Amazon Web Services ブログ
Part 1: Amazon Omics のご紹介 – セキュアかつ大規模に生物配列データから洞察を得る
この記事は、「Part 1: Introducing Amazon Omics – from sequence data to insights, securely and scale」を翻訳したものです。
この記事は、Amazon Omics のローンチの詳細を説明する 2 部作の Part 1 です。Part 2 では、より深い技術的詳細を説明します。
Amazon Omics の一般提供を開始できることを嬉しく思います。Amazon Omics は、バイオインフォマティシャン、研究者、科学者が、ゲノム、トランスクリプトーム、その他のオミックスデータを保存、クエリ、解析し、そこから洞察を得ることをご支援する目的に特化して構築されたサービスです。
ライフサイエンス分野のお客様は、医薬品の研究開発を加速させ、患者の治療法の開発につなげたいと考えています。また、ヘルスケア分野のお客様は、患者にとって最適な治療法や予防法を特定することで、医療を変革したいと考えています。その好例が、ゲノムデータを活用して個々の患者の腫瘍や血液中の循環マーカーのプロファイリングを行い、臨床医の診療の場での意思決定を支援する方法です。この方法により、がん患者に対する個別化医療の選択肢は、過去 10 年間で 4 倍に増加しました。Stanford、Philips、Roche、Genomics England が行った取り組みでは、より一層、個々の患者についての洞察を促進することと、患者や研究領域の全体像の理解を深めることの利点を証明しています。
精密医療の時代
私たちは医療の変曲点を迎えようとしています。高度に個別化され、正確にターゲットを絞った診断と治療の提供、いわゆる、精密医療の時代です。精密医療の発展の原動力となっているのは、
- 医療データのデジタル化と共有。医療記録の 98 %以上がデジタル化されています
- 2001 年に初めてヒトゲノムの塩基配列が決定されて以来、10 万分の 1 にまで低下した塩基配列決定のコスト。過去最低の約 200 ドルにまで達しています
- ヘルスケアおよびライフサイエンス分野でのクラウドコンピューティングの成長
DNA 配列だけでなく、RNA やタンパク質の配列も、これまで以上に簡単に測定できるようになりました。このようなゲノム、トランスクリプトーム、プロテオームなどのオミックスデータの爆発的な増加は、分子レベルで生物学に対する新たな理解をもたらしています。例えば、ゲノムの複雑な領域を同定する次世代シーケンサーなど、より新しく、正確なシーケンス技術の進歩は、日々のスループットを 2.5 倍に高め、オミックスデータの成長を加速しています。臨床情報とオミックス情報の組み合わせは、創薬、ワクチン開発、個人の遺伝的疾患の傾向予測に利用され、がん、感染症、希少疾病などの治療領域において、より個別化された治療法を提供しています。
疾患に関する生物学的データの爆発的な増加は、それを利用し理解する人間の能力をはるかに超えています。これは、オミックスデータを患者のための新しい治療法や診断に活用しようとする科学者や臨床医にとって、大きな課題となっています。オミックスデータのサイズ、急速な蓄積、複雑さ、多様性は、お客様が既存ツールやシステムでそれらを利用することを困難にしています。また、このようなデータは、プライバシー、セキュリティ、データの所有権と管理、ガバナンス、公平性といった課題も引き起こします。
お客様は、ペタバイト級の生のシーケンスデータを効率的に保存し、インデックスを作成し、保護しなければなりません。次に、このデータを再現性と拡張性のあるパイプラインにより解析および相互運用が可能な形式に処理するために、必要な計算インフラを準備、管理、運用する必要があります。解析ワークフローの一環として、お客様はしばしば個人のゲノムデータを医療記録やリファレンスゲノムデータセットなどの他のデータと組み合わせる必要がありますが、これには多くの手作業によるデータ処理が必要です。このようなデータ処理はエンジニアリングリソースを消費し、エラーが発生しやすく、ペタバイトスケールのオミックスデータに適用可能な形に実装するのは困難です。
Amazon Omics のご紹介

Amazon Omics を利用することで、お客様は、基盤となるサービスがお客様のセキュリティやコンプライアンスをサポートしていることを確認しながら、科学や医療のイノベーションにより多くの時間を割くことができます(詳細は、クラウド内におけるヘルスケアコンプライアンス、クラウド内でのライフサイエンスコンプライアンスをご覧ください)。Amazon Omics は大規模解析と共同研究をサポートし、お客様はインフラストラクチャーのプロビジョニングを気にする必要がなくなります。わずか数回の API コールで、最適化されたクエリー対応フォーマット(例:Apache Parquet)にデータをネイティブに保存することで、複雑な ETL パイプラインのセットアップと実行にかかる時間を短縮することが可能です。
お客様は独自のバイオインフォマティクスワークフローを持ち込むことができ、Amazon Omics がその実行のためのインフラストラクチャーを管理します。これにより、差別化につながらない重労働をさらに減らし、お客様は組み込みのアクセス制御、ロギング、監査証跡機能を備えた安全な環境で運用しながら、HIPAA、GDPR、およびその他の規制に準拠することが可能になります。
その好例として、フィラデルフィア小児病院、G42 Healthcare、C2i といったお客様が、すでに Amazon Omics を使用してオミックスワークフローを強化しています。
「Amazon Omics によって、G42 は、世界をリードするデータガバナンスを備えた、競争力のある展開可能なエンドツーエンドサービスを加速させます。我々は、AWS 上でグローバルにホストされた広範なオミックスデータの管理およびバイオインフォマティクスソリューションを、顧客の手元で活用することができるのです。私たちと AWS のコラボレーションは、単なるデータ以上のものです。それは新たな価値です。」
-Ashish Koshy 氏、G42 Healthcare 社、CEO
「C2i Genomics では、データサイエンティストはクラウドベースの計算ソリューションを活用し、大規模でカスタマイズ可能なゲノムパイプラインを実行させることで、メソッド開発と臨床性能に集中できるようにし、エンジニアリングチームはワークロードの運用、セキュリティ、プライバシー面を担当しています。Amazon Omics により、研究者は自身のドメインのツールや言語を使用することができ、コストやリソース配分を考慮しながらエンジニアリングのメンテナンス作業を大幅に削減することができます。これにより、新機能やアルゴリズム改良の市場投入までの時間や NRE コストが削減されます。」
-Ury Alon 氏、C2i Genomics 社、エンジニアリング担当副社長
Amazon Omics はまた、疾患リスクを理解するためのコントロールデータとして使用できる 1000 ゲノムプロジェクト、疾患の発見への扉を開くために集団の対立遺伝子頻度をもたらすゲノム集約データベース(gnomAD)、および 60 以上の他のゲノムデータセットなど、AWS 上のオープンデータレジストリで公開されている他のリファレンスデータセットとお客様がお持ちのデータを取り込んで簡単に組み合わせることができるようにします。
Amazon Omics は、お客様に 3 つのコンポーネントを提供します(図 1)。最初のコンポーネントは、生の配列データを効率的、安全、かつ低コストで保存、発見、共有するためのオミックス専用オブジェクトストレージ (Omics Storage) です。2 つ目のコンポーネントはOmics Workflows で、Omics Storage または S3 のいずれかに格納された生配列データを処理する再現可能なバイオインフォマティクスワークフローを大規模に実行することができ、ワークフロー実行に関連する差別化につながらない重労働をすべて取り除きます。そして 3 つ目のコンポーネントが Omics Analytics で、クエリーに対応したバリアント(またはミューテーション)とアノテーションによって分析を簡素化します。これらのコンポーネントは一緒に使用されることが多いのですが、単独で利用することも可能です。それぞれのコンポーネントの詳細については、以下のセクションで説明します。
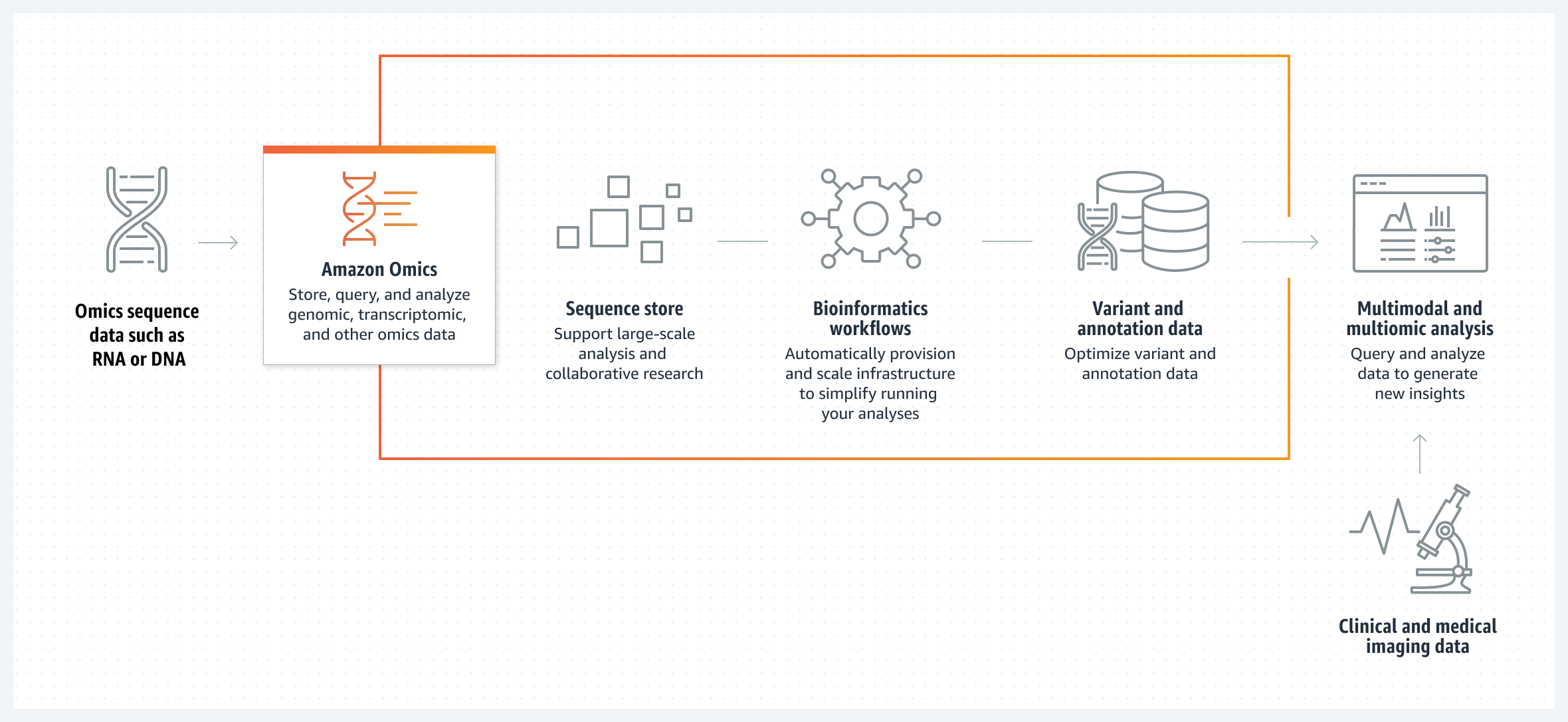
図 1 – Amazon Omics: ストレージ、ワークフロー、分析にまたがる仕組み
費用対効果の高い、オミックス専用オブジェクトストレージ
Amazon Omics は、リファレンスデータやシーケンスデータに対して、費用対効果の高いオミックス専用ストレージのオプションを提供し、生のシーケンスデータ(BAM、CRAM、FASTQ など)を保存する際の総所有コスト(TCO)を削減することが可能です。また、属性ベースのアクセス制御とドメイン固有の検索可能なメタデータの組み合わせにより、データの共有とガバナンスを促進します。
Amazon Omics には、すぐにアクセスできるデータ用の active と、オミックスデータを低コストで長期保存できる archive の 2 つのストレージクラスがあります。自動アーカイブはデフォルトで有効になっており、Amazon Simple Storage Service(Amazon S3)の Intelligent-Tiering ストレージクラスと同様に、定期的に(30 日以上)アクセスされない場合、Amazon Omics が自動的にデータをより安価なストレージクラスに移動し、お客様のコスト削減につながります。
重要なのは、すべてのシーケンサーは 1 回のランあたりの出力ギガベースで評価され(例えば、ヒトゲノムは 30 億塩基対、3 ギガベースペア)、お客様は通常、検査ごとにギガベース単位で臨床パネルを設計するため、我々はこれに従い、Amazon Omics ストレージは取り込まれたギガベース数ごとに設計しました。これにより、年間数十万ゲノムに達する大規模な生シーケンスデータの最適なストレージが確保されます。さらに、ショートリードやロングリードなど、あらゆるシーケンシングプラットフォームやテクノロジーを選択できる柔軟性と、異なるシーケンシングプラットフォーム間でののストレージコストの変動を心配することのない価格の予測性をお客様に提供します。
再現可能なワークフローを実行するためのスケーラブルなコンピュート
Amazon Omics は、再現可能なバイオインフォマティクスワークフローを実行するためのマネージドコンピュートリソースを提供します。これは、Amazon Omics ストレージまたは Amazon S3 から大量の生の配列データを抽出し、少量の分析データ(バリアントとして知られるゲノム変異や遺伝子発現量など)に変換する一連のタスクのスクリプトを含んでいます。結果、ワークフローを大規模に実行・管理することに付随する、差別化につながらない重労働をすべて取り除くことができます。
お客様は、Nextflow や Workflow Description Language(WDL)など、様々なバイオインフォマティクスワークフロー言語で書かれたスクリプトと、対応する Docker イメージを実行できます。お客様は各タスクごとに必要なコンピュートリソース(vCPU とメモリ)を指定します。Amazon Omics は、ワークフローを実行するためのリソースのスケジューリングとプロビジョニングを管理し、再試行を管理し、共有ファイルシステムをプロビジョニングします。
Amazon Omics では、Run Group を定義することにより、特定のワークフローとユーザーの最大同時実行数を制限できるため、お客様はコストを管理し、複数のプロジェクトを追跡することができます。Run のメトリクスとログは、Amazon Cloud Watch または Amazon Omics コンソールからアクセスできます。Amazon Omics は、与えられた入力に対して実行されたワークフロー、その実行から生成された出力を追跡することで、データの出所と系統を追跡することも可能です。
クエリ対応のバリアントデータとアノテーションデータによる解析の簡素化
DNA シーケンシング解析の出力は、バリアントコールファイル(VCF)およびゲノムバリアントコールファイル(gVCF)の形の生のゲノムバリアントです。お客様はこれらのバリアントをクエリし、アノテーションデータによって意味付けをすることで臨床的な意義を特定したいと考えています(たとえば、癌を引き起こすタンパク質を生成する欠陥遺伝子をもたらすバリアントを特定するなど)。しかし、これらのテキストベースの VCF は、その半構造化された性質上、クエリに最適化されているとは言えません。ゲノムは個人レベルで分析されるかもしれませんが、多くのお客様は、多くの遺伝子にまたがる数千のバリアント(それ以上でないとしても)を一度にクエリすることで、対応する臨床データとの関係から、ゲノムの変異が人類の健康にどのように影響し臨床結果を予測するかを理解しようとしています。
Amazon Omics は、お客様が VCF を Variant Store にインポートし、クエリ対応スキーマである Apache Iceberg Table として利用可能な形にシームレスに変換することで、これらの課題に取り組みます。また、変異アノテーションを Annotation Store にインポートすることも可能です。お客様は、AWS Lake Formation を通じてアクセスを管理し、きめ細かなアクセス制御を適用して、個々の患者レベルでフィルタリングすることができます。これにより、データをコピーすることなく、カスタム患者コホートを定義し、GDPR などのコンプライアンス体制対応のための患者の同意の管理をご支援します。また、Amazon Athena を使用してこれらのバリアントのクエリーと分析を行い、Amazon HealthLake やお客様の AWS Glue Data Catalog にある臨床データなど、他のモダリティからのデータを結合することができます。
Amazon QuickSight は、特定の変異や Amazon HealthLake での臨床観察など、さまざまな属性に基づいて患者のコホートを定義するためのビジュアルインターフェースとして使用できます。Amazon SageMaker は、このコホートに対して、患者の疾患リスクや特定の薬剤の全体的な効果などの AI 駆動型予測のための多くの機械学習モデルを、迅速かつ効率的に構築し展開するために使用することができます。
Amazon SageMaker は、このコホートに対する多くの機械学習モデルを迅速かつ効率的にビルド・デプロイし、患者の疾患リスクや特定の薬剤の全体的な効果を AI 駆動で予測することができます。
AWS パートナーとの連携による高速化
AWS パートナーソリューションとサービスによる、Amazon Omics を活用したゲノム、トランスクリプトーム、その他のオミックスデータ向けのスケーラブルなマルチモーダルソリューション構築のためのお客様へのご支援が可能です。AWS パートナーである Lifebit 社は、世界中のバイオメディカルデータを接続し、新たな治療に関するインサイトを得ることを使命としています。Amazon Omics の導入により、Lifebit 社は、大規模データに対して最適化された分析およびストレージへのアクセスを含む、さらに拡張性の高いバイオインフォマティクスソリューションを提供できるようになります。
Ovation のような他の AWS パートナーにとって、Amazon Omics バリアントストアを使用することは、研究者がより迅速かつ大規模にゲノムデータにアクセスすることを支援します。
更なる詳細は Amazon Omics Partners をご覧ください。
まとめ
お客様とパートナー様と共に、私たちは、研究者、データサイエンティスト、臨床医が対象の疾患に対し、より正確な治療で人々の健康を改善することを可能にし、目的特化型の機能で、来るべき時代の診療をモダナイズする大きな機会があります。Amazon Omics は、お客様が専用のツール、ワークフロー、インフラを設定・維持する必要性を排除することで、エンドツーエンドのオミックスの保存、処理、分析を可能にします。AWS Lake Formation や Amazon Athena などの分析サービスとネイティブに統合することで、Amazon Omics は、マルチモーダルデータレイクの一部であるオミックスデータに対する管理およびガバナンスを維持できるようにします。数回の API コールで、お客様は再現可能な本番運用レベルのインフラストラクチャを導入し、イノベーションと医学的洞察を得るまでの時間を加速できます。このブログの Part 2 では、これを実現するためのリファレンスアーキテクチャをご紹介します。
Amazon Omics のドキュメントで始めることもできますし、弊社のウェブページで詳細を知ることもできます。
本ブログは、ソリューションアーキテクトの高橋が翻訳しました。原文はこちらです。

Tehsin Syed
Tehsin Syed は、Amazon Comprehend Medical や Amazon HealthLake などを含む、Amazon Web Services の Health AI エンジニアリングおよび製品開発の責任者です。Amazon Web Services のエンジニアリング、サイエンス、プロダクト、テクノロジーを担当するチームと協力し、画期的なヘルスケアおよびライフサイエンス AI ソリューションとプロダクトを開発しています。AWS 勤務以前は、Cerner Corporation でエンジニアリング担当副社長を務め、ヘルスケアとテクノロジーの領域で 23 年間を過ごしました。

Taha Kass-Hout
Dr. Taha Kass-Hour は、Amazon Web Services の副社長兼最高医学責任者 (CMO) で、Amazon Comprehend Medical や Amazon HealthLake などの Health AI 戦略と取り組みを主導しています。COVID-19 臨床試験のため、科学、技術、規模の開発を担当する Amazon のチームと連携しており、Amazon が初めて FDA に認可されたアソシエイト向け検査(現在は一般家庭での検査を提供)を含みます。医師でありバイオインフォマティシャンでもある Taha は、オバマ大統領の下で 2 期務め、FDA の初代 Chief Health Informatics officer にも就任しました。任期中、Taha は新興技術やクラウド利用 (アメリカ疾病予防管理センター: CDC の電子疾病監視) を先導し、また、研究者や一般市民が有害事象データを検索・分析できる openFDA や、PrecisionFDA(Presidential Precision Medicine initiative の一部)といった、広くアクセス可能なグローバルデータ共有プラットフォームを確立しました。