Amazon Web Services ブログ
Teespring は Amazon S3 を使用してレガシーデータを制御
すべての Amazon Simple Storage Service (Amazon S3) バケットの内容を正確にご存知でしょうか? すべてのオブジェクトに正しいオブジェクトタグのセットが適用されていますか? 現在および将来のオブジェクトが自動的に管理されるように、ライフサイクルルールを設定していますか?
上記の質問に対して答えがすべて「はい」である場合、この記事はスキップしてもいいかもしれません。けれども、Amazon S3 バケットにレガシーデータファイルがあり、構造がほとんどなく、ネーミングに一貫性がなく、またはメタデータが不足している場合は、是非読み続けてください! この記事では、S3 Intelligent-Tiering および S3 Batch Operations がレガシーデータの制御を回復するのにどのように役立つかを説明します。最終的に、これらの機能はストレージコストの削減に役立ち、最新の S3 機能を採用して最も古いデータの価値を引き出すための明確な道筋を示します。
次の動画は、私の 15 分の re:Invent 2019 セッションです。この動画では、Teespring が S3 Intelligent-Tiering と S3 Batch Operations をどのように使用するかについて説明しています。
Teespring の出発点
Teespring は、商取引を通じてクリエイターとファンをつなげています。クリエイターは Teespring プラットフォームで伝統的な商品、カスタム限定版アイテム、デジタル商品をデザインします。そのクリエイターのファンは、パートナーを通じて、または直接当社のウェブサイトでこれらの商品を購入します。次の画像は当社のホームページで、クリエイターたちに当社のプラットフォームを使い始めるご案内を表示しています。
このプロセスの肝要な部分は、商品のデザインと画像を生成することと、これらのデジタル資産を保管することにあります。アパレル、ステッカー、マグカップなど、当社が製造する商品の高解像度のプレビューが必要です。さらに、プリンター、刺繍機、型抜き機、その他の機械に供給する、さらに高解像度のカスタマイズ資産も必要です。このプロセスの概要を次の図に示します。作成者は、製造および生産を通じて Amazon S3 を介して保存および送信されたデザインを提供します。

Teespring のリストでは、購入者が優れたショッピングエクスペリエンスを実現できるようにするために、500 以上の一意の画像が必要になるのが一般的です。これらは、内部および外部の製造業者のネットワークに正確な製品カスタマイズ仕様を提供するためにも必要です。
会社の創業当初はすべてのスタートアップがそうであるように、当社の焦点は製品の実用的な初回版を開発することに 100% 注がれていました。スケーラビリティ、保守性、または運用効率には焦点は当てられていませんでした。Teespring にとって幸いだったのは、最適化されていないストレージコストが上昇する中で、リスティングの数と販売数が指数関数的に増加したことです。当社のエンジニアリングチームは、ビジネスの急激な増加に追いつくのに忙しすぎて、オブジェクトストレージを再検討する余裕はありませんでした。これにより、識別可能な構造がほとんどないペタバイト規模のバケットがいくつもあり、ライフサイクルルールがなく、止まることがないかのようにストレージコストが増加していく状況に追い込まれてしまいました。
Teespring は、誰もがどこからでも新製品を発売できるようにしたことを誇りに思っています。初期費用がかからず、リスクもゼロです。これにより、Teespring で製品を発売することにより、何千何万という人が簡単に利益を上げることができるようになりました。また、S3 バケットには何十億ものオブジェクトがあり、一度も販売されたことがなく、これからも販売されないだろう製品が置かれていることも意味します。このようなファイルを保持するために毎月莫大なお金を浪費していました。
当社が直面していた課題は 2 つありました。
- 当社は全体的にストレージコストを削減する方法が必要でした。
- バケット内のオブジェクトに構造を遡及的にオーバーレイして、今後管理していくための方法が必要でした。
課題 1 に対しては、S3 Intelligent-Tiering が、パフォーマンスや可用性を犠牲にすることなく、全体のストレージコストを簡単に削減できる素晴らしいソリューションになりました。
Amazon S3 Intelligent-Tiering を使ったストレージコストの削減
前述のように、当社が直面した課題は、大幅に異なる周波数で使用されている数十億のオブジェクトを含むペタバイト規模のバケットがあることでした。データを効率的に調べて必要なものを見つけるのに役立つ命名規則やタグ付けはありませんでした (後でタグ付けのトピックについてさらに説明します)。
S3 Intelligent-Tiering は、このような問題のあるバケットで大幅な節約を実現できる非常に簡単なソリューションでした。その前提はシンプルです。S3 Intelligent-Tiering は、わずかなモニタリングおよび自動化料金で、各オブジェクトへのアクセスをモニタリングします。オブジェクトが連続して 30 日間アクセスされなかった場合、オブジェクトは自動的に低コストの低頻度アクセス階層に移動し、Amazon S3 の請求を削減するのに役立ちます。オブジェクトに再びアクセスがあると、S3 Intelligent-Tiering は自動的にそのオブジェクトを高頻繁アクセス階層に戻します。S3 Intelligent-Tiering の 2 つのアクセス階層にパフォーマンスの違いはなく、データにアクセスするときに取得料金はかかりません。
128 KB 未満のオブジェクトは S3 Intelligent-Tiering に保存できることを学びましたが、低頻度アクセス階層への自動階層化の対象にはなりません。S3 Intelligent-Tiering を使用すると、サイズに関係なく、すべてのオブジェクトに対して追加のモニタリングおよび自動化料金を支払うことになるため、これらのオブジェクトを S3 標準のままにしておくのがお勧めです。
前に述べた 30 日間のウィンドウは変更できず、またより長い休止期間後にオブジェクトを Amazon S3 Glacier に移動するなど、より細かな機能はまだ利用できません。これは将来利用できるようになるかもしれません。S3 チーム、ここで機能のリクエストをしたので、ご対応お願いします! ただし、堅牢性と引き換えに、実装が驚くほどシンプルで簡単です。当社にとっては、既存のすべてのオブジェクトを S3 Intelligent-Tiering に移行するバケット全体の S3 ライフサイクルルールを作成するのと同じくらい簡単でした。128 KB 未満のオブジェクトはごく一部のみで、バケット全体を S3 Intelligent-Tiering に移動する方が簡単なため、これは当社にとって実現可能なソリューションでした。

1~2 日後、すべてのオブジェクトが S3 Intelligent-Tiering ストレージクラスに移動するのを確認できました。そして 30 日後、アクセスの少ないオブジェクトで 40% 以上の節約が実現し始めたことに気づき、S3 インベントリレポートでどのオブジェクトがどのアクセス階層にあるかを確認することもできました。
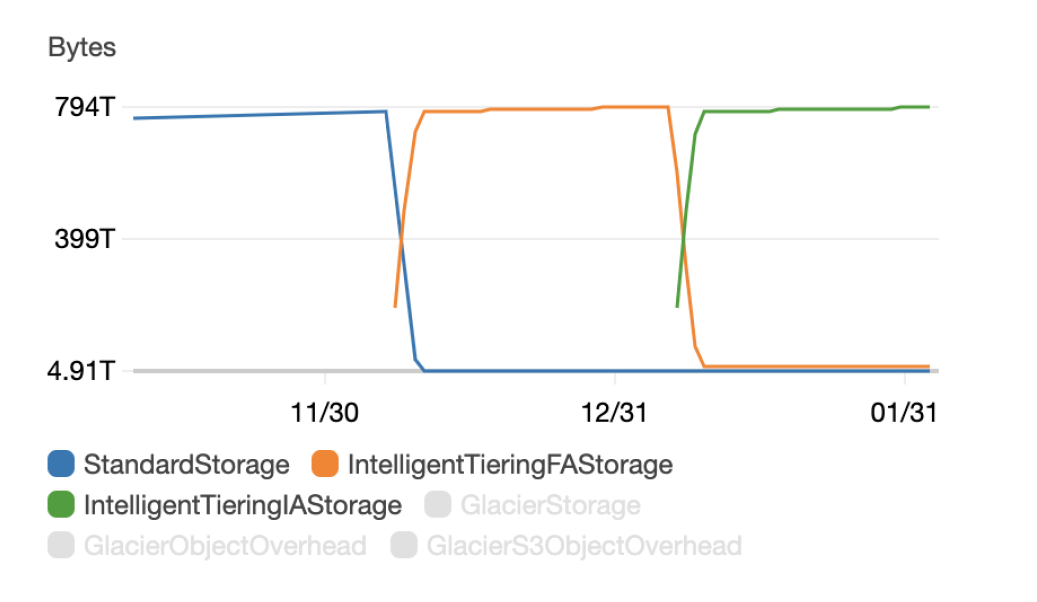
上のグラフは、S3 標準ストレージクラスから S3 Intelligent-Tiering ストレージクラスにオブジェクトを移動した後に何が起こったかを示しています。
- 青い StandardStorage 行は、このライフサイクルルールを作成した後、そのデフォルトのストレージクラスにオブジェクトが残っていないことを示しています。
- オレンジ色の IntelligentTieringFAStorage 行は、S3 Intelligent-Tiering Frequent Access Tier のストレージです。ご覧のとおり、新しく管理下に置かれたすべてのオブジェクトは最初にこの階層に配置され、その後 30 日間アクセスがなかったほとんどのオブジェクトは低頻度アクセス階層に自動的に移動しました。
- 最後に、緑色の IntelligentTieringIAStorage 行は、30 日後に、この特定のバケット内のオブジェクトの 98% にアクセスがなかったことを示しています。これらのオブジェクトは、S3 Intelligent-Tiering 低頻度アクセス階層に移動しました。
低頻度アクセス階層に到達したオブジェクト (当社のケースでは大多数) では、追加の取得コストなしで、ストレージコストを 40% 以上節約できました。
S3 Intelligent-Tiering は次の場合に検討するのがお勧めです。
- ワークロードのアクセスパターンが未知または変化する場合
- Amazon S3 の請求を簡単かつ自動的に節約する方法を求めている場合
- S3 スタンダードと同じ低レイテンシーと高スループットパフォーマンスが必要な場合
上記のすべてが当てはまるなら、S3 Intelligent-Tiering を是非利用してください!
| 「アクセスの少ないオブジェクトで 40% 以上の節約を実現し始めたことに気づき、S3 インベントリレポートでどのオブジェクトがどのアクセス階層にあるかを確認することもできました」 |
課題 2 に対しては、S3 バッチオペレーションが、オブジェクトに構造を追加し、今後管理するのに最適でした。
Amazon S3 バッチオペレーションでさらにコストを削減
S3 Intelligent-Tiering の主な魅力は、実装の容易さでした。特定のユースケースに適していることを確認したら、ライフサイクルルールを設定するのに数分しかかかりません。30 日後、お金を節約できています。ただし、オブジェクトのコストは今では少なくなっていますが、管理することはほとんど不可能でした。古いオブジェクトと新しいオブジェクトの寄せ集めがあり、それらの有用性を判断する方法も、効果的にアーカイブする方法もありませんでした。従来のデータの制御を本当に回復するには、メタデータをさまざまなオブジェクトにタグとしてアタッチする方法が必要でした。
S3 バッチオペレーション: ビジネスドメインをバケットに取り込む
S3 でアセットにメタデータをアタッチする例の 1 つは、アセットが利用規約に違反した場合です。
Teespring はユーザーが作成したコンテンツのプラットフォームであるため、残念なことに、著作権で保護されたコンテンツを使用したり、ヘイトスピーチを行ったりする悪質な人がいることがあります。許容できないコンテンツをスキャンするために、当社には重複するシステムが多数あります (スイスチーズモデルは、当社が頻繁に参照するものです)。ただし、著作権を侵害するコンテンツをプラットフォームから削除する場合、アセットを削除するのではなく、次の 2 つの理由でこれらを保持する必要があります。
- 後で法的な訴えが行われた場合、当社のサイトに表示されている特定の画像にアクセスできることが重要です。
- 当社は、Amazon Machine Learning (Amazon ML) 製品を実験して、侵害コンテンツを発見するためのモデルをトレーニングしています。これは、テクノロジースタックにスイスチーズをもう 1 枚加えるものです。問題のある画像のトレーニングセットをモデルにフィードすると、ドメインの精度が大幅に向上します。
したがって、わかりやすく説明すると、次のようなことを行おうと考えてます。
- コンテンツ違反のため、リスティングが一時停止している場合:
- そのリストのすべての製造カスタマイズ資産を削除します (これらは公開されていないため、法的な理由でそれらを保存する必要はありません)。
- リストのプライマリサムネイルを S3 1 ゾーン – 低頻度アクセス (S3 1 ゾーン – IA) ストレージクラスに移行します。管理システムの内部で表示するため、このプレビューを保存しておきます。
- 他のすべてのアセットを S3 Glacier ストレージクラスに移行します。
今後コンテンツにこれらのルールを実装するのはそれほど複雑ではありませんが、8 年間の履歴コンテンツに遡及的に適用するにはどうすればよいでしょうか?
コードベースとデータベースにのみ存在するロジックとデータに基づいて、S3 内で大規模に機能する方法が必要でした。ビジネスドメインを S3 バケットに組み込む必要がありました。ここで、S3 バッチオペレーションの出番です。S3 バッチオペレーションにより、Amazon S3 に保存されている数十億のオブジェクトを、1 回の API リクエストまたは S3 管理コンソールで数回のクリックで簡単に管理できます。
S3 バッチオペレーションを使用してオブジェクトにタグを付ける
アセットの削除、アーカイブ、または保存を決定するために必要なすべての情報は、Amazon Redshift データウェアハウスにすでに存在している、というのが当社にとって重要な洞察でした。
データウェアハウスは、どのリスティングが一時停止されているかを知っていて、そのリスティングに関連付けられている資産を知っていました。したがって、いくつかの単純な SQL スクリプトを使用して、「一時停止中のリスティングの製造資産」などを示すマニフェスト CSV を生成できます。このマニフェストファイルを使用すると、Object Tagging 操作を行って S3 のアセットにメタデータをアタッチできます。実行したいアクションではなく、オブジェクトの属性に対応するタグを使用することにしました。 たとえば、action:archive ではなく、created: 2018_jan、purpose: preview、listing_status: suspend といったタグを加えました。このアプローチを取ることで、ライフサイクルルールをより正確に記述できるようになり、将来的に他の操作に役立つ構造が得られます。
S3 バッチオペレーションのプレビュー期間中、コマンドラインツールと手書きのペイロードを使用して S3 バッチオペレーションジョブを作成しました。現在、AWS マネジメントコンソールにツールがあります。次のスクリーンショットは、[リージョン] を選択し、[マニフェスト] に入力しているところを示しています。

AWS マネジメントコンソールの次のスクリーンショットでは、[オペレーションタイプ] を選択し、[すべてのオブジェクトタグ設定の置換] に入力しています。

S3 バッチオペレーションによるオブジェクトの削除と移行
S3 バッチオペレーションでは、実際には、ストレージクラス間でオブジェクトを削除または移行することは、ネイティブオペレーションとしては許可されていません。ただし、これは問題ありません。上記のオブジェクトのタグ付けとライフサイクルルールを組み合わせれば、十分に強力でした。オブジェクトに対して実行する完全にカスタムのアクションが本当に必要な場合は、Lambda 関数を呼び出すオプションがあります。
このチャートは、これらの S3 バッチオペレーションの 1 つの結果を示しています。
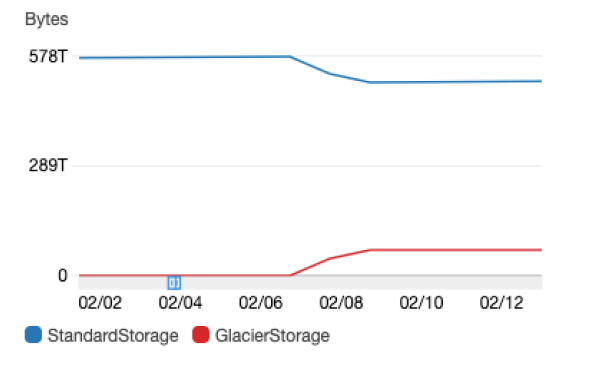
このバケットの場合、ストレージの約 12% (およびその結果、当社のコスト) がこのアセットに費やされました。このアセットは、ML モデルのトレーニングセットとしてのみ役立ちます。
まとめ
レガシーデータは扱いにくいです。私の経験では、レガシーコードと技術的負債よりも扱いが困難です。また、成功を収めるすべての企業が何らかの方法で対処しなければならないことでもあります。技術的債務のリファクタリングアプローチについては無数の本が書かれていますが、テラバイトおよびペタバイト規模の非構造化ファイルに対する制御を再考するための手引きはありません。残念ながら、レガシーデータを管理するために取らなければならないアプローチは、その会社のビジネスの仔細に密接に関わっているため、そのような手引きというものは存在しないと思います。
このブログ記事では、S3 Intelligent-Tiering のような実装が容易なソリューションが非常に大きな影響を与える可能性があることについて、概要を説明して例をいくつか取り上げました。さらに、レガシーデータに取り組む際は、S3 バッチオペレーションが希望の光であることを示しました。これにより、ビジネスドメインのロジックとデータを S3 にあるファイルにオーバーレイできます。したがって、S3 バッチオペレーションは、これらのオブジェクトを構造化、理解、および最終的に管理するために非常に貴重な汎用ツールになります。
詳細については、S3 の「Intelligent-Tiering ストレージクラス」と「バッチオペレーションユーザーガイド」を参照してください。このトピックの補足的な説明が必要な場合は、re:Invent セッションをご覧ください。そのセッションの中で、技術的債務のような「データ債務」は、立ち上げて間もない企業が安心して引き受けられるはずのものであることを説明しています。これは、後で利用できるツールが増えて元が取れるようになったときに特に当てはまります。
Teespring と、AWS のサービスを使用してビジネスを最適化する方法についてお読みいただきありがとうございました。ご不明な点がございましたらコメント欄にご記入ください。AWS チームがきっとフォローアップしてくれることでしょう!
この記事の内容および意見は第三者の作者によるものであり、AWS はこの記事の内容または正確性について責任を負いません。