Amazon Web Services ブログ
標準 JDBC ドライバーで AWS Advanced JDBC Wrapper を使い Amazon Aurora の高度な機能を活用する
本記事は 2026 年 1 月 8 日 に公開された「Unlock Amazon Aurora’s Advanced Features with Standard JDBC Driver using AWS Advanced JDBC Wrapper」を翻訳したものです。
Amazon Aurora を使う最新の Java アプリケーションでは、クラウドベースの機能を十分に活かしきれないことがよくあります。Aurora は高速フェイルオーバー、AWS Identity and Access Management (IAM) 認証、AWS Secrets Manager 統合といった機能を備えていますが、標準の JDBC ドライバーはクラウド固有の機能を想定して設計されていません。これはオープンソースドライバーの制約ではなく、データベース標準に注力して設計されており、クラウド向けの最適化は対象外であるためです。
Aurora のフェイルオーバーは数秒で完了しますが、標準 JDBC ドライバーでは DNS 伝播の遅延により再接続に最大 1 分かかることがあります。また、Aurora は IAM 認証や Secrets Manager 統合といった機能をサポートしていますが、標準 JDBC ドライバーでこれらを実装するには複雑なカスタムコードとエラーハンドリングが必要です。AWS Advanced JDBC Wrapper を使えば、こうした複雑さを解消できます。
本記事では、オープンソースの標準 JDBC ドライバーと HikariCP コネクションプーラーを使用する既存アプリケーションに AWS Advanced JDBC Wrapper (JDBC Wrapper) を追加し、最小限のコード変更で Aurora と AWS クラウド の機能を活用する方法を紹介します。既存の PostgreSQL ドライバーの利点をすべて維持しながら、クラウドベースの機能を追加できます。また、JDBC Wrapper の主要な機能のひとつである読み取り/書き込み分離についても紹介します。
ソリューション概要
JDBC Wrapper は、既存の JDBC ドライバーに Aurora と AWS クラウド の機能を付加するラッパーです。標準の PostgreSQL、MySQL、MariaDB ドライバーを、クラウド対応の本番環境向けソリューションに変換できます。JDBC Wrapper を導入すると、以下の機能を利用できます。
- DNS の制約を超えた高速フェイルオーバー – JDBC Wrapper は Aurora への直接クエリにより、クラスタートポロジーと各データベースインスタンスのプライマリ/レプリカの役割をリアルタイムにキャッシュします。DNS の遅延を完全にバイパスし、フェイルオーバー時に新しいプライマリインスタンスへ即座に接続できます。
- シームレスな AWS 認証 – Aurora は IAM データベース認証をサポートしていますが、従来の実装ではトークンの生成、有効期限の管理、更新処理にカスタムコードが必要でした。JDBC Wrapper は IAM 認証のライフサイクル全体を自動的に処理します。
- Secrets Manager のビルトインサポート – Secrets Manager 統合によりデータベース認証情報を自動取得します。アプリケーション側で実際のパスワードを意識する必要はなく、ドライバーがすべてを処理します。
- フェデレーション認証 – Microsoft Active Directory Federation Services や Okta を通じて、組織の認証情報でデータベースにアクセスできます。
- 接続制御による読み取り/書き込み分離 – 書き込み操作をプライマリインスタンスにルーティングし、読み取りを Aurora レプリカに分散させることで、Aurora のパフォーマンスを最大化できます。
注意: 読み取り/書き込み分離機能では、読み取り操作に対して開発者が明示的に setReadOnly(true) を呼び出す必要があります。ドライバーがクエリを自動解析して読み取り/書き込みを判定するわけではありません。setReadOnly(true) を呼び出すと、setReadOnly(false) を呼び出すまで、その接続で実行されるすべてのステートメントがレプリカにルーティングされます。この機能については後ほど詳しく説明します。
本記事では、JDBC Wrapper を使った Java アプリケーションの実践的な変換手順を紹介します。既存の Java アプリケーションが 3 つの段階を経て進化する様子を確認できます。
- ステージ 1: 標準 JDBC ドライバー (ベースライン) – アプリケーションは標準 JDBC ドライバーを通じて Aurora ライターエンドポイントに直接接続し、すべての操作が単一のデータベースインスタンスを使用し、DNS ベースのフェイルオーバーに依存します。
- ステージ 2: JDBC Wrapper による高速フェイルオーバー – アプリケーションは JDBC Wrapper を使って Aurora クラスターの内部トポロジーキャッシュを維持し、インスタンスの直接検出による高速フェイルオーバーを実現します。すべての操作は引き続きライターエンドポイントを経由します。
- ステージ 3: 読み取り/書き込み分離 – アプリケーションは JDBC Wrapper の読み取り/書き込み分離機能を使い、書き込み操作を Aurora ライターインスタンスに送信し、読み取り操作を Aurora リーダーインスタンスに分散させることで、自動ロードバランシングによるパフォーマンス最適化を実現します。
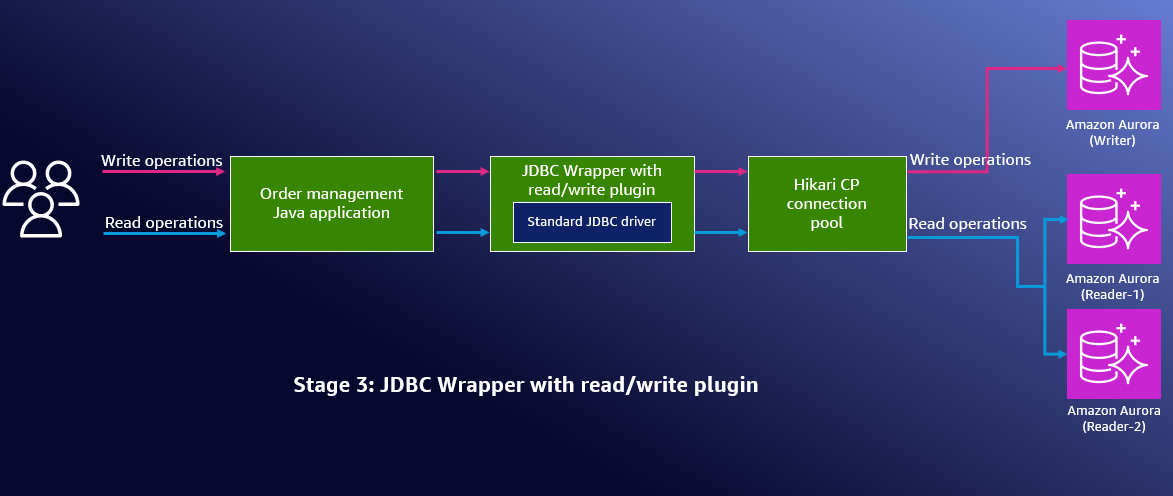
図 1: ステージ 3 の読み取り/書き込み分離を有効にした構成のアーキテクチャ図
前提条件
本記事のソリューションを実装するには、以下が必要です。
- Aurora クラスターを作成する権限を持つ AWS アカウント
- Aurora クラスターに接続可能なデモアプリケーションを実行するための、以下のソフトウェアがインストールされた Linux ベースのマシン:
- 認証情報が設定済みの AWS CLI バージョン 2
- Java Development Kit 8 以降
- Gradle 8.14 以降
インフラストラクチャのセットアップオプション
- オプション A: AWS クラウド Development Kit (AWS CDK) による Infrastructure as Code (推奨)
- 追加要件: Node.js 20 以降、Maven 3.6 以降
- AWS CDK v2 のインストールと設定:
- インストール: npm install -g aws-cdk (AWS CDK 入門ガイド)
- ブートストラップ: cdk bootstrap (AWS CDK 開発者ガイド)
- IAM 権限: AWS 認証情報に iam-policy-cdk.json で指定された権限が必要です
- オプション B: 手動セットアップ
- Aurora クラスター: リードレプリカを少なくとも 1 つ含む Aurora クラスターを作成します
- セキュリティグループ: リポジトリをクローンしたマシンからポート 5432 を開放します
ソリューションの実装
開発環境のセットアップ
このセクションでは、サンプルリポジトリをクローンし、標準 PostgreSQL JDBC ドライバーで HikariCP コネクションプーリングを使用する Java の注文管理アプリケーションを確認します。
以下のコマンドで GitHub リポジトリをクローンします。
デモアプリケーションは、オンラインストアの注文管理システムをシミュレートしています。顧客が注文し、スタッフが注文ステータスを更新し、マネージャーが売上レポートを生成します。このシナリオは、データベースワークロードが混在する課題を示しています。決済処理のように即時の整合性が必要な書き込み中心の操作がある一方、売上レポート生成のようにリードレプリカを使用してわずかな遅延を許容できる読み取り中心の操作もあります。
リポジトリの構成は以下のとおりです。

デモアプリケーションのコードをローカルに取得し、HikariCP と標準 PostgreSQL JDBC ドライバーを使用する典型的な Java 注文管理システムの構造を理解できたので、次はアプリケーションが接続する Aurora データベースインフラストラクチャを作成します。
データベースインフラストラクチャのデプロイ
AWS CDK による Infrastructure as Code を使用した自動スクリプトで、リードレプリカ 2 台を含む Aurora クラスターを作成します。2 台のリードレプリカは、AWS Advanced JDBC Wrapper の読み取り/書き込み分離機能のデモに必要です。読み取り操作のルーティング先となる個別のインスタンスを提供し、プライマリインスタンスは書き込み操作を処理します。提供されたスクリプトを使用しない場合は、AWS マネジメントコンソールからクラスターを手動で作成できます。
.env によるデフォルト設定の上書き (オプション)
既存の AWS リソース (特定の VPC やセキュリティグループなど) を使用する場合やリソース名をカスタマイズする場合は、.env ファイルを作成してデフォルト設定を上書きできます。既存の AWS インフラストラクチャを使用しない場合は、このステップをスキップしてデフォルトを使用してください。
Aurora クラスターの作成
セットアップスクリプトを実行して、リーダーインスタンス 2 台とライターインスタンスを含む Aurora クラスターを作成します。
クラスターの作成が成功すると、以下の出力が表示されます。
アプリケーションプロパティの設定
アプリケーションプロパティファイルには、Java アプリケーションが Aurora クラスターに接続するためのデータベース接続情報が含まれています。
提供された AWS CDK スクリプト (オプション A) でクラスターを作成した場合、スクリプトが src/main/resources/application.properties を自動的に作成し、Aurora の接続情報を設定します。そのため、アプリケーションプロパティファイルの作成や設定は不要です。
手動セットアップ (オプション B) の場合は、アプリケーションプロパティファイルを作成して設定します。
データベースパスワードの設定
提供された AWS CDK スクリプトでインフラストラクチャを作成した場合 (オプション A): AWS CDK スクリプトは安全なパスワードを自動生成し、Secrets Manager に保存します。以下のコマンドでデータベースパスワードの環境変数を設定します。
手動セットアップの場合 (オプション B):
Aurora クラスター作成時に指定したパスワードを設定するには、以下のコマンドを実行します。
export DB_PASSWORD=<your_database_password>
Aurora クラスターとリードレプリカのデプロイ、アプリケーションプロパティとデータベースパスワードの設定が完了しました。次は、AWS Advanced JDBC Wrapper の機能を段階的に示す 3 つのステージでアプリケーションをテストします。
JDBC Wrapper によるアプリケーションの設定
このセクションでは、Java アプリケーションに JDBC Wrapper を設定する 3 つの段階を説明します。
- ステージ 1: 標準 JDBC ドライバー (ベースライン) – 標準 PostgreSQL JDBC ドライバーでアプリケーションを実行します。
- ステージ 2: JDBC Wrapper による高速フェイルオーバー – JDBC Wrapper に高速フェイルオーバー機能を設定します。
- ステージ 3: 読み取り/書き込み分離 – 読み取り/書き込み分離を有効にして、読み取りを Aurora レプリカに分散させます。
ステージ 1: 標準 JDBC ドライバー (ベースライン)
JDBC Wrapper の機能で拡張する前に、標準 PostgreSQL JDBC ドライバーでアプリケーションを実行してベースラインを確立します。アプリケーションを実行して標準 JDBC の動作を確認します。
./gradlew clean run
出力例は以下のとおりです。
出力を見ると、書き込み操作 (注文の作成) と読み取り操作 (注文履歴の取得) の両方で同じ接続 URL パターン → WRITER jdbc:postgresql://aurora-jdbc-demo.cluster-xxxxxxx が表示されています。標準 JDBC の動作では、すべてのデータベース操作が Aurora ライターエンドポイントにルーティングされるため、トランザクション操作と分析クエリが同じライターリソースを奪い合います。これこそが、次のステップで導入する AWS Advanced JDBC Wrapper の読み取り/書き込み分離が解決する問題です。
標準 JDBC ドライバーでベースラインを確立し、すべての操作が Aurora ライターエンドポイントにルーティングされることを確認しました。次は、同じ機能を維持しながら高速フェイルオーバーなどのクラウド機能を追加するため、JDBC Wrapper を使用するようアプリケーションを設定します。
ステージ 2: JDBC Wrapper による高速フェイルオーバー
同じ機能を維持しながら高速フェイルオーバーなどの機能を追加するため、JDBC Wrapper を使用するようアプリケーションを変換します。標準 JDBC アプリケーションを Aurora と AWS クラウド の機能でアップグレードするために必要な変更を自動的に適用するスクリプトを使用します。スクリプトを実行する前に、JDBC Wrapper を使用するためにアプリケーションに必要な変更を確認しましょう。
build.gradle (JDBC Wrapper 設定前):
以下は、JDBC Wrapper の機能を使用するために必要な変更です。build.gradle (JDBC Wrapper 設定後):
この変更により、既存の PostgreSQL ドライバー (org.postgresql:postgresql:42.6.0) と並んで AWS Advanced JDBC Wrapper ライブラリ (software.amazon.jdbc:aws-advanced-jdbc-wrapper:2.5.6) が追加されます。ラッパーはデータベース呼び出しをインターセプトし、固有の機能を追加した上で、実際の SQL 操作を PostgreSQL ドライバーに委譲する中間レイヤーとして機能します。
上記のコード変更に加えて、データベース接続設定を含む application.properties ファイルの JDBC URL も更新する必要があります。以下は、標準 JDBC での現在の設定です。
JDBC Wrapper 設定前:
db.url=jdbc:postgresql://aurora-jdbc-demo.cluster-abc123.us-east-1.rds.amazonaws.com:5432/postgres
以下は、JDBC Wrapper を使用するための変更です。
JDBC Wrapper 設定後:
aws-wrapper: プレフィックスにより、ドライバーマネージャーが JDBC Wrapper の機能を使用するよう指示されます。
DatabaseConfig.java ファイルで接続設定を更新します。以下は、標準 JDBC での現在の設定です。
JDBC Wrapper 設定前:
以下は、JDBC Wrapper を使用するための変更です。
JDBC Wrapper 設定後:
上記のコードは、直接の JDBC URL 設定から JDBC Wrapper の使用に切り替えています。高速フェイルオーバー機能が有効になり、読み取り/書き込み分離や IAM 認証などの高度な機能もサポートされます。クラウド機能を追加しながらも、ラッパーは実際のデータベース操作を引き続き PostgreSQL ドライバーに委譲します。Aurora のクラウド機能を、アプリケーションのビジネスロジックを変更せずに利用できます。
以下のスクリプトを実行して上記の変更をすべて適用し、アプリケーションを実行します。
./demo.sh aws-jdbc-wrapper
上記のスクリプトは JDBC Wrapper の変更を適用し、Java アプリケーションを実行します。以前と同じ出力が表示されますが、JDBC Wrapper の機能が含まれています。
コネクションプール名が StandardPostgresPool から AWSJDBCPool に変わり、ログに AWS JDBC Wrapper connection pool initialized と表示されていることから、アプリケーションが JDBC Wrapper を使用していることを確認できます。接続タイプは software.amazon.jdbc.wrapper.ConnectionWrapper が org.postgresql.jdbc.PgConnection をラップしており、ラッパーがデータベース呼び出しをインターセプトしながら PostgreSQL ドライバーに委譲していることがわかります。
操作は引き続き Aurora ライターエンドポイントを使用しますが、ビジネスロジックを変更することなく高速フェイルオーバー機能が追加されました。
JDBC Wrapper による高速フェイルオーバー機能の設定が完了し、すべての操作が Aurora ライターエンドポイントで維持されていることを確認しました。次は、読み取り/書き込み分離を設定して読み取り操作を Aurora レプリカに分散させ、パフォーマンスを最適化します。
ステージ 3: 読み取り/書き込み分離の有効化
JDBC Wrapper の読み取り/書き込み機能を実装し、接続ルーティングを有効にします。接続ルーティングにより、書き込みはプライマリインスタンスに送信され、読み取りは roundRobin や fastestResponse などのリーダー選択戦略に基づいて Aurora レプリカに分散されます。設定の詳細は Reader Selection Strategies を参照してください。
JDBC Wrapper を使用した HikariCP のパフォーマンスに関する考慮事項
デモアプリケーションでは、複数のユースケースを示すために外部の HikariCP コネクションプーリングを使用しています。ただし、読み取り/書き込み操作が頻繁な本番アプリケーションでは、JDBC Wrapper の内部コネクションプーリングの使用を推奨します。JDBC Wrapper は現在、内部コネクションプールの作成と管理に HikariCP を使用しています。
内部プールと外部プールを使用したパフォーマンステスト、および読み取り/書き込み分離なしとの比較を含む包括的な例については、3 つのアプローチを示す ReadWriteSplittingSample.java を参照してください。
Spring Boot/Framework に関する考慮事項
Spring Boot/Framework を使用している場合、読み取り/書き込み分離機能のパフォーマンスへの影響に注意してください。たとえば、@Transactional(readOnly = true) アノテーションは、リーダーとライターの接続が頻繁に切り替わるため、パフォーマンスが大幅に低下する可能性があります。考慮事項と推奨される回避策の詳細は、Limitations when using Spring Boot/Framework を参照してください。
読み取り/書き込み分離に必要な変更
読み取り/書き込み分離に必要な変更を確認しましょう。DatabaseConfig.java ファイルに readWriteSplitting プラグインを追加します。
以下は、フェイルオーバーを設定した既存の JDBC Wrapper 設定です。
targetProps.setProperty("wrapperPlugins", "failover");
読み取り/書き込み分離を使用するための更新後のコードは以下のとおりです。
targetProps.setProperty("wrapperPlugins", "readWriteSplitting,failover");
OrderDAO.java ファイルで、リーダーインスタンスへのルーティングを有効にするため、接続を読み取り専用に設定します。
読み取り/書き込み分離の設定を実行します。
設定を実行した後の出力例は以下のとおりです。
JDBC Wrapper が書き込み操作を Aurora ライターエンドポイント (プライマリインスタンス) に、読み取り操作を Aurora リーダーエンドポイント (レプリカインスタンス) にルーティングするようになりました。読み取り/書き込み分離プラグインには以下の利点があります。
- 接続管理の簡素化 – アプリケーション内で読み取り用と書き込み用のコネクションプールを個別に管理する必要がありません。アプリケーションで Connection#setReadOnly() メソッドを設定するだけで、JDBC Wrapper が接続を自動的に管理します。
- 柔軟なリーダー選択戦略 – roundRobin、fastestResponse、least connections など複数のリーダー選択戦略から選択でき、アプリケーションの要件やワークロードパターンに応じてパフォーマンスを最適化できます。
- ライターの負荷軽減 – 分析クエリがトランザクションと競合しなくなります。
- リソース使用率の向上 – 読み取りトラフィックが複数のレプリカに分散され、アプリケーションロジックの変更なしに各 Aurora インスタンスが最適なワークロードを処理できます。
クリーンアップ
今後の課金を避けるため、このウォークスルーで作成したリソースを削除してください。
AWS CDK スクリプトを使用した場合 (オプション A):
以下のコマンドを実行して、すべての AWS リソースを削除します。
リソースを手動で作成した場合 (オプション B): Aurora クラスターと関連リソース (セキュリティグループ、DB サブネットグループ) を、作成時と同じ方法 (AWS マネジメントコンソールまたは AWS CLI) で削除してください。
まとめ
本記事では、JDBC Wrapper を使って Java アプリケーションに Aurora のクラウドベースの機能を追加する方法を紹介しました。本記事で紹介したシンプルなコード変更により、標準 JDBC アプリケーションに高速フェイルオーバー、読み取り/書き込み分離、IAM 認証、Secrets Manager 統合、フェデレーション認証を導入できます。
著者について
翻訳は Cloud Support Engineer の Michelle Kiyomi Turberfield が担当しました。