AWS Executive in Residence Blog
How to Build Data Capabilities
“He uses statistics as a drunken man uses lamp posts—for support rather than for illumination.”
—Andrew Lang
When it comes to the data, it is culture first and capability second. In my previous post, I talked about how executives can create a data-driven culture in their enterprises. In this post, I am going to dive a little deeper to share my learnings for the leaders who are charged with building data capabilities to help drive that culture.
Start With the Questions Being asked, Not by Bringing “All of the Data” In
If we look at some of the most expensive enterprise project failures, spending years and a ton of money in building enterprise data warehouses or data lakes probably ranks only second to large ERP implementations. While the cloud has significantly reduced the time to market and the cost of storing, processing, and analyzing data at scale, it is important that data capabilities start with the business outcomes rather than the data sources.
To build your data capabilities, start by listing the questions being asked around the company. Look at how frequently these questions are being asked; within the most commonly asked questions, rank them in order of the business impact. This will allow you to prioritize what data you need and in what order you should bring it. Most importantly, it will allow you to incrementally deliver value from your data without having to spend time bringing “all of the data” in.
One of the tools that I use is a visual map that shows key data elements on one axis and the core business functions that rely on that data on the other. Let’s consider a simple question: What is the P&L for product X? To answer this, we’ll need to list all the different sources of revenue and cost for this product
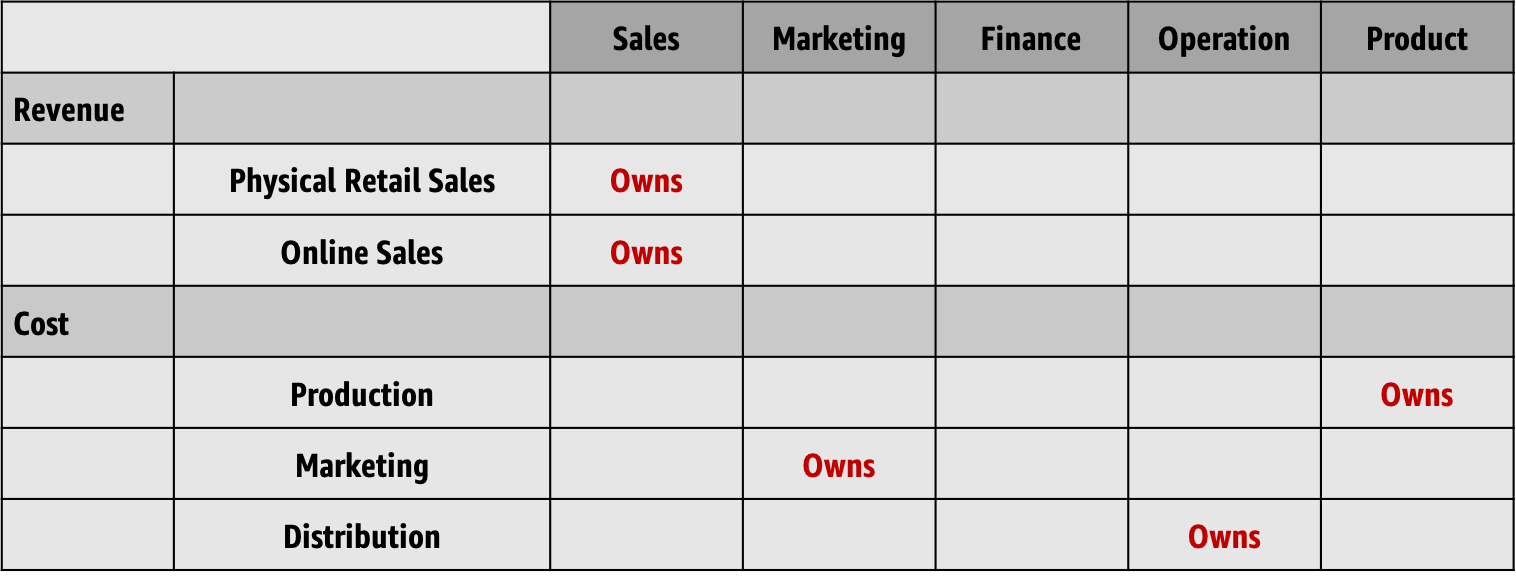
Now add who else cares about the same data elements. The chart below shows an extremely over-simplified version of this process.
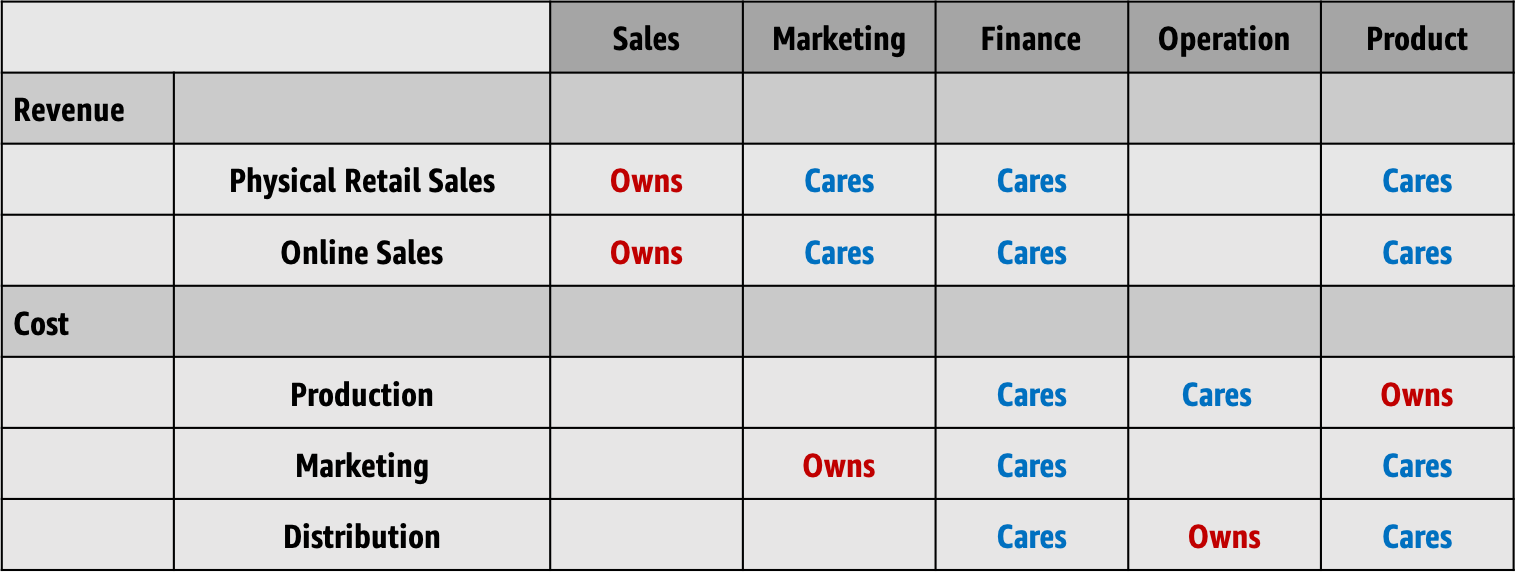
As you repeat this process with the list of prioritized questions, a picture will emerge, showing elements that drive value to multiple functions. It will also reveal what data elements you already have that can enable asking better or different questions than what you started with and what’s missing to fill the gaps. This can be a powerful visual tool to help incrementally build and prioritize your data platform without losing the sight of the big picture.
Address the Data “Black Holes”
It is critical to focus on capturing the right data as well, not just consuming it. Many key transactions within an enterprise happen in the spreadsheets, on the backs of napkins, or in workflows that are outside of any system. There’s a lot of valuable data from these workflows that goes untapped because there’s no application strategy tied to it.
Organizationally, enterprises tend to break up applications and data teams, creating a disconnect. A successful data strategy requires a tight integration with an enterprise application roadmap. If you don’t catch it, you can’t consume it.
Have a Strategy for Data Cleaning, Quality, and Reconciliation
As the enterprise changes to a data-driven culture, it is natural to experience resistance. The most common fear is the “lack of trust” in the data. It’s crucial to get ahead of this resistance by working with the data owners from the business units to define a business reconciliation process upfront. This is in addition to the technical validation and data quality.
Data quality issues can surface much later and derail a data initiative. To avoid this, run checks, identify edge cases, and clean up before bringing anything in. Sometimes data quality issues can also reveal larger organizational or business process issues. In the early part of my career, I worked on a sales data initiative for a large media company, and we found that there were 200+ different variations of a single customer record! The remedy for this turned out to be not a data cleanup process but having much larger conversations around silos within the sales function.
What I’ve also seen is that often, what is considered the “truth” is wrong. Don’t be afraid to revalidate, push back, and question the accuracy of whatever existing source of truth the new data platform is being compared to. One of the projects I worked on had a mainframe system as a source, and our reconciliation was off by a few cents on a very important measure—Cost Per Thousand (CPM). When you multiply this by millions of audience impressions, those few cents added up to millions of dollars. After spending countless late nights, we discovered that due to a limitation in the variable size, the old mainframe system was actually rounding certain numbers that our new data platform did not have to. Validation is truly about seeking the truth, not matching an existing paradigm.
Standardization is Overrated
Data is a rapidly evolving space, so be open to using the right tool for the right job rather than forcing standardization. Instead of burning cycles on consolidating tools, provide your builders with the flexibility to experiment and pivot.
When I was a CTO, we standardized our data store on Amazon S3, but beyond that we used whatever made sense from databases, ETL, API, and analytics to a consumption layer. One size does not fit all.
Keep the Data Moving
Stale data stinks! Think of your integration layer as a key part of your data capability. We used some of the same transactional APIs that were connecting our applications to populate our data layer incrementally. This eliminated yet another layer of logic that we had to maintain and validate, but more importantly, it provided our customers near real-time insights without having to wait for batch loads.
One additional benefit of having a strong API layer is the ability to create an abstraction and flexibility between your optimization or analytics layer and the data layer. In the media industry, for example, you’re constantly experimenting with partners who build a better inventory or price optimization engine. Having flexibility to not just integrate with a few but experiment with many can truly differentiate your business.
“Reporting” Ghost Towns
Don’t let your data platform be hijacked by automating, digitizing, or recreating reports that are “in circulation” but not really “in use.” Enterprises have hundreds and sometimes thousands of reports that are created and distributed but hardly ever used. When we replaced our financial system with a unified global platform, we discovered that there were over 250 existing reports slated to be in the scope. We worked diligently with our business partners and discovered that many were simply different variants because someone wanted to add a few more columns or liked different formatting. We killed a majority of them and reduced it down to a little over 50. That’s over 200 reports in just one system that no one really used!
Create a mechanism to see how often something is actually run and used—even if it’s in a beloved binder that gets generated at a set frequency for the executive team.
Make It Cool
Dashboards and data visualizations are sometimes labeled as “too elementary” and not part of an “advanced” data capability that breaks free from traditional reporting factories. I’ve found that they can be a very powerful tool for CIOs, CTOs, or CDOs to paint a picture that rest of the organization can touch and see. Don’t let them be the end; use them as means to breakdown silos, get support, and secure the funding you need to drive advanced data capabilities within the enterprise.
In my past role, we built an Alexa skill that allowed a voice interface to ask simple everyday questions of our data platform like, “How did last night’s premier do?” or “Who was the biggest advertiser on a <show> this season?” We then put Amazon Echo in some of our executive offices. That made our data platform something that you could “talk” to, making it more accessible and cooler. I would love to hear about what has worked for you in building data capabilities in your organization.
—Ishit
Twitter | LinkedIn | Blogs | Email
How to Create a Data-Driven Culture, Ishit Vachhrajani
In Search of Silver Bullets: Moving Beyond Dreaming of Data, Phil Le-Brun
The CFO as Catalyst for the Data-Driven Enterprise, AWS Executive Insights
The Power of the Data-Driven Enterprise, AWS Executive Insights