Amazon Web Services ブログ
Amazon S3 の 20 年を振り返り、未来を築く
今から 20 年前の 2006 年 3 月 14 日、Amazon Simple Storage Service (Amazon S3) は、「新着」ページに掲載されたわずか 1 段落のシンプルな発表とともにひっそりとリリースされました:
Amazon S3 はインターネットのためのストレージです。デベロッパーがウェブスケールコンピューティングをより簡単に利用できるように設計されています。Amazon S3 は、ウェブ上のどこからでも、いつでも、どのような量のデータでも保存および取得するために使用できるシンプルなウェブサービスインターフェイスを提供します。Amazon が自社のウェブサイトのグローバルなネットワークを運営するために使用している、スケーラビリティ、信頼性、高速性に優れた低コストのデータストレージインフラストラクチャを、すべてのデベロッパーが利用できるようにします。
Jeff Barr 氏のブログ記事もわずか数段落で、カリフォルニアで開催されるデベロッパー向けイベントに向かう飛行機に乗る前に書かれたものでした。コード例はありませんでした。デモもありませんでした。大々的な宣伝もありませんでした。当時、このリリースが私たちの業界全体を形づくることになろうとは、誰も想像していませんでした。
初期段階: ただ機能するビルディングブロック
S3 の中核には、オブジェクトを保存する PUT と、後でそれを取得する GET という、2 つのシンプルなプリミティブがあります。しかし、真のイノベーションは、その背後にある哲学にありました。すなわち、差別化につながらない手間のかかる作業を処理するビルディングブロックを作成することで、デベロッパーがより高度な作業に注力できるようにするということです。
S3 は、サービス開始当初から、今日でも変わっていない 5 つの基本原則をガイドとしてきました。
セキュリティは、お客様のデータがデフォルトで保護されていることを意味します。耐久性は、イレブンナイン (99.999999999%) の可用性を実現するように設計されており、当社はロスレスになるように S3 を運営しています。可用性は、障害は常に存在しており、対処される必要があるという前提に基づき、あらゆるレイヤーに組み込まれるように設計されています。パフォーマンスは、事実上あらゆる量のデータを劣化なく保存するために最適化されています。伸縮性とは、データの追加や削除に応じてシステムが自動的に拡張および縮小し、手動での介入が不要であることを意味します。
これらの原則が適切に機能することで、サービスは非常にわかりやすいものとなり、ほとんどのお客様はこれらの概念の複雑さについて考える必要はありません。
今日の S3: 想像を超えた成長
S3 は 20 年間にわたって、想像を絶する規模に成長を遂げながらも、その核となる基本理念を堅持してきました。
S3 が最初にリリースされたとき、3 つのデータセンターにまたがる 15 のラック内の約 400 のストレージノードで、合計約 1 ペタバイトのストレージ容量と合計 15 Gbps の帯域幅を提供していました。当社は、最大オブジェクトサイズを 5 GB として、数百億個のオブジェクトを保存できるようにこのシステムを設計しました。当初の料金は 1 ギガバイトあたり 15 セントでした。
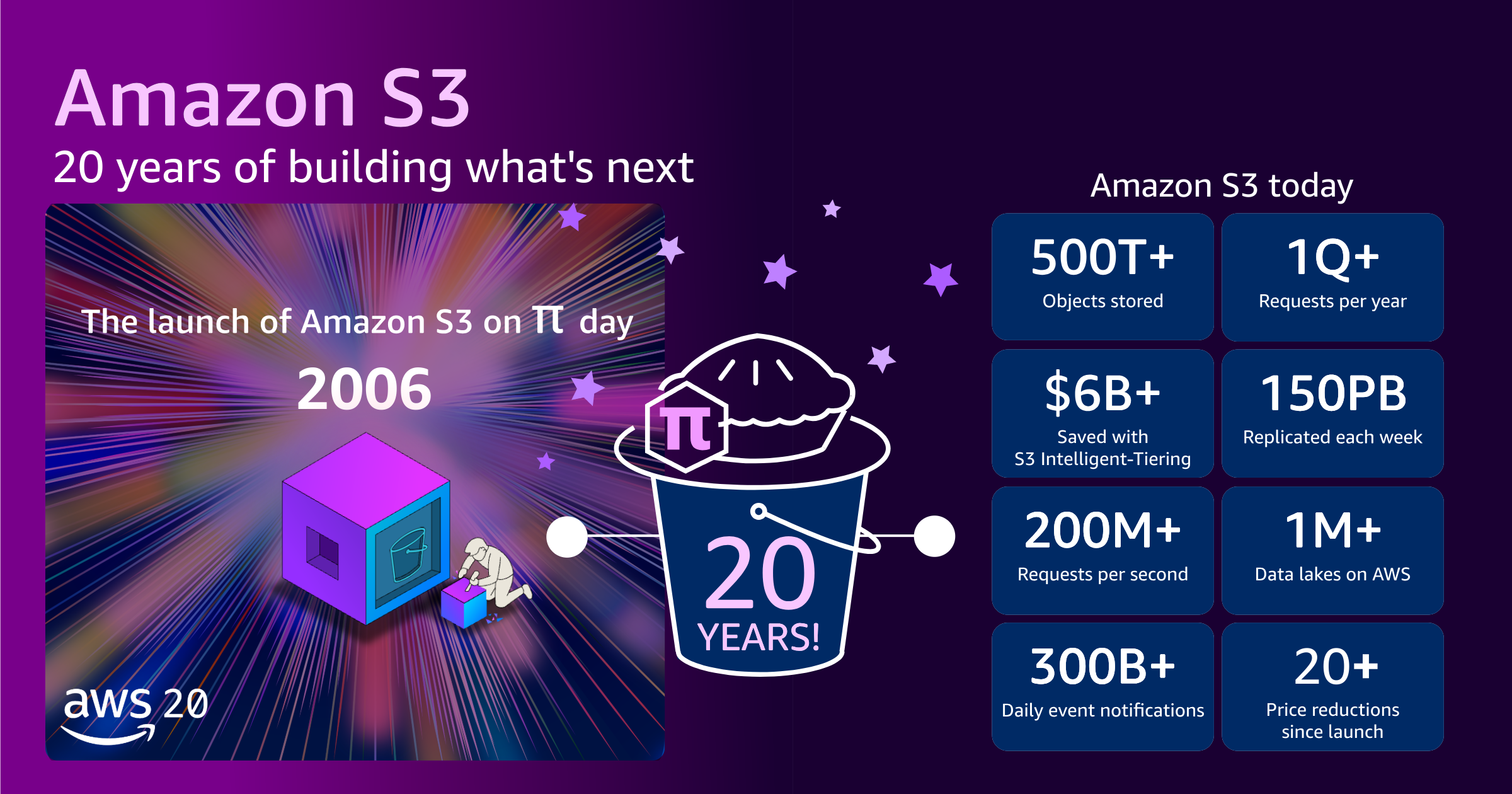
S3 は現在、数百エクサバイト規模のデータを対象として、39 の AWS リージョン内の 123 のアベイラビリティゾーンで、数百万のお客様のために、500 兆個超のオブジェクトを保存し、世界中で毎秒 2 億件超のリクエストを処理しています。最大オブジェクトサイズは 5 GB から 50 TB へと、1 万倍に増加しました。数千万台すべての S3 ハードドライブを積み重ねると、国際宇宙ステーションまで届き、ほぼ往復できるほどの高さになります。
S3 はこのような驚異的な規模を支えるまでに成長しましたが、お客様が支払う料金は低額になりました。今日、AWS が課金しているのは、1 ギガバイトあたり 2 セントをわずかに上回る料金です。これは、2006 年のリリースから見ると、約 85% 低い料金です。同時に、ストレージ階層を使用してストレージにかかる支出をさらに最適化する方法も継続的に導入しています。例えば、Amazon S3 Intelligent-Tiering を利用することで、Amazon S3 Standard と比較して、お客様全体で合計 60 億 USD 超のストレージコストを削減しています。
過去 20 年間にわたって、S3 API はストレージ業界全体で採用され、基準点として利用されてきました。現在、複数のベンダーが S3 互換のストレージツールとシステムを提供しており、同じ API パターンと慣例を実装しています。これは、S3 向けに開発されたスキルやツールが他のストレージシステムにも応用できることが多く、より広範なストレージ環境へのアクセスが容易になることを意味します。
このような成長や業界での普及にもかかわらず、おそらく最も注目すべき成果は、2006 年に S3 向けに作成したコードが、現在も変更されることなく機能していることです。お客様のデータは 20 年間のイノベーションと技術的な進歩を経てきました。当社は、複数世代のディスクとストレージシステムにわたって、インフラストラクチャを移行してきました。リクエストを処理するためのコードはすべて書き直されています。しかし、お客様が 20 年前に保存したデータは今日でも利用可能であり、当社は API の完全な後方互換性を維持しています。これは、常に「問題なく機能する」サービスを提供するという当社のコミットメントです。
規模を支えるエンジニアリング
S3 をこれほど大規模に実現できるのはなぜでしょうか? その答えは、エンジニアリングにおける継続的なイノベーションです。
以下の内容のほとんどは、AWS の VP of Data and Analytics である Mai-Lan Tomsen Bukovec と、The Pragmatic Engineer である Gergely Orosz 氏との対談に基づいています。詳細なインタビューでは、より深く理解したい方のために、技術的な詳細をさらに掘り下げています。以下の段落では、いくつかの例をご紹介します:
S3 の耐久性の中心にあるのは、フリート全体ですべてのバイトを継続的に検査するマイクロサービスのシステムです。これらの監査サービスはデータを監視し、劣化の兆候を検出した瞬間に修復システムを自動的にトリガーします。S3 はロスレスになるように設計されています。イレブンナインという設計目標は、レプリケーション係数と再レプリケーションフリートの規模を反映したものですが、システムはオブジェクトが失われないように構築されています。
S3 のエンジニアは、本番において形式手法と自動推論を用いて、数学的に正確性を証明しています。エンジニアがインデックスサブシステムにコードをチェックインすると、自動証明によって一貫性が損なわれていないことが検証されます。この同じアプローチは、リージョン間レプリケーションやアクセスポリシーの正確性を証明します。
AWS は過去 8 年間にわたって、S3 リクエストパスのパフォーマンスクリティカルなコードを Rust で段階的に書き換えてきました。Blob の移動とディスクストレージは書き換えられ、現在は他のコンポーネントで作業が積極的に進められています。生のパフォーマンスだけでなく、Rust の型システムとメモリ安全性の保証により、コンパイル時にバグのクラス全体を排除できます。これは、S3 の規模と高い正確性の要件を満たす必要がある運用において不可欠な特性です。
S3 は「スケールはメリットである」という設計哲学に基づいて構築されています。 エンジニアは、スケールが拡大することで、すべてのユーザーにとって性能が向上するようにシステムを設計します。S3 の規模が大きくなるほど、ワークロード間の相関性が低下し、すべてのユーザーにとって信頼性が高まります。
今後の展望
S3 のビジョンは、単なるストレージサービスを超え、すべてのデータおよび AI ワークロードの普遍的な基盤となることです。当社のビジョンはシンプルです。すなわち、あらゆる種類のデータを S3 に一度保存すれば、専用システム間でデータを移動させることなく、直接そのデータを利用できる、というものです。このアプローチにより、コストが削減され、複雑さが解消され、同じデータの複数のコピーを作成する必要がなくなります。
近年の注目すべきリリースをいくつかご紹介します:
- S3 Tables – 時間が経過する中で、クエリ効率を最適化し、ストレージコストを削減する、自動メンテナンスを備えたフルマネージド Apache Iceberg テーブル。
- S3 Vectors – セマンティック検索と RAG のためのネイティブベクトルストレージ。インデックスあたり最大 20 億のベクトルをサポートし、クエリレイテンシーは 100 ミリ秒未満です。わずか 5 か月間 (2025 年 7 月~12 月) で、25 万を超えるインデックスを作成し、400 億を超えるベクトルを取り込み、10 億件を超えるクエリを実行しました。
- S3 Metadata – データの即時検出のための一元化されたメタデータ。カタログ化のために大規模なバケットを再帰的にリストする必要がなくなり、大規模データレイクに関するインサイトの取得までの時間を大幅に短縮します。
これらの各機能は S3 のコスト構造で利用できます。従来は高コストのデータベースや専用システムが必要だった複数のデータタイプを、大規模かつ経済的に処理できます。
1 ペタバイトから数百エクサバイトに。1 ギガバイトあたり 15 セントから 2 セントに。シンプルなオブジェクトストレージから、AI と分析の基盤へ。このような変化の中にあっても、当社の 5 つの基本原則、すなわち、セキュリティ、耐久性、可用性、パフォーマンス、伸縮性は変わっていません。そして、2006 年に書かれたお客様のコードは、今日も機能します。
Amazon S3 における次の 20 年間のイノベーションに祝意を表したいと思います。
原文はこちらです。