Amazon Web Services ブログ
Step Functions 分散マップ – 大規模な並列データ処理のためのサーバーレスソリューション
AWS Step Functions の分散マップが利用可能になったことをお知らせします。このフローは、半構造化データのオンデマンド処理など、大規模な並列ワークロードのオーケストレーションのサポートを拡張します。
Step Function の Map ステートは、データセット内の複数のエントリについて同じ処理ステップを実行します。既存の Map ステートの並列イテレーションは、一度に 40 回に制限されています。この制限があることで、データ処理ワークロードをスケールして何千もの (またはそれを超える数の) 項目を並列処理することが困難になります。これまでよりも高度な並列処理を実現するには、既存の Map ステートコンポーネントに複雑な回避策を実装する必要がありました。
新しい分散 Map ステートにより、サーバーレスアプリケーション内の大規模な並列ワークロードを調整するための Step Functions を記述できます。Amazon Simple Storage Service (Amazon S3) に保存されているログ、画像、.csv ファイルなど、数百万を超えるオブジェクトに対して、イテレーションを実行できるようになりました。新しい分散 Map ステートは、最大 1 万の並列ワークフローを起動してデータを処理できます。
Step Functions がサポートする任意のサービス API を作成してデータを処理できますが、通常は Lambda 関数を呼び出して、任意のプログラミング言語で記述されたコードを使用してデータを処理します。
Step Functions の分散マップは、最大 10,000 の並列同時実行をサポートします。これは、他の AWS のサービスでサポートされている同時実行数をはるかに上回ります。分散マップの最大同時実行機能を使用して、ダウンストリームサービスの同時実行数を超えないようにすることができます。他のサービスと連携する際には、2 つの要素を考慮する必要があります。1 つ目は、アカウントのためにサービスによってサポートされる最大同時実行数です。2 つ目は、バーストレートとランピングレートです。これによって、最大同時実行数をどれだけ早く達成できるかが決まります。
例として Lambda を使用してみましょう。関数の同時実行数は、特定の時間にリクエストを処理するインスタンスの数です。Lambda のデフォルトの最大同時実行数のクォータは AWS リージョンあたり 1,000 です。いつでも引き上げをリクエストできます。トラフィックの最初のバーストでは、リージョン内の関数の累積同時実行数は 500~3,000 の初期レベルに達する可能性がありますが、これはリージョンによって異なります。バースト同時実行クォータは、リージョン内のすべての関数に適用されます。
分散マップを使用する場合は、必ずダウンストリームサービスに対するクォータを確認してください。開発中は分散マップの最大同時実行数を制限し、それに応じてサービスクォータを引き上げることを計画してください。
新しい分散マップと元の Map ステートフローを比較するために、このテーブルを作成しました。
| 元の Map ステートフロー | 新しい分散マップフロー | |
| サブワークフロー |
|
|
| 並列ブランチ | マップイテレーションは並列実行され、一度に有効な最大同時実行数は約 40 です。 | 何百万もの項目を複数の子実行に渡すことができ、一度に最大 10,000 の同時実行が可能です。 |
| 入力ソース | JSON 配列のみを入力として受け入れます。 | Amazon S3 オブジェクトリスト、JSON 配列またはファイル、csv ファイル、または Amazon S3 インベントリとして入力を受け入れます。 |
| ペイロード | 256 KB | 各イテレーションは、ファイルへの参照 (Amazon S3) またはファイルから 1 つのレコード (ステート入力) を受け取ります。実際のファイル処理能力は、Lambda のストレージとメモリによって制限されます。 |
| 実行履歴 | 25,000 イベント | Map ステートの各イテレーションは子実行で、それぞれの最大イベント数は 25,000 です (エクスプレスモードでは実行履歴に制限はありません)。 |
分散マップ内のサブワークフローは、Standard ワークフローと、低レイテンシーで短時間の Express ワークフローの両方で機能します。
この新機能は S3 と連携するように最適化されています。データを保存するバケットとプレフィックスは、分散マップ設定から直接設定できます。分散マップは、項目数が 1 億に達すると読み取りを停止し、最大 10 GB の JSON または csv ファイルをサポートします。
大きなファイルを処理するときは、ダウンストリームサービスの機能を考慮してください。再度 Lambda を例として用いてみましょう。各入力 (S3 上のファイルなど) は、一時ストレージとメモリの観点から Lambda 関数実行環境内に収まる必要があります。サイズの大きいファイルの処理をより容易にするために、Lambda Powertools for Python では、最小限のメモリフットプリントで S3 オブジェクトを取得、変換、処理するための新しいストリーミング機能が導入されました。これにより、Lambda 関数は実行環境のサイズよりも大きいファイルを処理できます。この新機能の詳細については、Lambda Powertools のドキュメントをご覧ください。
実際の動作
このデモでは、S3 に保存されている 1,000 枚の犬の画像を処理するワークフローを作成します。画像は既に S3 に保存されています。
➜ ~ aws s3 ls awsnewsblog-distributed-map/images/
2022-11-08 15:03:36 27034 n02085620_10074.jpg
2022-11-08 15:03:36 34458 n02085620_10131.jpg
2022-11-08 15:03:36 12883 n02085620_10621.jpg
2022-11-08 15:03:36 34910 n02085620_1073.jpg
...
➜ ~ aws s3 ls awsnewsblog-distributed-map/images/ | wc -l
1000ワークフローと S3 バケットは同じリージョンにある必要があります。
まず、AWS マネジメントコンソールの Step Functions ページに移動し、[Create state machine]。 (ステートマシンを作成) を選択します。次のページでは、ビジュアルエディタを使用してワークフローを設計します。分散マップは Standard ワークフローで動作します。ここでは、デフォルトの選択はそのままにします。[Next] (次へ) を選択して、ビジュアルエディタを使用します。
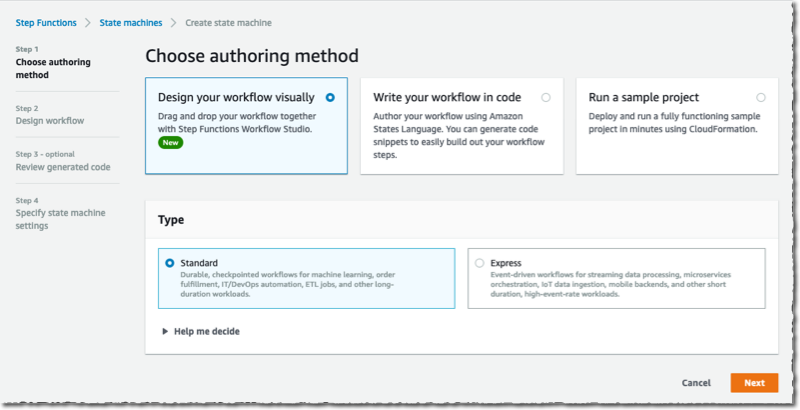 ビジュアルエディタでは、左側のペインで Map コンポーネントを検索して選択し、ワークフローのエリアまでドラッグします。右側では、コンポーネントを設定します。[Processing mode] (処理モード) として [Distributed] (分散) を選択し、[Item Source] (項目ソース) として [Amazon S3] を選択します。
ビジュアルエディタでは、左側のペインで Map コンポーネントを検索して選択し、ワークフローのエリアまでドラッグします。右側では、コンポーネントを設定します。[Processing mode] (処理モード) として [Distributed] (分散) を選択し、[Item Source] (項目ソース) として [Amazon S3] を選択します。
分散マップは S3 とネイティブに統合されています。画像が保存されているバケットの名前 (awsnewsblog-distributed-map) とプレフィックス (images) を入力します。
 [Runtime Settings] (ランタイム設定) セクションで、[Child workflow type] (子ワークフロータイプ) に [Express] を選択します。また、[Concurrency limit] (同時実行の制限) を制限することもできます。これは、私たちが確実に特定のアカウントまたはリージョンのためのダウンストリームサービス (このデモでは Lambda) の同時実行クォータの範囲内で運用するのに役立ちます。
[Runtime Settings] (ランタイム設定) セクションで、[Child workflow type] (子ワークフロータイプ) に [Express] を選択します。また、[Concurrency limit] (同時実行の制限) を制限することもできます。これは、私たちが確実に特定のアカウントまたはリージョンのためのダウンストリームサービス (このデモでは Lambda) の同時実行クォータの範囲内で運用するのに役立ちます。
デフォルトでは、サブワークフローの出力はステート出力として集約されます (最大 256KB)。より大きな出力を処理するために、[Export map state results to Amazon S3] (Map ステートの結果を Amazon S3 にエクスポート) を選択できます。

最後に、各ファイルについて何をするかを定義します。このデモでは、S3 バケット内のファイルごとに Lambda 関数を呼び出したいと考えています。この関数は既に存在します。左側のペインで Lambda 呼び出しアクションを検索して選択します。それを分散マップコンポーネントまでドラッグします。その後、右側の設定パネルを使用して、呼び出す実際の Lambda 関数を選択します。この例では AWSNewsBlogDistributedMap です。
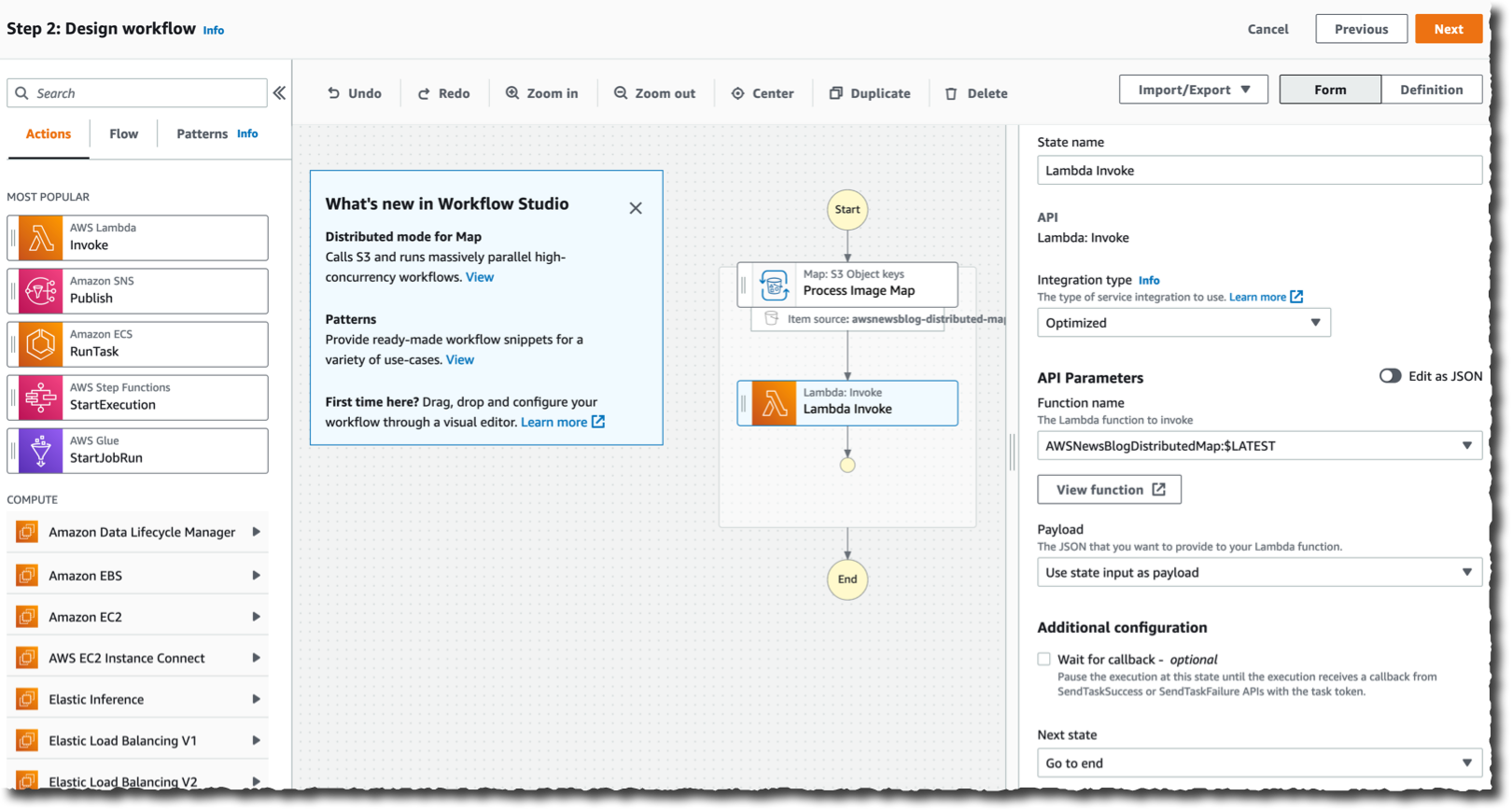
完了したら、[Next] (次へ) を選択します。[Review generated code] (生成コードを確認) ページで、再度 [Next] (次へ) を選択します (ここには表示されていません)。
[Specify state machine settings] (ステートマシンの設定を指定) ページで、ステートマシンの [Name] (名前) と実行する IAM [Permissions] (許可) を入力します。その後、[Create state machine] (ステートマシンを作成) を選択します。
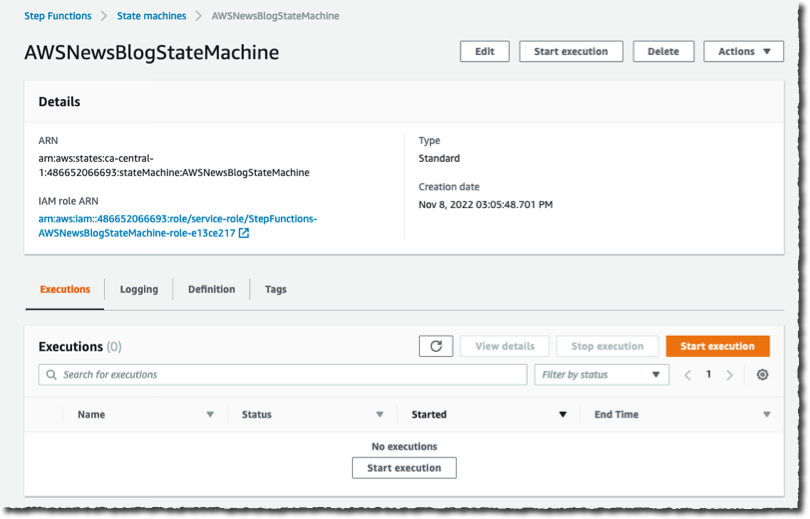
 これで、実行を開始する準備ができました。[State machine] (ステートマシン) ページで、新しいワークフローを選択し、[Start execution] (実行を開始) を選択します。オプションで JSON ドキュメントを入力してワークフローに渡すことができます。このデモでは、ワークフローは入力データを処理しません。そのままにして、[Start execution] (実行を開始) を選択します。
これで、実行を開始する準備ができました。[State machine] (ステートマシン) ページで、新しいワークフローを選択し、[Start execution] (実行を開始) を選択します。オプションで JSON ドキュメントを入力してワークフローに渡すことができます。このデモでは、ワークフローは入力データを処理しません。そのままにして、[Start execution] (実行を開始) を選択します。
 |
 |
ワークフローの実行中、進行状況をモニタリングできます。イテレーションの数と、正常に処理された項目またはエラーが発生した項目の数を確認できます。
 特定の実行をドリルダウンして詳細を確認できます。
特定の実行をドリルダウンして詳細を確認できます。
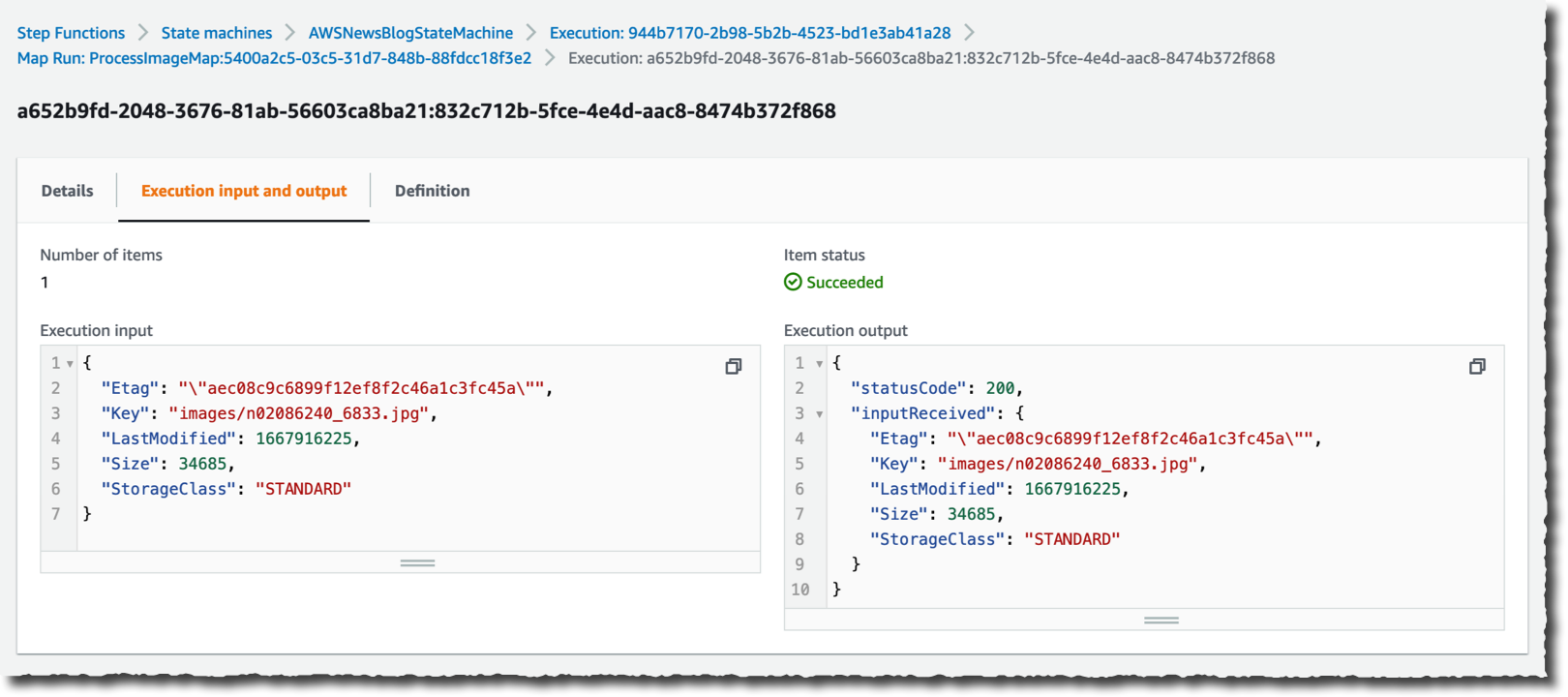
数回クリックするだけで、大量のデータを処理できる、大規模で並列性の高いワークフローを作成しました。
使用すべき AWS のサービス
AWS ではよくあることですが、この新しい機能と、AWS Glue、Amazon EMR、Amazon S3 Batch Operations などの既存のサービスとの間に重複が見られることがあります。ユースケースの区別を試みてみましょう。
私のメンタルモデルでは、データサイエンティストとデータエンジニアは AWS Glue と EMR を使用して大量のデータを処理します。一方、アプリケーションデベロッパーは Step Functions を使用して、アプリケーションにサーバーレスデータ処理を追加します。Step Functions はゼロから迅速にスケールできるため、お客様が結果を待っている可能性があるインタラクティブなワークロードに最適です。最後に、システム管理者と IT 運用チームは、数十億の S3 オブジェクトに対する許可のコピー、タグ付け、変更などの単一ステップの IT オートメーションオペレーションのために Amazon S3 Batch Operations を使用する可能性が高いです。
料金と利用可能なリージョン
AWS Step Functions の分散マップは、米国東部 (オハイオ、バージニア北部)、米国西部 (オレゴン)、アジアパシフィック (シンガポール、シドニー、東京)、カナダ (中部)、欧州 (フランクフルト、アイルランド、ストックホルム) という 10 の AWS リージョンで一般提供されています。
既存のインライン Map ステートの料金モデルに変更はありません。新しい分散 Map ステートでは、イテレーションごとに 1 回の状態遷移について課金されます。料金はリージョンによって異なり、1,000 回の状態遷移あたり 0.025 USD からです。Express ワークフローを使用してデータを処理する場合、ワークフローのリクエスト数とその期間に基づく料金も請求されます。再度お伝えすると、料金はリージョンによって異なりますが、100 万リクエストあたり 1.00 USD から、GB 時間あたり 0.06 USD (100 ミリ秒で按分) からです。
同じ数のイテレーションでも、分散マップと Standard ワークフローを組み合わせて使用すると、既存のインラインマップと比較してコストが削減されます。Express ワークフローを使用する場合、分散マップでは同じコストで、より高い価値を期待できます。
皆さんがこの新機能を使用して何を構築し、それがどのようにイノベーションの扉を開くのかを知ることをとても楽しみにしています。今すぐ並列性の高いサーバーレスデータ処理ワークフローの構築を始めましょう!
原文はこちらです。