Amazon Web Services ブログ
Amazon SageMaker から Amazon EMR クラスタを作成・管理し、 Spark と ML のインタラクティブな ワークロードを実行する – Part1
この記事は、“Create and manage Amazon EMR Clusters from SageMaker Studio to run interactive Spark and ML workloads – Part 1” を翻訳したものです。
Amazon SageMaker Studio は、機械学習のための初の完全統合開発環境(IDE)です。データの準備、モデルの構築、学習、デプロイに必要なすべての ML 開発ステップを実行できる、単一の Web ベースのビジュアルインターフェイスを提供します。先日、Studio ノートブックから Amazon EMR クラスタを視覚的に閲覧し、接続する機能を導入しました。詳細はこちらをご覧ください。米国時間 2021 年 12 月 1 日より、Amazon EMR 上で実行されている Spark ジョブを、Studio ノートブックからワンクリックで監視およびデバッグできるようになりました。さらに、Amazon SageMaker Studio から直接 EMR クラスタを検出、接続、作成、停止、管理できるようになりました。
この2部構成の記事で、新しく導入されたこれらの機能のデモを行います。
大量のデータを分析し、変換し、準備することは、あらゆるデータサイエンスと ML ワークフローの基本的なステップです。データサイエンティストやデータエンジニアなどのデータワーカーは、高速にデータを準備することを目的にAmazon EMR 上で実行される Apache Spark、Hive、Presto を使用します。これまで、これらのデータワーカーは、SageMaker Studio と同じアカウントで稼働する EMR クラスタを簡単に検出して接続することができましたが、アカウントをまたいで接続することはできませんでした(この構成は複数のお客様に共通するものです)。さらに、データワーカーが特定の対話型ワークロードに合わせた EMR クラスタをオンデマンドで作成する必要がある場合、管理者に作成を依頼するか、DevOps の詳しい技術知識を駆使して自分で作成するか、インターフェースを切り替える必要がありました。このプロセスは困難であり、ワークフローを混乱させるだけでなく、データワーカーがデータの準備作業に集中するのを妨げる要因にもなっていました。その結果、不経済的であるにもかかわらず、多くのお客様は、使用状況に関わらず、ワークロードが来ることを想定してクラスタを永続的に稼動させていました。さらに、Amazon EMR 上で実行される Spark ジョブの監視とデバッグには、複雑なセキュリティルールと Web プロキシの設定が必要で、データワーカーのワークフローにとって大きな障壁となっていました。
米国時間 2021 年 12 月 1 日より、データワーカーは、単一アカウントおよびクロスアカウント構成の EMR クラスタを、SageMaker Studio から直接簡単に検出し接続できるようになりました。
さらに、ワンクリックで Spark UI にアクセスし、SageMaker Studio ノートブックから Amazon EMR 上で実行されている Spark ジョブを直接監視およびデバッグできるようになったため、Spark デバッグワークフローが大幅に簡素化されました。
さらに、AWS Service Catalog を使用して、事前設定されたテンプレートを定義し、データワーカーを選択してロールアウトすることで、スタジオから直接 EMR クラスタを作成できるようになります。これにより、データワーカーがこれらのテンプレートを使用する際に遵守すべき組織、セキュリティ、コンピューティング、およびネットワークのガードレールを完全に制御することができます。データワーカーは、利用可能な一連のテンプレートを視覚的に閲覧し、特定のワークロードに合わせてカスタマイズし、必要に応じて EMR クラスタを作成し、SageMaker Studio で数回クリックするだけで停止することができます。この機能により、データ準備のワークフローが大幅に簡素化され、インタラクティブなワークロードのために SageMaker Studio からEMR クラスタの最適な使い方が可能になります。
本連載のPart 1 では、DevOps 管理者が AWS Service Catalog を使用して、データワーカーが SageMaker Studio の UI から EMR クラスタを作成する際に使用するテンプレートを定義する方法の詳細について説明します。既存の Amazon SageMaker ドメイン内に EMR クラスタを作成するための AWS Service Catalog 製品を作成する AWS CloudFormation テンプレートと、Amazon SageMaker ドメイン、Studio ユーザープロファイル、およびそのユーザーと共有するService Catalog 製品を立ち上げてゼロから始めることができる新規の CloudFormation テンプレートが提供されます。このソリューションの一部として、single-click Spark UI インターフェースを利用して、ETL ジョブのデバッグと監視を行います。変換されたデータを用いて、SageMaker のトレーニングおよびホスティングサービスを使用して ML モデルをトレーニングし、デプロイしています。
続いて、Part 2 では、クロスアカウントセットアップについて深く掘り下げて説明します。これらのマルチアカウント設定はお客様の間で一般的であり、私たちの AWS Well-Architected Framework で述べたように、多くのエンタープライズアカウントのセットアップのベストプラクティスとなっています。
ソリューションの概要
まず、 Perform interactive data engineering and data science workflows from Amazon SageMaker Studio notebooks のブログ記事にあるように、SageMaker Studio からAmazon EMR と通信する方法について説明します。このソリューションでは、Elastic Network Interface を用いてプライベート VPC モードで構成された SageMaker ドメインを利用しています。その接続された VPC で、このデモのための EMR クラスタをスピンアップしています。前提条件の詳細については、当社のドキュメントを参照してください。
次の図は、ユーザージャーニーの全容を表しています。DevOps ペルソナは、SageMaker Studionの実行ロールからアクセス可能なポートフォリオ内にサービスカタログ製品を作成します。

Amazon SageMaker Studio からデプロイできるテンプレートを作成する際に、Amazon EMR の CloudFormation プロパティをフルセットで使用できることを留意してください。つまり、Service Catalog 製品を通じて、Spot、オートスケーリング、およびその他の一般的な構成を有効にすることができます。
エンドユーザーがワークロードに合わせてクラスタのさまざまな要素を変更できるように、プリセットの (EMR クラスタを作成する)CloudFormation テンプレートをパラメータとして指定することができます。たとえば、データサイエンティストやデータエンジニアはクラスタのコアノード数を指定したいかもしれませんし、テンプレートの作成者は AllowedValues を指定してガードレールを設定することが可能です。
以下のテンプレートパラメーターは、一般的に使用されるパラメーターの例を示しています。
スタジオのインターフェイスで製品を表示するには、サービスカタログ製品に次のタグを設定する必要があります。
最後に、Service Catalog 製品の CloudFormation テンプレートは、以下の必須スタックパラメーターを持つ必要があります。
これらのパラメータの値は、いずれもスタック起動時に自動的に注入されるため、記入する必要はありません。SageMaker プロジェクトは、Service CatalogとSageMaker Studio 間の統合の一部として利用されるため、これらはテンプレートの一部となっています。
(アーキテクチャ図に示す)シングルアカウントユーザージャーニーの 2 つ目の要素は、SageMaker Studio 内のデータワーカーの視点からのものです。Perform interactive data engineering and data science workflows from Amazon SageMaker Studio notebooks のブログ記事で示したように、SageMaker Studio ユーザーは既存の EMR クラスタを参照し、Kerberos、LDAP、HTTP、または無認証メカニズムを使用してシームレスにこれらのクラスタに接続することができます。また、以下のアーキテクチャ図に示すように、テンプレートのプロビジョニングによって新しい EMR クラスタを作成することもできるようになりました。

SageMaker Studio のユーザーが利用可能なクラスタを参照するには、Amazon EMR の検出を許可する AWS Identity and Access Management (IAM) ポリシーを添付する必要があります。詳細については、既存のドキュメントを参照してください。
AWS CloudFormationを用いたリソースのデプロイ
この記事では、我々の GitHub リポジトリにあるような SageMaker Studio と EMR の機能の実演をするために、2つのCloudFormation スタックを提供しました。
最初のスタックは、プライベート VPC、その VPC に接続された SageMaker ドメイン、および事前に作成された Service Catalog 製品を確認する権限を持つ SageMaker ユーザーを立ち上げるエンドツーエンドの CloudFormation テンプレートを提供するものです。
2つ目のスタックは、既存の プライベート VPC でセットアップされたSageMaker Studio を持つユーザーが、CloudFormation スタックを利用してService Catalog 製品を展開し、それを既存の SageMaker ユーザーから見えるようにしたい場合に使用するものです。
以下のスタックを起動する際に使用する Studio および Amazon EMR のリソースが課金されます。詳細については、Amazon SageMaker の価格と Amazon EMR の価格を参照してください。
この記事の最後にあるクリーンアップセクションの指示に従って、これらのリソースに課金され続けることがないようにします。
エンドツーエンドスタックを起動するには、希望するリージョンのスタックを選択します。
| ap-northeast-1 | |
| ap-northeast-2 | |
| ap-south-1 | |
| ap-southeast-1 | |
| ca-central-1 | |
| eu-central-1 | |
| eu-north-1 | |
| eu-west-1 | |
| eu-west-2 | |
| eu-west-3 | |
| sa-east-1 | |
| us-east-1 | |
| us-east-2 | |
| us-west-1 | |
| us-west-2 |
このスタックは、ゼロからセットアップすることを目的としているため、管理者は自分のアカウントに関連する特定のパラメータを入力するためだけにこのスタックを起動する必要はありません。ただし、後述の Amazon EMR スタックはこのスタックの出力を使用するため、参照できるように一意なスタック名を提供する必要があります。上述のリンクでは、このデモで期待されるスタック名があらかじめ設定されていますが、それを変更しないように注意してください。
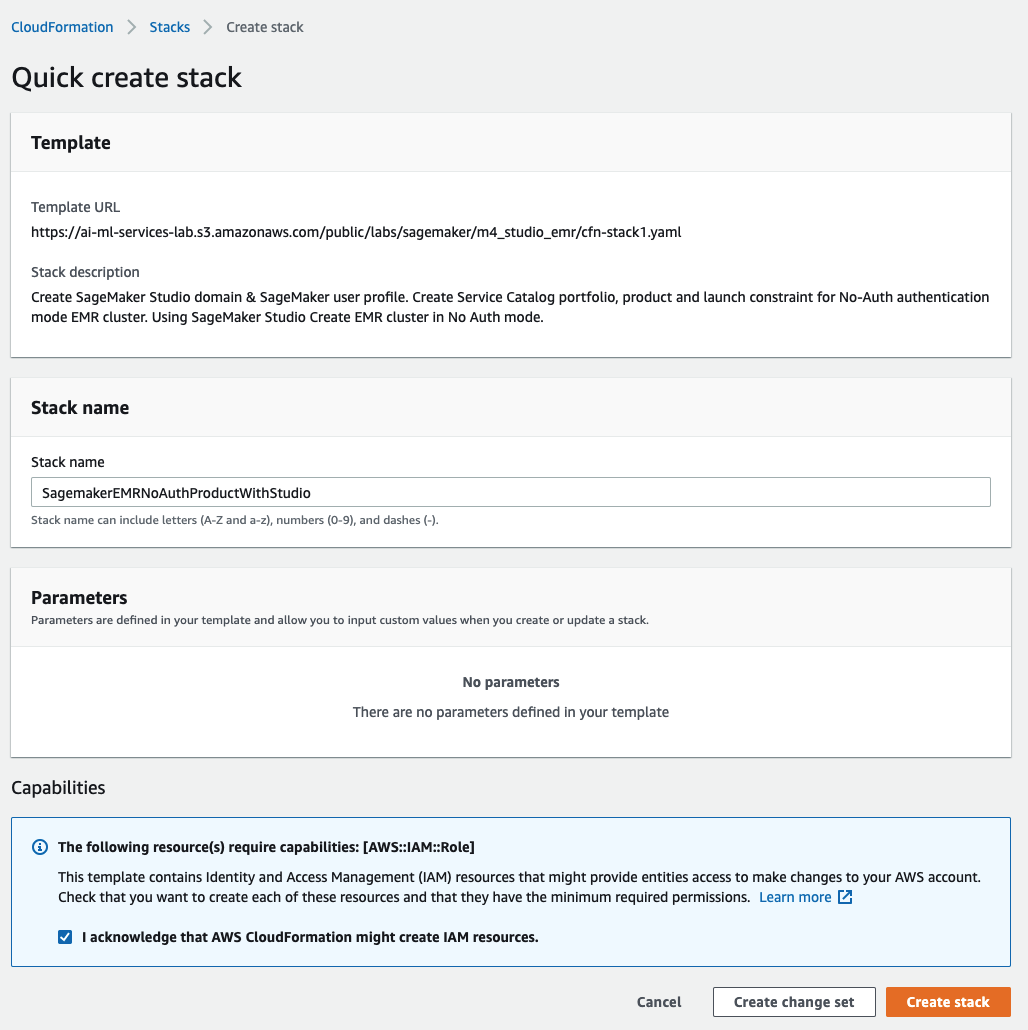
スタックを起動すると、SageMaker Studio ドメインが作成され、studio-user が Service Catalog 製品を可視化するために作成された実行ロールにアタッチされていることが確認できます。
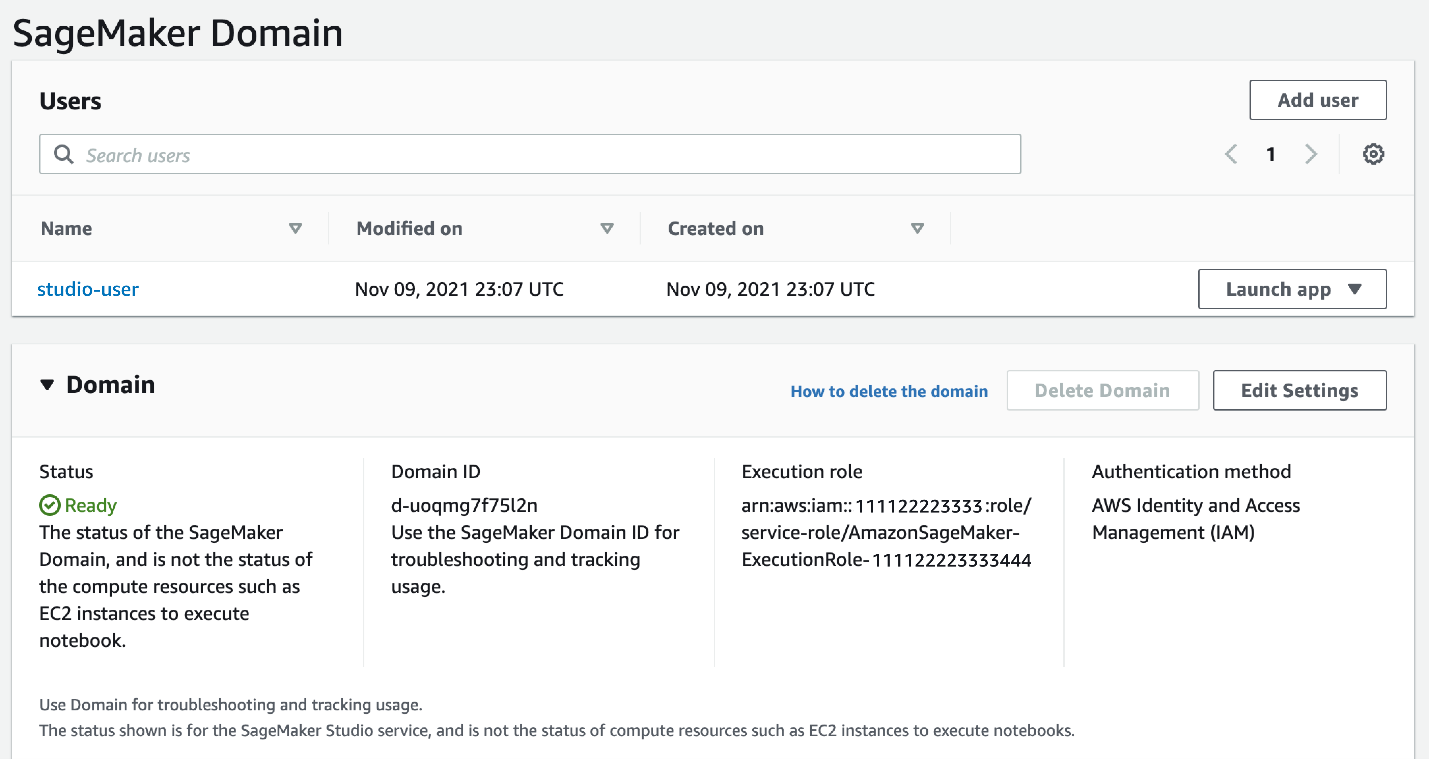
エンドツーエンドスタックを実行する場合、以下の既存ドメインに関する情報はスキップしてください。
既存のドメインスタックがある場合、お好みのリージョンで以下のスタックを起動します。
| ap-northeast-1 | |
| ap-northeast-2 | |
| ap-south-1 | |
| ap-southeast-1 | |
| ca-central-1 | |
| eu-central-1 | |
| eu-north-1 | |
| eu-west-1 | |
| eu-west-2 | |
| eu-west-3 | |
| sa-east-1 | |
| us-east-1 | |
| us-east-2 | |
| us-west-1 | |
| us-west-2 |
このスタックは、プライベートサブネットにアタッチされている既存のドメインを持つアカウントを対象としているため、管理者はスタック起動時に必要なパラメータを入力する必要があります。これは、このネットワーク情報を抽象化することで、データワーカーが必要な作業を簡素化することを目的としています。
繰り返しになりますが、次の Amazon EMR スタックは管理者がここで入力したパラメータを使用するため、それらを参照できるように一意なスタック名を提供する必要があります。上述のスタックリンクは、このデモで期待されるスタック名をあらかじめ設定しています。

既存のドメインとユーザーで 2 つ目のスタックを使用する場合、Spark UI 機能が使用可能で、ユーザーが EMR クラスタを参照し、スピンアップとスピンダウンすることが可能なことを確認するために、追加のステップを完了する必要があります。パラメータとして入力した SageMaker 実行ロールに、必要に応じて Region と Account ID を指定して、以下のポリシーをアタッチするだけです。
AWS Service Catalog 製品の確認
スタックを起動すると、起動制約として IAM ロールが作成され、EMR クラスタをプロビジョニングしていることが確認できます。また、どちらのスタックも AWS Service Catalog の製品と、SageMaker Studio 実行ロールへ関連付けられています。
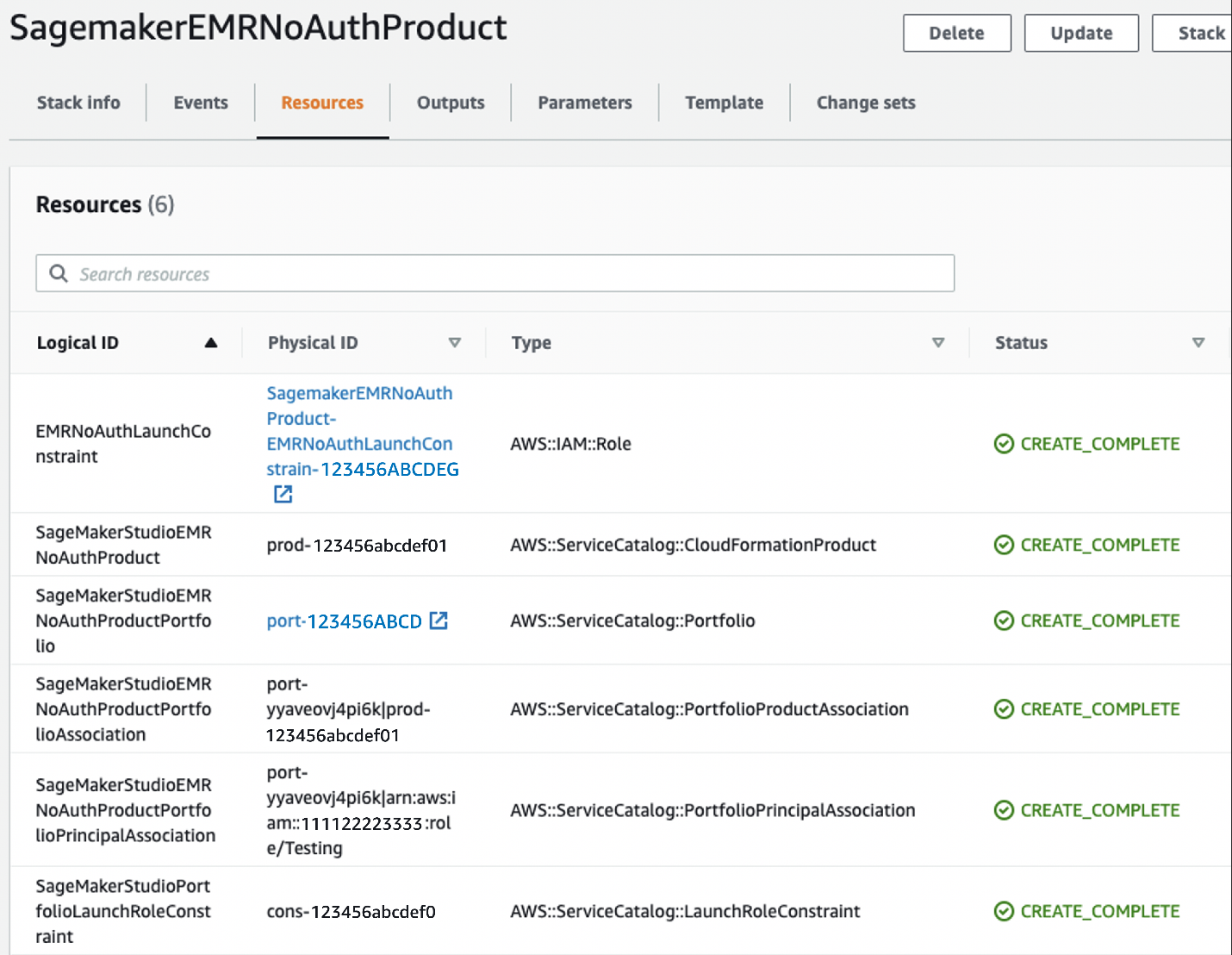 AWS Service Catalog の製品一覧では、製品名が表示されていますが、これは後に SageMaker Studio のインターフェイスから確認できるようになります。
AWS Service Catalog の製品一覧では、製品名が表示されていますが、これは後に SageMaker Studio のインターフェイスから確認できるようになります。
 この製品には、クラスタを作成するロールを制御する起動制約が設定されています。
この製品には、クラスタを作成するロールを制御する起動制約が設定されています。

なお、このService Catalog 製品は、Studio のインターフェイスで表示できるように、適切なタグが付けられます。

プロビジョニングされたテンプレートを見ると、クラスタを初期化し、Hive テーブルを作成し、デモデータをロードする CloudFormation テンプレートが表示されていることがわかります。
 SageMaker Studio から EMR クラスタを作成する
SageMaker Studio から EMR クラスタを作成する
お客様のセットアップに合ったスタックを介してアカウントにサービスカタログ製品の作成が完了したら、データワーカーの視点からデモを続けることができます。
- SageMaker Studio ノートブックを起動します。
- SageMaker resources のドロップダウンメニューから Clusters を選択します。
- Create Clusters を選択します。
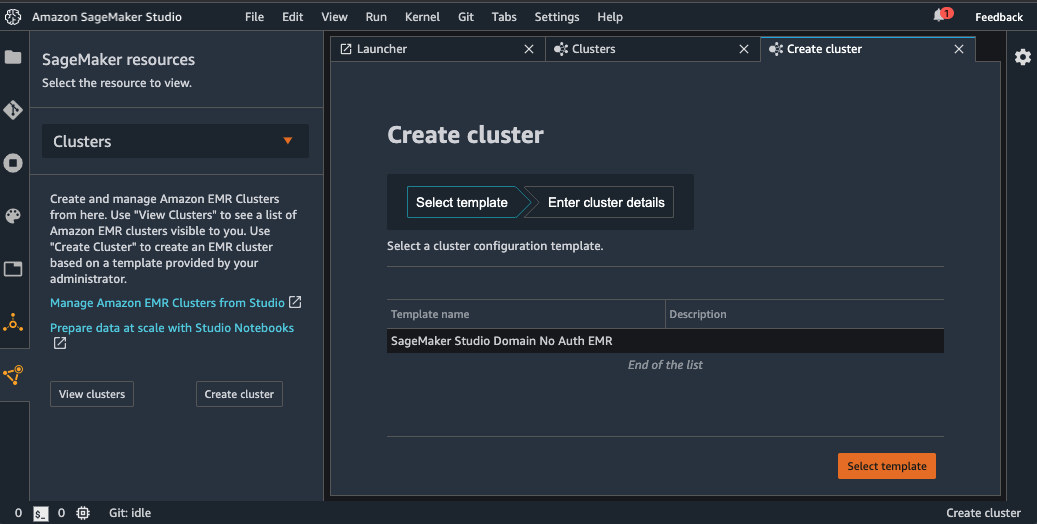
- 利用可能なテンプレートから、プロビジョニングされたテンプレートである SageMaker Studio Domain No Auth EMR を選択します。
- 必要な設定可能なパラメータを入力し、Create cluster を選択します。
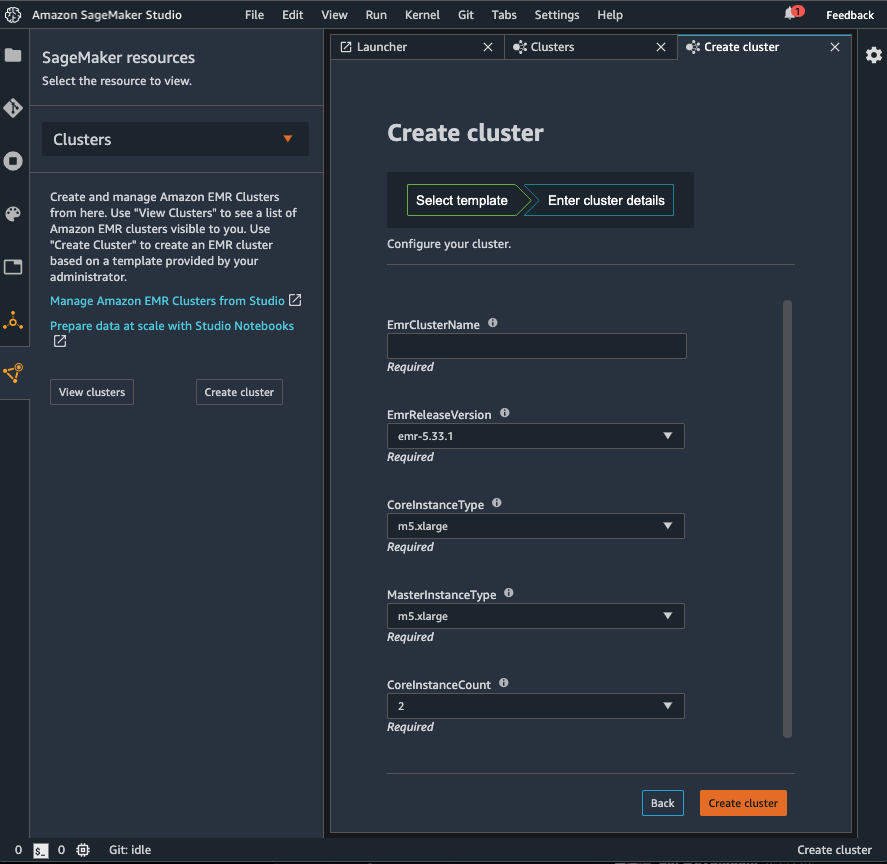
これで、マネージメントタブの Clusters からデプロイメントを監視できるようになりました。テンプレートの一部として、このクラスタは、この例の一部で使用されるいくつかのデータで Hive テーブルをインスタンス化します。

SageMaker Studio から EMR クラスタに接続する
クラスタのステータスが Running/Waiting 状態になったら、Perform interactive data engineering and data science workflows from Amazon SageMaker Studio notebooks の記事で説明したものと同じ方法で、クラスタに接続することができます。
まず、GitHub のレポジトリをクローンします。

この記事を書いている時点(2021 年 12 月)では、カーネルの一部のみが既存の EMR クラスタへの接続をサポートしています。サポートされているカーネルの完全なリストと、接続機能を備えた独自の Studio イメージの構築に関する情報については、当社のドキュメントを参照してください。この記事では、PySpark イメージの SparkMagic カーネルを使用し、リポジトリから blog_example_code/smstudio-pyspark-hive-sentiment-analysis.ipynb ノートブック を実行します。
簡単にするために、デプロイするテンプレートは無認証の認証メカニズムを使用しますが、以前投稿したブログで示したように、ここではKerberos、LDAP、HTTP 認証もシームレスに動作します。
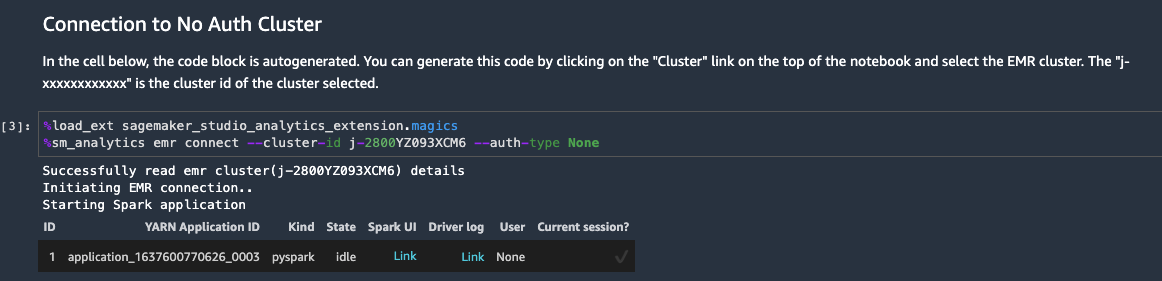 接続が完了すると、Spark UI へのハイパーリンクが表示され、デモのデバッグとモニタリングに使用できます。技術的な詳細については、この記事の後半で説明しますが、この時点で新しいタブでこの記事を開くことが可能です。
接続が完了すると、Spark UI へのハイパーリンクが表示され、デモのデバッグとモニタリングに使用できます。技術的な詳細については、この記事の後半で説明しますが、この時点で新しいタブでこの記事を開くことが可能です。
次に、前回の記事で紹介した、新しくインスタンス化したテーブルにPySpark を使ってクエリを実行する機能、変換したデータを Amazon Simple Storage Service (Amazon S3) に書き込む機能、SageMaker のトレーニングおよびホスティングジョブを起動する機能をすべて同じ smstudio-pyspark-hive-sentiment-analysis.ipynb ノートブックを基に紹介します。
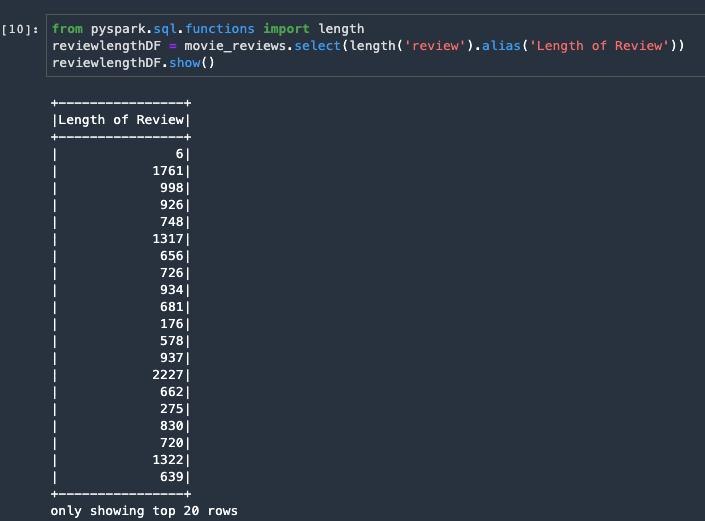
以下のスクリーンショットは、データの前処理を行うものの例です。

 以下のスクリーンショットは、モデルを学習するプロセスを示しています。
以下のスクリーンショットは、モデルを学習するプロセスを示しています。

 以下のスクリーンショットは、モデルのデプロイを示すものです。
以下のスクリーンショットは、モデルのデプロイを示すものです。
 Spark UIを用いてモニタリングとデバッグを行う
Spark UIを用いてモニタリングとデバッグを行う
前述の通り、Spark UI を表示するためのプロセスが大幅に簡略化され、クラスタへの接続時に署名済み URL が生成されるようになりました。それぞれの署名済み URL の有効期限は5分です。
この UI は、Spark の実行状況の監視やシャッフリングなどに利用できます。詳しくはドキュメント参照してください。
SageMaker Studio からEMR クラスタを停止する
解析とモデルの構築が終わったら、SageMaker Studio のインターフェイスを使ってクラスタを停止することができます。これは内部で DELETE STACK を実行するため、ユーザーはプロビジョニングされた Service Catalog テンプレートを使用して起動されたクラスタのみを停止するアクセス権を持ち、スタジオの外で作成された既存のクラスタを停止することはできません。
 エンドツーエンドスタックのクリーンアップ
エンドツーエンドスタックのクリーンアップ

エンドツーエンドスタックをデプロイした場合、以下の手順を実行してこのソリューション用にデプロイしたリソースをクリーンアップします。
- 前のセクションで示したように、クラスタを停止します。
これは、S3 バケットも削除するので、後で使用するためにデータを保持したい場合は、バケット内のコンテンツをバックアップ用のロケーションにコピーする必要があります。
- SageMaker Studio コンソールで、ユーザー名( studio-user )を選択します。
- Delete app を選択して、Apps に表示されているすべてのアプリケーションを削除します。
- ステータスが
Completedと表示されるまで待ちます。
次に、Amazon Elastic File System( Amazon EFS )ボリュームを削除します。
- Amazon EFS のコンソールで、SageMaker が作成したファイルシステムを削除します。
ファイルシステム ID を選択し、タグが ManagedByAmazonSageMakerResource であることを確認することで、正しいボリュームであることを確認することができます。
最後に、CloudFormation のテンプレートを削除します。
- AWS CloudFormation コンソールで、Stacks を選択します。
- このソリューションにデプロイしたスタックを選択します。
- Delete を選択します。
既存ドメインを利用したスタックのクリーンアップ
2つ目のスタックは、このチュートリアルを始める前に作成された SageMaker Studio のリソースをそのままにしておくので、クリーンアップがより簡単になります。
- 前のクリーンアップの手順で示したように、クラスタを停止します。
- SageMaker の実行ロールに追加した、Amazon EMR のブラウジングと
PresignedURLのアクセスを許可するポリシーを削除します - AWS CloudFormation コンソールで、Stacksを選択します。
- このソリューションにデプロイしたスタックを選択します。
- Deleteを選択します。
結論
この投稿では、EMR クラスタの作成と管理、クラスタ上での分析の実行、SageMaker モデルのトレーニングとデプロイを、すべて SageMaker Studio のインターフェースから行うための、ノートブックを中心とした統一された一連の機能を紹介しました。また、Spark UI から Amazon EMR ジョブのデバッグと監視を行うためのワンクリックインターフェースも紹介しました。この投稿の Part 2 では、データワーカーがマルチアカウント環境でクラスタを検出、接続、作成、停止する方法について詳しく説明します。
翻訳はソリューションアーキテクト 深見 修平 が担当しました。原文はこちらです