AWS 기술 블로그
Amazon S3 Files, 도입 전 반드시 확인해야 할 3가지 고려사항
소개
2026년 4월 7일 Amazon S3 Files가 정식 출시되면서 “S3 버킷을 파일시스템처럼 다룬다”는 메시지가 빠르게 확산되고 있습니다. 4월 21일에는 AWS Lambda 마운트 지원도 추가되어 Amazon EC2, Amazon Elastic Container Service(ECS) (AWS Fargate / Amazon ECS 관리형 인스턴스), Amazon EKS, AWS Lambda 네 가지 컴퓨팅에서 사용할 수 있습니다.
엔터프라이즈 고객의 도입 검토 과정에서 공식 문서만으로 답하기 어려운 질문들이 반복되었습니다.
- 비용은 어떻게 변하는가?
- 공식 예시대로 설정했는데 왜 예상보다 느린가?
- 이미 Amazon EFS나 Mountpoint for Amazon S3를 사용 중인 환경에 함께 도입해도 되는가?
이 글은 그 세 가지 영역을 공식 문서 교차검증과 Amazon CloudWatch 실측으로 정리한 도입 전 체크리스트입니다. 본 글의 실측 수치는 모두 개인 검증 계정 (ap-northeast-2, t3.medium, 2026-04 ~ 2026-05 측정)에서 나온 것입니다.
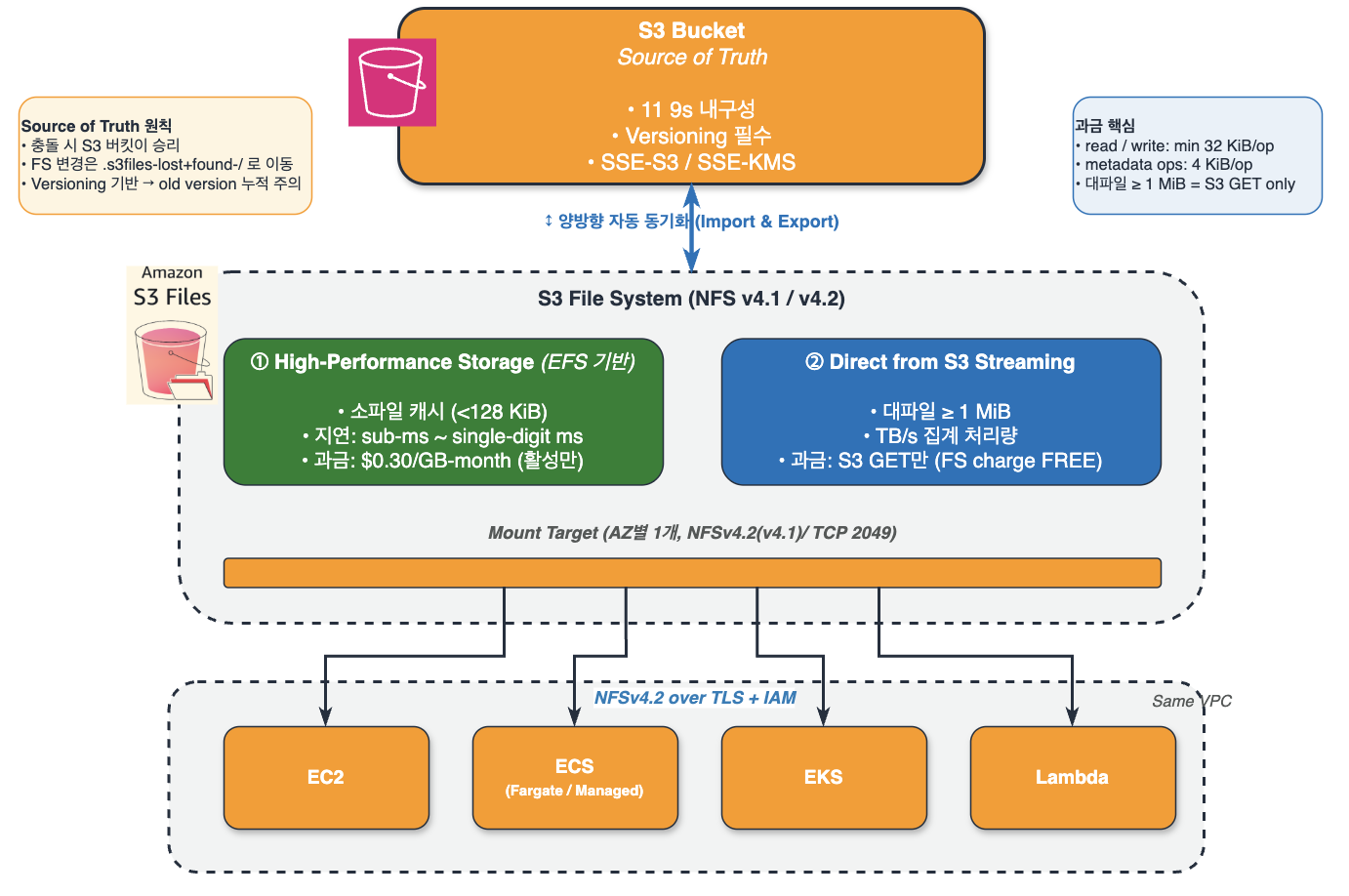
그림 0. Amazon S3 Files 의 이중 스토리지 계층 모델. 본 글에서 다루는 32 KiB 최소 과금, sizeLessThan 임계값, 1 MiB 읽기 경계, Mountpoint 충돌 시 Source of Truth 원칙은 모두 이 모델 위에서 작동합니다.
사전 준비 사항
- Amazon S3 Files 기본 개념 (Working with Amazon S3 Files)
- AWS CLI 및 Amazon CloudWatch 콘솔 접근 권한
- NFS · Amazon EFS 기본 이해 (마운트 대상, 2049 포트 등)
고려사항 1 — 비용: 1 바이트를 써도 32 KiB로 과금된다
공식 과금 측정 원칙
공식 S3 Files 과금 측정 방식 문서에 명시된 청구 단위는 다음과 같습니다.
| 항목 | 최소 단위 | 의미 |
|---|---|---|
| 파일 읽기 · 쓰기 | 작업당 32 KiB | 1 바이트만 읽거나 써도 32 KiB 청구 |
| 메타데이터 읽기 · 쓰기 | 작업당 4 KiB | 메타데이터 조회 · 갱신 |
| 1 MiB 이상 대용량 읽기 | 4 KiB 메타데이터만 청구 | 데이터는 표준 S3 GET 요청으로 청구 |
| 스토리지 최소 청구 파일 | 고성능 스토리지에서는 10 KiB | 1 KiB 파일도 10 KiB 로 청구 |
추가로 공식 문서는 *”각 작업에는 최소 측정 크기가 있으며, 그 값은 다음 1KiB 단위로 올림됩니다.”*로 명시합니다. 즉 32 KiB 이상의 작업은 1 KiB 단위로 올림 처리되어, 예를 들어 35 KiB 쓰기는 35 KiB로 청구됩니다 (32 KiB + 3 KiB 올림은 발생하지 않으나, 32 KiB 이상은 정확히 다음 1 KiB 경계까지).
원칙으로만 보면 평이하게 읽힐 수 있는 문장이지만, 이 조합이 소형 파일 대량 워크로드를 즉시 안티 패턴으로 만드는 핵심입니다.
실측 — CloudWatch가 말해주는 진실
1 KiB 파일 100개를 작성합니다.
# t3.medium 한 대에서 실행
for i in $(seq 1 100); do
dd if=/dev/urandom of=/mnt/s3files/small-$i.bin \
bs=1024 count=1 2>/dev/null
done실제 데이터 총량은 100 KiB입니다. 약 10 분 뒤 CloudWatch AWS/S3/Files 네임스페이스의 DataWriteBytes 지표를 조회한 결과는 다음과 같습니다.
| 지표 | 값 |
|---|---|
DataWriteBytes 합계 |
3,276,800 bytes (≈ 3.125 MiB) |
DataWriteBytes 개수 |
100 |
| 평균 (합계 ÷ 개수) | 32,768 bytes = 정확히 32 KiB |
| 실제 기록한 데이터 | 100 KiB |
| 과금 배율 | 약 32 배 |
공식 문서 한 문장이 CloudWatch 숫자로 100% 일치 검증됩니다.
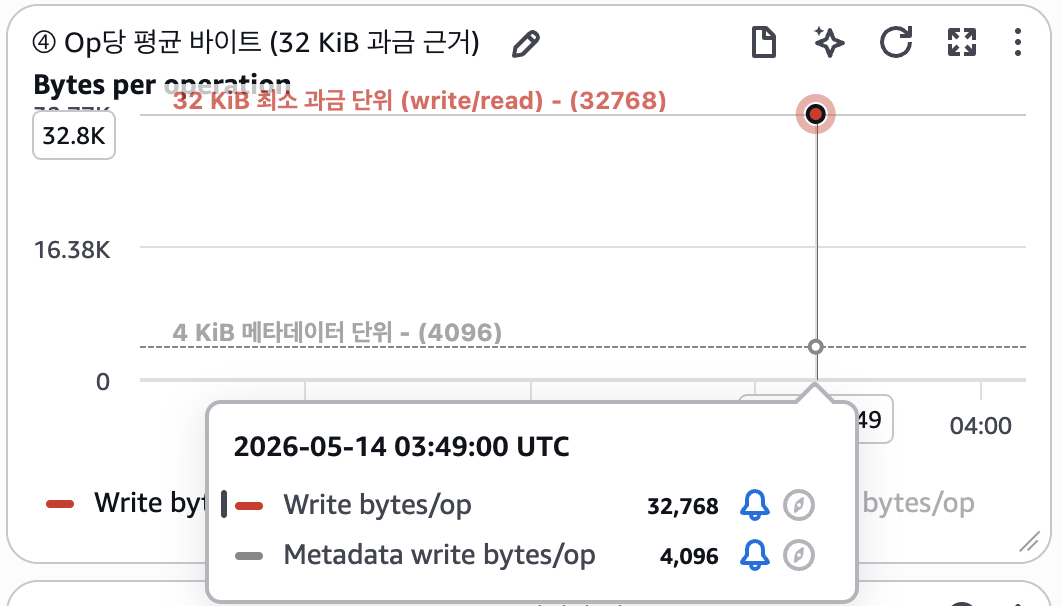
그림 1. CloudWatch — Op 당 평균 바이트. 실제로 1 KiB 씩만 썼지만 Write bytes/op 가 32 KiB 가로선에 정확히 수렴하고, Metadata write bytes/op 가 4 KiB 가로선에 정확히 수렴합니다.
실무 체크포인트 — 권장되지 않는 워크로드
평균 파일 크기가 32 KiB 미만이고 건수가 많은 워크로드는 청구 데이터가 실제 데이터의 32배까지 커질 수 있습니다. 위 실측에서 100 KiB(1 KiB × 100 건)가 3.125 MiB로 청구된 것이 그대로 적용됩니다.
도입 검토 시 다음 기준으로 판단할 수 있습니다.
| 워크로드 특성 | 32 KiB 영향 |
|---|---|
| 평균 파일 크기 ≥ 1 MiB | 거의 없음 — 적합 |
| 평균 파일 크기 < 32 KiB, 건수 적음 | 미미 — 사용 가능 |
| 평균 파일 크기 < 32 KiB, 건수 많음 (IoT 로그·트랜잭션 등) | 안티 패턴 — 사전 비용 시뮬레이션 필수 |
| 데이터베이스 WAL · append log 같은 바이트 범위 쓰기 빈번 | 안티 패턴 — 매 쓰기가 32 KiB 청구 (단 append의 경우 파일 전체를 고성능 스토리지로 가져오지는 않음 — UploadPartCopy 자동 적용) |
소형 파일 대량 적재 패턴이라면 Amazon Data Firehose 같은 스트림 적재 서비스로 일괄 처리 후 S3에 적재해 평균 객체 크기를 키운 뒤 S3 Files로 마운트하거나, 워크로드 특성에 따라 다른 서비스를 검토하는 것이 비용 효율적입니다.
고려사항 2 — 성능: 설정값이 적용되는 방식과 최적화 포인트
sizeLessThan은 가져오는 방향에만 적용된다
많은 사용자가 sizeLessThan = 128 KiB로 설정하면 “128 KiB 이상 파일은 고성능 스토리지(High-Performance Storage, HPS)에 올라가지 않는다”고 이해합니다. 그러나 이 임계값은 S3에서 고성능 스토리지로 데이터를 가져오는 방향에만 적용됩니다.
공식 S3 Files 과금 측정 방식은 다음과 같이 명시합니다.
“모든 파일 쓰기는 크기에 관계없이 고성능 스토리지에 저장되며, 최소 32 KiB로 과금됩니다. “
즉
sizeLessThan = 0으로 설정해도 파일시스템을 통해 쓴 데이터는 반드시 고성능 스토리지를 경유합니다.
| 방향 | sizeLessThan 적용 |
|---|---|
| S3 → 고성능 스토리지 (가져오기, 기존 파일 읽을 때) | ✅ 적용 |
| 클라이언트 → 고성능 스토리지 (쓰기, 새 파일 쓸 때) | ❌ 미적용 — 항상 고성능 스토리지 경유 |
100 MiB × 10 파일을 sizeLessThan 기본값 (128 KiB) 상태에서 썼을 때 CloudWatch StorageBytes가 정확히 +1 GB 증가했습니다. 쓰기는 전량 고성능 스토리지에 적재된 것입니다.
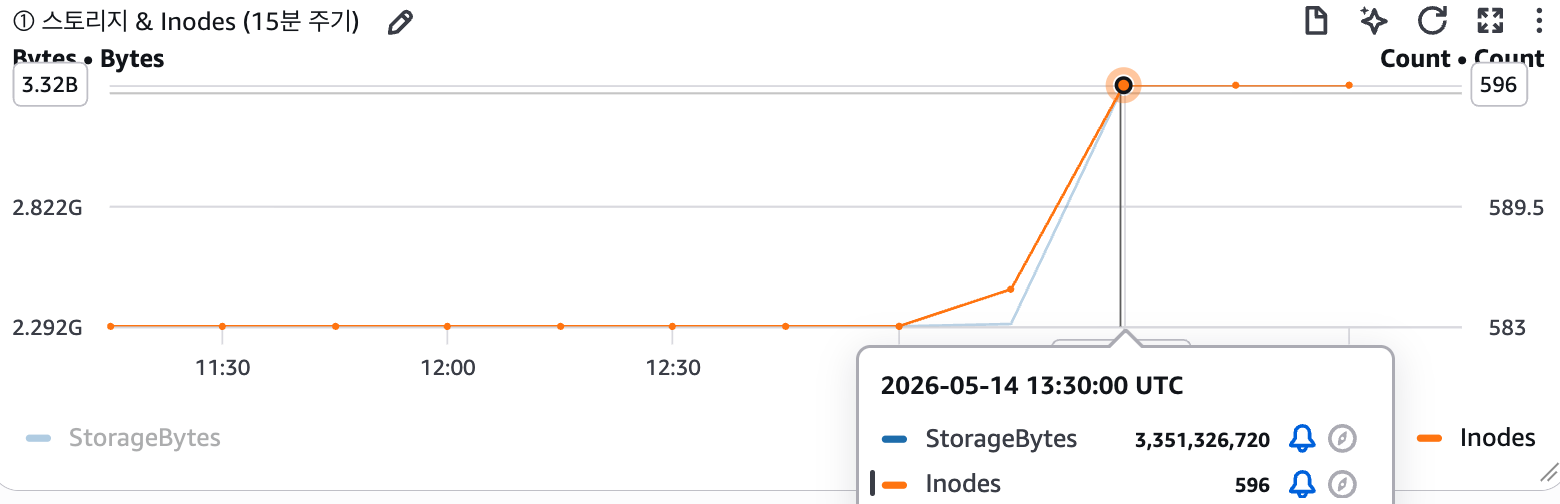
그림 2. CloudWatch StorageBytes & Inodes — 100 MiB × 10 쓰기 직후 기준 처리량 2.292 GB → 3.351 GB (+1 GB), Inodes도 +10 (10 개 파일).
Q: S3 게이트웨이 엔드포인트가 있으면 쓰기가 1 MiB 이상일 때 S3로 직접 가지 않나요?
아닙니다. 1 MiB 이상 직접 S3 서빙 규칙은 읽기 전용입니다. 쓰기 경로는 크기에 관계없이 항상 고성능 스토리지를 경유하며, S3 게이트웨이 엔드포인트의 효과는 다른 형태로 나타납니다 (아래 별도 섹션 참조).
S3 게이트웨이 엔드포인트 — 읽기 경로 환경별 비용
S3 Files의 콜드 읽기(고성능 스토리지에 캐시되지 않은 파일을 처음 읽는 경우)는 efs-proxy 데몬이 클라이언트 측에서 약 30개의 병렬 HTTPS 연결을 열어 S3에서 직접 데이터를 가져옵니다. 이 경로는 클라이언트 EC2의 아웃바운드 네트워크 환경에 따라 비용 구조가 다릅니다.
직접 검증한 결과를 1 GB 콜드 읽기 기준으로 정리하면 다음과 같습니다.
| 클라이언트 서브넷 환경 | S3 직접 읽기 경로 | S3 Files 읽기 청구 | NAT 데이터 처리 | 합계 (1 GB) |
|---|---|---|---|---|
| 게이트웨이 엔드포인트 있음 | 엔드포인트 경유 | $0 (4 KiB 메타데이터) | $0 | $0 |
| 엔드포인트 없음, NAT 있음 | NAT 경유 | $0 (4 KiB 메타데이터) | $0.045/GB | $0.045 |
| 엔드포인트도 NAT도 없음 (외부 연결이 없는 프라이빗 서브넷) | 차단 → 고성능 스토리지 대체 | $0.030/GB | $0 | $0.030 |
세 환경 모두 비용 구조가 다릅니다. 표의 세 번째 시나리오 (엔드포인트도 NAT도 없는 외부 연결이 없는 프라이빗 서브넷) 에서는 efs-proxy가 S3에 도달하지 못해 5초 타임아웃 후 마운트 대상 ENI의 고성능 스토리지 읽기로 대체되며, 이때 CloudWatch DataReadBytes가 읽은 데이터 양만큼 청구됩니다 (실측 100 MiB 읽기 시 지연 시간 5.94 초, DataReadBytes 약 104 MB 청구).
게이트웨이 엔드포인트 자체는 무료이므로 어떤 환경이든 추가하면 비용이 $0으로 떨어집니다. 보안 강화로 NAT를 제거한 외부 연결이 없는 프라이빗 서브넷일수록 효과가 큽니다.
rsize · wsize는 자동으로 최적값이 적용된다
영문 심층 분석 글에서 흔히 잘못 인용되는 주장 중 하나는 “NFS 클라이언트의 기본 rsize가 256 KiB이므로 처리량의 약 75%가 낭비된다, 반드시 rsize=1048576,wsize=1048576 을 명시하라” 입니다. S3 Files에서는 사실이 아닙니다.
공식 S3 Files 시스템 마운트에 명확히 기술되어 있습니다.
“mount helper가 S3 Files에 최적화된 옵션 (rsize, wsize 포함)을 자동 적용합니다.”
또한 S3 Files는 반드시 mount -t s3files (또는 EKS 의 efs-csi-driver)로만 마운트할 수 있고, 일반 mount -t nfs4 IP:/ /mnt/… 식 직접 마운트는 공식적으로 지원하지 않습니다.
실측 (500 MiB 콜드 읽기):
| 시도 | 결과 |
|---|---|
mount -t s3files 자동 마운트 후 findmnt |
rsize=1048576,wsize=1048576 자동 적용 |
mount -o remount,rsize=262144 시도 |
mount.nfs4: an incorrect mount option was specified 거부 |
| 콜드 읽기 처리량 | 165 MB/s (1 MiB rsize 적용 상태) |
EC2 / ECS / EKS / Lambda 모두 사용자가 rsize · wsize를 직접 설정할 필요가 없습니다. 일반 EFS · NFS 운영 경험에서 가져온 “rsize 명시” 가이드는 S3 Files에 적용되지 않습니다.
내보내기 후에도 고성능 스토리지 비용은 즉시 해제되지 않는다
파일을 쓰고 S3로 내보내기가 완료됐더라도 고성능 스토리지 비용이 즉시 사라지지 않습니다. 공식 문서는 고성능 스토리지 만료 조건을 다음과 같이 명시합니다.
“설정된 기간 (기본 30일) 동안 접근되지 않았고, 변경사항이 S3 버킷에 동기화 완료된 경우에만 고성능 스토리지에서 자동으로 만료됩니다. “
두 조건이 모두 필요합니다.
| 시나리오 | 고성능 스토리지 비용 종료 시점 |
|---|---|
write → export → rm 삭제 |
삭제 후 약 7분 내 (실측) |
| write → export → 방치 | export 후 기본 30일 뒤 |
| write → export → 계속 읽기 | 만료 안 됨 (읽기 마다 타이머 리셋) |
따라서 파일 하나를 쓰면 기본적으로 30일치 고성능 스토리지 비용이 발생합니다. “S3로 내보냈으니 고성능 스토리지 비용은 이제 없겠다”는 가정은 성립하지 않습니다. 단, rm 으로 삭제하면 만료 기간 대기 없이 즉시 해제됩니다.
두 경계값은 서로 다른 축이다
공식 성능 사양(Performance specifications) 문서는 S3 Files의 성능 모델을 두 개의 스토리지 계층으로 설명합니다. 활성 데이터가 올라가는 고성능 스토리지와, 대용량 읽기를 처리하는 Direct from S3 두 축이 독립적으로 작동합니다.
같은 문서에서 “1 MiB 이상의 대용량 읽기는 데이터가 고성능 스토리지에 있어도 S3에서 직접 스트리밍한다” 고 기술되어 있는데, S3 Files 동기화 사용자 지정 문서는 ML 학습 권장 설정은 “10 MiB 미만 파일을 여러 epoch 반복 읽기할 때 sizeLessThan = 10 MiB *로 설정해 미리 로드하라”*고 합니다.
두 문장을 나란히 놓으면 모순처럼 보입니다. 10 MiB 파일을 캐시에 올렸는데 1 MiB 이상 읽기가 어차피 S3 direct로 간다면 캐시의 의미는 무엇일까요?
답은 두 경계값이 독립적인 축이라는 점입니다.
| 기준 | 축 | 설정 가능 |
|---|---|---|
sizeLessThan |
파일 크기 (bytes of file) | ✅ 0 ~ 48 TiB (기본 128 KiB) |
| 1 MiB 경계 | 한 번의 읽기 요청의 IO 크기 | ❌ 고정 |
정리하면, sizeLessThan은 “파일을 캐시에 올릴지 말지”를 결정하고, 1 MiB 경계는 “캐시에서 읽을지 S3에서 읽을지”를 결정합니다. 두 축이 독립적으로 평가되기 때문에 같은 10 MiB 파일이라도 애플리케이션이 어떤 읽기 IO 크기로 접근하느냐에 따라 결과가 달라집니다.
실증 — 동일 파일, 다른 IO 크기
같은 10 MiB 파일을 sizeLessThan = 10 MiB로 캐시에 미리 가져온 상태에서 두 가지 방법으로 읽습니다.
# Test A — 작은 IO: 64 KiB × 160 = 10 MiB (각 읽기 < 1 MiB)
sudo dd if=/mnt/s3files/demo/file.bin of=/dev/null bs=64K count=160 iflag=direct
# Test B — 큰 IO: 1 MiB × 10 = 10 MiB (각 읽기 ≥ 1 MiB)
sudo dd if=/mnt/s3files/demo/file.bin of=/dev/null bs=1M count=10 iflag=direct| 구분 | Test A (64 KiB × 160) | Test B (1 MiB × 10) |
|---|---|---|
| 전송 데이터 | 10 MiB | 10 MiB |
| 경로 | 캐시 히트 (FS) | S3 direct |
DataReadBytes 합계 |
≈ +10 MiB | ≈ 0 |
DataReadBytes 개수 |
≈ 160 | ≈ 0 |
MetadataReadBytes 합계 |
소량 | ≈ +40 KiB (4 KiB × 10) |
| 지연 시간 | sub-ms ~ single-digit ms | 수십 ms (S3 first-byte) |
| 과금 | FS 읽기 $0.03/GB | S3 GET requests only |
같은 데이터인데 IO 패턴 하나로 청구 경로가 갈립니다.
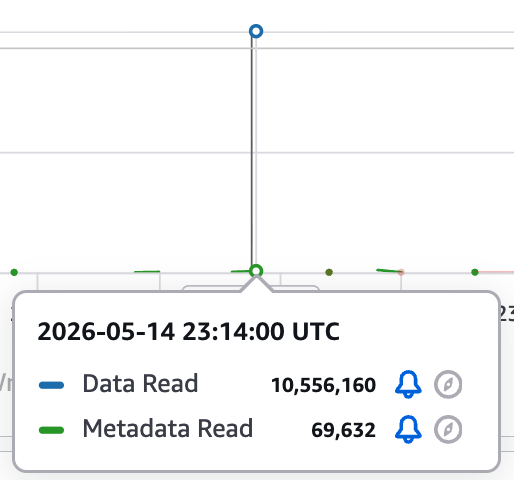
그림 3a. Test A 시점 (08:14 KST) — 같은 10 MiB 파일을 64 KiB × 160으로 읽자 모든 읽기가 1 MiB 미만이라 고성능 스토리지 캐시 히트 경로로 처리됐고, 파일시스템 읽기 청구 지표인 DataReadBytes가 10,556,160 바이트(≈ 10 MiB)로 스파이크.
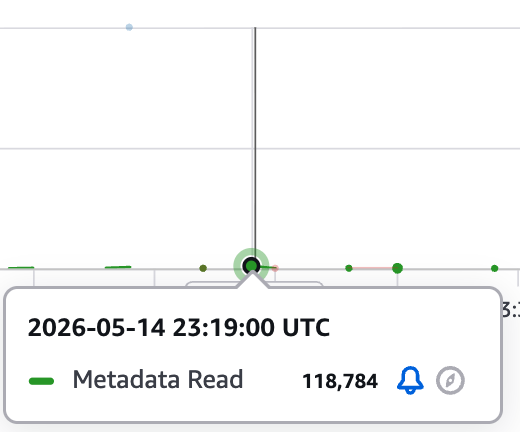
그림 3b. Test B 시점 (08:19 KST) — 같은 파일을 1 MiB × 10으로 읽자 모든 읽기가 1 MiB 이상이 되어 S3 direct 경로로 갈렸고, DataReadBytes는 0 (파일시스템 읽기 청구 미발생). MetadataReadBytes만 118,784 바이트(≈ 116 KiB)가 잡혔습니다.
워크로드별 권장 sizeLessThan
ML 학습이 작은 청크로 반복 읽는 패턴이라면 캐시 사용이 이득입니다. 반면 영상 인코딩 · 백업 복원처럼 순차적인 대용량 읽기는 sizeLessThan을 높여도 어차피 1 MiB 이상 IO로 처리되어 S3에서 직접 서빙되므로 효과가 없습니다.
| 워크로드 | 읽기 패턴 | 권장 sizeLessThan |
|---|---|---|
| ML 학습 (epoch 반복, 작은 청크) | 반복적, 작은 IO | 10 MiB (공식 예시) |
| 팀 공유 코드 · 설정 (자주 읽기) | 작은 파일, 작은 IO | 128 KiB (기본) |
| 영상 스트리밍 / 백업 복원 | 순차적인, 큰 IO | 0 |
| AI 에이전트 문서 탐색 | 한 번 스캔, 재방문이 거의 없는 | 0 (공식 에이전틱 패턴) |
| 혼합 (hot / cold prefix) | 다양 | 접두사별 규칙 분리 (최대 10 개) |
처리량 한계
공식 성능 사양 문서는 파일시스템당 읽기 IOPS 250,000, 쓰기 IOPS 50,000, 클라이언트당 읽기 처리량 3 GiB/s 의 상한을 명시합니다. 파일시스템당 IOPS 상한이 병목이 될 때는 같은 버킷에 용도별 접두사로 분리한 별도 파일시스템 생성을 검토할 수 있습니다.
CloudWatch로는 가져오는 / 내보내는 트래픽을 볼 수 없다
DataReadBytes와 DataWriteBytes는 직관적으로 “파일시스템에서 읽고 쓴 바이트 수”처럼 보이지만, S3 Files의 내부 동기화 트래픽은 여기에 포함되지 않습니다.
| 지표 | 포함되는 것 | 포함되지 않는 것 |
|---|---|---|
DataReadBytes |
NFS 클라이언트 읽기 | Export 읽기 (FS → S3 동기화) |
DataWriteBytes |
NFS 클라이언트 쓰기 | Import 쓰기 (S3 → FS 캐시 적재) |
파일을 쓰면 내보내는 과정에서 읽기 과금이 발생하고, S3에서 처음 읽을 때 고성능 스토리지로 가져오게 되면서 쓰기 과금이 발생하지만 이 두 과금은 지표에 나타나지 않습니다. CloudWatch DataReadBytes + DataWriteBytes만으로 비용을 예측하면 과소 추정될 수 있으므로, 정확한 비용 파악에는 AWS Cost Explorer의 USAGE_TYPE별 집계를 교차검증 수단으로 활용하는 것을 권장합니다.
고려사항 3 — 운영: 동일 버킷에 EFS / Mountpoint와 동시에 사용하면 충돌이 발생한다
시나리오 — 한 EC2 인스턴스, 세 가지 마운트
실무에서 자주 사용되는 구성입니다.
/mnt/s3files → S3 Files (NFS v4.2, 양방향 동기화)
/mnt/efs-compare → Amazon EFS (성능 비교 및 캐시 역할)
/mnt/s3-mountpoint → Mountpoint for Amazon S3 (FUSE, 읽기 중심)S3 Files와 Mountpoint for Amazon S3가 같은 S3 버킷을 접두사없이 마운트하고 있을 때, 두 마운트에서 같은 객체 키에 쓰기가 발생하면 충돌이 일어납니다.
충돌 메커니즘
S3 Files는 공식적으로 “S3 bucket as the source of truth” 원칙을 명시합니다. 타임라인은 다음과 같습니다.
T+0s S3 Files 에서 file.txt 작성 → 파일시스템에만 존재
T+2s Mountpoint 에서 같은 file.txt 작성 → S3 API 로 즉시 PUT → S3 버킷에 반영
T+60s S3 Files가 내보내기 시도 → S3 객체가 이미 바뀐 것을 감지
→ 충돌 판정: 파일시스템 버전은 .s3files-lost+found-{fs-id}/ 로 이동
→ S3 버킷의 값이 살아남음 (Mountpoint 버전)
이후 CloudWatch LostAndFoundFiles 지표 증가 → 알람 가능테스트 결과, 단순히 동시 마운트만 하는 것은 충돌을 일으키지 않습니다. 같은 객체 키에 양쪽에서 쓰기가 발생할 때만 충돌이 생깁니다.
해결 1: --prefix 로 경로 분리
가장 단순하고 확실한 해결책은 Mountpoint 에 --prefix를 지정해 S3 Files 와 쓰기 영역을 완전히 분리하는 것입니다.
# /etc/fstab (발췌)
fs-xxxxxxxxxxx:/ /mnt/s3files s3files _netdev,nofail 0 0
s3://DOC-EXAMPLE-BUCKET/mountpoint-data/ /mnt/s3-mountpoint mount-s3 \
_netdev,nosuid,nodev,nofail,rw,allow-other,allow-delete 0 0S3 Files는 버킷의 루트를, Mountpoint 는 /mountpoint-data/ 접두사 하위만 사용합니다. 같은 버킷이지만 경로가 분리되어 충돌이 근본적으로 차단됩니다.
해결 2: lost+found 로부터 복구
충돌이 이미 발생해 LostAndFoundFiles 알람이 발생한 경우, 파일시스템 버전을 되살리려면 수동 복구 절차가 필요합니다.
참고: S3 Files는 일반적으로 NFS extended attributes 를 미지원하지만 (S3 Files 할당량), lost+found 디렉토리 한정으로 원본 경로 조회용 xattr 이 노출됩니다 (S3 Files 동기화).
# 1. lost+found 에 어떤 파일이 있는지 확인
ls .s3files-lost+found-{fs-id}/
# 2. 원래 경로를 메타데이터로 확인
getfattr -n "user.s3files.status;$(date -u +%s)" \
.s3files-lost+found-{fs-id}/{hash}_filename --only-values
# 3. 원래 경로로 복사 (S3 Files 가 60초 뒤 S3 에 자동 export)
sudo cp .s3files-lost+found-{fs-id}/{hash}_filename /mnt/s3files/filename
# 4. lost+found 파일 수동 삭제 (자동 삭제되지 않음)
sudo rm .s3files-lost+found-{fs-id}/{hash}_filenamelost+found 파일은 자동 삭제되지 않습니다. 복구 또는 의도적 삭제 모두 수동 rm이 필요하며, 파일이 남아 있는 동안 LostAndFoundFiles 지표가 0으로 돌아가지 않아 알람이 유지됩니다.
실무 체크포인트
- 새로 S3 Files 를 도입할 때 Mountpoint가 이미 사용 중인 환경이라면
--prefix설정 여부 먼저 확인 LostAndFoundFiles > 0을 즉시 알람으로 설정 (합계 통계, 1 분 주기 업데이트)- lost+found 는 자동 청소 대상이 아니므로 복구 후 수동 삭제를 정책으로 포함
- 설계 원칙: 쓰기 주체를 한 쪽으로 고정 (Primary Writer 원칙)
설계 원칙 — prefix 우선
S3 Files 도입 시 가장 먼저 결정할 것은 “버킷 전체를 마운트할지, 접두사 단위로 좁힐지” 입니다. 다음 이유로 접두사 단위 범위 지정이 기본 권장입니다.
- 이름 변경 4시간 임계 (S3 Files 동기화): 접두사 안 객체가 약 1,200만 개 이상이면 (이름 변경이 4시간 넘는 규모) 파일시스템 생성 자체가 거부됩니다. 더 좁은 접두사로 나누거나
--AcceptBucketWarning강제 옵션이 필요합니다. S3 객체는 불변(immutable)이므로 디렉토리 변경은 접두사 하위 모든 객체를 신규 객체 쓰기 및 기존 객체 삭제로 처리됨을 기억해야 합니다. - 첫 디렉토리 목록 조회 비용: 처음
ls하는 디렉토리의 모든 파일에 대해 4 KiB 메타데이터 쓰기가 청구됩니다. 범위가 좁을수록 트래픽도 비용도 줄어듭니다. - 충돌 표면 축소: 같은 버킷에 Mountpoint 등 다른 마운트가 함께 있을 때 충돌 가능 영역이 접두사 범위만큼만 됩니다 (고려사항 ③ 참조).
- 권한·비용 분리: 한 파일시스템 = 한 IAM 정책 단위.
ml-training/,build-cache/,agent-docs/처럼 용도별 접두사 분리가 운영상 자연스럽습니다.
파일시스템은 계정당 1,000개까지 만들 수 있으므로 (S3 Files 할당량), 통째 마운트보다 접두사별 분리가 한도 측면에서도 유리합니다.
도입 판단
세 가지 고려사항을 종합한 도입 판단 흐름입니다.
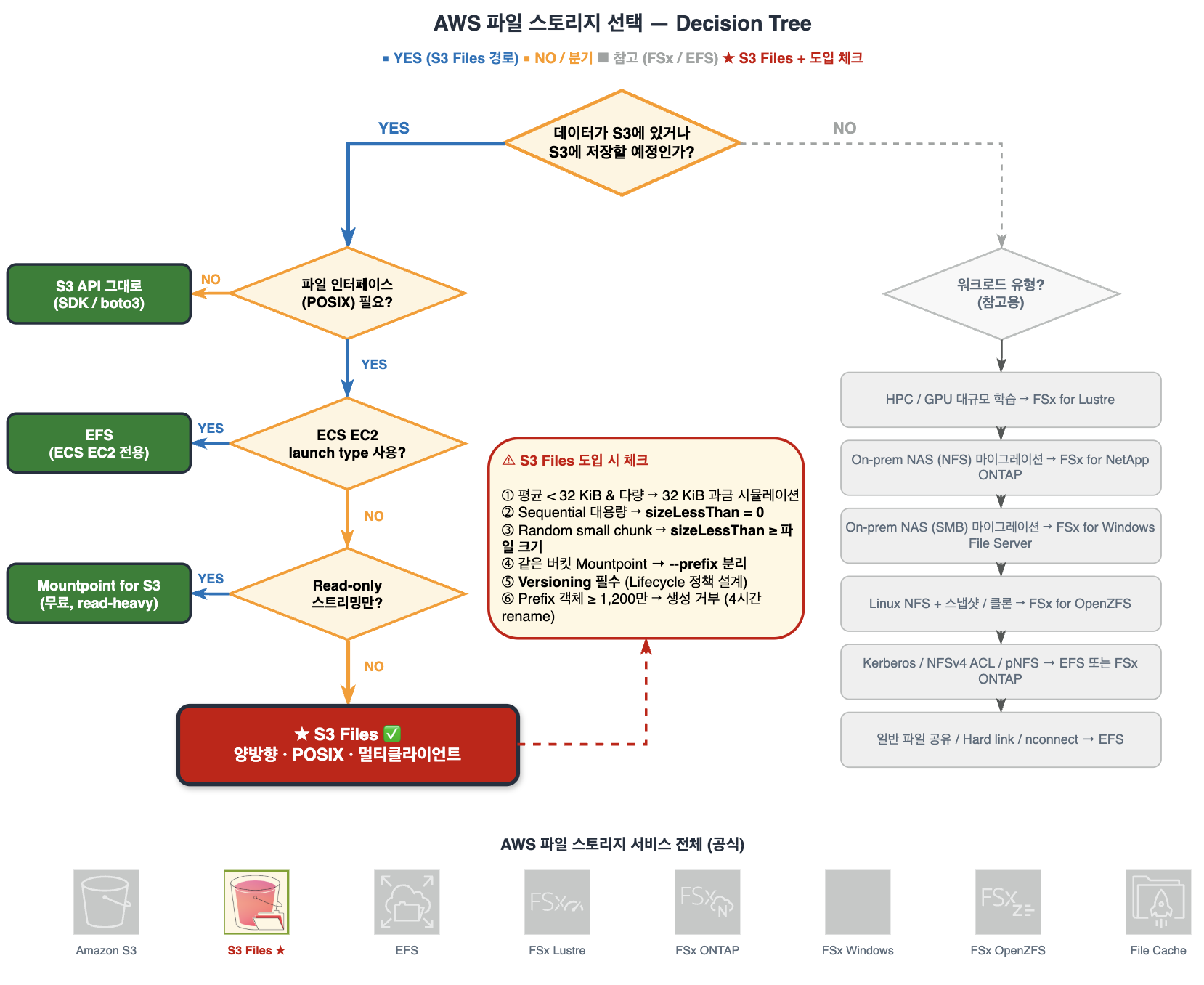
그림 4. AWS 파일 스토리지 선택 결정 트리. 좌측 경로는 S3 Files 진입 조건 (POSIX 필요 + 쓰기·rename 필요), 우측 상단 박스는 도입 후보 확정 시 점검할 6가지 체크, 우측 하단 영역은 S3 데이터가 아닐 때 검토할 다른 파일 스토리지 (Amazon FSx 시리즈 / Amazon EFS).
진입 분기 (POSIX · 쓰기·rename · ECS EC2 launch type)의 각 조건은 위 그림에서 직접 확인 가능하며, S3 Files 후보로 확정된 뒤의 점검은 아래 6가지 질문으로 이어집니다.
도입 전 확인할 6 가지 질문
검토 초기 단계에서 다음 여섯 가지만 정리해도 적합성, 예상 비용 범위, 운영 주의점을 한 번에 설명할 수 있습니다.
- 평균 파일 크기는 얼마인가 — 32 KiB 최소 과금 영향 판정
- 읽기 패턴이 순차인가 랜덤인가 —
sizeLessThan권장값 결정 - 같은 파일을 반복적으로 읽는가 — 캐시 비용 vs S3 GET 비용 트레이드오프
- 같은 버킷에 Mountpoint 나 다른 쓰기 경로가 있는가 — 충돌 위험 평가
- 컴퓨팅이 ECS EC2 시작 유형인가 — Fargate 와 관리형 인스턴스만 지원되며 EC2 시작 유형에서 S3 Files 볼륨을 구성한 작업은 실행 시 실패 (ECS에서 S3 Files 시스템 마운트)
- 버전 관리 누적 비용을 어떻게 관리할 것인가 — S3 Files는 버킷에 버전 관리 활성화 필수 (S3 Files 동기화), 모든 쓰기가 새 버전 생성. 이전 버전 누적 비용을 객체 수명 주기 관리 정책으로 설계해야 함
리소스 정리
이 글의 검증 절차를 테스트 환경에서 수행한 경우, 다음 리소스를 정리하여 불필요한 과금을 방지하세요. 특히 S3 Files 고성능 스토리지는 파일이 삭제될 때까지 시간당 비용이 발생하며, EC2 인스턴스는 종료될 때까지 시간당 비용이 청구됩니다.
- 테스트용 파일 삭제하여 고성능 스토리지 해제 (약 7분 내 기준 처리량 복귀):
sudo rm -rf /mnt/s3files/<test-prefix>/
주의: 이 명령은 데이터를 영구적으로 삭제하며 복구할 수 없습니다. 프로덕션 데이터가 아닌지 반드시 확인하세요.
- 테스트용 S3 Files 파일시스템을 생성한 경우, 마운트 해제 후 파일시스템을 삭제
- 테스트용 Mountpoint 마운트가 남아 있다면
umount /mnt/s3-mountpoint - CloudWatch 알람 (
LostAndFoundFiles)을 테스트용으로 만든 경우, 사용하지 않는다면 삭제 - 테스트용 Amazon S3 게이트웨이 엔드포인트를 생성한 경우, 삭제 절차를 따라 정리 (단, 무료 리소스이므로 유지해도 과금은 발생하지 않습니다)
- 테스트용 EC2 인스턴스를 종료하세요: AWS 콘솔에서 EC2 > 인스턴스로 이동하여 테스트 인스턴스를 선택하고 ‘인스턴스 상태 > 인스턴스 종료’를 선택하세요.
- 테스트용 S3 버킷의 버전 관리로 누적된 이전 버전을 정리하려면 S3 콘솔에서 버킷 > 관리 > 수명 주기 규칙을 확인하거나, 버킷을 완전히 삭제하려면 모든 객체 버전을 먼저 삭제한 후 버킷을 삭제하세요.
결론
Amazon S3 Files는 “객체와 파일 사이의 선택을 끝낸다”는 강한 약속으로 출시되었습니다. 다만 비용 / 성능 / 공존 세 영역에서 공식 문서를 정독하지 않으면 예상치 못한 동작과 청구로 이어질 수 있습니다.
도입 의사결정은 다음 흐름으로 정리됩니다.
- 워크로드 적합성 먼저 판단합니다. 평균 파일 크기가 32 KiB 미만인 대량 적재나 바이트 범위 쓰기가 빈번한 패턴은 안티 패턴입니다. 위 결정 트리와 6가지 질문으로 적합성을 먼저 확인하세요.
- VPC 환경부터 점검합니다. 외부 연결이 없는 프라이빗 서브넷이라면 무료인 Amazon S3 게이트웨이 엔드포인트를 추가해 고성능 스토리지 대체 비용을 회피하세요.
- 접두사 단위로 파일시스템 범위를 좁히고,
LostAndFoundFiles > 0알람을 설정하세요. Mountpoint 동시 사용이든 단독 사용이든 모두 권장되는 운영 기본기입니다.
이 글의 세 가지 고려사항은 공식 문서에 이미 기술되어 있으나 한 번의 독해로는 연결이 어려운 지점들을 실측으로 묶은 것입니다. 도입 후 “왜 이렇게 동작하는가” 라는 질문이 나오기 전에, 위 결정 트리와 6가지 질문으로 먼저 점검하시기 바랍니다.
참고 자료
- Amazon S3 Files 작업/시작하기
- S3 Files 과금 측정 방식
- 성능 사양
- S3 Files 시스템 마운트
- S3 Files 동기화 사용자 지정
- Amazon CloudWatch로 S3 Files 모니터링
- What’s New — AWS Lambda S3 Files 지원 (2026-04-21)
- Launch blog: Launching S3 Files (2026-04-07)
이 글은 개인 검증 계정에서 직접 측정한 CloudWatch 데이터와 공식 문서 교차검증을 정리한 가이드입니다