AWS News Blog
New – Amazon S3 Batch Operations

|
 AWS customers routinely store millions or billions of objects in individual Amazon Simple Storage Service (Amazon S3) buckets, taking advantage of S3’s scale, durability, low cost, security, and storage options. These customers store images, videos, log files, backups, and other mission-critical data, and use S3 as a crucial part of their data storage strategy.
AWS customers routinely store millions or billions of objects in individual Amazon Simple Storage Service (Amazon S3) buckets, taking advantage of S3’s scale, durability, low cost, security, and storage options. These customers store images, videos, log files, backups, and other mission-critical data, and use S3 as a crucial part of their data storage strategy.
Batch Operations
Today, I would like to tell you about Amazon S3 Batch Operations. You can use this new feature to easily process hundreds, millions, or billions of S3 objects in a simple and straightforward fashion. You can copy objects to another bucket, set tags or access control lists (ACLs), initiate a restore from Glacier, or invoke an AWS Lambda function on each one.
This feature builds on S3’s existing support for inventory reports (read my S3 Storage Management Update post to learn more), and can use the reports or CSV files to drive your batch operations. You don’t have to write code, set up any server fleets, or figure out how to partition the work and distribute it to the fleet. Instead, you create a job in minutes with a couple of clicks, turn it loose, and sit back while S3 uses massive, behind-the-scenes parallelism to take care of the work. You can create, monitor, and manage your batch jobs using the S3 Console, the S3 CLI, or the S3 APIs.
A Quick Vocabulary Lesson
Before we get started and create a batch job, let’s review and introduce a couple of important terms:
Bucket – An S3 bucket holds a collection of any number of S3 objects, with optional per-object versioning.
Inventory Report – An S3 inventory report is generated each time a daily or weekly bucket inventory is run. A report can be configured to include all of the objects in a bucket, or to focus on a prefix-delimited subset.
Manifest – A list (either an Inventory Report, or a file in CSV format) that identifies the objects to be processed in the batch job.
Batch Action – The desired action on the objects described by a Manifest. Applying an action to an object constitutes an S3 Batch Task.
IAM Role – An IAM role that provides S3 with permission to read the objects in the inventory report, perform the desired actions, and to write the optional completion report. If you choose Invoke AWS Lambda function as your action, the function’s execution role must grant permission to access the desired AWS services and resources.
Batch Job – References all of the items above. Each job has a status and a priority; higher priority (numerically) jobs take precedence over those with lower priority.
Running a Batch Job
Ok, let’s use the S3 Console to create and run a batch job! In preparation for this blog post I enabled inventory reports for one of my S3 buckets (jbarr-batch-camera) earlier this week, with the reports routed to jbarr-batch-inventory:
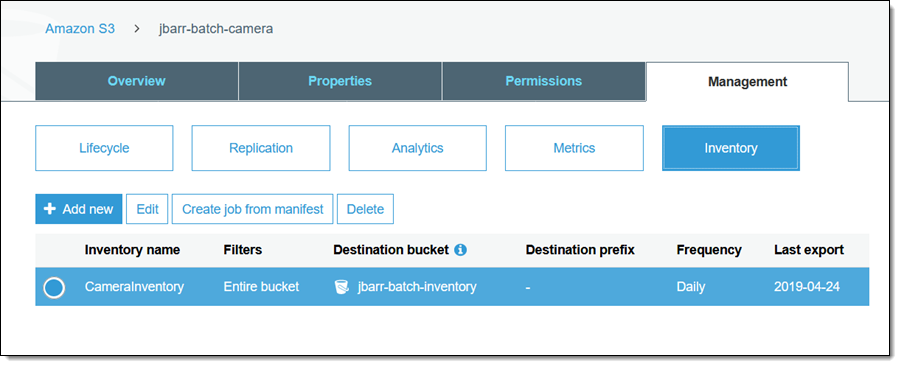
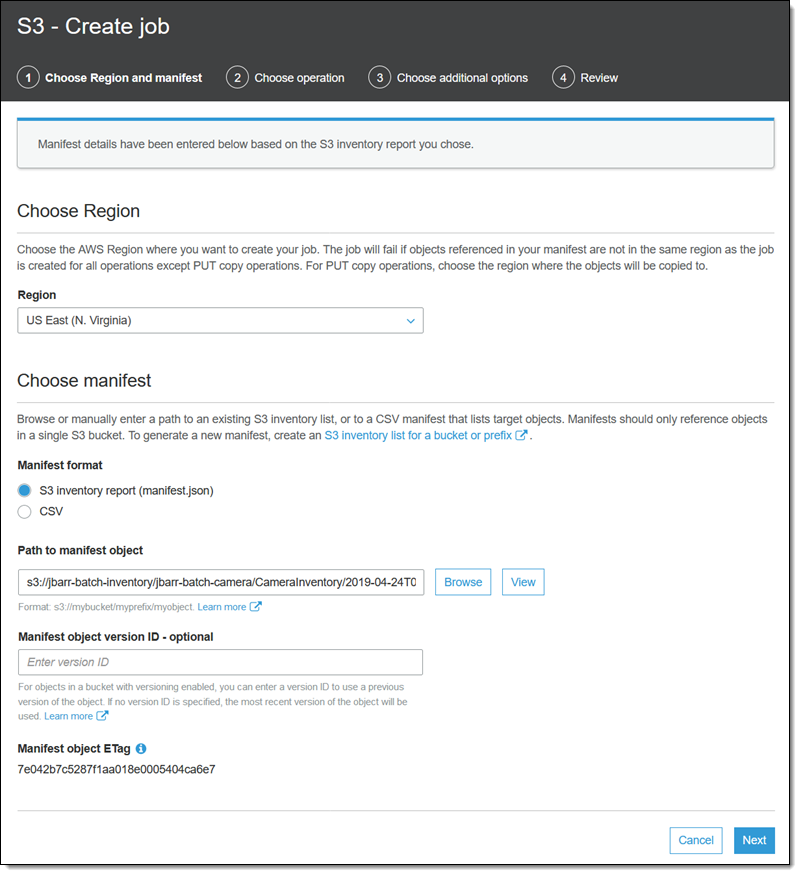
I select the desired inventory item, and click Create job from manifest to get started (I can also click Batch operations while browsing my list of buckets). All of the relevant information is already filled in, but I can choose an earlier version of the manifest if I want (this option is only applicable if the manifest is stored in a bucket that has versioning enabled). I click Next to proceed:
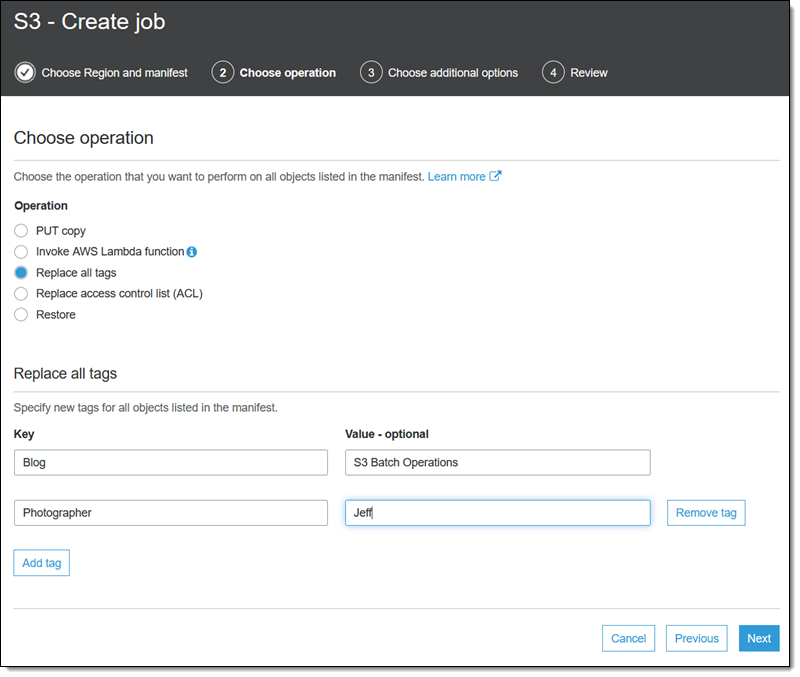
I choose my operation (Replace all tags), enter the options that are specific to it (I’ll review the other operations later), and click Next:
I enter a name for my job, set its priority, and request a completion report that encompasses all tasks. Then I choose a bucket for the report and select an IAM Role that grants the necessary permissions (the console also displays a role policy and a trust policy that I can copy and use), and click Next:
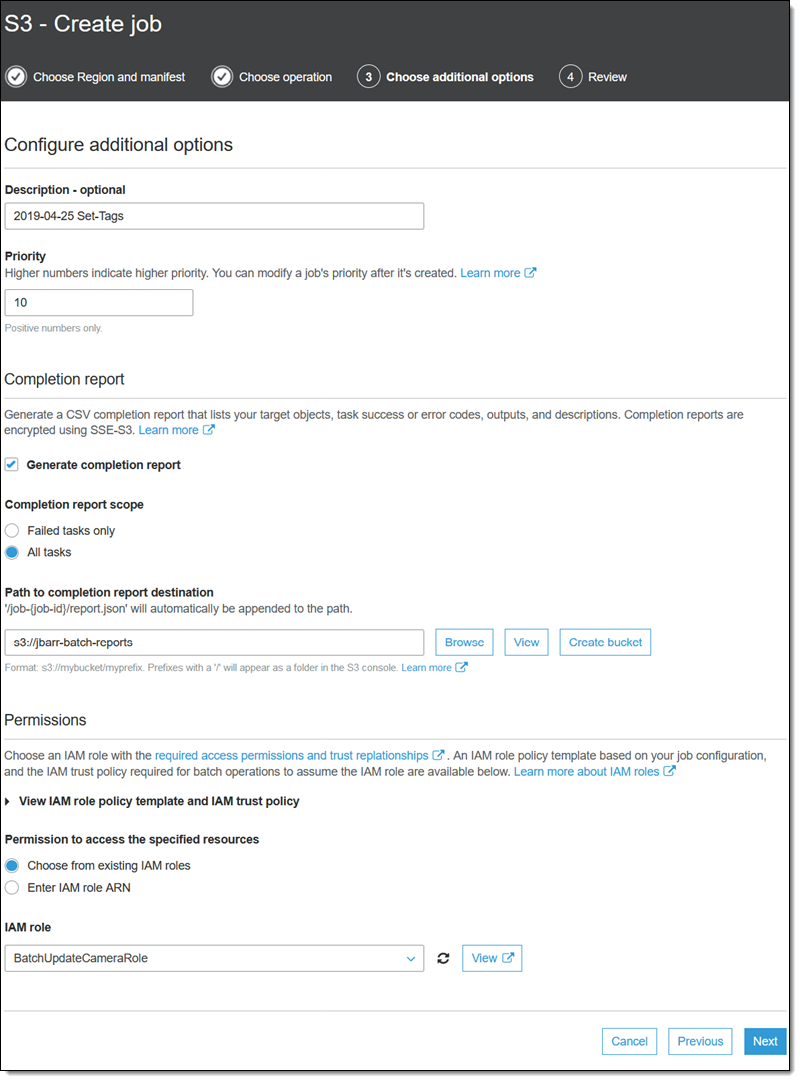
Finally, I review my job, and click Create job:
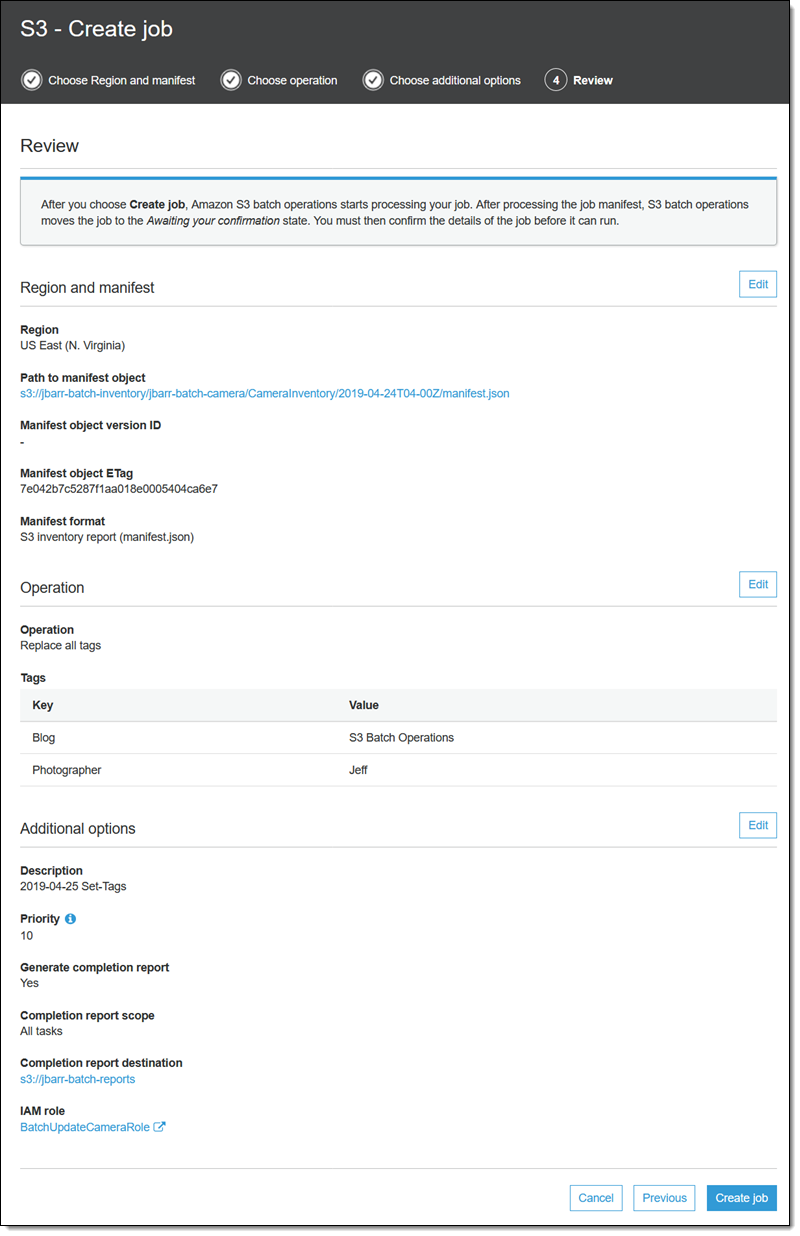
The job enters the Preparing state. S3 Batch Operations checks the manifest and does some other verification, and the job enters the Awaiting your confirmation state (this only happens when I use the console). I select it and click Confirm and run:
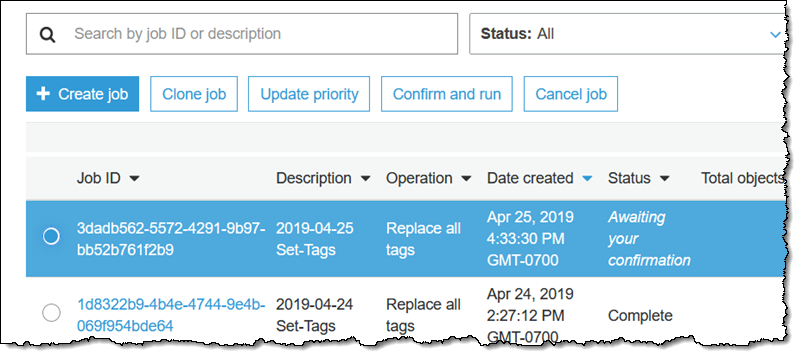
I review the confirmation (not shown) to make sure that I understand the action to be performed, and click Run job. The job enters the Ready state, and starts to run shortly thereafter. When it is done it enters the Complete state:
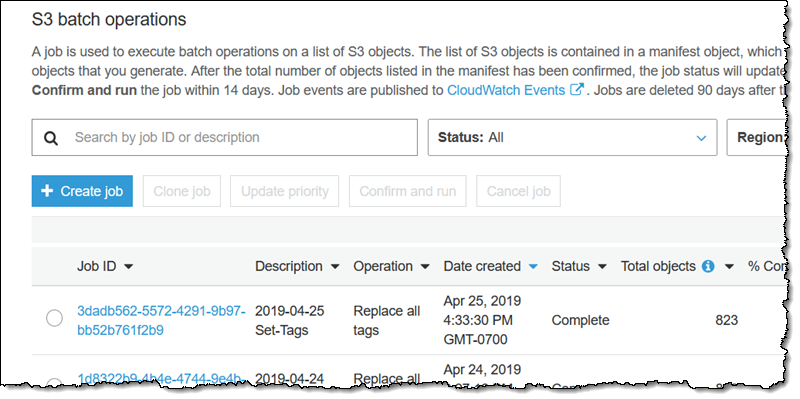
If I was running a job that processed a substantially larger number of objects, I could refresh this page to monitor status. One important thing to know: After the first 1000 objects have been processed, S3 Batch Operations examines and monitors the overall failure rate, and will stop the job if the rate exceeds 50%.
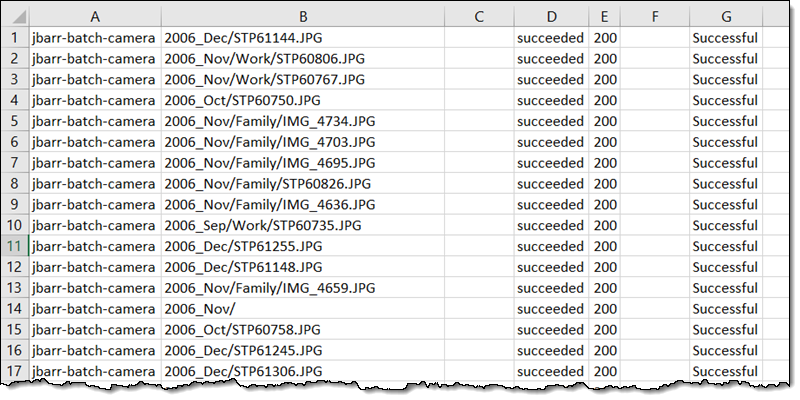
The completion report contains one line for each of my objects, and looks like this:
Other Built-In Batch Operations
I don’t have enough space to give you a full run-through of the other built-in batch operations. Here’s an overview:
The PUT copy operation copies my objects, with control of the storage class, encryption, access control list, tags, and metadata:
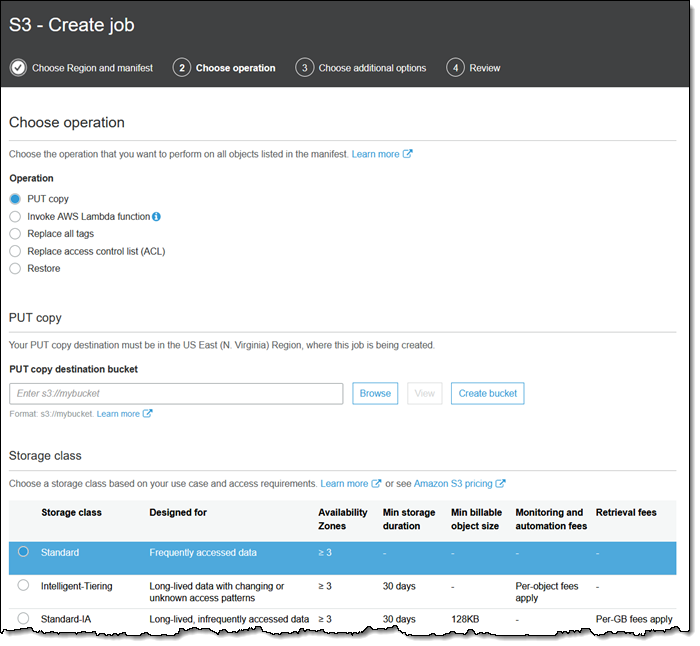
I can copy objects to the same bucket to change their encryption status. I can also copy them to another region, or to a bucket owned by another AWS account.
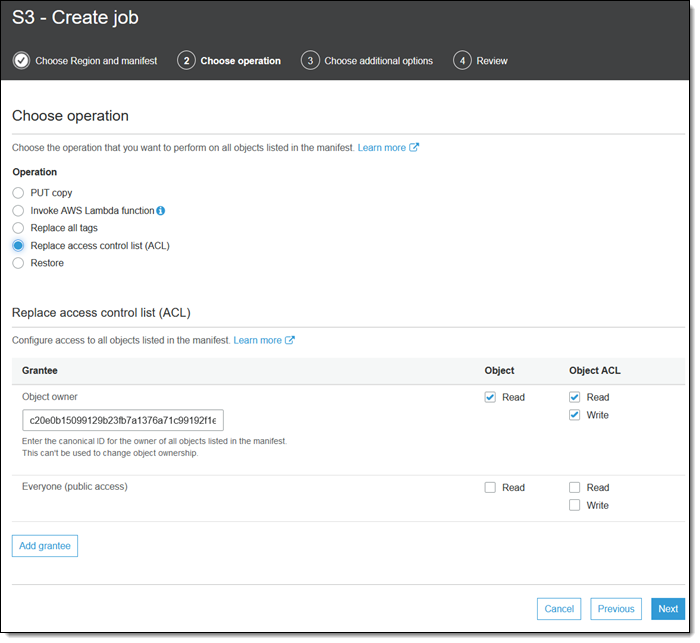
The Replace Access Control List (ACL) operation does exactly that, with control over the permissions that are granted:
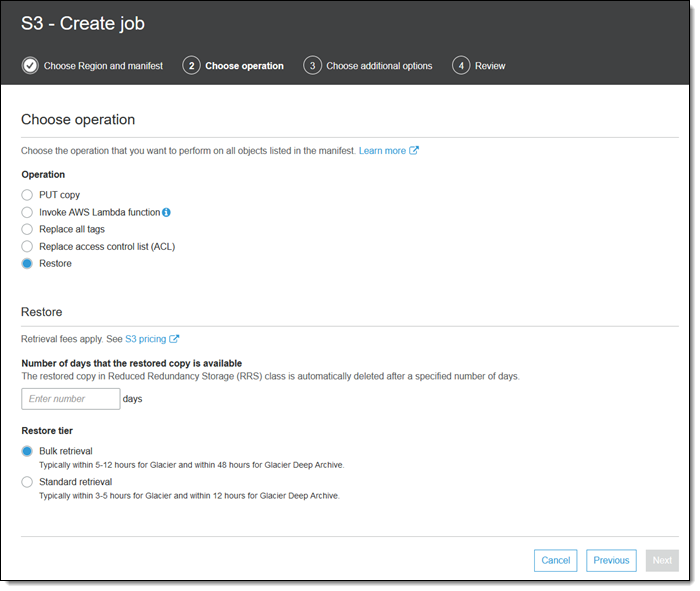
And the Restore operation initiates an object-level restore from the Glacier or Glacier Deep Archive storage class:
Invoking AWS Lambda Functions
I have saved the most general option for last. I can invoke a Lambda function for each object, and that Lambda function can programmatically analyze and manipulate each object. The Execution Role for the function must trust S3 Batch Operations:
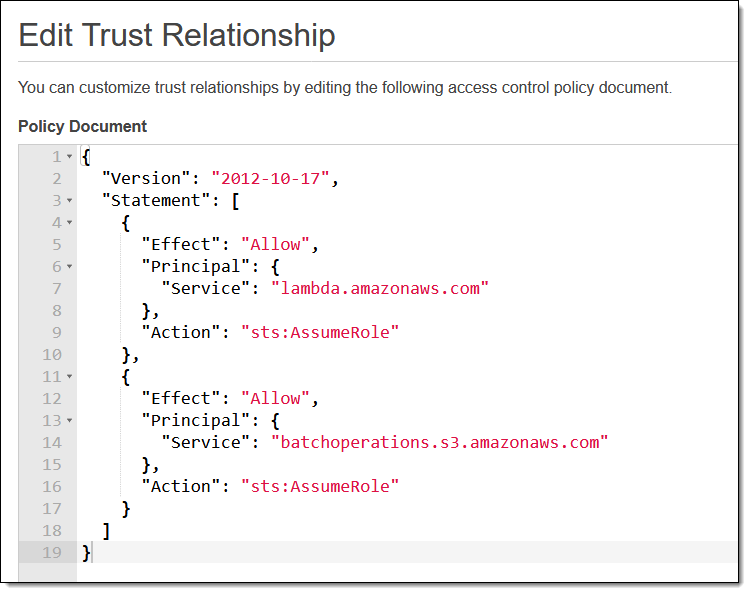
Also, the Role for the Batch job must allow Lambda functions to be invoked.
With the necessary roles in place, I can create a simple function that calls Amazon Rekognition for each image:
With my function in place, I select Invoke AWS lambda function as my operation when I create my job, and choose my BatchProcessObject function:
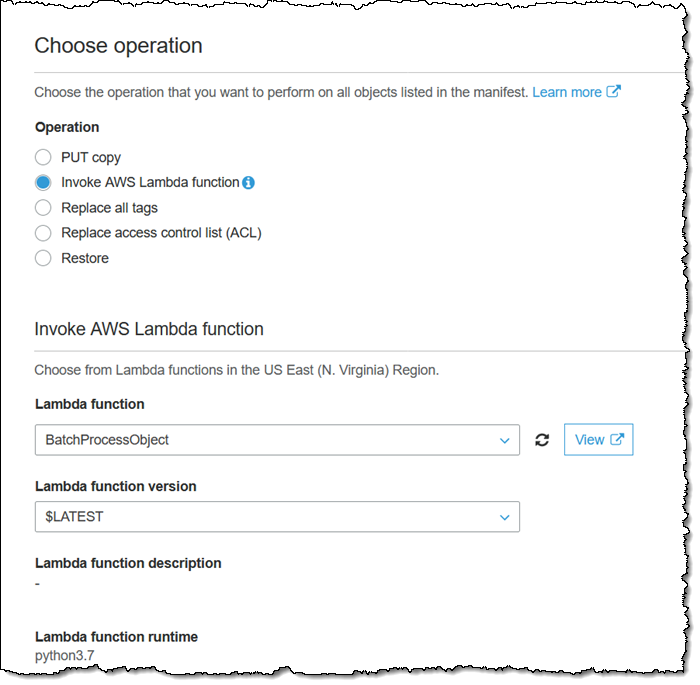
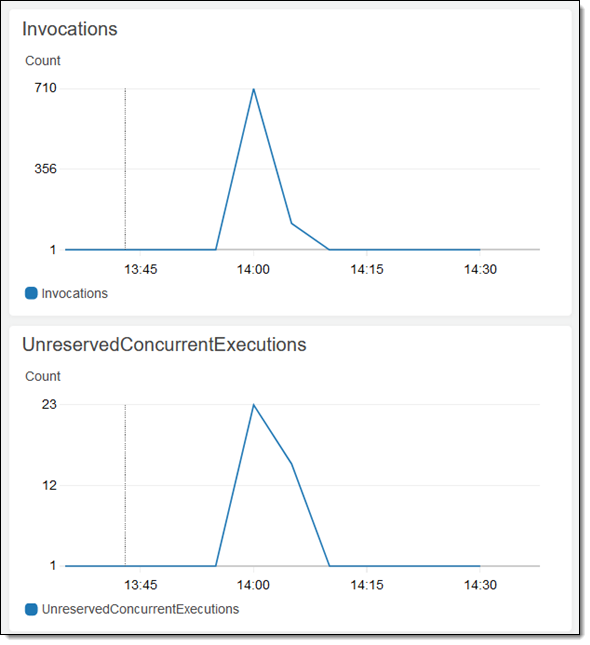
Then I create and confirm my job as usual. The function will be invoked for each object, taking advantage of Lambda’s ability to scale and allowing this moderately-sized job to run to completion in less than a minute:
I can find the “Detected” messages in the CloudWatch Logs Console:
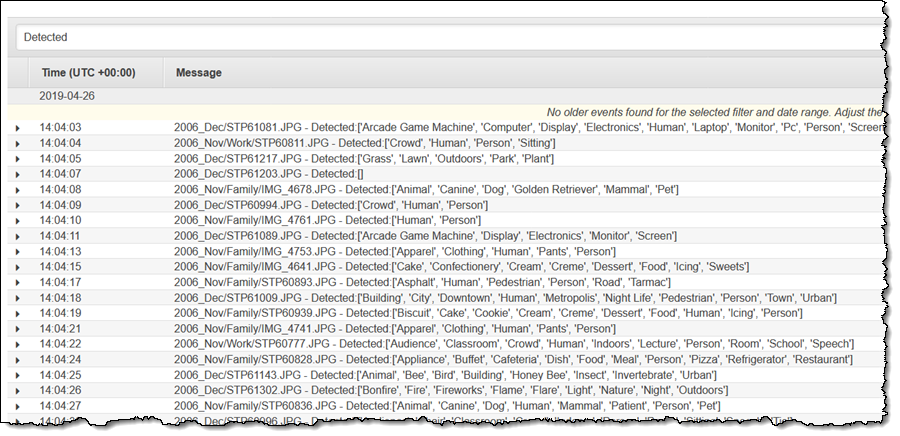
As you can see from my very simple example, the ability to easily run Lambda functions on large numbers of S3 objects opens the door to all sorts of interesting applications.
Things to Know
I am looking forward to seeing and hearing about the use cases that you discover for S3 Batch Operations! Before I wrap up, here are some final thoughts:
Job Cloning – You can clone an existing job, fine-tune the parameters, and resubmit it as a fresh job. You can use this to re-run a failed job or to make any necessary adjustments.
Programmatic Job Creation – You could attach a Lambda function to the bucket where you generate your inventory reports and create a fresh batch job each time a report arrives. Jobs that are created programmatically do not need to be confirmed, and are immediately ready to execute.
CSV Object Lists – If you need to process a subset of the objects in a bucket and cannot use a common prefix to identify them, you can create a CSV file and use it to drive your job. You could start from an inventory report and filter the objects based on name or by checking them against a database or other reference. For example, perhaps you use Amazon Comprehend to perform sentiment analysis on all of your stored documents. You can process inventory reports to find documents that have not yet been analyzed and add them to a CSV file.
Job Priorities – You can have multiple jobs active at once in each AWS region. Your jobs with a higher priority take precedence, and can cause existing jobs to be paused momentarily. You can select an active job and click Update priority in order to make changes on the fly:
Learn More
Here are some resources to help you learn more about S3 Batch Operations:
Documentation – Read about Creating a Job, Batch Operations, and Managing Batch Operations Jobs.
Tutorial Videos – Check out the S3 Batch Operations Video Tutorials to learn how to Create a Job, Manage and Track a Job, and to Grant Permissions.
Now Available
You can start using S3 Batch Operations in all commercial AWS regions except Asia Pacific (Osaka) today. S3 Batch Operations is also available in both of the AWS GovCloud (US) regions.
— Jeff;