Amazon Web Services ブログ
Kinesis Firehoseを使用してApache WebログをAmazon Elasticsearch Serviceに送信する
Elasticsearch、Logstash、および、Kibana(ELK)スタックを所有して運用する多くのお客様が、他の種類のログの中でもApache Webログを読み込んで可視化しています。 Amazon Elasticsearch Serviceは、AWSクラウドにElasticsearchとKibanaを提供しており、セットアップと運用が簡単です。 Amazon Kinesis Firehoseは、Amazon Elasticsearch ServiceにApache Webログ(またはその他のログデータ)をサーバーレスで確実に配信します。
Firehoseを使用すると、Firehose内のレコードを変換するAWS Lambda関数への自動呼び出しを追加できます。これらの2つのテクノロジーを使用すると、既存のELKスタックを効果的かつ簡単に管理することができます。
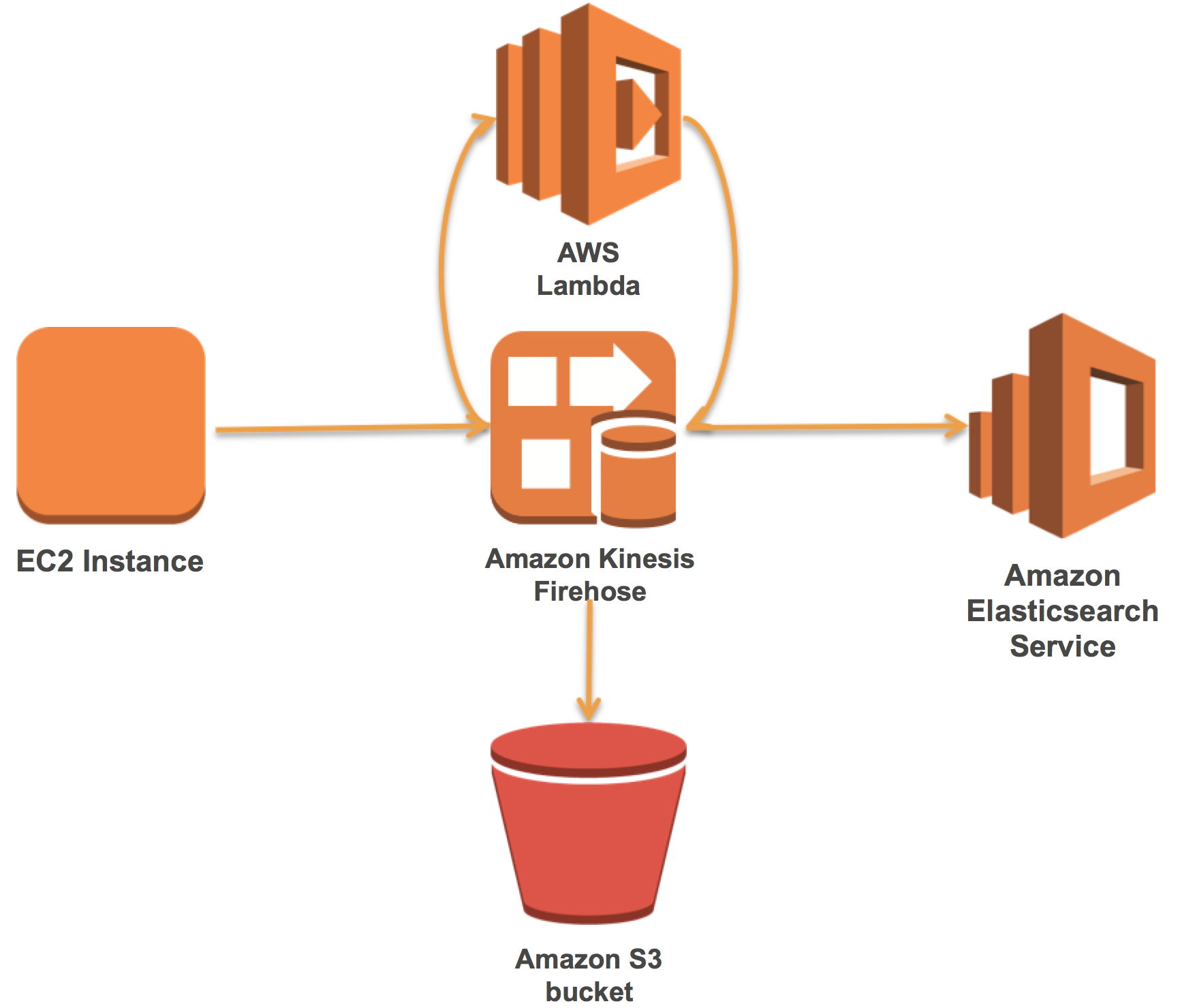
この記事では、最初にAmazon Elasticsearch Serviceドメインを設定する方法を説明します。次に、事前ビルドされたLambda関数を使用してApache Webログを解析するFirehoseストリームを作成して接続する方法を示します。最後に、Amazon Kinesis Agentでデータをロードし、Kibanaで可視化する方法を示します。
Amazon Elasticsearch Serviceドメインを設定する
まず、Amazon Elasticsearch Serviceドメインを設定する必要があります。
このブログ記事の目的のために、私はElasticsearchバージョン5.1ドメインを作成しました。このドメインには、m3.mediumデータインスタンスが1つあり、マスターインスタンスはありません。個別のユースケースにおいては、各ユースケースに一致するデータインスタンスのインスタンスタイプと数を選択して下さい。次のスクリーンショットは、データインスタンスを設定するコンソールページを示しています。
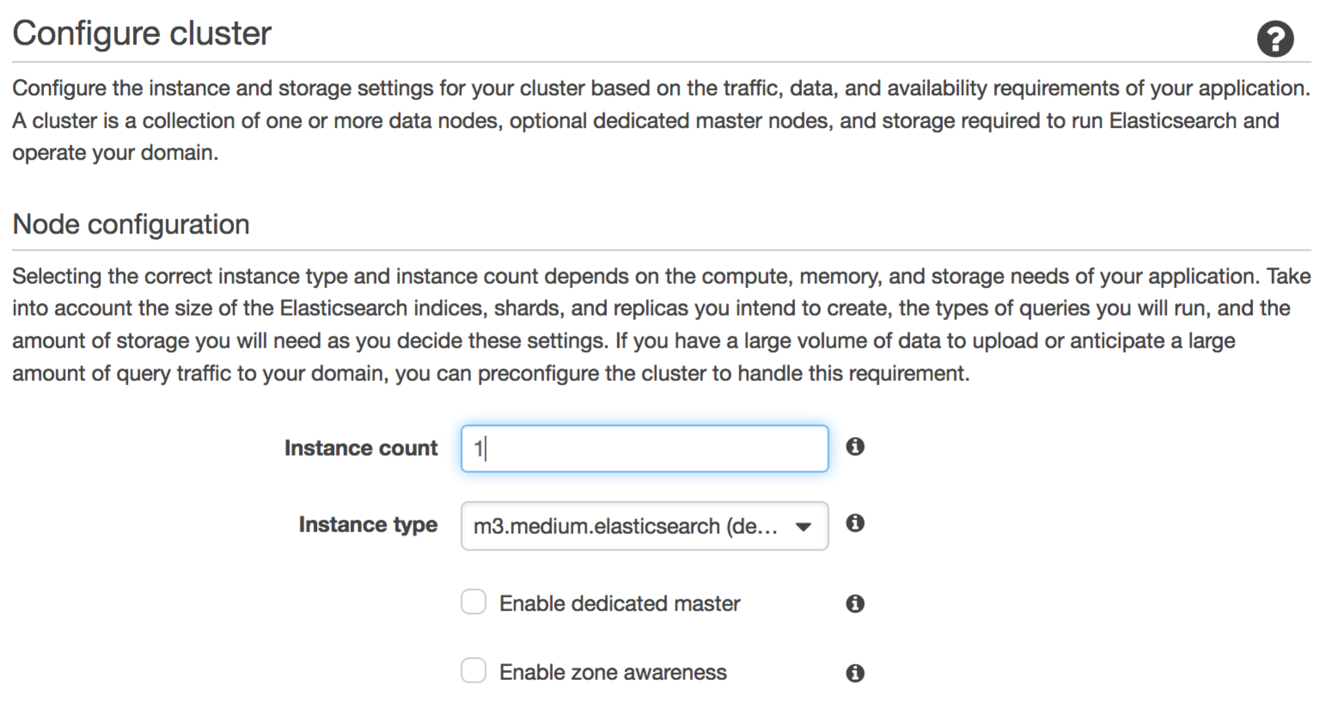
私たちは以前のブログ記事にいくつかのサイジングガイダンスを提供しました。この例では有効にしていませんが、実際のワークロードでは、m3.medium.elasticsearchタイプの3つの専用マスターインスタンスを推奨します。
インスタンス数を設定すると、ドメインへのアクセスを保護するAWS Identity and Access Management (IAM)ポリシーを設定できます。
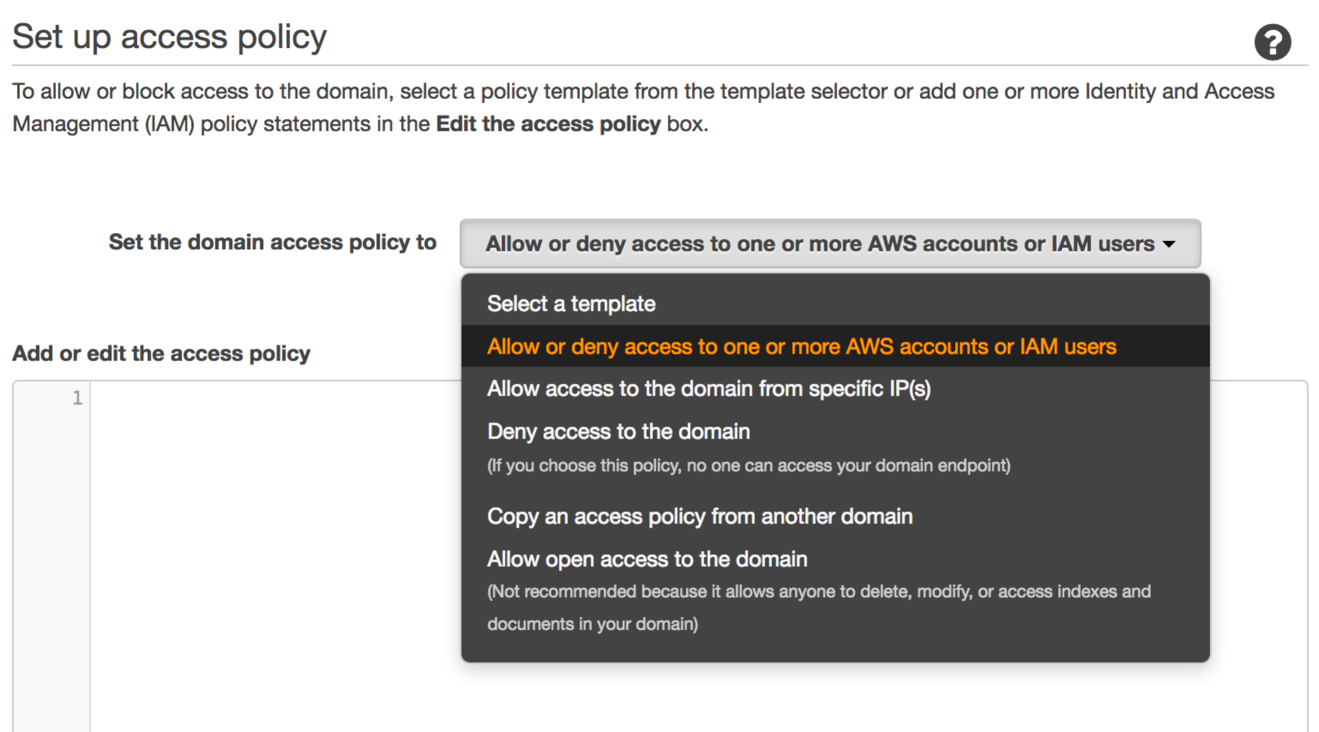
アクセスを制限し、権限のないユーザーがドメイン内のデータを作成、変更、削除することを防ぐポリシーを設定することを強くお勧めします。開始するには、Allow or deny access to one or more AWS accounts for IAM usersを選択し、結果のダイアログボックスにアカウントIDをコピーして貼り付けてください。 Amazon Elasticsearch Serviceドメインのセキュリティ保護に関する詳細については、このブログ記事を参照してください。
Nextを選択し、ドメインを確認して作成します。
ストリームを作成する
次に、Amazon Kinesis Firehoseストリームを作成し、Lambda変換を追加し、作成したばかりのドメインに接続します。 Services、Analytics、Kinesisの順に選択して、Kinesisコンソールに移動します。 Go to Firehoseを選択し、Create Delivery Streamを選択します。
宛先については、Amazon Elasticsearch Serviceを選択します。
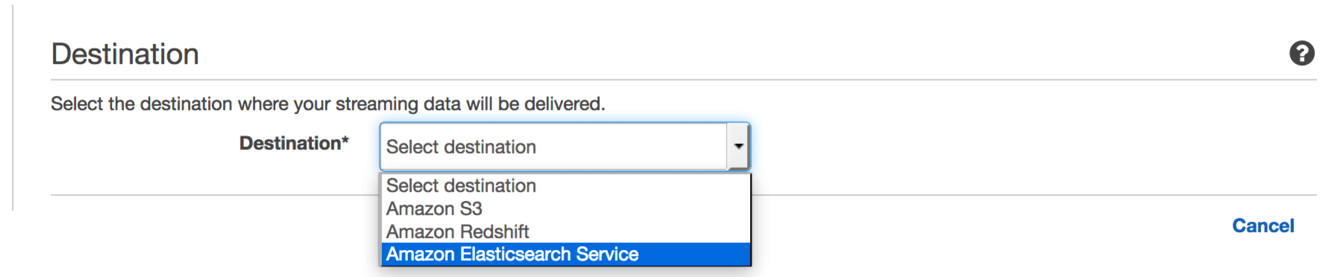
コンソールには、ストリームに名前を付けたり、Amazon Elasticsearch Serviceへの配信を指定したりカスタマイズしたりするためのフィールドが追加されています。
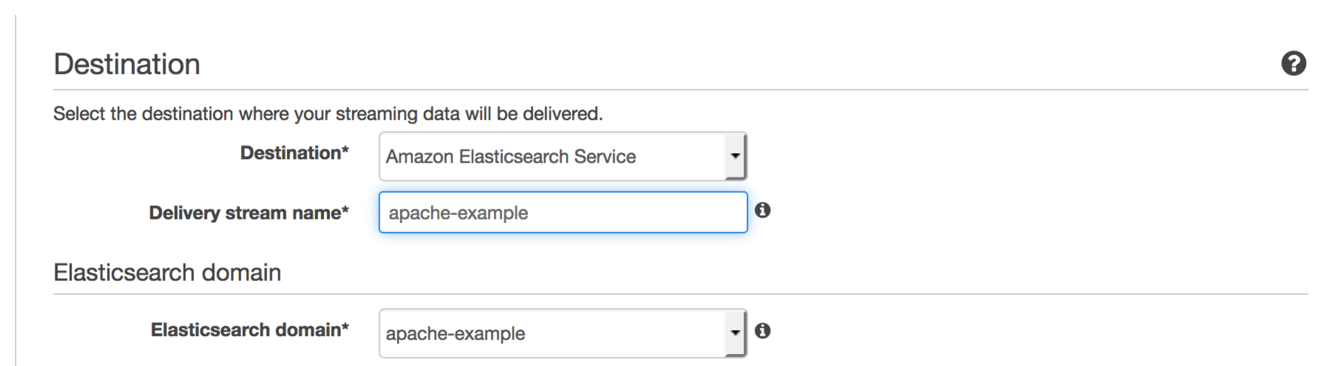
筆者はいつもストリームとAmazon Elasticsearch Serviceドメインを同じ名前にします。一貫性があれば、何が何につながっているのかを理解しやすくなります。次に、Elasticsearch domainで、作成したばかりのドメインを選択します。
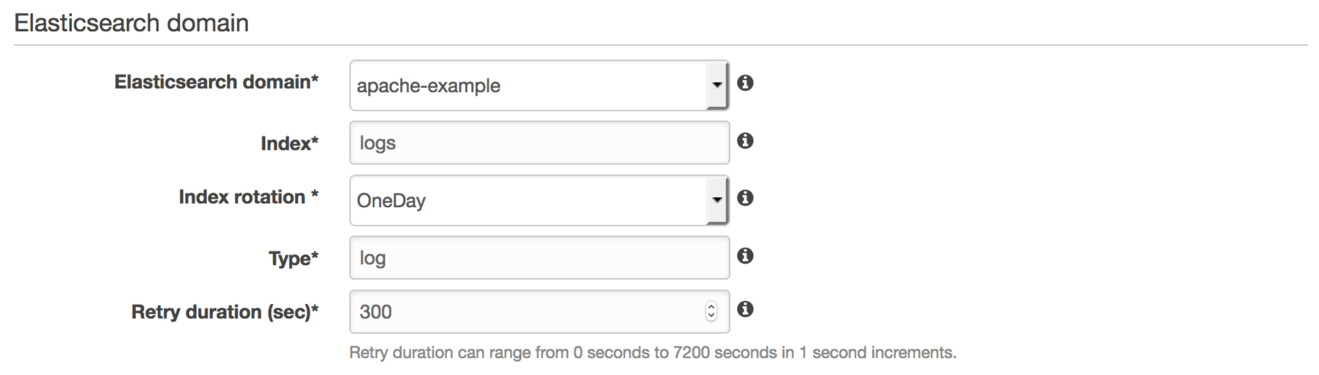
次に、Elasticsearchインデックスパターンを追加して入力します。 Firehoseは、インデックスパターンを使用して、タイムスタンプを付けた新しいインデックスを作成し(たとえば、logs-2017-02-24)、作成したタイプでデータをロードします。 Firehoseは新しいインデックスを作成し、選択したIndex rotation値に基づいてログの配信を回転させます。 OneDayは一般的な選択です。 OneHourは大量のワークロードに適しています。 OneWeekまたはOneMonthは、少量のワークロードに適しています。
Firehose配信ストリームの優れた機能の1つは、レコードのバッチを配信できなかった場合に自動的に再試行することです。 Retry durationでFirehoseが再試行する時間を制御することができます。合理的なデフォルトは300秒です。失敗したレコードを最新の状態に保ちたいという希望に基づいて調整します。
次に、Firehoseが失敗したレコードを配信できるAmazon S3バケットを設定します。

筆者の場合は、既存のバケットを再利用していますが、ウィザードで新しいバケットを簡単に作成できます。複数のワークロードに対して同じバケットを再利用する場合は、S3 prefixの値を使用します。 S3に配信されるすべてのレコードは、そのプレフィックスを使用します。
Firehoseはまた、すべてのログデータのコピーを保持するのに最適な方法です。All documentsを選択するだけで、FirehoseはすべてのレコードをS3およびAmazon Elasticsearch Service(Amazon ES)に配信します。
Nextを選択すると、次のストリーム構成ページが表示されます。
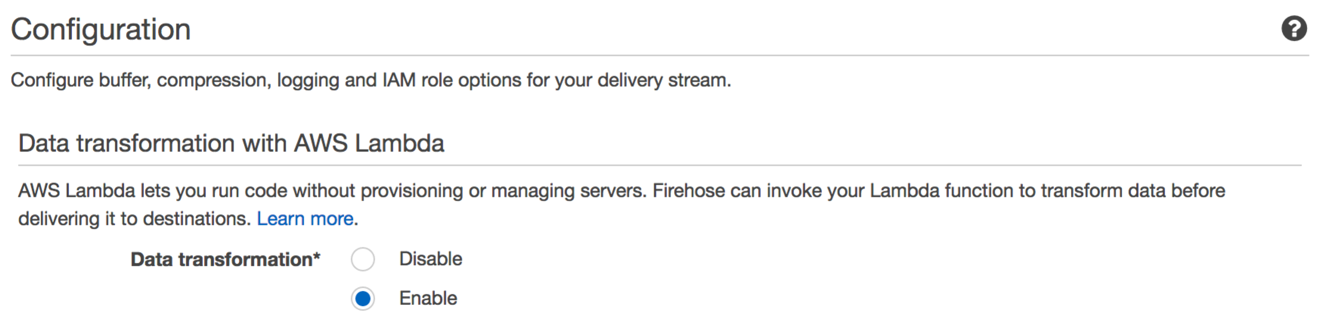
データ変換を無効にすることで、Amazon ESドメインにデータを”そのまま通過させる”(デフォルト)ことができます。データ変換を有効にすると、Firehoseがストリームを通って来る各レコードに対してインラインで呼び出すLambda関数を指定できます。

こちらで定義してあるように、入力と出力を持つ独自の関数を記述することができます。 Firehoseコンソールには、すぐに使用できる多くの既存機能が用意されています。 関数のリストを表示するために(Optional) Create a new Lambda functionを選択し、Apache Log to JSONを選択します。Lambdaコンソールに移動して、コードを入力して関数を作成します。

関数に名前を付けます。 ここでは、FirehoseストリームとAmazon ESドメイン名と同じ名前を使用します。
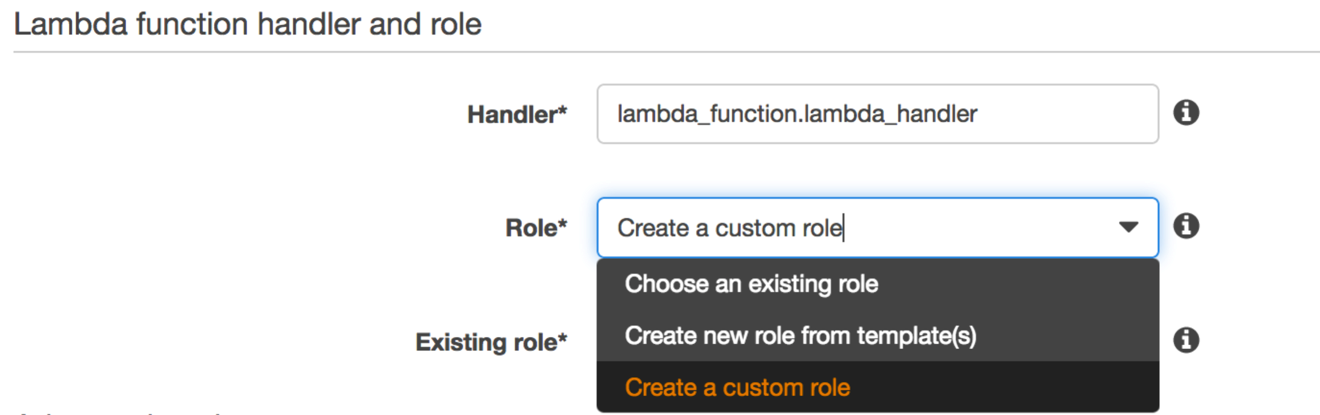
Lambda関数がストリームからデータバッチを受け取るロールを作成する必要があります。作成しているLambda関数は、Amazon ESドメインにアクセスする必要はありません。これは、データをAmazon ESに配信するのではなく、Firehoseに直接応答するためです。RoleでCreate a custom roleを選択します。この選択によりIAMコンソールに移ります。
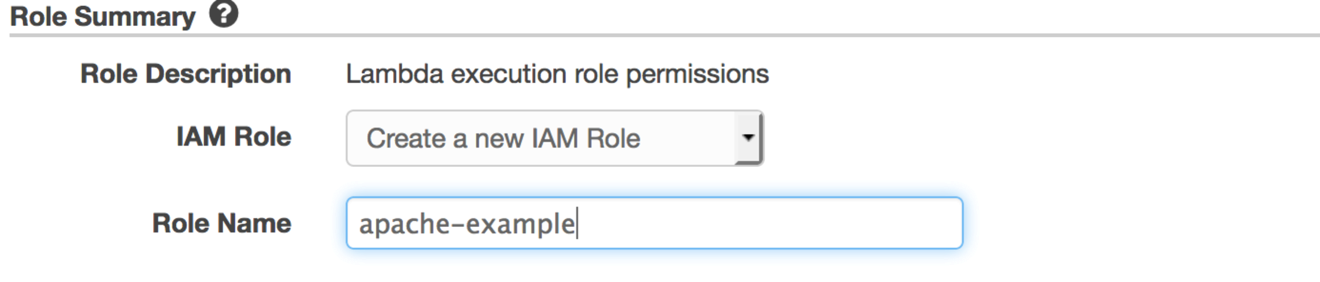
Create a new IAM Roleを選択し、(この記事での)私たちのお気に入りの名前、apache-exampleと名づけます。 Allowを選択すると、Lambdaコンソールに戻ります。
Advanced settingsを選択すると、Firehoseからのログデータのバッチを処理するためのLambda専用のMemoryおよびTimeout値が表示されます。
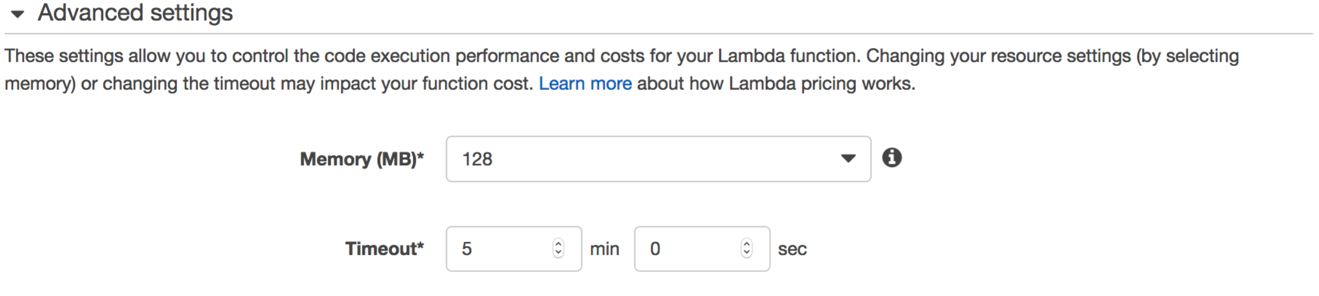
デフォルトのタイムアウトは3秒です。これを30秒以上に増やす必要があります。Lambdaコンソールで機能の実行時間を監視し、適切なタイムアウトに調整することができます。
Nextを選択し、次にCreate Functionを選択して残りのデフォルト値を受け入れることができます。 Firehoseコンソールに戻り、Lambda関数メニューをリロードし、今作成した機能を選択します。
FirehoseがAmazon ESに配信するデータのバッチサイズをElasticsearch Buffer設定で制御します。
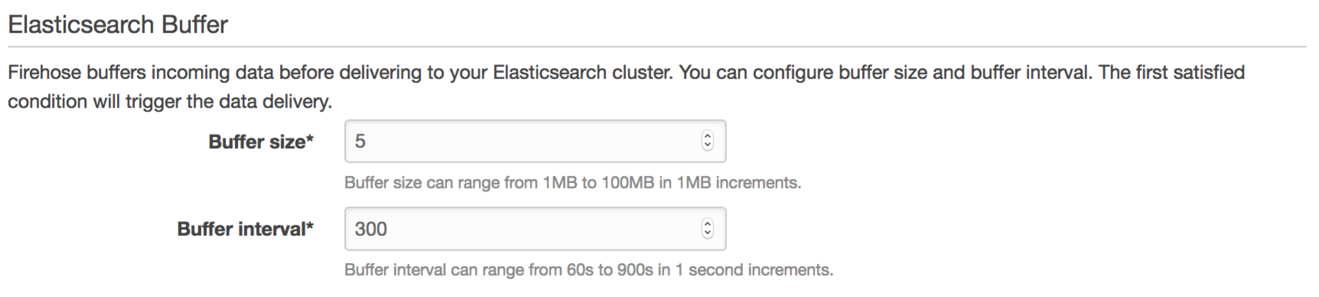
Firehoseにデータを送信すると、Amazon ESはそのデータをバッファし、これらのフィールドに入力した値に基づいてバッファをフラッシュします。少量のデータを扱う場合は、値を低く調整する必要があります – 1MBと60秒が最速の配信時間です。毎分1GB以上を送信する場合は、値を上に調整します。ただし、Amazon Elasticsearch Serviceのバッチサイズ制限に注意してください。小さいインスタンスほど、受け入れる一括リクエストのサイズに制限があります。
バッチサイジングを調整して、書き込みリクエストでクラスタを圧倒しないようにします。生成するリクエストの数を理解するには、Firehoseに1秒ごとに送信する予定のログデータの合計サイズから始めます。最初にヒットするフラッシュトリガーに応じて、1秒あたりのフラッシュ回数を推測できます。この数値は、Amazon ESドメインに対する1秒あたりの書き込み数と同じです。一般的なガイドラインとして、ボリュームを処理するには、Amazon ESドメインに少なくとも2倍の数のvCPUを用意する必要があります。
たとえば、1GB/分(または16MB/秒)をFirehoseに送信しているとします。バッファサイズを1MBに設定し、バッファ間隔を60秒に設定した場合は、最初に1MBでBuffer sizeフラッシュトリガーに当たります。ここでは、毎秒16回のフラッシュを生成します。私のクラスタがm3.medium.elasticsearchデータインスタンスで構成されていて、それぞれvCPUが1つの場合、私は32台を維持する必要があります。 32個のvCPUを持つr3.8xlarge.elasticsearchデータインスタンスを選択すると、1台だけ必要になります。
画面を下へ進めて、IAM Roleに達するまで、すべてのデフォルト値をそのままにしておきます。
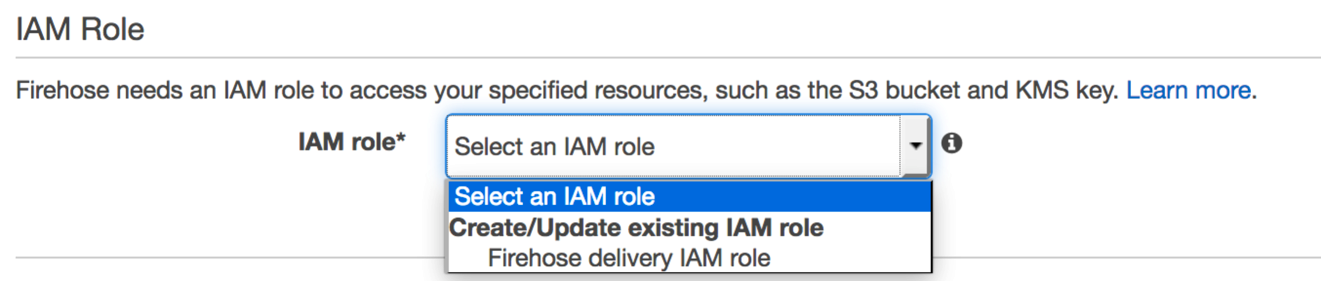
2番目のIAMロールを作成して、FirehoseがAmazon Elasticsearch Service、S3、Amazon CloudWatchに書き込むことを許可する必要があります。 Firehose delivery IAM roleを選択すると、IAMコンソールに転送されます。 IAM Roleで、Create a new IAM Roleを選択します。
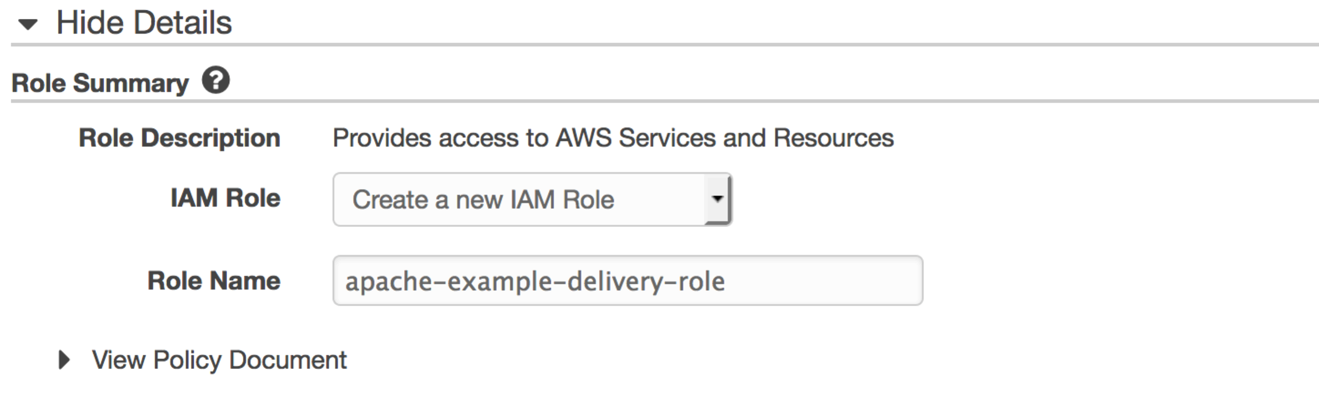
ロールの新しい名前が必要ですが、apache-exampleは既に使用されていますので、apache-example-delivery-roleのような名前を使用できます。 Allowを選択すると、Firehoseコンソールにリダイレクトされます。
Nextを選択し、設定した値を確認してからCreate Delivery Streamを選択します。
データを読み込む
Webログの処理をシミュレートするため、こちらにある1995年7月のNASA Apache Webログを使用します。これらのログは、元のホスト、日付スタンプ、要求、結果、サイジング情報を含むApache共通ログ形式です。ここにサンプルラインがあります。
ApacheログからJSONへの変換が適用されると、これらのレコードはAmazon Elasticsearch Serviceに次のような個別のドキュメントを含むバッチで届きます。
Amazon Linux Amazon Machine Image(AMI)を実行しているEC2インスタンス(t2.micro)をテストホストとして提供します。 そして、Amazon Kinesis Agentを使用して、ファイルシステムからFirehoseストリームにデータを流します。 Amazon Kinesis Agentは、Amazon KinesisとFirehoseにデータを収集して送信するための簡単な方法を提供するスタンドアロンのJavaソフトウェアアプリケーションです。こちらの指示に従って、エージェントをダウンロードしてインストールしてください。
設定ファイルを編集する手順に従ってください。あなたは自分の設定を先に見ることができます。エージェントがNASAのデータを認識してアップロードするには、筆者はいくつかのことをしなければなりませんでした:
- Webログファイルを保持するには、/tmpディレクトリを使用します。
- エージェントを起動したときにファイルが存在しないことを確認してください。
- エージェントがtailしているファイルに既存のファイルをcatする:
- /var/logs/aws-kinesis-agent/aws-kinesis-agent.logでエージェントのログを監視します。筆者の場合は、このようなログラインを得ました:
データを可視化する

私はKibanaで通常ログファイルを可視化します。Kibanaを実行するには、Amazon Elasticsearch Serviceが提供するバージョンを選択できます。もしKibanaを利用するなら、ここで詳述されているように、セキュリティ設定にはもうひと作業が必要です。
簡単なショートカットとして、私はラップトップでKibanaを実行し、GitHubにあるAWS SigV4署名プロキシを使用します。(この署名プロキシはAWSではなく第三者によって開発されたものですあり、AWSは外部コンテンツの機能や適合性について責任を負いません)このプロキシは開発やテストには最適ですが、プロダクションワークロードには適していません。
プロキシをダウンロードしてインストールし、ポート9200で通信します。Kibanaをダウンロードしてインストールします。バージョンはAmazon Elasticsearchサービスドメインのバージョンと一致する必要があります。 kibana.ymlでエンドポイントを設定します。
ブラウザを起動し、http://localhost:5601に移動します。
まず、インデックスパターンを設定する必要があります。 Firehoseストリームを作成したときに設定したインデックスルートを使用します(筆者の場合、logs*)。 Kibanaはログインデックスを認識し、Time-field nameの値を設定できるようにする必要があります。 Firehoseには2つの選択肢があります。
@timestamp – ファイルに記録された時刻
@timestamp_utc – タイムゾーン情報がログデータに存在する場合に使用可能
いずれかを選択すると、検出されたフィールドの概要が表示されます。discoverタブを選択すると、各イベントの拡張可能な詳細とともに、イベントのグラフが表示されます。
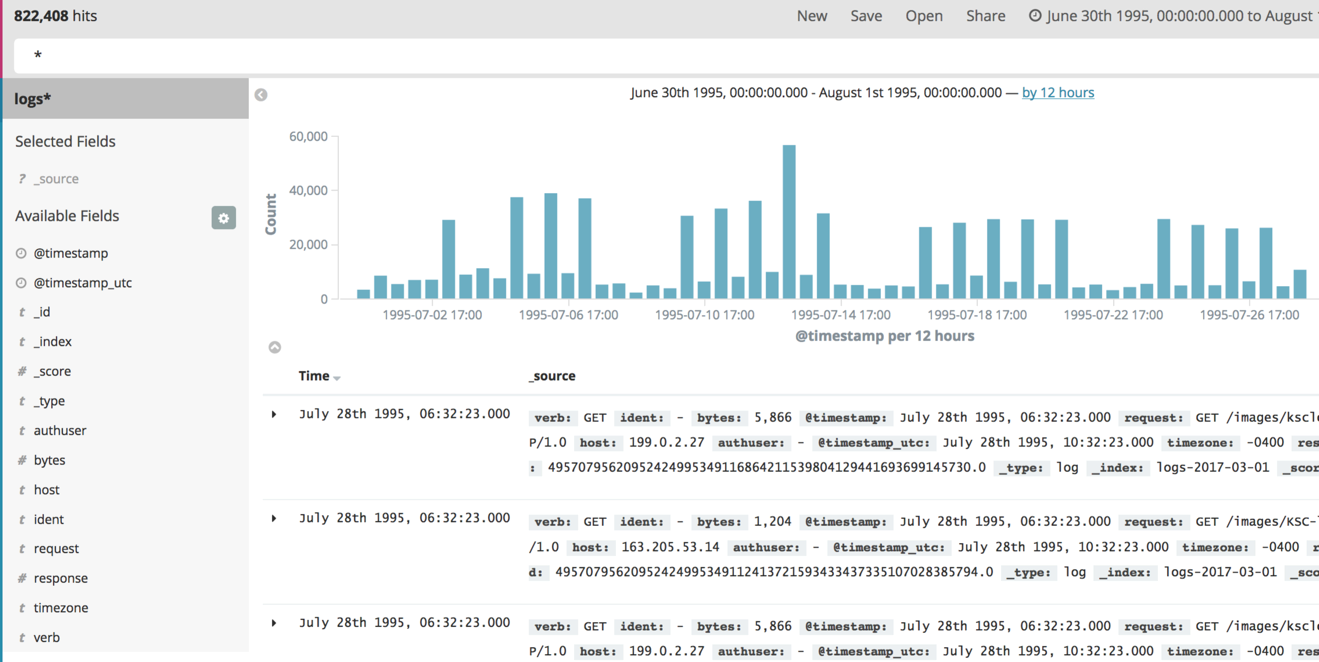
NASAデータセットを使用している場合、結果がないというメッセージが表示されます。それは1995年のデータなので、Kibanaダッシュボードの右上にあるタイムセレクタを展開し、Absoluteを選択し、1995年6月30日の開始日と1995年8月1日の終了日を選択します。このようなものが表示されます。
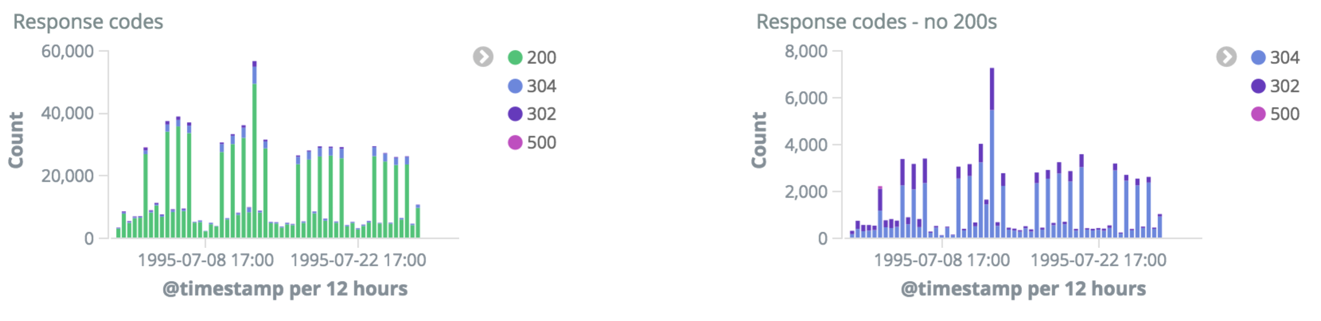
たとえば、エラー数の詳細など、ビジュアライゼーションを作成することができます。ここでは、HTTPレスポンスコードを持つ1組のグラフを示します。最初は200を含めたもの、2つ目は200以外です。
結論
Amazon Elasticsearch Service、Amazon Kinesis Firehose、およびKibanaを使用すると、Amazon Elasticsearch Serviceに独自のApache Webログを簡単かつスケーラブルに送信できます。 今回は、Amazon Elasticsearch Serviceドメインを設定する方法を示しました。次に、ログラインをApacheの共通ログ形式からElasticsearch形式に変換するLambda関数を含むFirehoseストリームを作成する方法を示しました。私はKinesis Agentを使用して、元のサーバーからFirehoseにログをストリーミングする方法と、Kibanaで結果を表示する方法を示しました。
皆さんがどんなログファイルを送信するのかをぜひお知らせください。そして、ハッピーロギングしましょう!
原文:Send Apache Web Logs to Amazon Elasticsearch Service with Kinesis Firehose(翻訳:半場光晴)