Amazon Web Services ブログ
Part 4: NatWest GroupによるAmazon SageMakerアーキテクチャーへのMLモデルのマイグレーション
この記事は Part 4: How NatWest Group migrated ML models to Amazon SageMaker architectures を翻訳したものです。
NatWest Group のAWSクラウドテクノロジーの採用は、自社の顧客に対する最適なプロダクト・サービスの提供までに必要な時間を削減しながら、MLワークロードをさらに堅牢かつスケーラブルなソリューションに移行できるようになったことを意味します。
NatWestはクラウド導入のジャーニーにおいて、AWSにマイグレーションするユースケースとして、カスタマーライフタイムバリュー(Customer Lifetime Value, CLV)モデルを選択しました。このモデルは、顧客に対する理解を深め、パーソナライズされたソリューションの提供を支援します。CLVモデルは、一つのパイプラインとして結合された、連続する複数の異なるMLモデルから構成されます。処理が必要なデータの量を鑑みると、スケーラブルなソリューションが必要となります。
本ブログ記事は、英国最大の金融機関の一つである NatWest Group がAWS Professional Services との協業を通じて実現したMLOps基盤プロジェクトについて解説した4つの記事からなるシリーズの最後の記事です。本記事は、Amazon SageMakerを用いた複雑なソリューションの構築方法について理解したい、MLエンジニア、データサイエンティスト、およびエグゼクティブに向けた内容です。本記事では、スターターとなるいくつかのコードテンプレートを活用し、素早くかつ再現性のある方法で複雑かつスケーラブルなユースケースを提供する方法を説明することにより、SageMakerのプラットフォームが持つ柔軟性を実証します。
シリーズ全体の記事はこちら:
|
課題
NatWest Groupは、規制を守りながら顧客を喜ばせるというミッションのもと、MLワークロードの導入と本番稼働に向け、標準化された安全なソリューションをAWSと共同で構築しています。以前のMLワークロードの実装では、データがサイロ化しており、環境のスピンアップとスピンダウンに長いリードタイムが必要でした。また、計算リソース活用の非効率性にもつながっていました。これらの課題を改善するため、AWSとNatWestの協業により、AWSサービスを活用したMLプロジェクトおよび環境のテンプレートを複数開発しました。
NatWest Groupは、リテール、ウェルス、コマーシャルの各事業において、銀行に対するお客様のニーズの予測と適応のため、MLの活用により新たなインサイトを導き出しています。また、MLモデルの開発とプロダクションへのデプロイの際には、銀行が設けるコンプライアンス基準を満たすため、数多くの事項について考慮する必要があります。これらの事項には、モデルの説明性、バイアス、データ品質、ドリフトモニタリングなどが含まれます。本協業を通じて開発されたテンプレートには、これらの事項の評価を行う機能が導入されており、NatWestのチームではこれらのテンプレートを、SageMakerを用いた安全なマルチアカウント設定でのユースケースの導入と実用化を行うために活用しています。
テンプレートには、SageMakerのMLOps機能を使用したAWSベストプラクティスの導入により、MLワークフローの実用化に必要な基準が埋め込まれています。また、Amazon Simple Storage Service (Amazon S3) を経由した、AWS MLサービスのためのセルフサービス型の安全なマルチアカウント基盤へのデプロイメントも複数含まれています。
これらのテンプレートにより、NatWestのチームは以下の機能を実現することができます:
- NatWestのMLOps成熟モデルに合わせた機能の構築
- SageMakerサービスのMLOps機能に関するAWSベストプラクティスの実装
- 実用化可能なMLワークフロー開発のための標準テンプレートの構築と活用
- マネージドアプローチによるプロジェクト環境のスピンアップとスピンダウンに必要な時間の削減
- プロセスの標準化、自動化、オンデマンドコンピュートによるメンテナンスコストの削減
- 既存のコードを機能ごとに分割し、オンデマンド側のクラウドアーキテクチャを活用しながらコードのリーダビリティの改善と技術的負債の解消を可能にするコードのプロダクション化
- Proof-of-Concept (PoC) およびユースケース開発の継続的統合・デプロイメント、PoCならびにユースケース開発のための学習、および追加のMLOps機能(モデルモニタリング、説明性、条件ステップ)の実現
以降のセクションでは、NatWestがテンプレートを用い、既存プロジェクトのマイグレーション、および新規プロジェクトの開発を実現した方法について解説します。
カスタムSageMakerテンプレートとアーキテクチャ
NatWestとAWSは、既存のSageMakerプロジェクトテンプレートの機能を用いてカスタマイズされたテンプレートを構築し、プロダクション環境へのデプロイのため、インフラテンプレートと統合しました。このセットアップには、学習と推論のためのサンプルとなるパイプラインが含まれており、NatWestのユーザがマルチアカウントデプロイメントをすぐに活用できるようにしています。
このマルチアカウントのセットアップは、開発環境のセキュリティを維持しながらプロダクションに近い環境でのテストを可能にします。したがって、プロジェクトチームはMLワークロードに注力することができます。プロジェクトテンプレートは、インフラ、リソースプロビジョニング、セキュリティ、監査可能性、再現性、および説明性に対応します。また、ユーザがそれぞれのユースケースの要件に合わせて、テンプレートの拡張を可能にする柔軟性も備えています。
ソリューション概要
NatWestでユースケースチームを立ち上げるためには、NatWestによって開発された、AWS Service Catalogで提供されるテンプレートに基づき、以下のステップを経る必要があります。
- プロジェクトオーナーが新たなAWSアカウントを準備し、オペレーションチームが新しいアカウントにMLOpsの前提となるインフラをセットアップ
- プロジェクトオーナーがAWS Service Catalogを使用し、Amazon SageMaker Studioのデータサイエンス環境を構築
- データサイエンティストのリードが新しいプロジェクトを立ち上げ、AWS Service Catalogで提供されるテンプレートを使用してSageMaker Studioユーザを作成
- プロジェクトチームがプロジェクトに関する作業を行い、ユースケースに合わせてテンプレートのフォルダ構造を更新
以下の図に、我々がCLVユースケースに合わせて適応されたテンプレートのアーキテクチャを示します。開発環境の中で、複数の学習パイプラインが構築され、実行される様子が描かれています。デプロイされたモデルは、プリプロダクションおよびプロダクションの各環境でのテストと実用化が可能です。

CLVモデルは、複数のツリーベースのモデルと、これらからの出力をすべて結合する推論セットアップを含むモデルのシーケンスです。このMLワークロードで使用されるデータは、さまざまなソースから収集され、5億行以上、約1,900個の特徴量に及びます。プロセッシング、特徴量エンジニアリング、モデル学習、およびオンプレミスでの推論タスクは、全てPySparkまたはPythonで実行されています。
SageMaker パイプラインテンプレート
CLVは、順番に構築された複数のモデルによって構成されています。各モデルからの出力は別のモデルへの入力になるため、それぞれのモデルに特化した学習パイプラインが必要となります。Amazon SageMaker Pipelines では、SageMakerのモデルレジストリを用い、複数のモデルを学習・登録することができます。各パイプラインでは、プロセッシング、特徴量エンジニアリング、およびモデル学習の論理コンポーネントはそのままに、既存のNatWestのコードをSageMaker Pipelinesに合わせてリファクタリングしています。
さらに、推論を連続して実行するためのモデルのコードは、推論に特化した一つのパイプラインにリファクタリングされています。したがって、このユースケースは複数の学習パイプラインと、一つの推論パイプラインで構成されます。
各学習パイプラインにより、それぞれのMLモデルが作られます。このモデルをデプロイするためには、モデル承認者(NatWestのMLユースケースのために定義されたロール)による承認が必要になります。デプロイされた後のモデルは、SageMaker推論パイプラインで利用できます。この推論パイプラインは、新しいデータに対し、一連の学習されたモデルを適用します。推論はバッチ処理で実行されており、各推論の結果を組み合わせることにより、各顧客の最終的なライフタイムバリューが算出されます。
このテンプレートは、以下のステップからなる標準的なMLOpsの例です:
- PySparkプロセッシング
- データ品質とデータバイアスの検証
- モデル学習
- 条件
- モデル作成
- モデル登録
- 変換
- モデルのバイアス、説明性、品質の検証
このパイプラインは、Part 3の記事「Amazon SageMakerを用いたNatWest Groupでの監査・再現・説明可能なMLモデルの構築」でより詳しく説明されています。
以下の図は、テンプレートによって提供されたサンプルパイプラインの設計を表しています。

データは、前処理を経て、学習、検証、評価の各データセットに分割し(Processing Step)、その後、モデル学習(Training)で使われます。モデルがデプロイ(Create Model)された後、バッチ推論による予測(Transform)で使用されます。予測の結果は、後処理を経てAmazon S3に格納されます(Processing)。
データ品質およびデータバイアス検証により、学習で使われるデータに関するベースラインの情報が提供されます。モデルバイアス、説明性、品質の検証では、テストデータに対する予測結果に基づき、モデルのふるまいを検証します。これらの情報は、モデル評価のメトリクス(Processing)とともにモデルレジストリで表示されます。モデルは、過去に最適とみなされたモデルに対し、特定の条件を満たした場合にのみ登録されます(Condition step)。
パイプラインの実行時に生成されるアーティファクトとデータセットは、テンプレートのプロビジョニングの際に自動的に作られたAmazon S3のバケットに保存されます。
パイプラインのカスタマイズ
既存のコードベースの論理コンポーネントを確実にマイグレーションするためには、テンプレートをカスタマイズする必要がありました。
我々は、 LightGBM フレームワークを使用してモデルを構築しています。このユースケースで構築した最初のモデルの一つは、モデル学習時に特定の特徴量の分割を行うためのシンプルな決定木でした。さらに、特定の特徴量に基づき、データを分割する処理も行っています。これらの処理を実装するため、二つの異なる決定木モデルの学習を行う必要がありました。
決定木では、数値予測とクラス分類の二つの種類の予測を行うことができます。我々のケースでは、モデル評価のためのカスタムメトリクスの算出のためにテストデータに対する数値予測を用い、推論ではクラス分類を使用しています。
以上の処理に対応するため、テンプレートから提供された学習と推論の各パイプラインに対する仕様の追加が必要となりました。ユースケースのモデルがもたらす複雑さへの考慮と、テンプレートの柔軟性を示すため、パイプラインに新たなステップを追加し、さらに必要なコードを適用するためにこれらのステップをカスタマイズしています。
以下の図に、アップデートされたテンプレートを示します。この図から、推論パイプラインに転送するモデルを、必要な数だけデプロイできる様子がわかります。
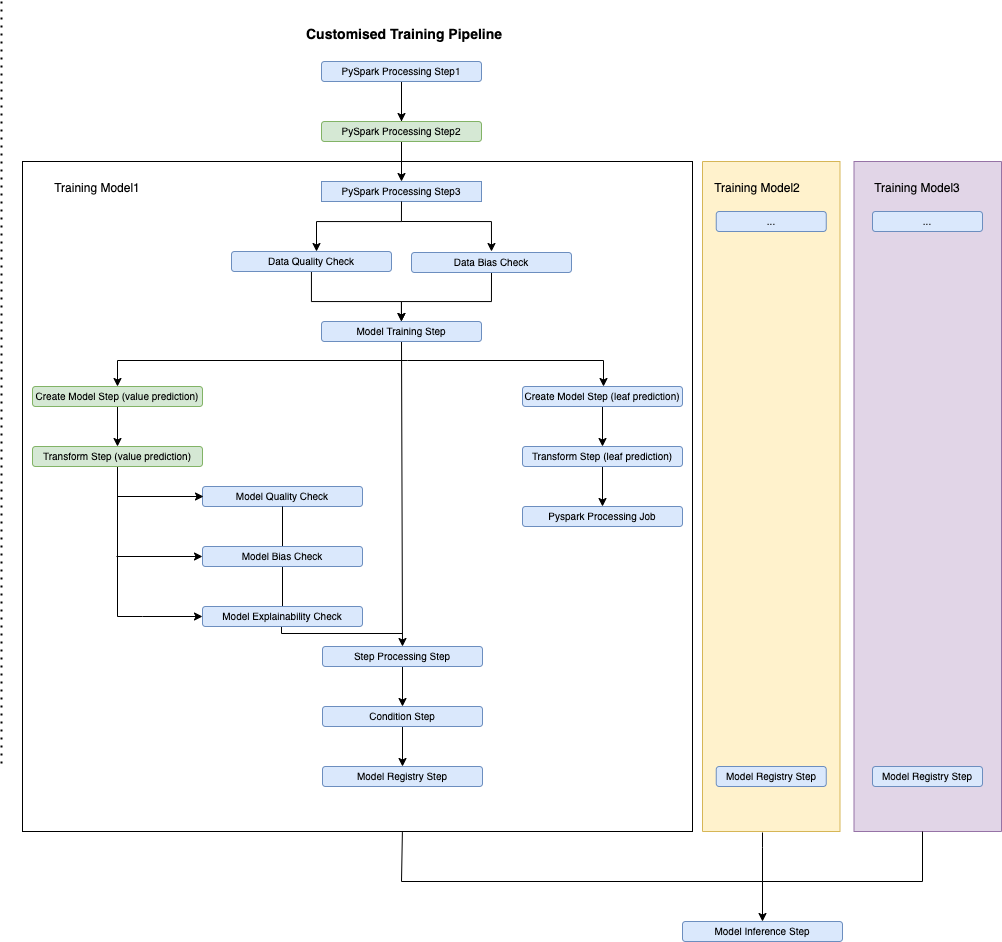
我々の最初のモデルでは、ビジネス知識に基づき、与えられた特定の特徴量に基づいてデータを分割します。この学習パイプラインでは、各データセットに対し、2つの異なるLightGBMモデルを登録する必要がありました。
この2つのモデル学習のためのステップはほぼ同じものでした。したがって、最初のプロセッシングステップ以外の全てのステップを、分割された各データセットに対して2回ずつ実行しています。さらに、各モデルのユニークなデータセットに対応するため、2つ目のプロセッシングステップが適用されています。
以降のセクションにて、カスタマイズされたステップについてそれぞれ詳しく説明します。
プロセッシング
各プロセッシングステップにはプロセッサーインスタンスが割り当てられ、SageMakerのプロセッシングタスクの実行を担います。このユースケースでは、Pythonコードの実行のため、2種類のプロセッサが使用されています:
- PySpark プロセッサ – PySpark プロセッサが割り当てられたプロセッシングジョブでは、それぞれのSparkコンフィグレーションを用いてジョブを最適化します
- Script プロセッサ – 本ユースケースの既存のPythonコードを用い、提供された実データと予測結果に基づきカスタムメトリクスを生成し、後にモデルレジストリで閲覧できるように出力フォーマットを整えます(JSON)。ここでは、テンプレートによって生成されたカスタムイメージを使用します。
各ユースケースでは、学習パイプラインのニーズに合わせて、インスタンスタイプ、インスタンス数、Amazon Elastic Block Store (Amazon EBS) のボリュームサイズ(GB)を修正することができます。さらに、テンプレートによって生成されたカスタムコンテナイメージを適用し、必要に応じてデフォルトライブラリを拡張することもできます。
モデル学習
SageMaker トレーニングステップは、さまざまなMLフレームワークにおけるマネージドな学習と推論を支援します。我々のケースでは、Amazon ECR から提供されたカスタム Scikit-learn イメージと Scikit-learn Estimator を組み合わせて、2つのLightGBMモデルの学習を行います。
以前の決定木モデルの設計には複雑なカスタムクラスが含まれており、フィルタリングされたデータスライスごとに別の決定木をフィットさせることで簡素化する必要がありました。そこで、各モデルに必要なパラメータと入力データが異なる2つの学習ステップを実装することで、これを実現しました。
条件
SageMaker Pipelinesの条件ステップは、ステップ実行時の条件分岐をサポートします。条件リストの中の条件が全て True の場合、各 if ステップに実行可能なマークが付与されます。これ以外の場合、各 else ステップに実行可能のマークが付与されます。我々のユースケースでは、二つの条件ステップ (ConditionLessThan) を使用し、各モデルの現状のカスタムメトリクス(たとえば、あるテストセットに対する平均絶対誤差)が所定の性能閾値を下回っているかを確認します。この確認により、モデルの品質が許容可能と判断された場合にのみ、モデルを登録します。
モデル作成
モデル作成ステップは、推論タスクで活用可能なモデルを提供するとともに、予測結果を生成するためのコードを継承します。我々のユースケースでは、数値予測とクラス分類が2つのモデルでそれぞれ必要となるため、学習パイプラインには4つのモデル作成ステップが作られます。
各ステップには、後続の変換ステップに与えられたデータに基づく予測の種別(数値予測、クラス分類)に応じたエントリポイントファイルが提供されます。
バッチ変換
個々のバッチ変換ステップは、モデル作成ステップで作られたモデルを利用して予測結果を返します。我々のケースでは、作成されたモデルごとに変換ステップがあるため、合計4つの変換ステップが存在します。各ステップは、それぞれのモデルについてクラス分類または数値予測の結果を返します。この出力は、パイプラインの次のステップに応じてカスタマイズされます。たとえば、数値予測のための変換ステップは、パイプラインで次に続くモデル検証ステップにそれぞれ必要な入力を作成するための出力フィルタを有しています。
モデル登録
最後に、各学習パイプラインの中のモデル分岐にはそれぞれに特化したモデル登録ステップがあります。標準的なセットアップと同様、それぞれのモデル登録ステップでは、全ての検証ステップ(品質、説明性、バイアス)からの情報とともに、カスタムメトリクスとモデルアーティファクトなど、各モデルに特化した情報を受け取ります。そして、各モデルはそれぞれユニークなモデルパッケージグループとして登録されます。
本ユースケースに特化した変更をサンプルコードベースに適用した後、パイプライン実行時の各パイプラインステップのキャッシュコンフィグレーションを使用することにより、デバッグ体験を補強しています。このようなキャッシングステップは、コストとパイプライン検証の時間を削減できるため、SageMakerパイプラインの構築時には有用です。
得られたベネフィット
AWSとNatWestの協業は、SageMakerパイプラインを通じたMLモデルの実装とMLOpsベストプラクティスにおけるイノベーションをもたらしました。現在、NatWest Groupは、柔軟なカスタムテンプレートを通じ、標準化されたセキュアなソリューションを活用してAWSへのMLワークロードの実装と実用化を行っています。本記事で紹介したモデルのマイグレーションによるビジネスベネフィットは運用開始当初から複数確認され、現在も継続しています。
第一のベネフィットは、標準化による複雑さの軽減です:
- 再利用可能なソリューションを作るため、サードパーティーのカスタムモデルを高度なモジュール方式でSageMakerと統合することができます。
- テンプレートを用いた非標準的なパイプラインの構築が可能です。また、これらのテンプレートは標準化されたMLOps実用環境でサポートされています。
また、ソフトウェアおよびインフラのエンジニアリングにおいても、以下のベネフィットを確認しています:
- 個別のユースケースに応じてテンプレートのカスタマイズができます
- 元のモデルコードを機能ごとに分割・リファクタリングすることにより、ソリューションの再構築、レガシーコードによる顕著な技術的負債の解消、マネージドなオンデマンド型の実行環境へのパイプラインの移行を可能とします
- 標準テンプレートを通じて追加の機能を活用することにより、モデルの説明性のアップグレードと標準化の実現と、データとモデルの品質およびバイアスの検証が可能になります
- NatWestのプロジェクトチームは、ほぼ完全なセルフサービス環境で、環境のプロビジョニング、モデルの実装と実用化を行うことができます
最後に、以下のような生産性の改善と運用コストの低減効果も確認しています:
- MLプロジェクト実用化までの時間削減 – 標準コード、ユニットテスト、および実用化可能なユースケース開発のためのCI/CDパイプラインをプロジェクトの初期段階から活用し、プロジェクトを開始することができます。この新たな標準化により、今後のユースケースの導入時間についても削減が期待できます。
- クラウド上でのMLワークフロー実行コスト削減 – マネージドアーキテクチャを用いたデータ処理とMLワークフローを実行が可能になりました。また、標準テンプレートを用いることにより、アーキテクチャーを支えるインフラをユースケースの要件に適応させることができます。
- プロジェクトチーム間のコラボレーション増加 – モデル開発の標準化により、個々のチームが開発したモデル機能の再利用性が向上しています。これにより、開発とオペレーションのそれぞれにおいて継続的に戦略を改善する機会が生まれます。
- 境界のないデリバリー – 本ソリューションにより、伸縮性のあるオンデマンドインフラを24時間365日利用できるようになりました。
- 継続的なインテグレーション、デリバリー、テスト – 開発完了から本番稼働までのデプロイメント時間の短縮により、以下のメリットが生まれます:
- インフラとソフトウェアのコンフィグレーションを、モデルの学習・推論の実行時間に合わせて最適化できます。
- プロセス、自動化、オンデマンドコンピュートの標準化により、運用コストの削減が可能です。そのため、本番環境では再学習と推論の実行コストは月に一度のみ発生します。
結論
AWSのイノベーションリーダーシップによる支援のもとでSageMakerを活用することにより、NatWestではML生産性の好循環を作ることができました。本プロジェクトの成果として得られたテンプレート、モジュール型の再利用可能なコード、および標準化プロセスは、既存のデリバリーの制約からプロジェクトチームを解放しています。さらに、MLOpsの自動化はサポート業務を軽減しており、各チームは他のユースケースやプロジェクトや、既存のモデルやプロセスの改善などの業務に取り組むことを可能としています。
本記事は、NatWest GroupとAWS Professional Servicesの戦略的協業に関する4本の記事から構成されるシリーズの4本目にあたります。本シリーズの他の記事もご参照ください: