今日の世界ではデータの役割が絶えず進化し、増大しているため、データガバナンスが効果的にデータを管理する上で重要な側面となっています。多くの組織は、データレイクを単一のリポジトリとして使用して、組織の事業体に属するデータをさまざまな形式で格納しています。メタデータ、カタログ化、およびデータ系統の使用は、データレイクを効果的に使用する上で鍵をにぎります。
この記事では、Amazon EMR にインストールされた Apache Atlas がこれを行う上でどのように機能するかについて説明します。この設定を使用すると、データを動的に分類し、さまざまなプロセスを経る際にデータの系統を表示できます。この一部として、Atlas のドメイン固有言語 (DSL) を使用してメタデータを検索できます。
Amazon EMR と Apache Atlas の紹介
Amazon EMR は、Apache Hadoop や Spark などのビッグデータフレームワークの実装を簡素化するマネージドサービスです。Amazon EMR を使用している場合、定義済みのアプリケーションセットから選択するか、リストから独自のものを選択できます。
Apache Atlas は、Hadoop のエンタープライズ規模のデータガバナンスおよびメタデータフレームワークです。Atlas は、組織がデータ資産のカタログを作成するためのオープンなメタデータ管理およびガバナンス機能を提供します。Atlas は、データがどのように進化したかを表す、ストレージ系統を含むデータ分類をサポートしています。また、重要な要素とそのビジネス定義を検索する機能も提供します。
Apache Atlas が提供するさまざまな機能の中でもとりわけこの記事で関心を寄せる中核的な機能は、Apache Hive のメタデータ管理とデータ系統です。Atlas のセットアップが成功したら、ネイティブツールを使用して Hive テーブルをインポートし、データを分析して直感的にエンドユーザーにデータ系統を提示します。Atlas とその機能の詳細については、Atlas のウェブサイトをご覧ください。
AWS Glue Data Catalog 対Apache Atlas
AWS Glue Data Catalog は、さまざまなデータソースとデータ形式にわたる統一されたメタデータリポジトリを提供します。AWS Glue Data Catalog は、Amazon EMR、Amazon RDS、Amazon Redshift、Redshift Spectrum、および Amazon Athena と統合します。データカタログは、Hive メタストアと互換性のあるあらゆるアプリケーションと連携できます。
Amazon EMR に Apache Atlas をインストールする範囲は、Amazon EMR の Hive メタストアが系統、検出、および分類の機能を提供するために必要なものを示すものに過ぎません。また、AWS Glue がない AWS リージョンのカタログ化にもこのソリューションを使用できます。
アーキテクチャ
Apache Atlas では、Apache Hadoop、HBase、Hue、Hive などの前提アプリケーションを使用して Amazon EMR クラスターを起動する必要があります。Apache Atlas では、検索機能には Apache Solr を使用し、ストレージには Apache HBase を使用します。Solr と HBase の両方が Atlas のインストールの一部として永続的な Amazon EMR クラスターにインストールされます。
このソリューションのアーキテクチャは、内部と外部の両方の Hive テーブルをサポートします。Hive メタストアが複数の Amazon EMR クラスターにまたがって存続するには、外部の Amazon RDS または Amazon Aurora データベースを使用してメタストアを含める必要があります。Hive サービスが外部 RDS Hive メタストアを参照するためのサンプル設定ファイルは、Amazon EMR ドキュメントにあります。
次の図は、このソリューションのアーキテクチャを示しています。
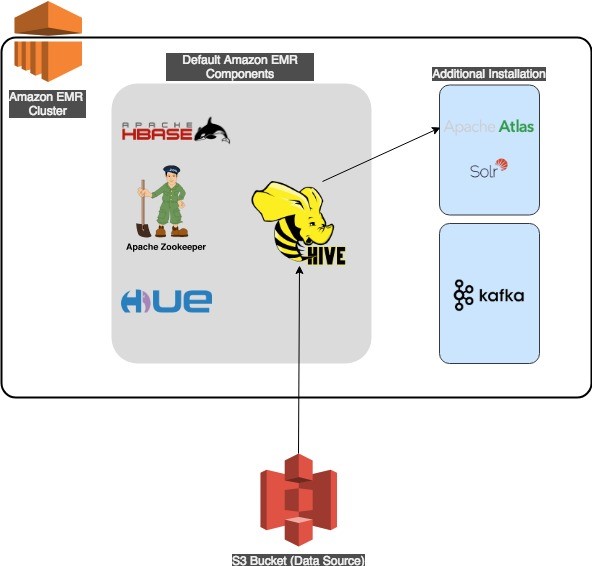
Amazon EMR–Apache Atlas のワークフロー
Apache Atlas の機能を説明するために、この記事では次のことを行います。
- AWS CLI または AWS CloudFormation を使用して Amazon EMR クラスターを起動する
- Hue を使用して、外部 Hive テーブルにデータを入力する
- Hive テーブルのデータ系統を表示する
- 分類を作成する
- Atlas ドメイン固有言語を使用してメタデータを発見する
1a.AWS CLI を使用して Apache Atlas で Amazon EMR クラスターを起動する
以下の手順では、AWS CLI を使用して Amazon EMR に Atlas をインストールする方法について説明します。このインストールでは、Hadoop、HBase、Hive、Zookeeper を使用して Amazon EMR クラスターを作成します。また、Amazon S3 バケットにあるスクリプトを実行し、/apache/atlas フォルダの下に Apache Atlas をインストールします。
自動化シェルスクリプトは以下を前提としています。
- アクセスキーとシークレットキーを使用して、AWS CLI パッケージの作業用ローカルコピーを設定していること。
- クラスターをデプロイする予定の AWS リージョンに、デフォルトのキーペア、VPC、およびサブネットがあること。
- AWS CLI で設定されたデフォルトの AWS リージョンに S3 バケットと Amazon EMR クラスターを作成するための十分な権限があること。
aws emr create-cluster --applications Name=Hive Name=HBase Name=Hue Name=Hadoop Name=ZooKeeper \
--tags Name="EMR-Atlas" \
--release-label emr-5.16.0 \
--ec2-attributes SubnetId=<subnet-xxxxx>,KeyName=<Key Name> \
--use-default-roles \
--ebs-root-volume-size 100 \
--instance-groups 'InstanceGroupType=MASTER, InstanceCount=1, InstanceType=m4.xlarge, InstanceGroupType=CORE, InstanceCount=1, InstanceType=m4.xlarge \
--log-uri ‘<S3 location for logging>’ \
--steps Name='Run Remote Script',Jar=command-runner.jar,Args=[bash,-c,'curl https://s3.amazonaws.com/aws-bigdata-blog/artifacts/aws-blog-emr-atlas/apache-atlas-emr.sh -o /tmp/script.sh; chmod +x /tmp/script.sh; /tmp/script.sh']
コマンドが正常に実行されると、クラスター ID を含む出力が表示されます。
{
"ClusterId": "j-2V3BNEB9XQ54H"
}
アクティブなクラスターの名前を一覧表示するには、次のコマンドを使用します (クラスターは準備が整った後一覧に表示されます)。
aws emr list-clusters --active
前のコマンドの出力で、サーバー名 EMR-Atlas を探します (スクリプトのデフォルト名を変更した場合を除く)。jq コマンドラインユーティリティを使用できる場合は、次のコマンドを実行して、名前とそのクラスター ID 以外のすべてをフィルタリングできます。
aws emr list-clusters --active | jq '.[][] | {(.Name): .Id}'
Sample output:
{
"external hive store on rds-external-store": "j-1MO3L3XSXZ45V"
}
{
"EMR-Atlas": "j-301TZ1GBCLK4K"
}
クラスターがアクティブリストに表示されたら、Amazon EMR と Atlas の操作準備が整います。
1b.AWS CloudFormation を使用して Apache Atlas で Amazon EMR クラスターを起動する
CloudFormation を使ってクラスターを起動することもできます。emr-atlas.template を使用して Amazon EMR クラスターをセットアップするか、次のボタンを使用して AWS マネジメントコンソールから直接起動します。

起動するには、次のパラメータに値を入力します。
| VPC |
<VPC> |
| Subnet |
<Subnet> |
| EMRLogDir |
< Amazon EMR logging directory, for example s3://xxx > |
| KeyName |
< EC2 key pair name > |
CloudFormation テンプレートを使用して Amazon EMR クラスターをプロビジョニングすると、前述の CLI コマンドと同じ結果が得られます。
続行する前に、CloudFormation スタックイベントでスタックのステータスが「CREATE_COMPLETE」に達したことが表示されるまで待ちます。
2.Hue を使って Hive テーブルを作成する
次に、Apache Atlas と Hue にログインし、Hue を使用して Hive テーブルを作成します。
Atlas にログインするには、まず Amazon EMR マネジメントコンソールを使用して、クラスターインストールでマスターパブリック DNS 名を見つけます。次に、次のコマンドを使用して Atlas ウェブブラウザへの Secure Shell (SSH) トンネルを作成します。
ssh -L 21000:localhost:21000 -i key.pem hadoop@<EMR Master IP Address>
上記のコマンドが機能しない場合は、キーファイル (*.pem) に適切な権限があることを確認してください。SSH のインバウンドルール (ポート 22) をマスターのセキュリティグループに追加する必要があるかもしれません。
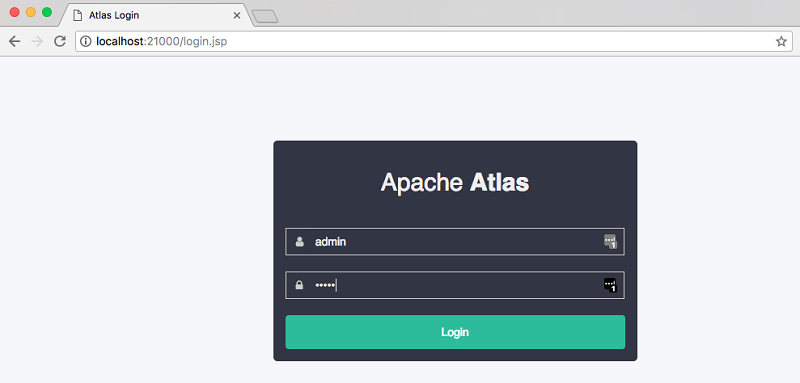
SSH トンネルを正常に作成したら、次の URL を使用して Apache Atlas UI にアクセスします。
次のような画面が表示されるはずです。デフォルトのログイン情報は、ユーザー名が admin で、パスワードも admin です。
Hue のウェブインターフェースを設定するには、Amazon EMR ドキュメントの手順に従ってください。Apache Atlas で行ったように、コンソールアクセス用にリモートポート 8888 に SSH トンネルを作成します。
ssh -L 8888:localhost:8888 -i key.pem hadoop@<EMR Master IP Address>
トンネルが作成されたら、次の URL を使用して Hue コンソールにアクセスします。
次のように、最初のログイン時に、Hue スーパーユーザーを作成するように求められます。スーパーユーザーの資格情報を失ってはいけません。
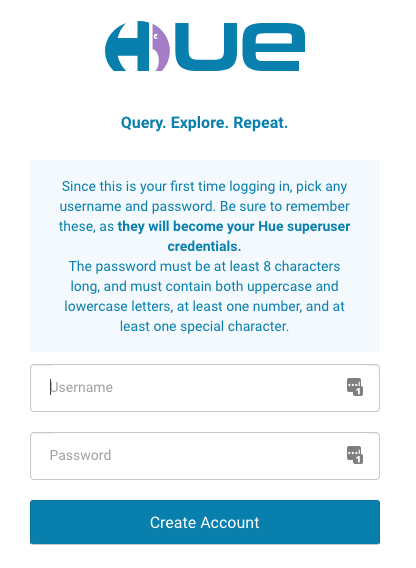
Hue スーパーユーザーを作成したら、Hue コンソールを使用して Hive クエリを実行できます。
Hue にログインしたら、次の手順を実行して次の Hive クエリを実行します。
-
create database atlas_emr;
use atlas_emr;
-
- S3 に格納されたデータを使用して、trip_details という新しい外部テーブルを作成し、S3 の場所を自分が所有するバケットに変更する。
CREATE external TABLE trip_details
(
pickup_date string ,
pickup_time string ,
location_id int ,
trip_time_in_secs int ,
trip_number int ,
dispatching_app string ,
affiliated_app string
)
row format delimited
fields terminated by ',' stored as textfile
LOCATION 's3://aws-bigdata-blog/artifacts/aws-blog-emr-atlas/trip_details/';
-
- S3 に格納されているデータを使用して、trip_zone_lookup という新しいルックアップ外部テーブルを作成する。
CREATE external TABLE trip_zone_lookup
(
LocationID int ,
Borough string ,
Zone string ,
service_zone string
)
row format delimited
fields terminated by ',' stored as textfile
LOCATION 's3://aws-bigdata-blog/artifacts/aws-blog-emr-atlas/zone_lookup/';
-
- 次のテーブルを結合して、trip_details と trip_zone_lookup の交差テーブルを作成する。
create table trip_details_by_zone as select * from trip_details join trip_zone_lookup on LocationID = location_id;
次に、Hive インポートを実行します。Atlas にインポートするメタデータの場合、Atlas Hive インポートツールは、Amazon EMR サーバーのコマンドラインを使用してのみ利用できます (Web UI はありません)。 開始するには、次のように SSH を使用して Amazon EMR マスターにログインします。
ssh -i key.pem hadoop@<EMR Master IP Address>
その後、次のコマンドを実行します。スクリプトは Atlas のユーザー名とパスワードを要求します。デフォルトのユーザー名は admin で、パスワードもadmin です。
/apache/atlas/bin/import-hive.sh
インポートが成功すると、次のようになります。
Enter username for atlas :- admin
Enter password for atlas :-
2018-09-06T13:23:33,519 INFO [main] org.apache.atlas.AtlasBaseClient - Client has only one service URL, will use that for all actions: http://localhost:21000
2018-09-06T13:23:33,543 INFO [main] org.apache.hadoop.hive.conf.HiveConf - Found configuration file file:/etc/hive/conf.dist/hive-site.xml
2018-09-06T13:23:34,394 WARN [main] org.apache.hadoop.util.NativeCodeLoader - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2018-09-06T13:23:35,272 INFO [main] hive.metastore - Trying to connect to metastore with URI thrift://ip-172-31-90-79.ec2.internal:9083
2018-09-06T13:23:35,310 INFO [main] hive.metastore - Opened a connection to metastore, current connections: 1
2018-09-06T13:23:35,365 INFO [main] hive.metastore - Connected to metastore.
2018-09-06T13:23:35,591 INFO [main] org.apache.atlas.hive.bridge.HiveMetaStoreBridge - Importing Hive metadata
2018-09-06T13:23:35,602 INFO [main] org.apache.atlas.hive.bridge.HiveMetaStoreBridge - Found 2 databases
2018-09-06T13:23:35,713 INFO [main] org.apache.atlas.AtlasBaseClient - method=GET path=api/atlas/v2/entity/uniqueAttribute/type/ contentType=application/json; charset=UTF-8 accept=application/json status=200
2018-09-06T13:23:35,987 INFO [main] org.apache.atlas.hive.bridge.HiveMetaStoreBridge - Database atlas_emr is already registered - id=cc311c0e-df88-40dc-ac12-6a1ce139ca88.Updating it.
2018-09-06T13:23:36,130 INFO [main] org.apache.atlas.AtlasBaseClient - method=POST path=api/atlas/v2/entity/ contentType=application/json; charset=UTF-8 accept=application/json status=200
2018-09-06T13:23:36,144 INFO [main] org.apache.atlas.hive.bridge.HiveMetaStoreBridge - Updated hive_db entity: name=atlas_emr@primary, guid=cc311c0e-df88-40dc-ac12-6a1ce139ca88
2018-09-06T13:23:36,164 INFO [main] org.apache.atlas.hive.bridge.HiveMetaStoreBridge - Found 3 tables to import in database atlas_emr
2018-09-06T13:23:36,287 INFO [main] org.apache.atlas.AtlasBaseClient - method=GET path=api/atlas/v2/entity/uniqueAttribute/type/ contentType=application/json; charset=UTF-8 accept=application/json status=200
2018-09-06T13:23:36,294 INFO [main] org.apache.atlas.hive.bridge.HiveMetaStoreBridge - Table atlas_emr.trip_details is already registered with id c2935940-5725-4bb3-9adb-d153e2e8b911.Updating entity.
2018-09-06T13:23:36,688 INFO [main] org.apache.atlas.AtlasBaseClient - method=POST path=api/atlas/v2/entity/ contentType=application/json; charset=UTF-8 accept=application/json status=200
2018-09-06T13:23:36,689 INFO [main] org.apache.atlas.hive.bridge.HiveMetaStoreBridge - Updated hive_table entity: name=atlas_emr.trip_details@primary, guid=c2935940-5725-4bb3-9adb-d153e2e8b911
2018-09-06T13:23:36,702 INFO [main] org.apache.atlas.AtlasBaseClient - method=GET path=api/atlas/v2/entity/uniqueAttribute/type/ contentType=application/json; charset=UTF-8 accept=application/json status=200
2018-09-06T13:23:36,703 INFO [main] org.apache.atlas.hive.bridge.HiveMetaStoreBridge - Process atlas_emr.trip_details@primary:1536239968000 is already registered
2018-09-06T13:23:36,791 INFO [main] org.apache.atlas.AtlasBaseClient - method=GET path=api/atlas/v2/entity/uniqueAttribute/type/ contentType=application/json; charset=UTF-8 accept=application/json status=200
2018-09-06T13:23:36,802 INFO [main] org.apache.atlas.hive.bridge.HiveMetaStoreBridge - Table atlas_emr.trip_details_by_zone is already registered with id c0ff33ae-ca82-4048-9671-c0b6597e1475.Updating entity.
2018-09-06T13:23:36,988 INFO [main] org.apache.atlas.AtlasBaseClient - method=POST path=api/atlas/v2/entity/ contentType=application/json; charset=UTF-8 accept=application/json status=200
2018-09-06T13:23:36,989 INFO [main] org.apache.atlas.hive.bridge.HiveMetaStoreBridge - Updated hive_table entity: name=atlas_emr.trip_details_by_zone@primary, guid=c0ff33ae-ca82-4048-9671-c0b6597e1475
2018-09-06T13:23:37,035 INFO [main] org.apache.atlas.AtlasBaseClient - method=GET path=api/atlas/v2/entity/uniqueAttribute/type/ contentType=application/json; charset=UTF-8 accept=application/json status=200
2018-09-06T13:23:37,038 INFO [main] org.apache.atlas.hive.bridge.HiveMetaStoreBridge - Table atlas_emr.trip_zone_lookup is already registered with id 834d102a-6f92-4fc9-a498-4adb4a3e7897.Updating entity.
2018-09-06T13:23:37,213 INFO [main] org.apache.atlas.AtlasBaseClient - method=POST path=api/atlas/v2/entity/ contentType=application/json; charset=UTF-8 accept=application/json status=200
2018-09-06T13:23:37,214 INFO [main] org.apache.atlas.hive.bridge.HiveMetaStoreBridge - Updated hive_table entity: name=atlas_emr.trip_zone_lookup@primary, guid=834d102a-6f92-4fc9-a498-4adb4a3e7897
2018-09-06T13:23:37,228 INFO [main] org.apache.atlas.AtlasBaseClient - method=GET path=api/atlas/v2/entity/uniqueAttribute/type/ contentType=application/json; charset=UTF-8 accept=application/json status=200
2018-09-06T13:23:37,228 INFO [main] org.apache.atlas.hive.bridge.HiveMetaStoreBridge - Process atlas_emr.trip_zone_lookup@primary:1536239987000 is already registered
2018-09-06T13:23:37,229 INFO [main] org.apache.atlas.hive.bridge.HiveMetaStoreBridge - Successfully imported 3 tables from database atlas_emr
2018-09-06T13:23:37,243 INFO [main] org.apache.atlas.AtlasBaseClient - method=GET path=api/atlas/v2/entity/uniqueAttribute/type/ contentType=application/json; charset=UTF-8 accept=application/json status=404
2018-09-06T13:23:37,353 INFO [main] org.apache.atlas.AtlasBaseClient - method=POST path=api/atlas/v2/entity/ contentType=application/json; charset=UTF-8 accept=application/json status=200
2018-09-06T13:23:37,361 INFO [main] org.apache.atlas.AtlasBaseClient - method=GET path=api/atlas/v2/entity/guid/ contentType=application/json; charset=UTF-8 accept=application/json status=200
2018-09-06T13:23:37,362 INFO [main] org.apache.atlas.hive.bridge.HiveMetaStoreBridge - Created hive_db entity: name=default@primary, guid=798fab06-ad75-4324-b7cd-e4d02b6525e8
2018-09-06T13:23:37,365 INFO [main] org.apache.atlas.hive.bridge.HiveMetaStoreBridge - No tables to import in database default
Hive Meta Data imported successfully!!!
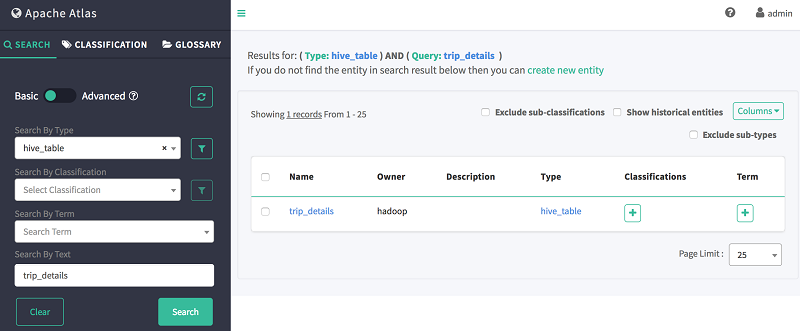
Hive のインポートが成功したら、Atlas Web UI に戻ってインポートした Hive データベースまたはテーブルを検索できます。Atlas UI の左側のペインで、[検索] が選択されていることを確認し、以下の 2 つのフィールドに次の情報を入力します。
-
-
- タイプで検索:hive_table
- テキストで検索:trip_details
上記のクエリの出力は、次のようになります。
3.Atlas を使って Hive テーブルのデータ系統を見る
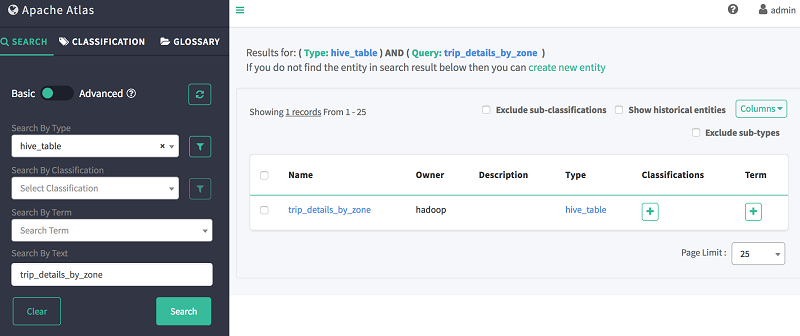
作成したテーブルの系統を表示するには、Atlas ウェブ検索を使用できます。たとえば、前に作成した交差テーブル trip_details_by_zone の系統を表示するには、次の情報を入力します。
-
-
- タイプで検索:hive_table
- テキストで検索:trip_details_by_zone
上記のクエリの出力は、次のようになります。
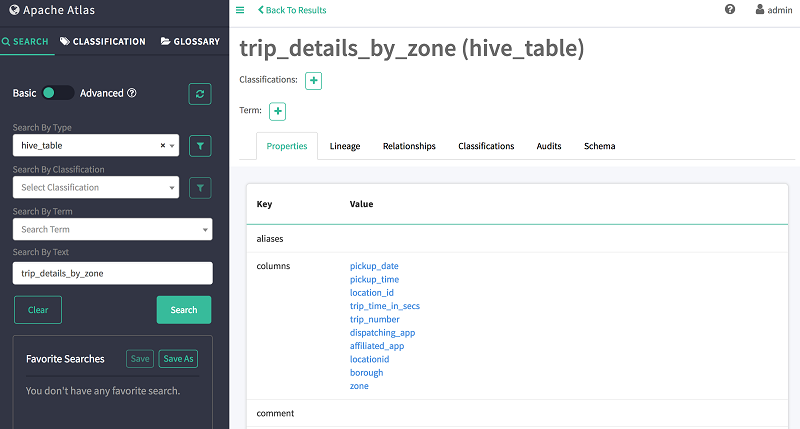
次に示すように、テーブルの詳細を表示するには、テーブル名 trip_details_by_zone を選択します。
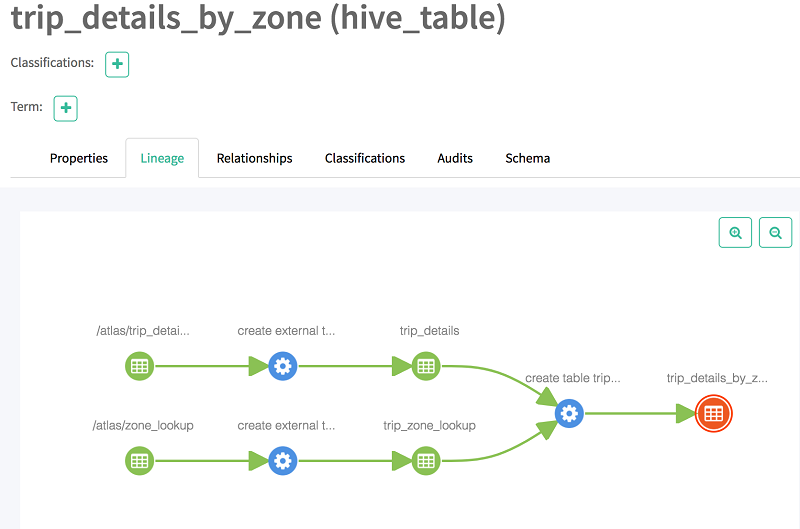
[系統] を選択すると、テーブルの系統が表示されます。以下に示すように、系統はそのベーステーブルに関する情報を提供し、2 つのテーブルの交差テーブルです。
4.メタデータ管理用の分類を作成する
Atlas は、組織に固有のデータガバナンス要件に準拠するようにメタデータを分類するのに役立ちます。次に分類例を作成します。
分類を作成するには、次の手順に従ってください。
-
-
- 左側のペインから [分類] を選択し、[+] をクリックする。
- [名前] フィールドに PII と入力し、[説明] に個人識別情報と入力する。
- [作成] を選択する。
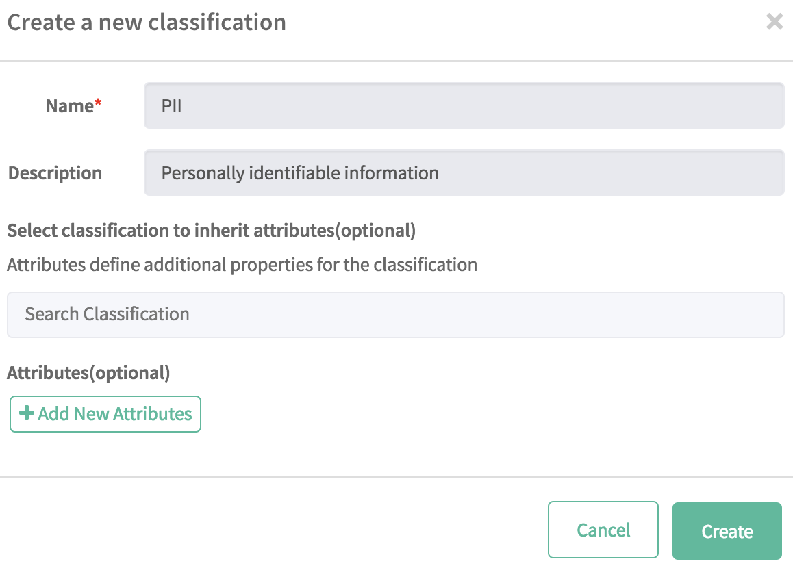
次に、次の手順に従ってテーブルを PII として分類します。
-
-
- 左側のペインの [検索] タブに戻る。
- [テキストによる検索] フィールドに、trip_zone_lookup と入力する。
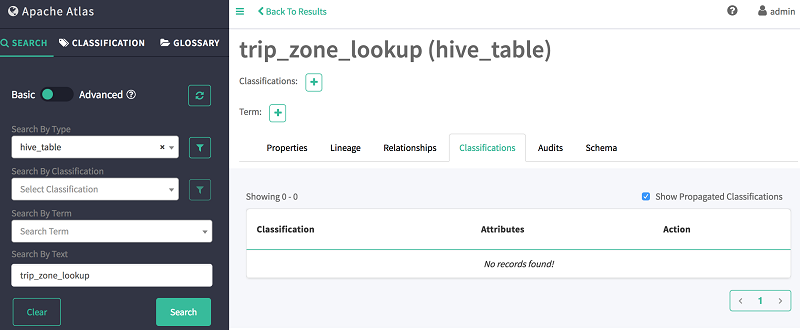
-
-
- [分類] タブを選択し、追加アイコン (+) を選択する。
- リストから作成した分類 (PII) を選択する。
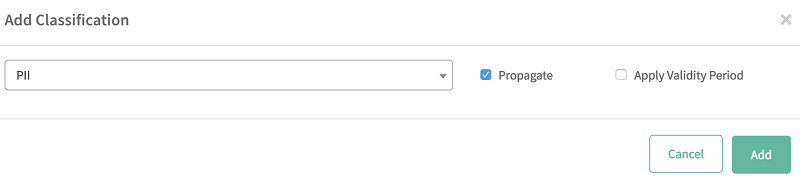
-
-
- [追加] を選択する。
列とデータベースを同様に分類することができます。
次に、次の手順に従ってこの分類に属するすべてのエンティティを表示します。
-
-
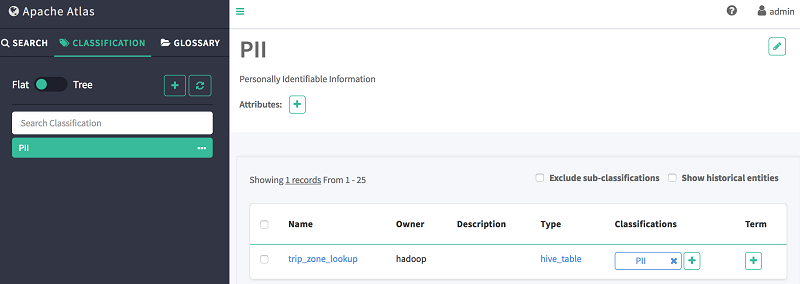
- [分類] タブを選択する。
- 作成した [PII] 分類を選択する。
- メインペインに表示されている、この分類に属するすべてのエンティティを表示する。
5.Atlas ドメイン固有言語 (DSL) を使用してメタデータを発見する
次に、SQL に似たクエリ言語である Atlas ドメイン固有言語 (DSL) を使用して、Atlas でエンティティを検索できます。この言語には、ユーザーが Atlas データリポジトリをナビゲートするのに役立つ単純な構成があります。この構文は、リレーショナルデータベースの世界で広く使用されている SQL を大まかにエミュレートします。
DSL を使用してテーブルを検索するには、次の手順に従います。
-
-
- [検索] を選択する。
- [詳細検索] を選択する。
- [タイプ別検索] で、hive_table を選択する。
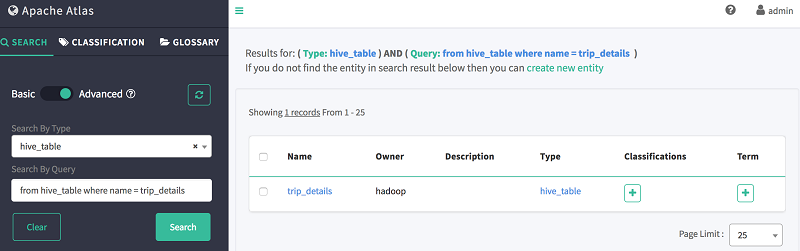
- [クエリで検索] で、次の DSL コードを使用してテーブル trip_details を検索する。
from hive_table where name = trip_details
次に示すように、Atlas はテーブルのスキーマ、系統、および分類情報を表示します。
次に、次の手順に従って DSL を使用して列を検索します。
-
-
- [検索] を選択する。
- [詳細検索] を選択する。
- [タイプ別検索] で、hive_column を選択する。
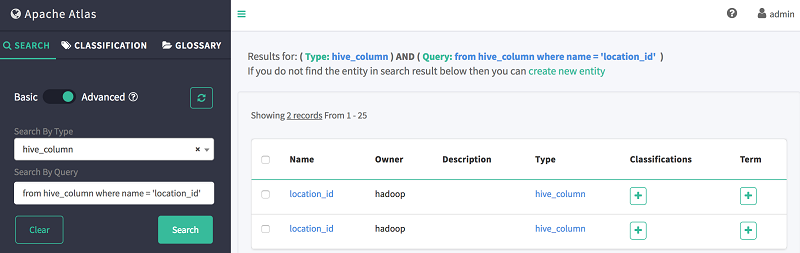
- [クエリで検索] で、次の DSL コードを使用して column location_id を検索します。
from hive_column where name = 'location_id'
以下に示すように、Atlas は以前に作成された両方のテーブルに列 location_id が存在することを示します。
DSL を使ってテーブルを数えることもできます。
-
-
- [検索] を選択する。
- [詳細検索] を選択する。
- [タイプ別検索] で、hive_table を選択する。
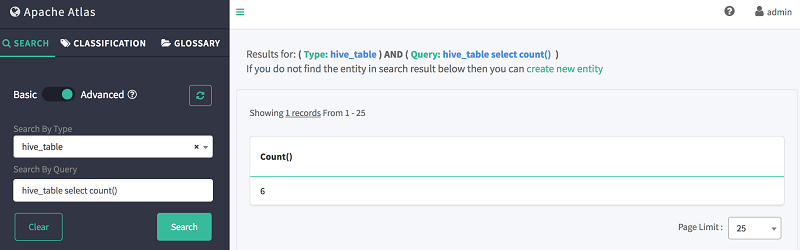
- [クエリで検索] で、次の DSL コマンドを使用してテーブルストアを検索する。
hive_table select count()
以下に示すように、Atlas はテーブルの総数を示します。
最後のステップはクリーンアップすることです。不要な課金を避けるために、試した後は Amazon EMR クラスターを削除してください。
最も簡単な方法は、CloudFormation を使用していた場合は、以前に作成した CloudFormation スタックを削除することです。デフォルトでは、クラスターは終了保護を有効にして作成されます。クラスターを削除するには、まず終了保護をオフにする必要があります。これは、Amazon EMR コンソールを使用して実行できます。
結論
この記事では、AWS CLI または CloudFormation を使用して、Apache Atlas で Amazon EMR クラスターをインストールおよび設定するために必要な手順の概要を説明しました。また、Atlas にデータをインポートして Atlas コンソールを使用してクエリを実行し、データアーティファクトの系統を表示する方法についても説明しました。
Amazon EMR または AWS に関するその他のビッグデータトピックの詳細については、「AWS Big Data ブログの EMR ブログ投稿」をご覧ください。
著者について
 Nikita Jaggi は、AWS のシニアビッグデータコンサルタントです。
Nikita Jaggi は、AWS のシニアビッグデータコンサルタントです。
 Andrew Park は、AWS のクラウドインフラストラクチャアーキテクトです。お客様との関わりを重視して業務に取り組むことに加えて、彼は顧客と直接連携してカスタム AWS ソリューションを構築し提供しています。 Andrew は、長い間 Linux ソリューションエンジニアとして働いてきて、Linux 関連の課題にどっぷりと取り組むのが大好きです。彼はオープンソースの支持者であり、野球を愛し、地元の AWS プラクティスで「ハッピーキャンパー」賞を最近受賞し、あらゆる場面で人助けをすることが大好きです。
Andrew Park は、AWS のクラウドインフラストラクチャアーキテクトです。お客様との関わりを重視して業務に取り組むことに加えて、彼は顧客と直接連携してカスタム AWS ソリューションを構築し提供しています。 Andrew は、長い間 Linux ソリューションエンジニアとして働いてきて、Linux 関連の課題にどっぷりと取り組むのが大好きです。彼はオープンソースの支持者であり、野球を愛し、地元の AWS プラクティスで「ハッピーキャンパー」賞を最近受賞し、あらゆる場面で人助けをすることが大好きです。