fluent Bit を使用して Amazon CloudWatch へプッシュする Container Insights により、これを実現しています。
AWS コンソールにログインし、Amazon CloudWatch を開きます。ロググループを選択します。下図のように、このクラスターには 3 つのロググループ (/aws/containerinsights/<cluster-name> 以下の application、dataplane、host) が存在するでしょう。

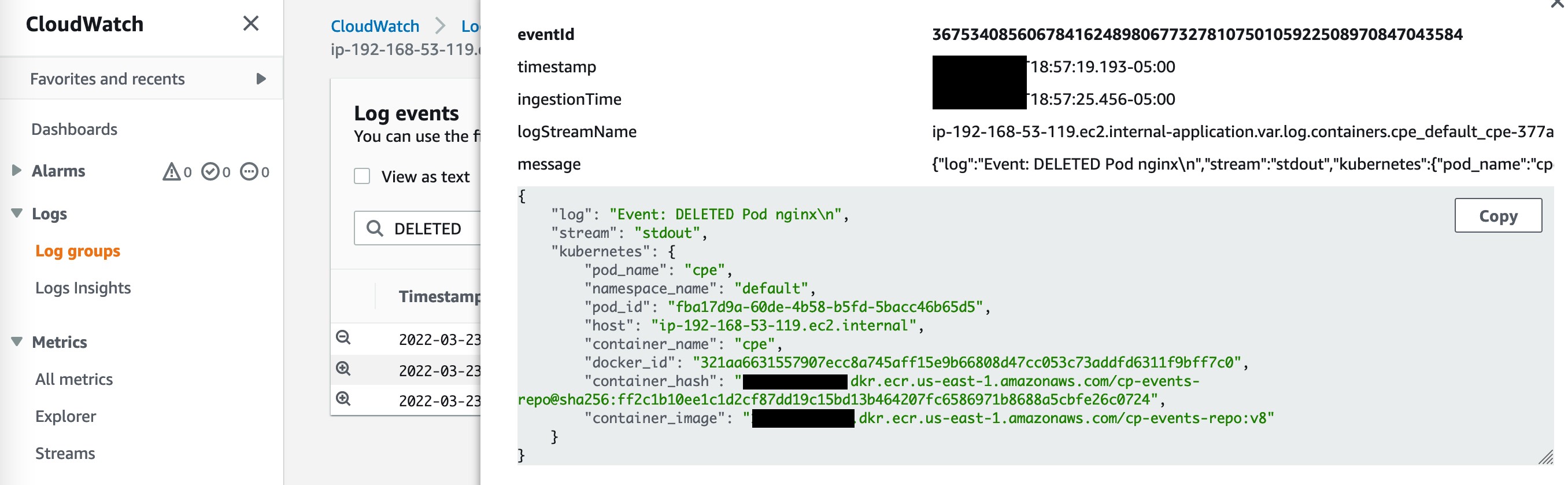
イベントの永続性を確認するために、application 以下にあるコンテナログを確認します。cpe-xx のリンクを探し、コントロールプレーンイベントアプリケーションの動作を確認してください。下図では、nginx の Pod の作成と削除のイベントが取得されていることが分かります。

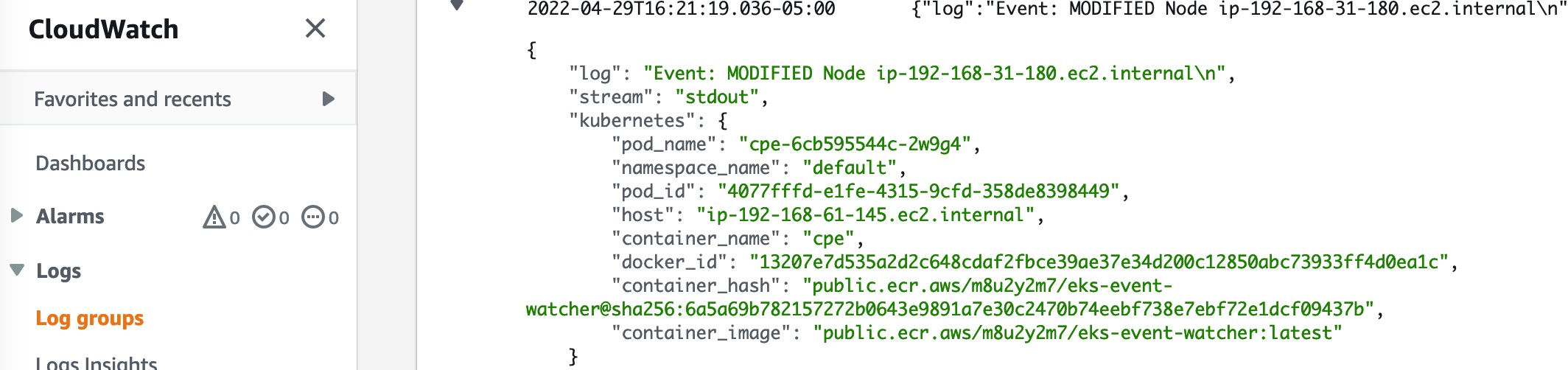
また、下図に示すように、いくつかの Node イベントも確認できます。典型的な実世界のシナリオでは、この例のような Node が削除されるスケールダウンイベントなどが発生するでしょう。
前のステップで説明したように、mega-pod はリソースの制約により、intolerable-pod は Taint によりデプロイできませんでした。テキストボックスで FailedScheduling を検索すると、下図のように、これらの詳細を確認できます。

Service イベントも確認できます。これは、ステップ 4 で公開した Service です。

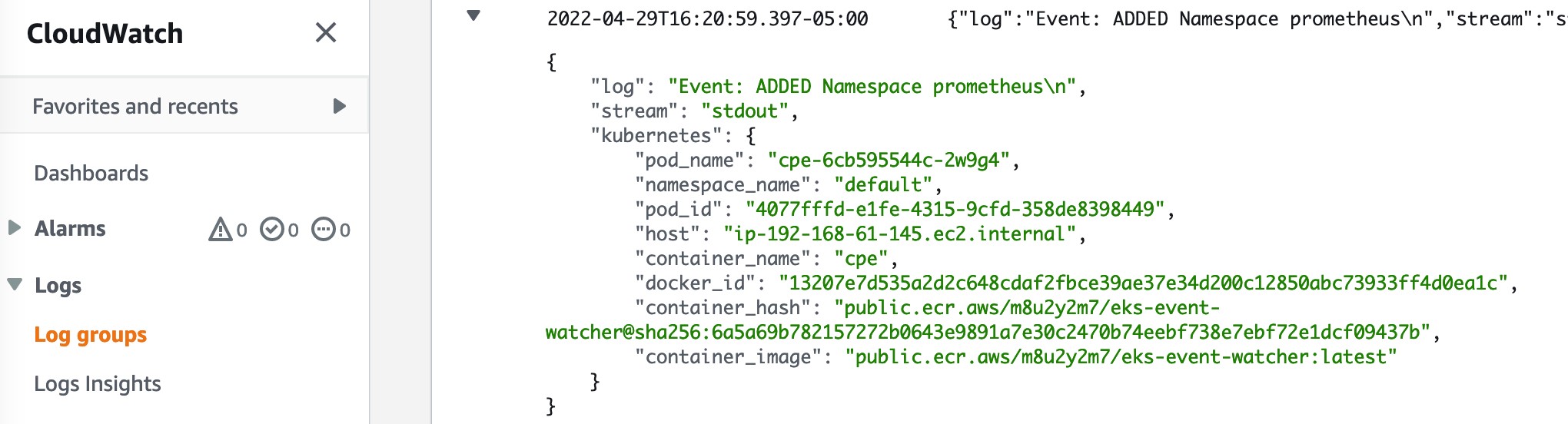
また、いくつかの Namespace と PersistentVolumeClaim のイベントもここで取得されます。例えば Prometheus をインストールしていれば、以下の例のようなイベントを確認できます。
パフォーマンスをテストする
数百の Pod が実行されている場合のコントロールプレーンイベントアプリケーションのイベント永続化のパフォーマンスをテストするために、既存のワークロードに加えて 100 個の nginx の Pod をデプロイしてみます。以下の Grafana のスナップショットからわかるように、この例の Amazon EKS クラスターでは 160 以上の Pod が実行されています。

コントロールプレーンイベントアプリケーションの Pod のログを確認すると、以下のように直近の nginx の Pod イベントが表示されます。
CloudWatch Container Insights からも、下図のような情報を得ることができます。

ペイロードが非常に小さいため、このイベント取得の仕組みは、システム内で数百の Pod が動作していても機能します。
後片付け
以降の課金を避けるため、作成したリソースを削除しましょう。
まとめ
この記事では、60 分というイベント TTL の制約の影響を受けずに、Amazon EKS のコントロールプレーンイベントを永続化する方法を紹介しました。これは、1 時間ごとに API サーバーにイベントを問い合わせるカスタムアプリケーションを作成することで実現しました。その結果、コントロールプレーンの API サーバーへの負荷は最小限に抑えて、イベントを永続化することができました。