Amazon Web Services 한국 블로그
Amazon DynomoDB 자동 스케일링 기능 출시!
Amazon DynamoDB는 다양한 산업 및 사례에 걸쳐 십만이 넘는 고객을 보유하고 있습니다. 스타트업 부터 엔터프라이즈까지 다양한 규모의 고객은 전 세계 16 개 리전에서 DynamoDB의 일관된 성능을 활용합니다. 최근 경향은 DynamoDB를 사용하여 서버리스(Serverless) 애플리케이션 백엔드 저장소로 활용하는 고객이 늘고 있다는 것입니다. DynamoDB를 사용하면 서버 프로비저닝, OS 및 데이터베이스 소프트웨어 패치 수행, 고 가용성을 보장하기 위한 가용 영역 복제 구성 등의 작업이 필요 없습니다. 간단히 테이블을 만들고 데이터를 추가하기 만하면 됩니다.
DynamoDB는 응용 프로그램에 필요한 읽기 및 쓰기 용량을 설정할 수 있는 프로비저닝 용량 모델을 제공합니다. 이로 인해, 용량 걱정 없이 간단한 API 호출 또는 AWS 관리 콘솔에서 버튼 클릭으로 테이블에 대한 용량을 변경할 수 있습니다.
이에 더 나아가 오늘 DynamoDB에 자동 스케일링(Auto Scaling)을 도입하여 테이블 및 글로벌 보조 인덱스 용량 관리를 자동화 기능을 출시합니다. 이는 원하는 대상 활용 방법에 대해 읽기 및 쓰기 용량의 상한 및 하한선을 설정하면 됩니다. 그런 다음 DynamoDB는 Amazon CloudWatch 알림을 사용하여 처리량 소비를 모니터링 한 다음 필요할 때 프로비저닝 된 용량을 조정합니다. Auto Scaling은 모든 새로운 테이블과 인덱스에 대해 기본적으로 설정 되며, 기존 테이블과 인덱스에도 구성 할 수 있습니다.
DynamoDB Auto Scaling은 테이블 및 인덱스를 모니터링하여 응용 프로그램 트래픽의 변화에 따라 처리량을 자동 조정합니다. 이를 통해 DynamoDB 데이터를 보다 쉽게 관리하고 응용 프로그램의 가용성을 극대화하며 DynamoDB 비용을 줄일 수 있습니다.
함께 살펴 보겠습니다.
자동 스케일링 기능 설정 방법
이제 DynamoDB 콘솔에서 새 테이블을 만들 때, 기본 매개 변수(Parameter) 집합을 제안합니다. 기본 설정을 그대로 사용하거나 기본 설정 사용을 선택 취소하고 자체 매개 변수를 입력 할 수 있습니다.
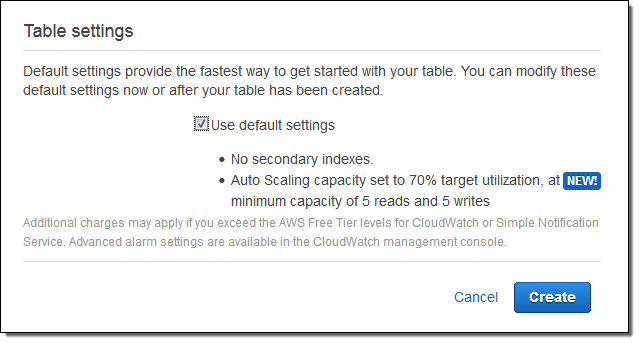
자신의 매개 변수를 입력하는 방법은 다음과 같습니다.
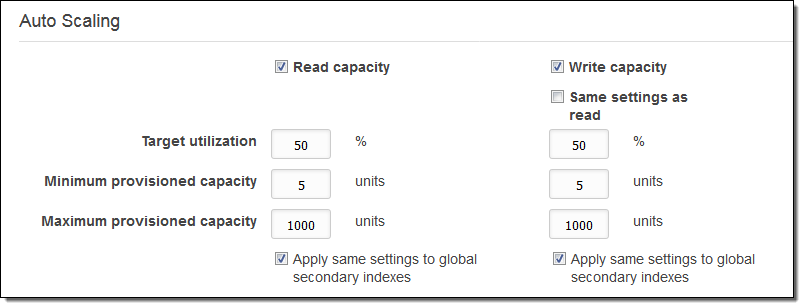
목표 사용률은 소비 용량 대 공급 용량의 비율로 표시됩니다. 위의 매개 변수를 사용하면 읽기 또는 쓰기 요청이 급작스럽게 늘어 소비 된 용량을 두 배로 늘릴 수 있는 충분한 여유 공간 (DynamoDB 읽기 및 쓰기 작업과 제공된 용량 간의 관계에 대해 자세한 사항은 용량 단위 계산 참고)이 허용됩니다. 프로비저닝 용량 변경은 백그라운드로 처리됩니다.
자동 스케일링 기능 사용해 보기
새 기능을 실제로 사용하려면 설명서 지침을 참고하세요. 나는 새로운 EC2 인스턴스를 시작하고 (sudo pip install boto3) AWS SDK for Python을 구성 (aws configure)을 합니다. 그런 다음 Python 및 DynamoDB 소스 코드를 사용하여 일부 데이터로 테이블을 만들고, 읽기 및 쓰기 용량을 각각 5 로 수동구성했습니다.
CloudWatch 측정 항목에 대한 자동 스케일링 조정의 효과를 보여줄 수 있습니다. 다음은 적용하기 전에 측정 항목 통계입니다.
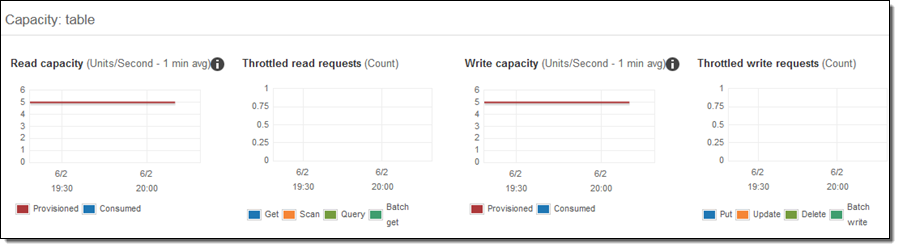
3 단계에서 코드를 수정하여 1920 년에서 2007 년 사이의 임의의 연도에 대한 쿼리를 지속적으로 발행하고 코드의 단일 복사본을 실행 한 다음 1 ~ 2 분 후에 읽기 통계를 확인했습니다.
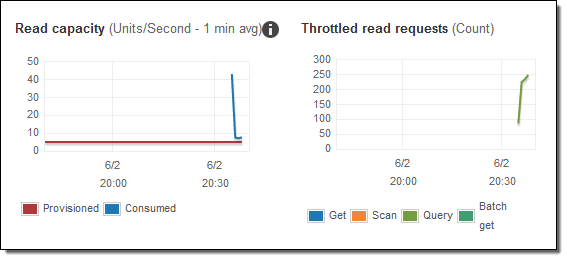
소비 용량은 제공된 용량보다 높으므로, 읽기 트래픽 제한이 발생합니다. 자동 스케일링을을 한번 적용해 봅시다. 콘솔로 돌아와 내 테이블의 Capacity 탭을 클릭했습니다. 그런 다음 Read capacity을 클릭하고 기본값을 그대로 사용하고 Save을 클릭했습니다.
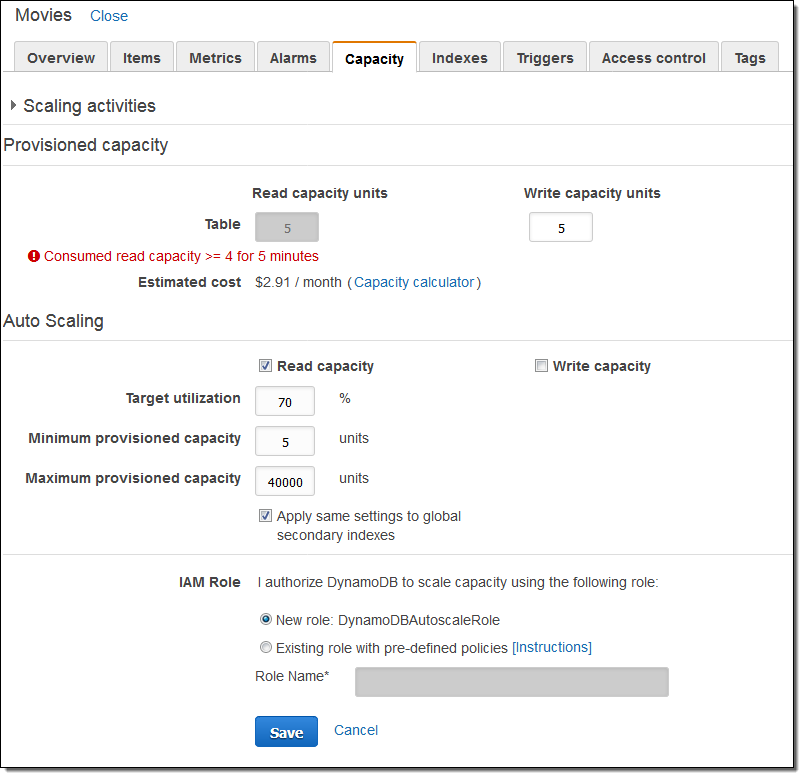
DynamoDB 읽기 용량의 자동 확장을 관리하기 위해, 새로운 IAM 역할 (DynamoDBAutoscaleRole)과 한 쌍의 CloudWatch 알람을 생성했습니다.
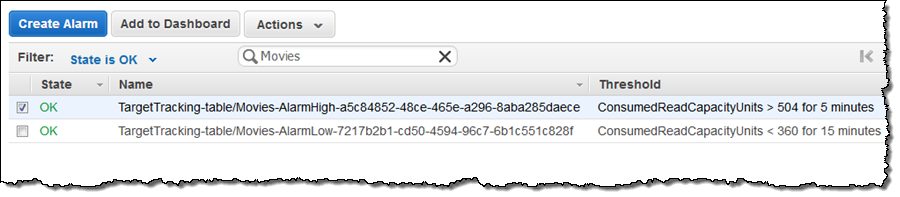
DynamoDB 자동 스케일링은 알람 임계 값을 관리하여, 스케일링 프로세스가 진행됩니다. 첫 번째 알림이 시작되어, 추가 읽기 용량이 프로비저닝 된 동안 테이블 상태가 업데이트로 변경되었습니다.
변경 사항은 몇 분 내에 읽기 측정 항목에서 볼 수 있습니다.
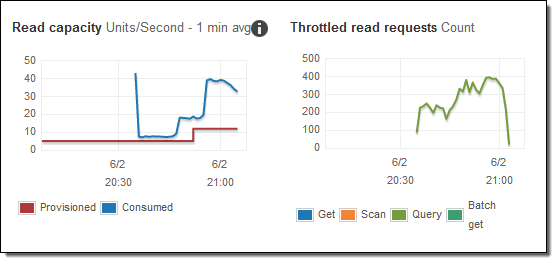
수정 된 쿼리 스크립트의 몇 가지 추가 복사본을 시작하고 추가 용량이 프로비저닝 된 것을 확인했습니다 (빨간색 선으로 표시).
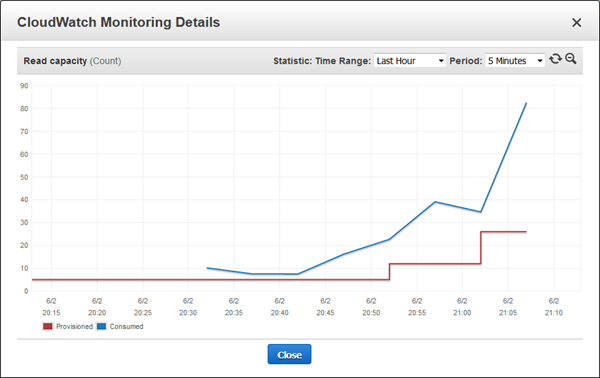
모든 스크립트를 끄고, 스케일 다운 알람이 울리기를 기다리는 후 얻은 결과 입니다.
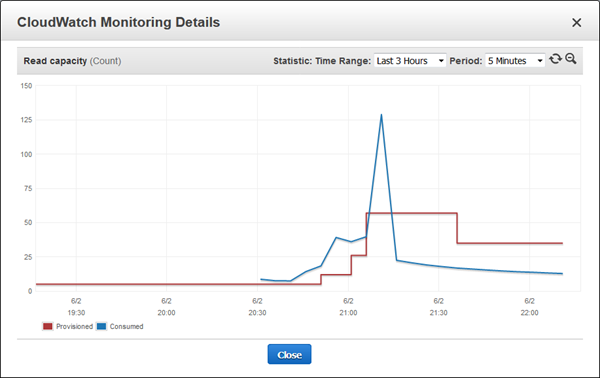
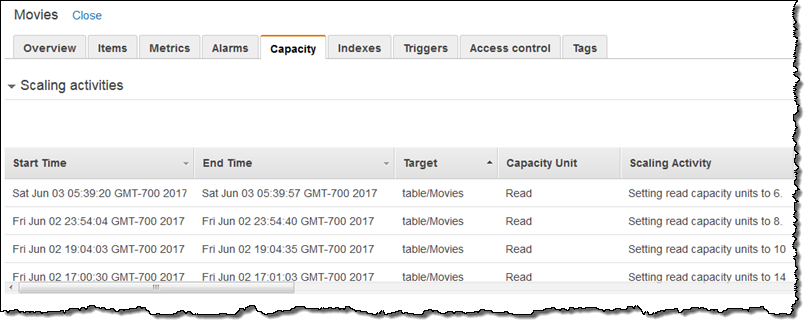
다음날 아침 Scaling activities을 점검하여, 알람이 밤새 여러 번 트리거되었음을 확인했습니다.
이는 측정 항목에도 표시되었습니다.
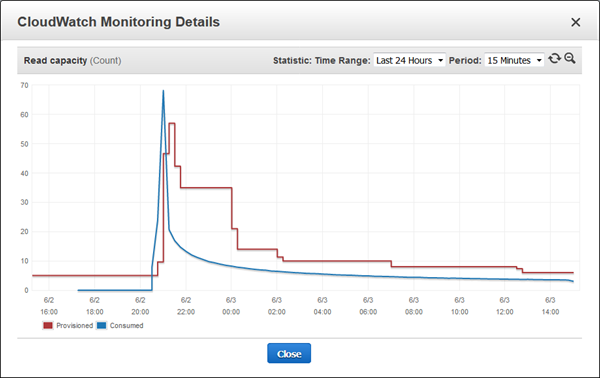
지금까지 예상 용량에 맞게 읽기 용량을 설정하고, 초과 용량 (파란색 선과 빨간색 선 사이의 공간)을 돈을 지불함으로써 이러한 상황을 대비할 수 있습니다. 또한, 트래픽을 줄이면 너무 낮게 설정하고 모니터링하는 것을 잊어 버리고 트래픽이 소진 될 때 용량이 소진 될 수 있었습니다. 그러나, 자동 스케일링을 사용하면 수요가 증가하면, 더 많은 용량이 필요하다는 것을 나타내는 자동 응답과 용량이 더 이상 필요하지 않을 때 또 다른 자동 응답을 얻을 수 있습니다.
알아 두어야 할 점
DynamoDB Auto Scaling은 다소 예측 가능하고 일반적으로 주기적인 방식으로 변화하는 요청 속도를 수용하도록 설계되었습니다. 예기치 못한 읽기 작업의 급격한 변화를 수용 해야하는 경우, Amazon DynamoDB Accelerator (DAX) – 읽기 작업을 위한 인-메모리 캐싱 기능)와 자동 스케일링 기능을 함께 사용해야 합니다. 또한 AWS SDK는 급격한 요청에 제한된 읽기 및 쓰기 요청을 감지하고 적절한 지연이 있은 후, 다시 시도합니다.
앞서 언급한 DynamoDBAutoscaleRole는 테이블 및 인덱스를 확장 할 수 있도록 자동 스크롤링에 필요한 권한을 제공합니다. 이 역할과 이 역할이 사용하는 권한에 대한 자세한 내용을 보려면 DynamoDB 자동 스케일링에 대한 사용자 권한 부여를 참고하시기 바랍니다.
자동 스케일링 정책 활성화 및 비활성화하는 기능을 포함하여 AWS CLI 및 API를 완벽하게 지원합니다. 예측 가능한 시간 제한이 있는 트래픽이 발생하는 경우, 프로그래밍 방식으로 자동 스케일링 정책을 비활성화하고 설정된 시간 동안 더 높은 처리량을 제공 한 다음 나중에 자동 확장을 다시 활성화 할 수도 있습니다.
DynamoDB의 제한 페이지에서 언급했듯이 필요한 만큼 자주 필요한 용량만큼 (요청에 따라 늘릴 수 있는 계정 당 한도에 따라) 프로비저닝 된 용량을 늘릴 수 있습니다 각 테이블 또는 글로벌 보조 인덱스에 대해 용량을 하루에 최대 9 회까지 줄일 수 있습니다.
정기적으로 DynamoDB 요금에 따라 제공하는 용량에 대해 비용을 지불합니다. 추가 절감을 위해 DynamoDB 예약 용량을 구입할 수도 있습니다.
정식 출시
이 기능은 현재 서울 리전을 포함한 모든 지역에서 지금 사용할 수 있습니다!
— Jeff;
이 글은 New – Auto Scaling for Amazon DynamoDB의 한국어 번역입니다.