AWS Storage Blog
How Globe Telecom used AWS DataSync at scale to migrate 7.2 PB of Hadoop data
Data migration is a critical first step for an organization in their cloud journey. It often requires a lift and shift of business-critical applications, databases, data analytics workloads, data warehouses, big data, and trained artificial intelligence/machine learning (AI/ML) models. The data is generated and stored in different layers causing complexity in the migration process. Due to this complexity, it’s important that data ingestion and migration processes are well designed with a streamlined methodology to make sure of a continuously flowing data transfer.
Globe Telecom is a major provider of telecommunications services in the Philippines, operating one of the largest mobile, fixed line, broadband networks in the country with close to 60 million customers. Globe Telecom provides a superior customer experience by using AWS for its web portal, content registration platforms, online store, and self-service apps.
In this post, we take you through Globe Telecom’s data migration journey, including the migration of Cloudera data to Amazon Simple Storage Service (Amazon S3). For this project, the Enterprise Data Office (EDO) of Globe Telecom owned the distribution of data across different business functions. Globe was tasked with migrating 7.2 petabytes of Hadoop Distributed File System (HDFS) data in less than four months over our network. During the migration, the system was in production and subsequent transfers of data kept the S3 bucket destination up-to-date with the active source Cloudera system. The tight timeline was necessary because Globe Telecom’s Cloudera license was due for renewal, and the new data generated was consuming the on-premises storage with a risk of reaching the capacity limit.
Globe Telecom’s technical requirements
Globe Telecom needed to build and manage the centralized data repository on Amazon S3 as a raw data lake. When the data lands in Amazon S3, it needed to be pre-processed and shared with analytics engines to run data insights. Business users would later leverage business intelligence (BI) tools to visualize the data and help in data-driven business decisions.
Globe Telecom’s data migration Requirements:
- Cloudera is the source HDFS
- Migrate data from HDFS Storage Nodes without a staging area
- Online Data migration with an available network bandwidth of 10Gb/s with AWS Direct Connect
- Data size of 7.2 petabytes consisting of historical data as well as new incoming data
- Total number of files are > 1Billion
- Historical data and the incremental sync of new data sets
- Minimal on-premises footprint for migration infrastructure
- Automation, monitoring, reporting, and scripting support
Evaluating solutions
Initially, we looked at a vendor product that performs historical data migrations, subsequent transfers of newly ingested data, and the ability to perform an open file sync from the source Cloudera system. The overall feature set was compelling and it met our primary requirements. However, we decided not to proceed due to heavy licensing costs, infrastructure requirements, and complexity when implementing at such a large scale. Additionally, it was difficult to access the software to perform proof of concept testing.
We evaluated additional solutions for migrating the HDFS data to Amazon S3, including AWS DataSync. We selected DataSync as our tool of choice because it met our primary requirements and provided flexibility to build a scale out architecture using multiple DataSync agents.
During the proof of concept, we listed the success criteria mentioned as follows and conducted a series of tests for each tool. It was a tight race and we considered the following factors:
- Agility
- Reliability
- Functionality
- Availability and scalability
- Security
- Support and future-proofing
- Cost
Among these areas, the areas of differentiation were cost, availability, and scalability. We ultimately chose DataSync based on these factors, along with the following additional reasons that influenced our decision.
- Easy set up and deployment
- AWS Command Line Interface (AWS CLI) and scripting is supported
- Incremental data transfer between source and target
- Single dashboard for monitoring
- Task based with the ability to scale
- DataSync Agents on Amazon Elastic Compute Cloud (Amazon EC2)
- Simple pricing model
Solution overview
We built a unique solution architecture for migrating our 7.2PB of Cloudera data using DataSync. The AWS team recommends that you run the DataSync agent as close to your storage system as possible for low latency access and better performance. However, in our setup we took the approach of installing all DataSync agents as EC2 instances with no on-premises footprint and utilized the high bandwidth network with consistent performance. For more information, refer to the supported DataSync agent requirements.
We applied “include filters” in each of our task executions, a unique functionality of AWS DataSync that lets you scale data transfers with multiple DataSync agents from the same source storage system targeting specific folders. With careful planning, this allowed the PoC to run smoothly. By doing this, we parallelized the DataSync tasks with multiple agents.
Building for resilience
We built a resilient architecture for the HDFS data migration by distributing the EC2 instances across Availability Zones (AZs), and grouped the agents based on tasks with “include filters.” We did not encounter any latency or performance issues, as our environment has an available 10-Gbps network pipe and a source storage system that provides consistent read throughput. Careful planning of task allocation per agent and using filters helped us optimize the data ingestion.
Tasks running in each Availability Zone utilize three DataSync agents configured with each source HDFS location. To protect against unforeseen events, two additional standby agents were deployed and activated. While DataSync tasks do not provide automatic failover between agents, standby agents can be used as ready replacements.
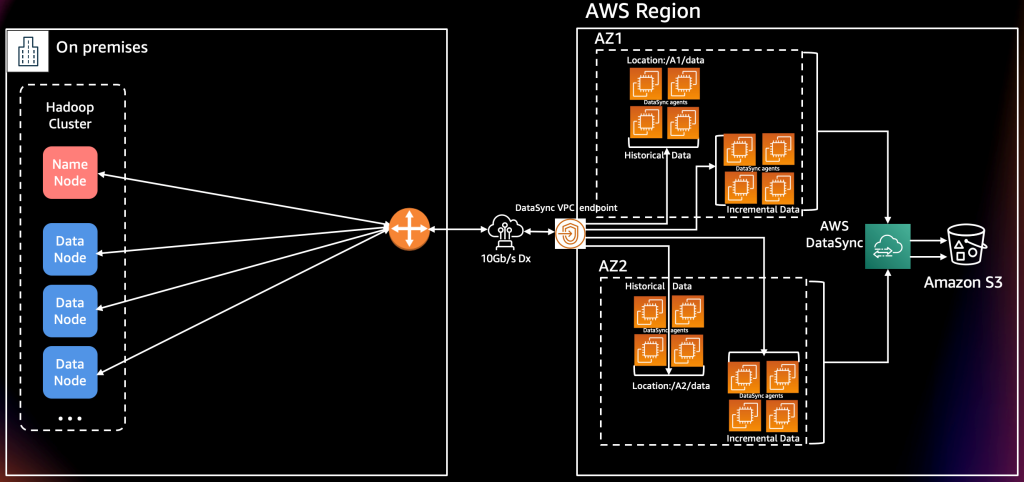
Designing for scale
AWS DataSync agents were activated using private VPC endpoints that provided a secure end-to-end connection from on premises. With the current source system configuration, we achieved the following performance metrics:
|
Source system |
Network bandwidth |
Network throughput |
Read IOPS |
|
Cloudera CDH 5.13.3, 370 Datanodes, 2 Namenodes |
10 Gb/s |
800 MB/s |
27K |
In the following source Cloudera location, we included folders in each task with a specific agent to process. Using this method, we processed 6 to 9 tasks using 9 to 12 agents across Availability Zones.
| Data Type | Source directory location | Destination location on Amazon S3 |
| Historical data | HDFS /S2/data/ | Prod S3 /s2/data |
We ran the tasks in parallel and achieved a data migration rate of up to 72 TB per day with a network utilization of 85%. This is close to 800MB/s or 2.2 TB/hr.
The DataSync agents were deployed as M5.4Xlarge instances to meet the 50 million files requirement for each task.
The following image is our strategy that we carved out for a task execution and ‘include filters’ for DataSync locations. We prioritized the datasets stored in the following HDFS directories for historical data: S1, S2, and Group. These datasets needed to be migrated in the first phase of migration. The data set consisted of greater than 6PB of historical data and a daily incremental of 125TB, which is migrated after the initial sync phase.

In addition, we ran tasks to migrate incremental file updates using the same combinations of source locations and task filters.

Conclusion
Globe Telecom’s EDO data migration project was successfully completed within the defined project timeline of four months. DataSync provided agility, flexibility, and security to build a scale out architecture for high performance and faster secure movement of data. Built-in automation, monitoring, a single dashboard view and task completion reports helped our team members focus on data migration strategy, reduced data transfer costs, and provided peace of mind during the migration phase. DataSync’s data integrity and validation checks gave us confidence in our data post-migration. We quickly kicked off the analytical data pipeline for further processing and data visualization for end users with a shorter turnaround time. DataSync streamlined our HDFS data migration journey to AWS cloud.
Thank you for reading this post. If you have any comments or questions, don’t hesitate to leave them in the comments section. For more information, please watch our demo of AWS DataSync.