Amazon Web Services ブログ
Amazon Aurora の新機能 – データベースから直接機械学習を使用する
機械学習により、データからより良いインサイトを得ることができます。しかし、ほとんどの構造化データはどこに保存されているのでしょうか? データベースに保存されています! 現在、リレーショナルデータベースのデータで機械学習を使用するには、データベースからデータを読み取り、機械学習モデルを適用するカスタムアプリケーションを開発する必要があります。このアプリケーションを開発するには、データベースとインターラクションして。機械学習を使用できるようにするためのスキルが必要です。これは新しいアプリケーションであり、パフォーマンス、可用性、およびセキュリティを管理する必要があります。
リレーショナルデータベースのデータに機械学習を適用することを簡単にすることができますか? 既存のアプリケーションでも可能ですか?
本日より、Amazon Aurora は、2 つの AWS Machine Learning サービスとネイティブに統合されます。
- Amazon SageMaker。カスタム機械学習モデルを迅速に構築、トレーニング、デプロイする機能を提供するサービスです。
- Amazon Comprehend。機械学習を使用してテキストのインサイトを見つける自然言語処理 (NLP) サービスです。
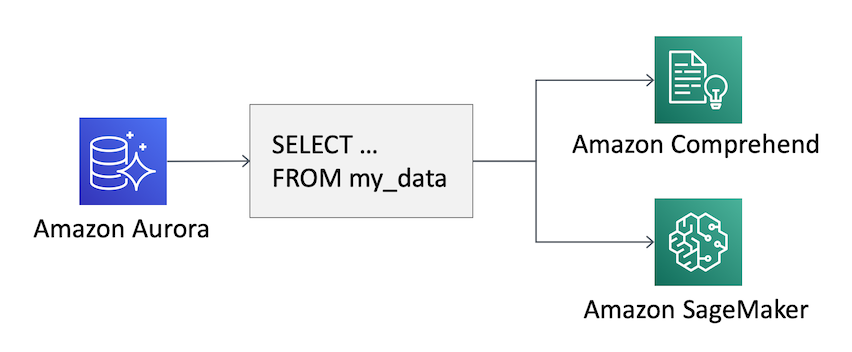
この新しい機能を使用すると、クエリで SQL 関数 を使用して、リレーショナルデータベースのデータに機械学習モデルを適用できます。たとえば、Comprehend を使用してユーザーコメントの センチメント を検出したり、SageMakerで構築されたカスタム機械学習モデルを適用したりして、お客様の「解約」のリスクを推定できます。 解約は「変化」と「ターン」を混ぜた言葉で、サービスの使用を停止するお客様を説明するために使用されます。
機械学習サービスからの追加情報を含む大規模なクエリの出力を新しいテーブルに保存したり、機械学習の経験を必要とせずにクライアントが実行する SQL コードを変更するだけで、アプリケーションでこの機能を対話的に使用したりできます。
最初に Comprehend を使用し、次に SageMaker を使用して、Aurora データベースからできることの例をいくつか見てみましょう。
データベース権限の設定
最初のステップは、次の使用したいサービスにアクセスするためのデータベース許可を付与することです。Comprehend、SageMaker、またはその両方。 RDS コンソール で、新しい Aurora MySQL 5.7 データベースを作成します。利用可能な場合、リージョンのエンドポイントの [Connectivity&security] タブで、[IAM ロールの管理] セクションを探します。
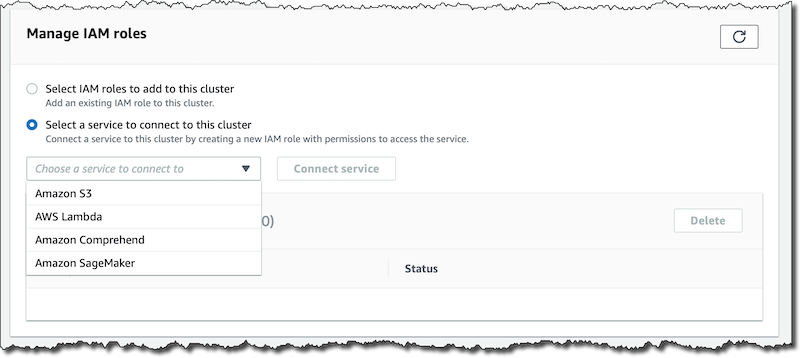
そこで、Comprehend と SageMaker をこのデータベースクラスターに接続します。SageMaker の場合、デプロイされた機械学習モデルの エンドポイント の Amazon リソースネーム (ARN) を指定する必要があります。複数のエンドポイントを使用する場合は、この手順を繰り返す必要があります。コンソールは、新しい機械学習統合を機能させるために、Aurora データベースのサービスロールを作成してそれらのサービスにアクセスします。

Amazon AuroraのComprehend の使用
MySQL クライアントを使用してデータベースに接続します。テストを実行するには、ブログプラットフォーム用のコメントを格納するテーブルを作成し、いくつかのサンプルレコードを挿入します。
CREATE TABLE IF NOT EXISTS comments (
comment_id INT AUTO_INCREMENT PRIMARY KEY,
comment_text VARCHAR(255) NOT NULL
);
INSERT INTO comments (comment_text)
VALUES ("This is very useful, thank you for writing it!");
INSERT INTO comments (comment_text)
VALUES ("Awesome, I was waiting for this feature.");
INSERT INTO comments (comment_text)
VALUES ("An interesting write up, please add more details.");
INSERT INTO comments (comment_text)
VALUES ("I don’t like how this was implemented.");テーブル内のコメントのセンチメントを検出するために、次の aws_comprehend_detect_sentiment および aws_comprehend_detect_sentiment_confidence SQL functions を使用できます。
SELECT comment_text,
aws_comprehend_detect_sentiment(comment_text, 'en') AS sentiment,
aws_comprehend_detect_sentiment_confidence(comment_text, 'en') AS confidence
FROM comments;
Aws_comprehend_detect_sentiment 関数は、入力テキストに対して最も可能性の高い感情を返します。POSITIVE、NEGATIVE、またはNEUTRAL。Aws_comprehend_detect_sentiment_confidence関数は、0 (まったく自信がない) から 1 (完全に自信がある) までのセンチメント検出の信頼度を返します。
Amazon AuroraのSageMaker エンドポイントの使用
Comprehend で行ったことと同様に、SageMaker エンドポイントにアクセスして、データベースに保存されている情報を充実させることができます。実用的なユースケースを確認するために、この投稿の冒頭で述べた顧客離れの例を実装しましょう。
携帯電話事業者には、最終的に顧客が最終的に解約したお客様と、サービスの使用を継続したお客様の過去の記録があります。この履歴情報を使用して、機械学習モデルを構築できます。モデルへの入力として、現在のサブスクリプションプラン、1 日のさまざまな時間にお客様が電話でどれだけ話しているか、およびカスタマーサービスに電話をかけた頻度に注目しています。
顧客テーブルの構造は次のとおりです。
SHOW COLUMNS FROM customers;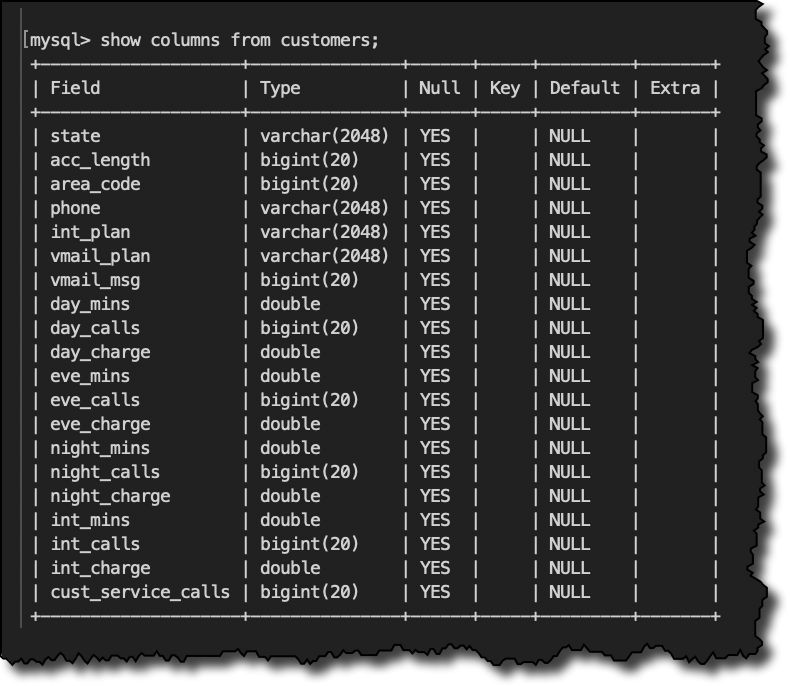
解約のリスクがある顧客を特定できるように、XGBoost アルゴリズム を使用して、この サンプルSageMakerノートブック に従ってモデルをトレーニングします。モデルが作成されると、ホストされたエンドポイントにデプロイされます。
SageMaker エンドポイントが稼働中の場合、コンソールの IAM ロールの管理 セクションに戻り、エンドポイントARNにアクセスするための Aurora データベースのアクセス許可を付与します。
ここで、モデルに必要なパラメーターをエンドポイントに入力する新しい will_churn SQL関数を作成します。
CREATE FUNCTION will_churn (
state varchar(2048), acc_length bigint(20),
area_code bigint(20), int_plan varchar(2048),
vmail_plan varchar(2048), vmail_msg bigint(20),
day_mins double, day_calls bigint(20),
eve_mins double, eve_calls bigint(20),
night_mins double, night_calls bigint(20),
int_mins double, int_calls bigint(20),
cust_service_calls bigint(20))
RETURNS varchar(2048) CHARSET latin1
alias aws_sagemaker_invoke_endpoint
endpoint name 'estimate_customer_churn_endpoint_version_123';ご覧のとおり、モデルはお客様の電話加入の詳細とサービス使用パターンを調べて、解約のリスクを特定します。will_churn SQL 関数を使用して、customers テーブルに対してクエリを実行し、機械学習モデルに基づいてお客様にフラグを立てます。クエリの結果を保存するために、新しい customers_churn テーブルを作成します。
CREATE TABLE customers_churn AS
SELECT *, will_churn(state, acc_length, area_code, int_plan,
vmail_plan, vmail_msg, day_mins, day_calls,
eve_mins, eve_calls, night_mins, night_calls,
int_mins, int_calls, cust_service_calls) will_churn
FROM customers;customers_churn テーブルからいくつかのレコードを見てみましょう。
SELECT * FROM customers_churn LIMIT 7;
最初の 7 人のお客様が明らかに解約しないことは幸運です。しかし、全体的にはどうなっていますか? Will_churn 関数の結果を保存したので、customers_churn テーブルで SELECT GROUP BY ステートメントを実行できます。
SELECT will_churn, COUNT(*) FROM customers_churn GROUP BY will_churn;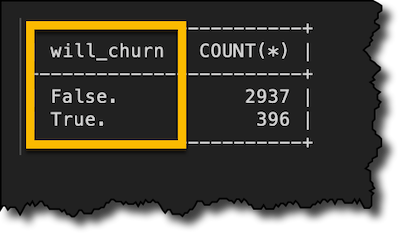
そこから始めて、顧客が解約する原因を理解するために深く掘り下げることができます。
新しいエンドポイント ARN を使用して機械学習モデルの新しいバージョンを作成すると、SQL ステートメントを変更せずに will_churn 関数を作成し直すことができます。
今すぐ利用可能
本日、Aurora MySQL 5.7 で新しい機械学習統合が利用可能になりました。SageMaker 統合は一般使用可能で、Comprehend 統合はプレビュー版です。ドキュメンテーションの詳細をご覧ください。他のエンジンとバージョンに取り組んでいます:Aurora MySQL 5.6 と Aurora PostgreSQL 10 および 11 はまもなく公開されます。
Aurora の機械学習の統合は、基礎となるサービスが利用可能なすべてのリージョンで利用できます。たとえば、Aurora MySQL 5.7 と SageMaker の両方がリージョンで利用可能な場合、SageMaker の統合を使用できます。利用可能なサービスの完全なリストについては、AWS リージョナルテーブル をご覧ください。
統合を使用するための追加費用はありません。通常の料金で基礎となるサービスに対して支払うだけです。Comprehend を使用するときは、クエリのサイズに注意してください。 たとえば、カスタマーサービスのウェブページでユーザーフィードバックのセンチメント分析を行い、特に肯定的または否定的なコメントを行った人々に連絡し、人々が 1 日 10,000 件のコメントを行っている場合、1日 3 ドルを支払うことになります。 コストを最適化するには、結果を保存することを忘れないでください。
リレーショナルデータベースに保存されたデータに機械学習モデルを適用するのがかつてないほど簡単になりました。この機能を使って、何を構築しようと考えているか、ぜひ教えてください。
— Danilo