AWS 기술 블로그
Aurora PostgreSQL에서 한국어 하이브리드 검색 구현하기: pg_bigm + pgvector로 만드는 한국어 특화 RAG
한국어는 교착어 특성상 영어 기반 벡터 검색만으로는 정확한 결과를 얻기 어렵습니다. 이 블로그에서는 Amazon Aurora PostgreSQL에서 pg_bigm(바이그램 키워드 검색)과 pgvector(벡터 시맨틱 검색)를 RRF(Reciprocal Rank Fusion)로 결합한 하이브리드 검색을 구현하여, 한국어 RAG 애플리케이션의 검색 품질을 개선하는 방법을 소개합니다.
왜 한국어에는 하이브리드 검색이 필요한가?
RAG(Retrieval-Augmented Generation) 애플리케이션에서 검색 품질은 최종 답변의 정확도를 결정합니다. 벡터 검색(pgvector)은 의미적으로 유사한 문서를 찾는 데 탁월하지만, 한국어 환경에서는 다음과 같은 한계가 있습니다:
- 고유명사/전문 용어 누락: “pgvector”나 “HNSW”와 같은 기술 용어를 검색할 때, 벡터 검색은 의미적으로 유사한 다른 문서를 반환할 수 있지만, 정확히 해당 키워드가 포함된 문서를 놓칠 수 있습니다.
- 한국어 조사/어미 변화: “데이터베이스를”, “데이터베이스에서”, “데이터베이스의” 등 조사가 붙은 형태가 다양하여, 키워드 기반 검색이 여전히 중요합니다.
- 복합어 처리: “클라우드컴퓨팅”, “인공지능” 등 한국어 복합어는 임베딩 모델이 제대로 분리하지 못하는 경우가 있습니다.
반면 키워드 검색(pg_bigm)은 정확한 문자열 매칭에 강하지만, “데이터베이스 성능을 높이려면?”과 같은 자연어 질문에는 대응하지 못합니다. 두 방식을 결합하면 각각의 약점을 보완할 수 있습니다.
| 검색 방식 | 강점 | 약점 | 인프라 관점 |
|---|---|---|---|
| pg_bigm (키워드) | 정확한 용어 매칭, 한국어 조사 처리 | 동의어/문맥 이해 불가 | GIN 인덱스 스토리지 사용 |
| pgvector (시맨틱) | 의미적 유사도, 자연어 질문 대응 | 정확한 키워드 매칭 약함 | HNSW 인덱스 메모리 의존 |
| 하이브리드 (RRF) | 두 방식의 상호 보완 | 튜닝 포인트 증가 | 복합 연산 필요 |
아키텍처 개요
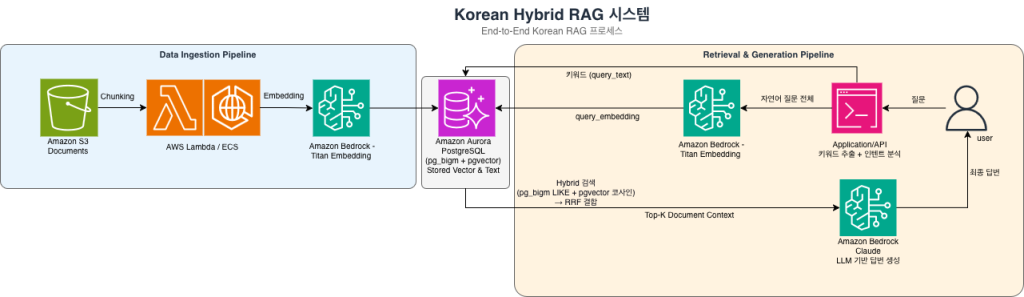
위 다이어그램은 한국어 하이브리드 RAG 시스템의 전체 데이터 흐름을 보여줍니다.
Data Ingestion Pipeline (데이터 수집)
- Amazon S3에 저장된 원본 문서를 AWS Lambda/ECS가 적절한 크기로 청킹합니다.
- Amazon Bedrock Titan Embeddings V2가 각 청크를 1024차원 벡터로 변환합니다.
- 원본 텍스트와 벡터 임베딩이 Amazon Aurora PostgreSQL에 저장되며, pg_bigm GIN 인덱스와 pgvector HNSW 인덱스가 생성됩니다.
Retrieval & Generation Pipeline (검색 및 응답 생성)
- 사용자가 한국어 질문을 입력하면, Application/API 레이어에서 키워드 추출과 인텐트 분석을 수행합니다.
- 추출된 키워드(
query_text)는 pg_bigm 키워드 검색에, 자연어 질문 전체는 Bedrock Titan을 통해 쿼리 임베딩(query_embedding)으로 변환되어 pgvector 시맨틱 검색에 사용됩니다. - Aurora PostgreSQL 내부에서 두 검색 결과가 RRF로 결합되어 Top-K 관련 문서가 반환됩니다.
- 반환된 문서 컨텍스트를 기반으로 Amazon Bedrock Claude가 최종 한국어 답변을 생성합니다.
1단계: 환경 설정
확장 설치
Aurora PostgreSQL 12.9 이상에서 pg_bigm을, 15.3 이상(14.8, 13.11 이상)에서 pgvector를 사용할 수 있습니다. 본 블로그의 예제는 Aurora PostgreSQL 16.6에서 테스트되었습니다.
테이블 및 인덱스 설계
2단계: pg_bigm — 한국어 키워드 검색의 핵심
왜 pg_bigm인가?
PostgreSQL의 기본 전문 검색(tsvector)은 영어 중심 파서를 사용하여 한국어 조사를 처리하지 못합니다. 예를 들어 “대한민국”으로 검색할 때 “대한민국은”, “대한민국의”, “대한민국에서”를 찾지 못합니다.
pg_bigm은 텍스트를 2글자(바이그램) 단위로 분할하여 인덱싱하므로, 조사가 붙어도 원래 단어의 바이그램이 모두 포함되어 한국어 부분 문자열 매칭에 효과적입니다.
한국어 위키백과 100,000건에서 테스트한 결과, pg_bigm은 한국어 조사가 붙은 문서까지 포함하여 tsvector보다 훨씬 많은 문서를 찾습니다.
| 검색어 | tsvector 매칭 | pg_bigm 매칭 | pg_bigm 우위 | 설명 |
|---|---|---|---|---|
| 대한민국 | 14,465건 | 27,846건 | 92% | pg_bigm은 “대한민국은/의/을/에서” 등 조사 형태 모두 포함 |
| 서울 | 5,629건 | 12,303건 | 119% | “서울에서/까지/의” 등 포함 |
| 데이터베이스 | 379건 | 588건 | 55% | “데이터베이스를/에서” 등 포함 |
| 인공지능 | 161건 | 226건 | 40% | “인공지능이/의/을” 등 포함 |
| 경제 | 3,153건 | 7,980건 | 153% | “경제적으로/경제를” 등 포함 |
tsvector는 “대한민국”으로 검색해도 “대한민국은”(448건), “대한민국의”(19,741건) 등 조사가 붙은 문서를 찾지 못합니다. pg_bigm은 바이그램 매칭으로 조사 형태를 자연스럽게 처리합니다. 일상 한국어 단어 100개로 테스트한 결과, pg_bigm이 tsvector보다 평균 304% 더 많은 문서를 찾았습니다.
pg_bigm 유사도 검색 팁: LIKE 대신
=%연산자를 사용하면 GIN 인덱스를 활용한 유사도 기반 필터링이 가능합니다.SET pg_bigm.similarity_limit = 0.3;으로 임계값을 설정한 후WHERE content =% '검색어'를 사용하면, LIKE보다 유연한 매칭이 가능합니다.
pg_bigm 주의사항: GIN 인덱스는 텍스트를 2글자 단위로 모두 분할하여 인덱싱하므로, 인덱스 크기가 커질 수 있습니다. 문서를 500~1,000자 단위로 청킹하면 검색 정확도와 인덱스 효율 모두에 유리합니다. 대량의 문서를 초기 적재할 때는 PostgreSQL의
maintenance_work_mem파라미터를 임시로 늘려주면 인덱싱 속도를 크게 높일 수 있습니다. (예:SET maintenance_work_mem = '1GB';)
3단계: pgvector — 시맨틱 검색으로 의미 기반 매칭
pgvector의 강점
pg_bigm은 정확한 키워드 매칭에 강하지만, “데이터베이스 성능을 높이려면?”과 같은 자연어 질문이나 “한국 전쟁” → “6.25 전쟁”과 같은 동의어/관련 개념 매칭에는 대응하지 못합니다. pgvector는 임베딩 벡터 간의 코사인 유사도를 계산하여 의미적으로 관련된 문서를 찾습니다.
검색 방식별 강점 비교 — 실제 테스트 결과
한국어 위키백과 100,000건과 AWS 한국어 기술문서 960건에서 다양한 쿼리 유형으로 pg_bigm 단독, pgvector 단독, 하이브리드(RRF)를 비교했습니다.
단일 키워드 — pg_bigm과 pgvector 모두 정확
| 쿼리 | pg_bigm만 Top-1 | pgvector만 Top-1 | 하이브리드 Top-1 |
|---|---|---|---|
| 태권도 | 태권도 ✅ | 태권도 ✅ | 태권도 (kw=1, sem=1) ✅ |
| 독립운동 | 독립운동 ✅ | 독립운동 ✅ | 독립운동 (kw=1, sem=1) ✅ |
| Aurora | Aurora 모범 사례 | Aurora이란 무엇인가요? | Aurora (kw=1, sem=3) |
→ 단일 키워드에서는 세 방식 모두 관련 문서를 잘 찾습니다.
2단어 조합 Top-5 비교 — 하이브리드의 장점이 가장 극적
“한국 전쟁” 검색 Top-5:
| 순위 | pg_bigm만 | pgvector만 | 하이브리드 (RRF) |
|---|---|---|---|
| 1 | 한국 표준시 ❌ | 6.25 전쟁 ✅ | 6.25 전쟁 (kw=4, sem=1) ✅ |
| 2 | 한국 정교회 ❌ | 전쟁 | 6.25 전쟁 전투 목록 (kw=13, sem=8) |
| 3 | 한국 전쟁의 무기 목록 | 전쟁 목록 | 전쟁 (sem=2) |
| 4 | 6.25 전쟁 ✅ | 1·4 후퇴 | 전쟁 목록 (sem=3) |
| 5 | 한국지엠 ❌ | 제3차 인도차이나 전쟁 | 1·4 후퇴 (sem=4) |
→ pg_bigm만 쓰면 Top-5 중 3개가 “한국”만 매칭된 무관한 문서(“한국 표준시”, “한국 정교회”, “한국지엠”). pgvector만 쓰면 “6.25 전쟁”을 1위로 정확히 찾지만, “제3차 인도차이나 전쟁” 같은 다른 전쟁도 포함. 하이브리드는 pgvector의 시맨틱 매칭(sem=1)과 pg_bigm의 키워드 매칭(kw=4)을 결합하여 “6.25 전쟁”을 1위로 올리면서, 한국 전쟁 관련 문서가 상위에 집중.
“제주 화산” 검색 Top-5:
| 순위 | pg_bigm만 | pgvector만 | 하이브리드 (RRF) |
|---|---|---|---|
| 1 | 제주 화산섬과 용암 동굴 ✅ | 화산 (중국) ❌ | 제주 화산섬과 용암 동굴 (kw=1, sem=2) ✅ |
| 2 | 제주도 | 제주 화산섬과 용암 동굴 | 제주도 (kw=2, sem=10) |
| 3 | 제주특별자치도 | 화산 | 화산 (중국) (sem=1) |
| 4 | 한라산 | 제주 삼다수 | 화산 (sem=3) |
| 5 | 아시아의 세계유산 | 화산대 | 제주 삼다수 (sem=4) |
→ pgvector만 쓰면 “화산 (중국)”이 1위(제주와 무관한 중국 지명). pg_bigm은 “제주” 키워드로 정확히 필터링하여 “제주 화산섬과 용암 동굴”이 1위. 하이브리드는 pg_bigm의 키워드 정확 매칭(kw=1)과 pgvector의 시맨틱 상위(sem=2)를 결합하여 가장 관련성 높은 문서를 1위로 올림.
자연어 질문 — pg_bigm 완전 무력화, pgvector만 대응 가능
| 쿼리 | pg_bigm만 Top-1 | pgvector만 Top-1 | 하이브리드 Top-1 |
|---|---|---|---|
| 한국에서 가장 높은 산은 무엇인가 | (0건) | 산 ✅ | 산 (sem=1) ✅ |
| 한국 전쟁은 언제 시작되었나 | (0건) | 6.25 전쟁 ✅ | 6.25 전쟁 (sem=1) ✅ |
| 한글을 만든 사람은 누구인가 | (0건) | 한국어 한자 | 한국어 한자 (sem=1) |
| 제주도의 세계유산은 무엇인가 | (0건) | 제주 화산섬과 용암 동굴 ✅ | 제주 화산섬과 용암 동굴 (sem=1) ✅ |
→ 자연어 질문에서는 pg_bigm이 완전히 무력화(0건 매칭). 문장 전체를 LIKE로 검색하면 정확히 일치하는 문서가 없기 때문. pgvector만이 의미 기반으로 관련 문서를 찾을 수 있으며, 하이브리드에서 pgvector가 주도. “한국 전쟁은 언제 시작되었나”에서 “6.25 전쟁”을 찾아낸 것이 시맨틱 검색의 핵심 가치.
핵심: 왜 하이브리드인가?
| 쿼리 유형 | pg_bigm | pgvector | 하이브리드 |
|---|---|---|---|
| 단일 키워드 (“태권도”) | ✅ 정확 | ✅ 정확 | ✅ 양쪽 결합 |
| 2단어 (“한국 전쟁”) | ❌ 부분 매칭 실패 | ✅ 의미 매칭 | ✅ pgvector가 보완 |
| 2단어 (“제주 화산”) | ✅ 키워드 정확 | ❌ 키워드 무시 | ✅ pg_bigm이 보완 |
| 조사 포함 (“서울에서 부산까지”) | ❌ 부정확 | ✅ 의미 매칭 | ✅ pgvector가 보완 |
| 자연어 질문 | ❌ 0건 | ✅ 의미 매칭 | ✅ pgvector가 주도 |
실제 RAG 환경에서는 사용자가 어떤 형태의 질문을 할지 예측할 수 없습니다. 단일 검색 방식에 의존하면 특정 쿼리 유형에서 반드시 실패합니다. 하이브리드는 pg_bigm이 강한 영역(정확한 키워드, 고유명사)에서는 pg_bigm이 주도하고, pgvector가 강한 영역(자연어, 동의어)에서는 pgvector가 주도하여, 모든 쿼리 유형에서 안정적인 결과를 보장합니다.
4단계: RRF로 두 검색 결과 결합하기
RRF 알고리즘
RRF(Reciprocal Rank Fusion)는 서로 다른 검색 방식의 결과를 순위(rank) 기반으로 결합하는 알고리즘입니다. 각 검색 결과의 점수 스케일이 달라도 공정하게 결합할 수 있다는 것이 핵심 장점입니다.
공식: RRF_score = Σ weight / (k + rank)
k: 스무딩 상수 (기본값 60). k가 작을수록 상위권 결과에 더 큰 가중치를 부여rank: 각 검색 방식에서의 순위weight: 키워드/시맨틱 가중치 (기본값 0.4/0.6)
하이브리드 검색 내부 동작 흐름
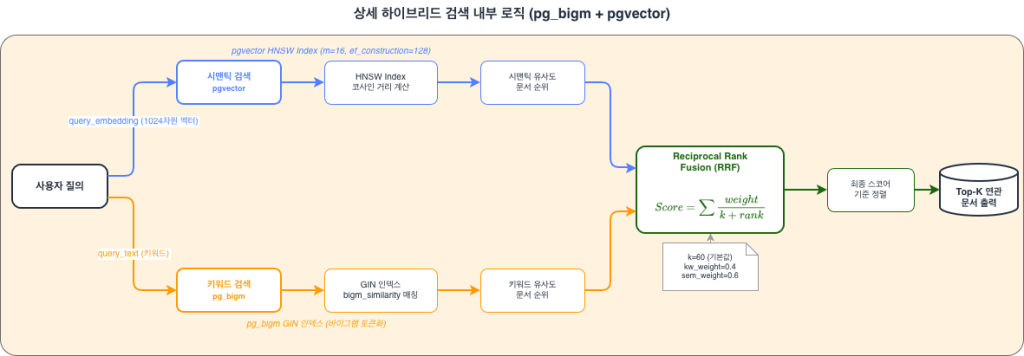
- 사용자 질의가 입력되면 두 경로로 분기됩니다:
- 시맨틱 경로:
query_embedding(1024차원 벡터)이 pgvector HNSW 인덱스를 통해 코사인 거리 기반 검색을 수행 - 키워드 경로:
query_text(키워드)가 pg_bigm GIN 인덱스를 통해 바이그램 매칭 검색을 수행
- 시맨틱 경로:
- 두 경로의 순위가 RRF에서 가중치 기반으로 결합됩니다.
- 최종 RRF 스코어 기준으로 정렬된 Top-K 문서가 반환됩니다.
RAG 파이프라인에서의 사용 주의사항:
query_text에는 자연어 질문 전체가 아닌 핵심 키워드를 전달해야 합니다. 실제 RAG 파이프라인에서는 LLM이나 형태소 분석을 통해 키워드를 추출한 뒤query_text로 전달하고, 원본 질문은query_embedding생성에 사용하는 것이 효과적입니다.
하이브리드 검색 함수 구현
사용 예시
5단계: Python RAG 애플리케이션에 통합
결론
이 글에서는 Aurora PostgreSQL에서 pg_bigm(바이그램 키워드 검색)과 pgvector(벡터 시맨틱 검색)를 RRF로 결합하여, 한국어 RAG 애플리케이션의 검색 품질을 개선하는 방법을 다뤘습니다. 한국어 위키백과 100,000건 테스트에서 pg_bigm이 tsvector보다 평균 304% 더 많은 문서를 찾았으며, 2단어 조합이나 자연어 질문에서는 하이브리드 검색이 단일 방식보다 안정적인 결과를 보였습니다.
이 글의 SQL 함수와 Python 코드를 Aurora PostgreSQL 환경에 적용하면 바로 한국어 하이브리드 검색을 시작할 수 있습니다. Amazon Aurora PostgreSQL과 Amazon Bedrock에 대한 자세한 내용은 각 제품 페이지에서 확인할 수 있습니다.