Amazon Web Services 한국 블로그
Amazon Redshift 동시성 확장(Concurrent Scaling) 기능 출시
![]() Amazon Redshift는 엑사바이트 규모까지 확장이 가능한 데이터 웨어하우스입니다. 현재 NTT DOCOMO, Finra 및 Johnson & Johnson을 비롯한 수많은 AWS 고객이 Redshift를 사용하여 미션 크리티컬 BI 대시보드를 실행하고 실시간 스트리밍 데이터를 분석하고 예측 분석 작업을 실행합니다.
Amazon Redshift는 엑사바이트 규모까지 확장이 가능한 데이터 웨어하우스입니다. 현재 NTT DOCOMO, Finra 및 Johnson & Johnson을 비롯한 수많은 AWS 고객이 Redshift를 사용하여 미션 크리티컬 BI 대시보드를 실행하고 실시간 스트리밍 데이터를 분석하고 예측 분석 작업을 실행합니다.
그런데, 문제는 사용자 피크 시간에 동시 쿼리의 수가 증가할 때 발생합니다. 다수의 비즈니스 분석가가 모두 BI 대시보드로 이동하거나 오래 실행되는 데이터 과학 워크로드가 다른 워크로드와 리소스를 경합하는 경우 Redshift는 클러스터에서 충분한 컴퓨팅 리소스를 사용할 수 있을 때까지 쿼리를 대기열에 배치합니다. 이는 모든 작업을 완료하기 위한 동작이지만 피크 시간에 성능 저하가 발생한다는 것을 의미합니다. 이때 선택할 수 있는 옵션은 두 가지입니다.
- 피크 요구 사항을 충족하기 위해 클러스터를 오버프로비저닝합니다. 이 옵션은 즉각적인 문제를 해결하지만 리소스 및 비용이 필요 이상으로 낭비됩니다.
- 일반적인 워크로드에 맞춰 클러스터를 최적화합니다. 이 옵션을 사용하는 경우 피크 시간에 결과가 나오는 시간이 더 오래 걸리므로 중요한 비즈니스 의사 결정이 지연될 수 있습니다.
새로운 동시성 확장 (Concurrent Scaling) 기능
동시성 확장 (Concurrency Scaling)을 사용하면 사실상 무제한의 동시 사용자 및 동시 쿼리를 일관되게 빠른 쿼리 성능으로 지원할 수 있습니다. 따라서, 추가적인 쿼리 처리 성능을 필요에 따라 Redshift 클러스터 성능을 확장할 수 있습니다. 이 작업은 몇 초 내에 투명하게 수행되며 워크로드가 수백 개 동시 쿼리까지 증가하더라도 빠르고 일관적인 성능을 제공합니다. 추가 처리 성능은 몇 초 내에 준비되며 사전 준비 또는 사전 프로비저닝이 필요하지 않습니다. 초당 청구 금액으로 사용한 만큼만 요금을 지불하면 되며 기본 클러스터를 실행하는 동안 24시간마다 1시간의 동시 조정 클러스터 크레딧이 누적됩니다. 추가 처리 성능은 더 이상 필요하지 않은 경우 제거되므로 앞서 설명한 버스트 사용 사례를 해결하기에 매우 적합합니다.
특정 사용자 또는 대기열에 버스트 성능을 할당할 수 있으며 기존 BI 및 ETL 애플리케이션을 계속해서 사용할 수 있습니다. 동시 조정 클러스터는 많은 형태의 읽기 전용 쿼리를 처리하는 데 사용되며 유연성을 추가로 제공하기 위한 작업을 진행 중입니다. Concurrency Scaling에서 자세한 내용을 확인할 수 있습니다.
동시성 확장 기능 활용하기
기존 클러스터에서 이 기능을 몇 분 내에 활성화할 수 있습니다! 테스트용으로 만들어진 새 Redshift 파라미터 그룹에서 시작하는 것이 좋으므로 새 파라미터 그룹 하나를 생성합니다.
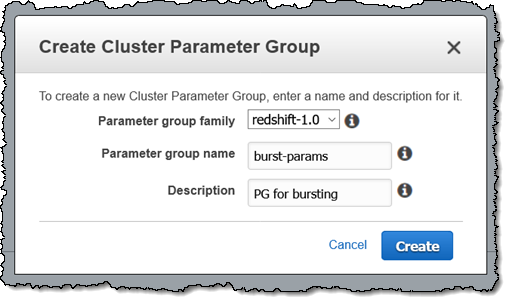
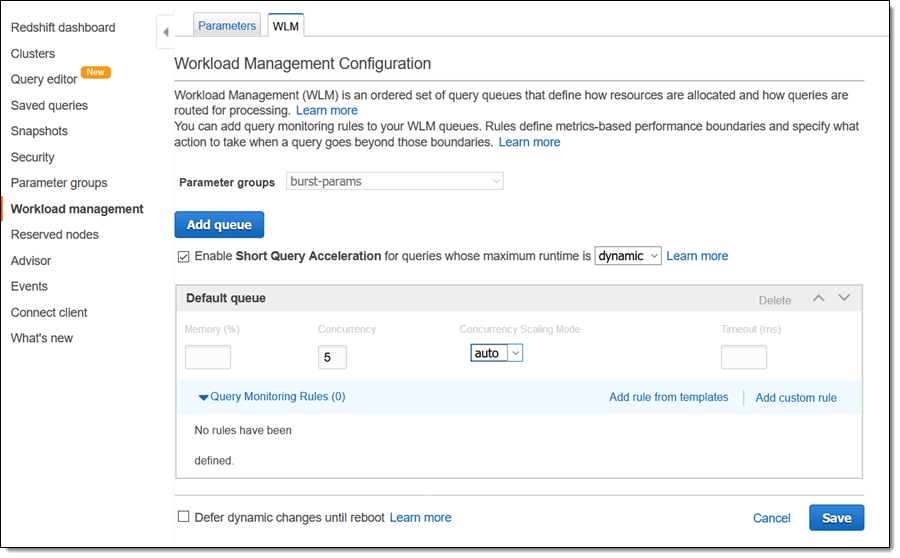
클러스터의 [Workload Management Configuration]을 편집하고 새 파라미터 그룹을 선택한 다음 [Concurrency Scaling Mode]를 [auto]로 설정하고 [Save]를 클릭합니다.
 [Cloud Data Warehouse Benchmark Derived From TPC-DS]를 테스트 데이터 및 테스트 쿼리의 소스로 사용할 것입니다. DDL을 다운로드하고 AWS 자격 증명을 사용하여 사용자 지정한 다음 psql을 사용하여 클러스터에 연결하고 테스트 데이터를 생성합니다.
[Cloud Data Warehouse Benchmark Derived From TPC-DS]를 테스트 데이터 및 테스트 쿼리의 소스로 사용할 것입니다. DDL을 다운로드하고 AWS 자격 증명을 사용하여 사용자 지정한 다음 psql을 사용하여 클러스터에 연결하고 테스트 데이터를 생성합니다.
이 DDL은 테이블 및 로드를 생성하고 S3 버킷에 저장된 데이터를 사용하여 채웁니다.
쿼리를 다운로드하고 다수의 PuTTY 창을 열어 Redshift 클러스터에 대한 유의미한 로드를 생성합니다.
병렬 쿼리의 초기 세트를 실행한 후 계속해서 쿼리를 늘립니다. 클러스터의 [Cluster Performance] 탭에서 이러한 쿼리를 확인할 수 있습니다.
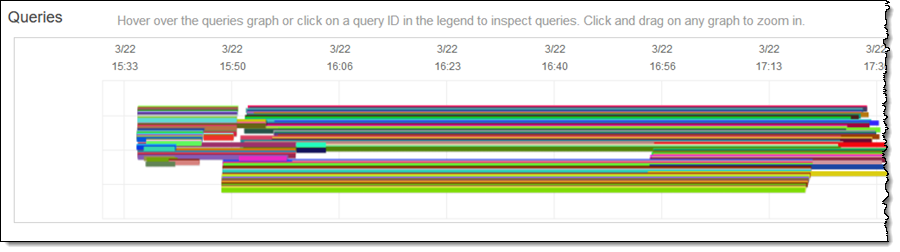
[Database Performance] 탭에서 추가 처리 성능이 필요에 따라 온라인으로 전환되고 더 이상 필요하지 않은 경우 제거되는 것을 볼 수 있습니다.
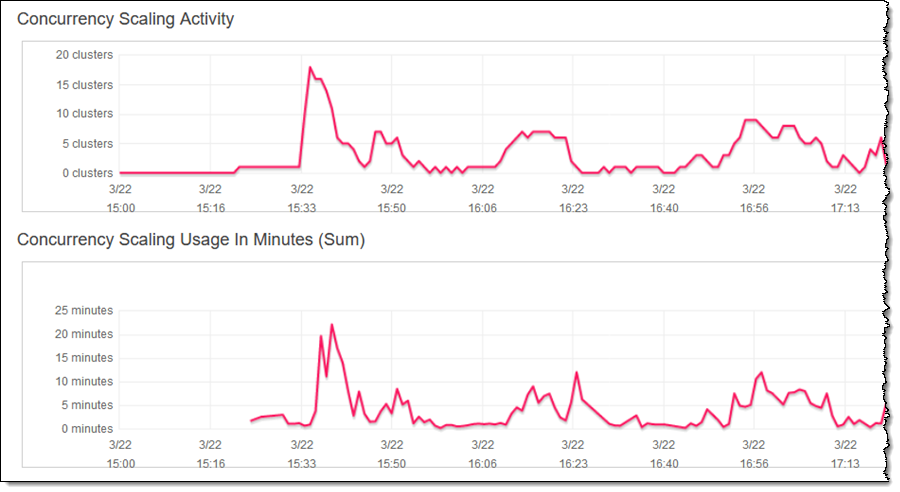
여기서 볼 수 있듯이 모든 쿼리를 가능한 신속하게 처리하기 위해 필요에 따라 클러스터가 조정됩니다. Concurrency Scaling Usage는 추가 처리 성능을 사용한 시간(초)을 보여줍니다. 앞서 설명한 것과 같이 각 클러스터에는 24시간마다 1시간의 동시 크레딧이 누적됩니다.
max_concurrency_scaling_clusters 파라미터를 사용하여 사용 가능한 동시 조정 클러스터의 수를 제어할 수 있습니다. 기본 제한은 10이지만 더 많이 필요한 경우 증가를 요청할 수 있습니다.
정식 출시
오늘부터 미국 동부(버지니아 북부), 미국 동부(오하이오), 미국 서부(오레곤), EU(아일랜드) 및 아시아 태평양(도쿄) 리전에서 동시 조정 클러스터를 사용할 수 있으며 올해 하반기에 더 많은 리전이 추가될 예정입니다.
— Jeff;