AWS 기술 블로그
Amazon Bedrock 위에서 Codex와 Claude Code 함께 쓰기: Harness Engineering으로 구현해보기
Codex + Claude Code, 이 조합 가능할까?
2026년 상반기, 터미널에서 도는 AI 코딩 에이전트는 더 이상 신기한 도구가 아니라 매일 쓰는 작업 환경이 되었습니다. 시장은 두 축으로 빠르게 수렴했습니다. 하나는 Anthropic의 Claude Code, 다른 하나는 OpenAI의 Codex입니다. 두 도구는 모두 터미널 CLI를 중심에 두면서 IDE·웹·클라우드·SDK까지 같은 엔진을 공유하고, claude -p와 codex exec 같은 헤드리스 모드로 CI에 바로 연결되며, CLAUDE.md·AGENTS.md·MCP로 컨텍스트를 주고받습니다. 그리고 2026년 6월, 의미 있는 변화가 하나 더 생겼습니다. GPT‑5.5·GPT‑5.4·Codex가 Amazon Bedrock에서 정식 출시(GA)되면서, Claude뿐 아니라 Codex도 같은 AWS 계정·같은 거버넌스 안에서 돌릴 수 있게 된 것입니다.
이 글은 한 가지 질문에서 출발했습니다. “굳이 둘 중 하나만 골라야 할까?” 독립 리뷰들의 공통된 결론은 “보편적 승자는 없다”는 것이고, 경험 많은 개발자들은 두 도구를 상황에 따라 병행한다고 보고합니다(Codersera, Zapier, Jozefiak). 그렇다면 두 도구를 섞어서 개발하면 실제로 무슨 일이 일어날까요? 한쪽이 만든 코드를 다른 쪽이 리뷰하면 더 좋아질까요, 아니면 토큰만 두 배로 쓸까요? 이 질문을 막연한 인상이 아니라 측정 가능한 실험으로 확인해보기로 했습니다. 동일한 게임을 8가지 협업 방식으로, 두 가지 난이도로, 각각 3번씩, 모두 합쳐 48번 만들게 하고, 토큰·시간·비용·기능 점수·행동 특징을 전부 기록했습니다. 그리고 그 실험을 가능하게 한 것은 모델이 아니라, 두 에이전트를 엮는 하네스(harness) 였습니다.
이 글에서는 Bedrock에서 두 CLI를 함께 돌린 방법과, 48런(run)에서 드러난 비용·실패 패턴·리뷰 차이를 중심으로 정리합니다.
두 도구의 강점: 공식 자료가 말하는 것
본격적인 비교에 앞서, 두 도구가 공식적으로 내세우는 강점을 정리하면 실험 결과를 해석하는 지도가 됩니다
Claude Code의 플래그십은 2026년 5월 28일 출시된 Claude Opus 4.8입니다. Anthropic은 이 모델이 이전 버전 대비 코드 결함을 놓치지 않고 지적할 확률이 약 4배 높다고 밝혔는데, 이 점은 뒤에서 “리뷰어로서의 Claude”를 해석할 때 다시 등장합니다. Opus와 Sonnet은 최대 1M 토큰 컨텍스트를 제공하고, 무엇보다 Claude Code의 가장 두드러진 차별점은 계층화된 멀티 에이전트 오케스트레이션입니다. 격리된 컨텍스트에서 도는 서브에이전트, 실험적 Agent Teams, 수십~수백 개 백그라운드 에이전트를 분산하는 동적 워크플로우까지 갖췄습니다. Claude Code의 강점은 여러 에이전트를 실제 작업 흐름으로 운영하는 데 있습니다.
Codex의 권장 기본 모델은 2026년 4월 23일 출시된 GPT‑5.5(코드명 ‘Spud’)로, 약 1.05M 토큰 컨텍스트와 none~xhigh의 추론 강도를 지원합니다. CLI는 오픈소스(Apache‑2.0)이며 약 96%가 Rust로, 속도와 효율을 강조합니다. OS 수준 샌드박싱(macOS Seatbelt, Linux bwrap+seccomp)과 로컬↔클라우드 위임이 핵심 차별점이고, 독립 리뷰들이 가장 일관되게 꼽는 강점은 토큰 효율입니다. 한 벤치마크에서 동일 작업에 Claude 대비 약 1/4 토큰을 썼다는 보고가 있습니다. Jozefiak의 표현을 빌리면, “Codex는 에이전트를 개선하는 데 낫고, Claude Code는 에이전트를 실행하는 데 낫다“ 입니다.
두 도구의 공식 사양을 한 표로 정리하면 차이가 더 분명해집니다.
| 항목 | Claude Code | Codex |
|---|---|---|
| 플래그십 모델 | Opus 4.8 (2026‑05‑28) | GPT‑5.5 (2026‑04‑23, ‘Spud’) |
| 컨텍스트 윈도우 | 최대 1M 토큰 | ~1.05M 토큰 |
| API 가격(플래그십, per MTok) | 입력 $5 / 출력 $25 | 입력 $5 / 캐시 $0.5 / 출력 $30 |
| CLI 라이선스 | 비공개, 자동 업데이트 | 오픈소스 Apache‑2.0, ~96% Rust |
| 설정 파일 | CLAUDE.md | AGENTS.md(개방 표준) |
| 멀티 에이전트 | 에이전트 팀(실험적), 상호 메시지 | 격리 병렬 에이전트 |
| 작업 스타일 | 협업적·대화형(권한 요청) | 자율적·위임 중심 |
| 토큰 효율(벤더/리뷰 보고) | “수다스러움”·사전계획 오버헤드 | 간결, 약 4배 효율 |
Opus 4.8 발표 문구는 Claude를 리뷰어로 쓸 때의 기대치를 직접 건드립니다. Anthropic이 강조한 “코드 결함을 놓치지 않고 지적할 확률이 4배“ 는 곧 결함 탐지에 무게를 둔 모델이라는 뜻입니다. 반대로 Codex의 OS 수준 샌드박싱과 apply_patch 기반의 점진적 편집 방식은 Codex가 자기 코드를 스스로 검증·정리하는 craftsman 성향과 맞닿아 있습니다. 두 회사가 각자 다른 곳에 투자했다는 뜻이고, 이 글의 실험은 바로 그 “다름”이 협업에서 어떻게 작동하는지를 봅니다.
다만 벤치마크 해석에는 주의가 필요합니다. Terminal‑Bench 2.0 독립 리더보드를 보면 공식 하네스는 최상위 커스텀 스캐폴드보다 눈에 띄게 낮은 점수를 받습니다. 예컨대 같은 GPT‑5.5라도 공식 Codex CLI 하네스와 커스텀 스캐폴드의 점수 차가 큽니다. 즉 점수의 상당 부분은 모델 자체보다 하네스·스캐폴드 설계에 좌우된다는 뜻인데, 이 사실 자체가 이 글이 모델 비교가 아니라 하네스 이야기인 이유이기도 합니다. 우리가 측정하려는 것은 “어느 모델이 더 똑똑한가”가 아니라 “두 모델을 어떻게 엮으면 더 나은 결과가 나오는가”입니다.
둘을 조합하면 좋을까? 그리고 왜 Bedrock일까?
두 도구를 병행한 이유는 기능 목록보다 작업 성향의 차이가 컸기 때문입니다. 여러 독립 리뷰가 비슷하게 정리하는 그림은 이렇습니다. Codex는 빠르고 범위가 명확한 작업, 비용에 민감한 작업, 전체 코드베이스를 읽는 리팩터링에 강합니다. Claude Code는 모호하거나 탐색적인 작업, 대규모 컨텍스트, 자율 멀티 에이전트 오케스트레이션에 강합니다. 다수의 저자가 “Codex는 키스트로크/리팩터, Claude Code는 커밋/에이전트“ 처럼 역할을 나눠 병행한다고 말합니다.
그런데 “병행”에는 숨은 비용이 있습니다. 두 개의 인증, 두 개의 청구 체계, 두 개의 거버넌스 경계입니다. 바로 여기서 Amazon Bedrock이 결정적인 역할을 합니다. 2026년 6월부터 Codex가 Bedrock에서 GA되면서, 이제 같은 노트북에서 `codex exec`와 `claude -p`가 둘 다 Bedrock(us-east-2)으로 추론할 수 있습니다. 자격증명·리전·VPC·로깅·비용추적이 한 AWS 계정으로 통일되고, 모델 교체는 설정 파일 한 줄(model = “openai.gpt-5.5” ↔ “global.anthropic.claude-opus-4-8”)이 됩니다. 두 프런티어 에이전트를 선택적으로 쓰거나 혼용하는 진입장벽이 사실상 0이 되는 것입니다. 이 글의 실험 48런 전체가 바로 그 환경, 즉 하나의 genai AWS 프로필과 하나의 리전에서 돌았다는 사실이 그 증거입니다.
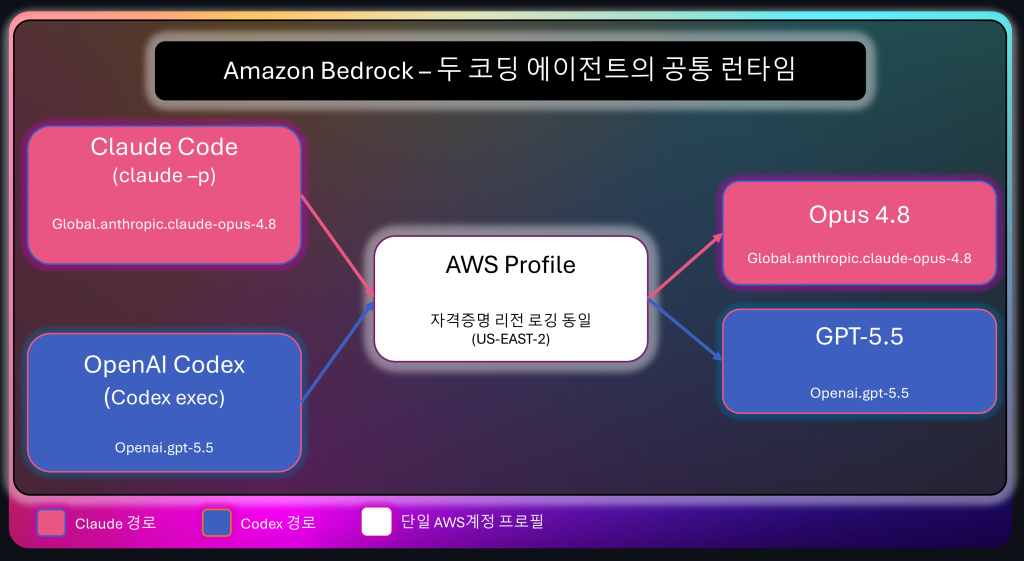
그림 1. 두 CLI가 하나의 AWS 프로필(`genai`)을 거쳐 같은 Bedrock 엔드포인트로 추론하는 구조. Claude Code는 `CLAUDE_CODE_USE_BEDROCK=1`로, Codex는 `model_provider=amazon-bedrock`으로 설정되며, 실제로 호출되는 모델만 Opus 4.8과 GPT‑5.5로 갈립니다. 인증·리전·로깅·비용추적이 한 곳으로 모이는 것이 혼용의 진입장벽을 낮추는 핵심입니다.
Bedrock에서 두 도구를 띄우는 설정은 이렇게 간단합니다. Codex 쪽은
~/.codex/config.toml 예시:
Claude Code 쪽은 ~/.claude/settings.json 예시:
이 두 설정만으로 codex exec “…”와 CLAUDE_EFFORT=xhigh claude -p “…”가 같은 Bedrock 백엔드 위에서 나란히 돕니다.
두 도구를 기술적으로 엮는 방법도 여러 갈래입니다. OpenAI가 공식 배포하는 Claude Code 플러그인 `openai/codex-plugin-cc`는 /codex:review·/codex:rescue 슬래시 커맨드로 로컬 codex app-server를 JSON‑RPC로 구동합니다(셸아웃이 아닙니다). 양방향 MCP(codex mcp-server ↔ claude mcp serve)나 CLI‑to‑CLI 위임도 가능합니다. 다만 우리가 보고 싶었던 것은 “위임”(한쪽이 다른 쪽에 통째로 맡기는 것)이 아니라 진짜 협업, 즉 한쪽이 개발하고 다른 쪽이 리뷰하거나 번갈아 코드를 고치는 방식이었고, 그것은 본질적으로 하네스 엔지니어링의 영역이었습니다.
협업 하네스 설계
협업 실험에서 정작 어려운 부분은 모델을 고르는 일이 아니라, 두 모델을 어떻게 이어 붙이느냐였습니다. 모델이 같더라도 한쪽의 산출물을 다른 쪽에 어떤 형태로 넘기는지, 리뷰를 어떻게 받아 다음 단계의 입력으로 연결하는지, 각 단계를 어떻게 기록하는지에 따라 결과가 눈에 띄게 달라졌습니다. 그래서 게임을 만들기 전에 두 에이전트를 연결하는 구조부터 설계했습니다. 이 구조를 한 번 제대로 만들어 두면 과제가 바뀌어도 그대로 재사용할 수 있도록, 처음부터 범용 하네스로 설계했습니다.
네 가지 협업 토폴로지
먼저 “협업”이라는 말이 실제로 무엇을 가리키는지부터 정해야 했습니다. 두 도구가 코드를 주고받는 방식은 생각보다 여러 갈래인데, 그것을 “코드를 최종적으로 누가 소유하는가”와 “리뷰어가 코드를 직접 편집하는가”라는 두 축으로 나눠 네 가지 토폴로지로 정리했습니다.
| 토폴로지 | 흐름 | 코드 소유 | 리뷰어가 코드를 편집? |
|---|---|---|---|
| 위임(Delegation) | A → B에게 통째로 위임 | B 단독 | (협업 아님, 제외) |
| 특화(Specialized) | 계획 → 구현 → 통합 (역할 분담) | 공동 | 통합 단계에서 |
| 릴레이(Relay, 리뷰전용) | 개발 → 리뷰(읽고 지적만) → 원개발자 개선 | 원개발자 | 아니오 |
| 핑퐁(Ping‑pong, 리뷰+수정) | 개발 → 리뷰어가 직접 편집 → 다시 편집 | 공동 | 예 |
같은 내용을 단계 흐름으로 그리면 네 토폴로지의 차이가 더 또렷합니다. 각 행이 하나의 토폴로지이고, 박스 색은 그 단계를 맡은 도구(핑크=Claude, 블루=Codex), 박스 사이의 라벨은 단계 사이에 오가는 산출물입니다.

그림 2. 네 가지 협업 토폴로지의 단계 흐름. 위임은 Claude가 Codex에 통째로 넘기는 한 방향이라 “협업“에서 제외했고, 특화·릴레이·핑퐁이 실제 측정 대상입니다. 릴레이만 리뷰가 `review.md`라는 별도 산출물로 흐르고(파란 피드백 선), 핑퐁은 두 도구가 `index.html`을
직접 주고받습니다.
이 가운데 위임은 OpenAI 공식 플러그인의 /codex:rescue가 하는 방식과 같습니다. Claude가 작업을 Codex에 통째로 넘기고 결과만 받아오는 구조라, 개발은 Codex가 사실상 100% 맡습니다. 한 도구가 다른 도구에 일을 시키는 것에 가깝지 두 도구가 함께 만드는 것은 아니어서, 이번 실험에서는 제외했습니다. 나머지 셋이 우리가 실제로 측정하려 한 “진짜 협업”입니다.
특화는 사람 팀의 설계자–구현자 분업을 그대로 옮긴 형태입니다. 한 도구가 먼저 PLAN.md에 구현 계획을 적으면, 다른 도구가 그 계획을 따라 코드를 작성하고, 처음 계획을 세운 도구가 마지막에 계획 대비 구현을 검수하며 통합합니다. 릴레이는 리뷰어가 코드에는 손대지 않고 reviewN.md에 지적만 남기는 방식입니다. 그 리뷰를 원래 개발한 도구가 읽고 직접 고치므로 코드 소유권이 한쪽에 머물고, 그만큼 도구 사이의 핸드오프가 가볍습니다. 핑퐁은 가장 긴밀한 동시에 가장 까다로운 방식으로, 리뷰어가 index.html을 직접 편집해 두 도구가 코드를 공동으로 소유합니다. 뒤에서 보겠지만 이 “직접 편집”이 협업의 효과를 가장 키우면서도, 동시에 가장 자주 어긋나는 지점이기도 했습니다.
하네스가 풀어야 했던 네 가지 문제
토폴로지를 정했다면, 그것을 실제로 돌아가게 만드는 연결 작업이 남습니다. 이 부분에서는 네 가지 문제를 차례로 풀어야 했습니다.
첫째는 산출물을 어떻게 넘기느냐였습니다. 한 단계가 만든 코드를 다음 단계가 받아야 하는데, 이를 표준출력이 아니라 파일시스템으로 넘겼습니다. 모든 단계가 같은 작업 디렉터리를 공유하게 하고, 한 도구가 index.html을 쓰면 다음 도구가 같은 폴더에서 그 파일을 읽도록 했습니다. 700~1,100줄짜리 코드를 프롬프트 본문에 그대로 끼워 넣었다면 토큰이 크게 늘고 중간에 잘릴 위험도 있었을 텐데, 파일 경로 하나만 주고받으니 그런 부담이 사라졌습니다.
둘째는 리뷰를 어떻게 보관하느냐였습니다. 리뷰어의 지적이 다음 단계로 정확히 전달되려면, 휘발성 출력이 아니라 구조화된 파일로 남아 있어야 합니다. 그래서 리뷰 단계 프롬프트에 “전체 리뷰를 reviewN.md에 써라”를 명시해, 라운드마다 별도의 리뷰 파일이 남도록 했습니다.
셋째는 그 리뷰를 다음 단계에 어떻게 다시 전달하느냐였습니다. 리뷰가 파일로 남아 있어도, 개선 단계가 그것을 읽지 않으면 의미가 없습니다. 그래서 개선 단계 프롬프트에 “ ./reviewN.md를 읽고 모든 FAIL/PARTIAL을 고쳐라“를 명시해, 한 단계의 출력이 다음 단계의 입력으로 분명하게 이어지도록 했습니다.
넷째는 각 단계를 어떻게 계측하느냐였습니다. 협업의 가치를 따지려면 “각 단계가 결과를 얼마나 바꿨는가”를 측정해야 하는데, 기록이 없으면 그 값을 잴 수 없습니다. 그래서 단계마다 걸린 시간(wall-clock)과 토큰을 따로 기록하고, 매 단계가 끝날 때 index.html을 sN.html로 스냅샷해 두었습니다. 이렇게 하면 단계 사이의 차이를 나중에 diff로 추적하고, 화면으로도 비교할 수 있습니다.
이 네 가지가 맞물린 결과, 한 번의 실행은 다음과 같은 디렉터리로 남습니다. 최종 결과물뿐 아니라 모든 중간 산출물이 증거로 보존되도록 한 것입니다.
견고함은 하네스 설계에 의하여
처음 만든 하네스는 일회성 셸 스크립트였습니다. 실행할 때마다 손이 많이 갔고 과제마다 한 번씩만 돌렸기 때문에, 통계적으로 약했고 격리도 비대칭이었으며 헤드리스에서 어떤 모델로 연결되는지조차 확신하기 어려웠습니다. 그래서 이 약점들을 정면으로 해소하면서, 다른 개발 과제에도 재사용 가능한 견고한 엔진으로 다시 짰습니다.
핵심은 단일 진입점 + 테이블 주도 디스패치입니다. run_one.sh <arm> <task> <run> 하나가 8가지 토폴로지를 모두 처리하고, run_matrix.sh가 전체 매트릭스를 순차·재개 가능하게 돌리며, lib.sh가 도구 추상화(엔진)를 담습니다. 여기서 arm은 “하나의 비교 그룹”, 즉 어떤 협업 방식으로 한 판 돌리는가를 가리키는 이름입니다(단독 2가지 + 협업 6가지 = 8가지). 전체 흐름을 그림으로 보면, 진입점에서 출발한 실행이 lib.sh 엔진의 네 가지 안전장치를 거쳐 격리된 단계 실행으로 내려가고, 모든 산출물이 run 디렉터리에 쌓이는 구조입니다.
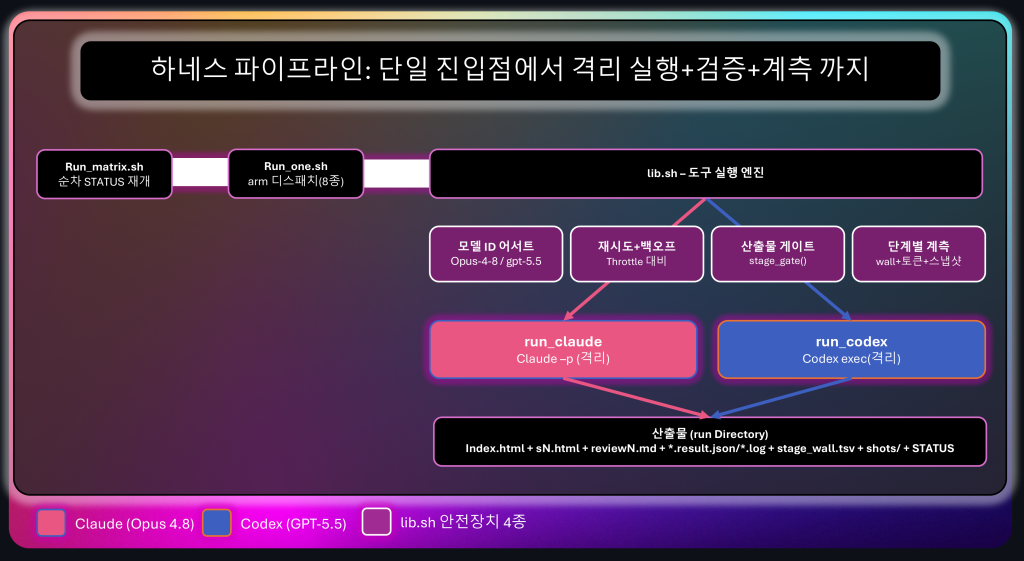
그림 3. 하네스 파이프라인. `run_matrix.sh`(순차·재개)가 `run_one.sh`로 arm을 디스패치하면, 실제 도구 호출은 `lib.sh` 엔진을 거칩니다. 엔진은 모델 ID 어서트·재시도·산출물 게이트·단계별 계측이라는 네 안전장치를 적용한 뒤 `run_claude`/`run_codex`로 격리 실행하고,
결과를 run 디렉터리에 남깁니다.
예를 들어 릴레이(R1)와 핑퐁(P1)의 단계 시퀀스는 이렇게 한 곳에서 선언됩니다:
ROUNDS를 바꾸면 릴레이/핑퐁의 반복 횟수가 달라지고, run_claude/run_codex가 동일한 시그니처(prompt dir tag)를 쓰기 때문에 새 도구를 추가하기도 쉽습니다. 새 과제를 추가하려면 프롬프트 파일 하나와 case 한 줄만 더하면 됩니다.
그리고 네 가지 안전장치를 코드에 새겼습니다. 첫째, 모델 ID 어서트는 각 단계가 정말 opus-4-8/gpt-5.5 풀 ID로 돌았는지 결과·세션에서 확인하고, 별칭이나 다운그레이드면 재시도합니다(이전 버전에서 “헤드리스가 다른 버전으로 라우팅되는 것 아닌가” 하던 불확실성을 없앴습니다). 둘째, 재시도+백오프는 뒤에서 설명할 Bedrock throttle에 대비해 지수 백오프로 최대 4번 다시 시도합니다. 셋째, 산출물 게이트는 각 단계가 기대한 산출물을 냈는지 검사하고, 통과해야 다음으로 넘어갑니다. 넷째, STATUS 기반 재개는 각 런이 DONE/FAILED를 기록해 매트릭스가 중단돼도 완료분을 건너뛰고 이어붙입니다.
산출물 게이트는 처음엔 단순히 “index.html이 유효한가”만 봤는데, 이게 버그를 낳았습니다. 특화 토폴로지의 계획 단계는 index.html이 아니라 PLAN.md를 만드는데, 게이트가 index.html을 요구하니 매번 NO_FILE로 4번씩 재시도하며 25분을 흘려보낸 것입니다. 이 문제를 겪고 나서, 단계가 내놓는 산출물에 맞춰 게이트를 따로 두도록 고쳤습니다. 태그별로 검사 대상을 아는 함수입니다:
validate_index는 단순히 파일 존재만 보는 게 아니라, <script> 안의 JS를 추출해 node --check로 구문을 검사하고, 외부 http(s) 의존성이 없는지(무의존성 정책) 확인합니다. 검증을 기계적·결정적으로 만들어 토큰을 한 푼도 쓰지 않으면서도 “게임이 아예 안 만들어진” 케이스를 정직하게 걸러냅니다.
공정성을 위한 격리도 대칭으로 맞췄습니다. 초기에는 Codex만 격리된 홈에서 돌리고 Claude는 글로벌 설정·스킬·MCP를 그대로 불러왔는데, 이번에는 Claude도 --setting-sources project --strict-mcp-config --disable-slash-commands로 “맨몸” 상태로 격리해 두 도구의 출발 조건을 같게 만들었습니다.
하네스를 스킬로 패키징하기
이 하네스는 벤치마크 전용으로 끝내기엔 아깝습니다. 핵심 로직(어떤 도구가 어떤 순서로 일하고, 산출물을 어떻게 주고받는가)은 과제와 무관하기 때문입니다. 그래서 절대경로·모델·과제·채점 기준을 모두 환경변수로 빼서, 임의의 두 CLI 에이전트에 쓸 수 있는 Claude Code 스킬로 패키징했습니다. 스킬은 SKILL.md(언제 쓰는지 + 어떻게 실행하는지) 한 파일과 범용화한 엔진 스크립트로 구성됩니다.
SKILL.md의 frontmatter는 스킬이 언제 떠야 하는지를 정합니다. “두 코딩 에이전트를 협업시킨다”, “Codex로 Claude 코드를 리뷰한다”, “릴레이/핑퐁으로 번갈아 고친다” 같은 요청에 반응하도록 적습니다.
엔진은 과제를 하드코딩하지 않고 환경변수로 받습니다. 그래서 게임이든 API 서버든, 같은 스킬로 협업 토폴로지를 돌릴 수 있습니다.
실험 설계
대상 앱은 의존성 0인 단일 `index.html` 게임으로 정했습니다. 외부 라이브러리가 없으니 실행·스크린샷·측정의 잡음이 최소화되고, 브라우저에서 바로 돌려볼 수 있습니다. 명세 복잡도는 두 단계로 두었습니다. 변별력을 위해서입니다. Breakout(벽돌깨기) 은 기본 과제로 10개 요구사항(캔버스+게임루프, 패들 조작, 공 반사, 벽돌 충돌, 점수, 목숨 3개, 승리 조건, 게임오버+재시작, 난이도 증가, 단일 파일)을 둡니다. Tetris(테트리스) 는 복합 과제로 15개 요구사항(7종 테트로미노, SRS 월킥, 라인 클리어, hold, ghost piece, 레벨 중력, pause 등)을 두는데, 회전 보정이나 hold처럼 상태 관리가 까다로운 항목이 많아 도구 간 차이가 드러나기 좋습니다.
비교 축(arm)은 8가지입니다. 코드 소유 구조와 도구 배치를 한눈에 보면 이렇습니다.
| arm | 토폴로지 | 단계 시퀀스 |
|---|---|---|
| claude / codex | 단독(원샷) | 한 도구가 전부 |
| S1 | 특화 | Claude 계획 → Codex 구현 → Claude 통합 |
| S2 | 특화 | Codex 계획 → Claude 구현 → Codex 통합 |
| R1 | 릴레이 | Claude 개발 → [Codex 리뷰 → Claude 개선] × 2라운드 |
| R2 | 릴레이 | Codex 개발 → [Claude 리뷰 → Codex 개선] × 2라운드 |
| P1 | 핑퐁 | Claude 개발 → [Codex 리뷰+편집 → Claude 리뷰+편집] × 2라운드 |
| P2 | 핑퐁 | Codex 개발 → [Claude 리뷰+편집 → Codex 리뷰+편집] × 2라운드 |
이 8개 arm을 2개 과제로, 각각 3번씩 반복해 48런을 돌렸습니다. 협업 arm을 도구 순서만 바꿔 쌍(S1↔S2, R1↔R2, P1↔P2)으로 둔 이유는, “어느 도구가 어느 역할을 맡을 때 더 나은가“ 를 대칭적으로 비교하기 위해서입니다. 예컨대 R1(Codex가 리뷰)과 R2(Claude가 리뷰)를 나란히 보면 “어느 쪽이 리뷰어로 더 강한가”가 드러납니다.

그림 4. 실험 전체 구성. 8개 arm(단독 2 + 혼용 6)을 두 과제에 대해 3번씩 반복해 48런이 됩니다. arm 라벨의 색은
단독 도구(파랑=Claude, 초록=Codex)와 혼용(보라)을 구분하며, 모든 런은 같은 격리 조건(Track A)·xhigh에서 실행했습니다.
공정성을 위해 몇 가지를 고정했습니다. 두 도구 모두 xhigh(코드를 쓰기 전에 추론에 토큰을 최대한 더 쓰는 단계)로 통일하고, 프롬프트는 바이트 단위로 동일하게 주입했으며, 매트릭스의 모든 arm을 격리(Track A) 로 돌렸습니다. 이건 의도적 결정으로, 협업 arm이 단독 arm과 오직 한 변수(협업 토폴로지) 만 다르게 하기 위해서입니다. 만약 특화 arm에만 풀파워 기능(동적 워크플로우, 스킬 등)을 켰다면 변수가 둘(토폴로지+기능)이 되어 “결과가 좋아진 게 협업 때문인지 기능 때문인지” 구분할 수 없었을 겁니다. 한 번에 한 변수만 바꾼다 는 실험 원칙을 코드에 새긴 셈입니다.
먼저 같은 명세를 두 도구가 단독으로 구현했을 때의 결과물입니다. 모든 스크린샷은 shoot.mjs가 헤드리스 Chromium(system Chrome)으로 결과물을 실제 로드하고 키입력을 주입한 뒤 찍은 것입니다. 콘솔 에러를 함께 수집하고 외부 네트워크를 차단(무의존성 재확인)합니다. 다만 8개 게임이 저마다 다른 상태 머신을 갖기 때문에(어떤 건 Space로 발사, 어떤 건 클릭으로 시작, 어떤 건 라이프 사이에 “Ready” 오버레이를 표시) 일부 컷은 공이 날아다니는 플레이 중 화면, 일부는 발사 대기/일시정지 오버레이 화면입니다. 점수가 0이 아니거나 벽돌에 빈 칸이 생긴 컷은 게임이 실제로 진행됐다는 증거입니다. 둘 다 제대로 동작하는 게임이지만, 화면 구성과 디테일에서 손길의 차이가 드러납니다.
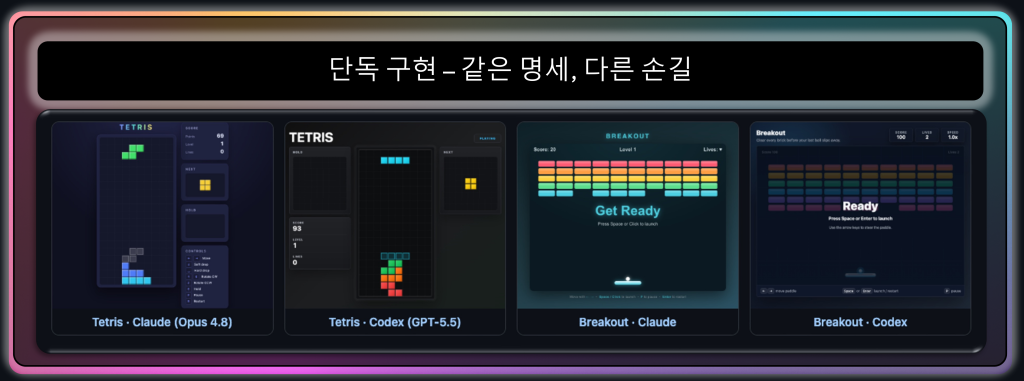
그림 5. 같은 명세로 Claude(좌)와 Codex(우)가 단독으로 만든 Tetris(위)와 Breakout(아래). 네 게임 모두 캔버스·점수·NEXT/HOLD 같은 핵심 요소를 갖췄지만, 화면을 채우는 방식이 다릅니다. Claude 쪽은 컨트롤 안내를 화면 안에 함께 배치하는 경향이,
Codex 쪽은 패널을 분리한 정돈된 배치가 보입니다. Codex Tetris의 ‘PLAYING’ 배지나 점수 값처럼,
정지된 듯 보이는 컷에도 게임이 실제로 진행된 흔적이 남아 있습니다.
채점은 개발자가 자기 결과물을 자기가 채점하지 않는다는 원칙을 지켰습니다. 개발·리뷰와 분리된 격리된 제3의 컨텍스트가 채점하되, 키워드가 아니라 “도달성(reachability)” 으로 판정합니다. 코드에 ‘YOU WIN!’ 문자열이 있어도 그 상태로 가는 경로가 없으면 dead code로 FAIL입니다. 그리고 한 걸음 더 나아가, 2명의 채점관(Claude judge + Codex judge) 으로 패널을 꾸렸습니다. 같은 계열 채점관 하나만 쓰면 그 계열의 맹점을 그대로 물려받기 때문입니다. 채점 결과는 항상 라인 근거를 첨부해 검증 가능하게 했습니다.
도구의 행동을 관찰하다: 어떻게 개발했을까?
수치를 비교하기 전에, 두 도구가 어떻게 생각하고 일하는지를 따로 기록하고 싶었습니다. 그래서 단독 8런의 세션 로그를 별도 에이전트들이 분석하게 하고, 그 주장들을 다시 적대적으로 검증했습니다. 근거가 약한 5개 주장은 폐기하고 살아남은 관찰만 남겼습니다.
Claude는 단일 패스 작성자였습니다. 워크스페이스를 전혀 탐색하지 않고(파일을 읽거나 grep하지 않고) 700~800줄 게임을 사실상 한 번에 써 내려갔습니다(3번의 Tetris 모두 num_turns 3~4, 중간 수정 없음). 외부 문서나 웹 검색도 없이 기억만으로 7‑bag Fisher‑Yates 무작위화, I 조각과 JLSTZ 조각을 분리한 완전한 SRS 월킥 테이블, 고스트 피스, hold/next 미리보기 같은 “가이드라인 수준”의 구현을 뽑아냈습니다. 자기 검증은 정적 수준에 머물렀습니다. 요약 첫머리에 “Syntax checks out” 같은 구문 검사 주장을 달고 15개 요구사항을 코드 심볼에 매핑한 자체 채점표를 붙였지만, 게임을 실제로 실행해보지는 않았습니다. 한 Breakout 실행에서는 “JavaScript가 깨끗하게 검증된다”고 단언했는데 그에 해당하는 도구 호출 기록이 어디에도 없었습니다. 검증을 수행한 게 아니라 주장한 셈입니다. 그리고 이 단일 패스의 대가로 무해한 죽은 코드가 남았는데, 특히 Breakout에서 level 변수를 1로 초기화한 뒤 한 번도 증가시키지 않아 레벨별 난이도 곡선이 실제로는 작동하지 않는 버그가 남았습니다. 직접 플레이해봤다면 잡혔을 결함입니다.
Codex는 탐색 우선의 craftsman이었습니다. 매 실행을 pwd·ls로 작업 디렉터리를 먼저 살피는 것으로 시작한 뒤 하나의 apply_patch로 전체 파일(705~1,123줄)을 작성했습니다. 도구가 없으면 반사적으로 적응했는데, rg(ripgrep)가 샌드박스에 설치돼 있지 않아 종료코드 127이 떨어지면 불평이나 재시도 없이 곧바로 find/ls로 대체했습니다(4번의 실행 모두). 테스트가 통과한 뒤에도 요청하지 않은 코드 정리를 스스로 했다는 점도 눈에 띕니다. 키 핸들러에서 Set을 끌어올리거나 미사용 변수를 제거하는 식이었습니다. 자기 검증은 진짜로 실행하지만 실행마다 편차가 컸습니다. 어떤 실행은 약속한 sanity check를 끝내 돌리지 않았고, 가장 엄격했던 실행은 세 단계 사다리를 밟았습니다. 인라인 스크립트를 추출해 node --check로 구문을 검사하고, 실제 Chromium Playwright 스모크 테스트를 시도했다가 브라우저 바이너리가 없어 실패하자, 워크스페이스에 브라우저를 끌어들이길 거부하고 node‑vm으로 document·canvas를 흉내 낸 모의 런타임을 직접 만들어 20×10 보드와 하드드롭 점수, 드롭당 1회 hold, 일시정지 상태를 행위 수준으로 검증한 뒤 정리 패치 후 전체를 한 번 더 돌렸습니다.
요약하면 두 도구의 개발 성향은 이렇게 갈립니다.
| 축 | Claude (Opus 4.8) | Codex (GPT‑5.5) |
|---|---|---|
| 작업 시작 | 정찰 없이 바로 작성 | pwd/ls로 워크스페이스 정찰 먼저 |
| 작성 방식 | 단일 패스, 한 번에 700~800줄 | 단일 apply_patch, 705~1,123줄 |
| 자기 검증 | 정적(구문 주장 + 자체 채점표), 실행 안 함 | 실제 실행하나 편차 큼(없음~node‑vm 모의 런타임) |
| 도구 적응 | (해당 없음) | rg 없으면 즉시 find/ls 폴백 |
| 사후 정리 | 거의 없음(죽은 코드 잔존) | 테스트 후 자발적 리팩터 |
한마디로 Claude는일관된 원샷 작성자, Codex는자가검증과 자발적 리팩터를 하는 장인으로 묘사할 수 있었습니다. 이 성향 차이는 곧이어 수치로도, 그리고 협업에서의 역할 적합성으로도 그대로 나타납니다.
단독 실행: 효율과 철저함은 명세 복잡도에 따라 갈린다
먼저 단독 실행을 3반복 평균으로 보면, “특정한 툴이 더 효율적”이라는 통념이 조건부임을 알 수 있습니다.
| 과제 | arm | 시간 | 라인 | reasoning 토큰 |
|---|---|---|---|---|
| Breakout (기본, 10항목) | Claude | 105s | 524 | 0 (별도 미노출) |
| Breakout (기본, 10항목) | Codex | 73s | 685 | 1,178 |
| Tetris (복합, 15항목) | Claude | 119s | 765 | 0 |
| Tetris (복합, 15항목) | Codex | 215s | 1,031 | 9,349 |
명세가 단순한 Breakout에서는 Codex가 빠릅니다(Codex 73s and Claude 105s). “Codex 효율” 이론에 부합합니다. 그런데 명세가 복잡한 Tetris로 가면 순서가 뒤집힙니다. Codex의 시간이늘고(Codex 215s and Claude 119s), 특히 reasoning 토큰이 9,349개까지 올라갑니다. 이건 xhigh의 숨은 비용인데, 출력 토큰만 세면 보이지 않습니다. 그래서 토큰을 비캐시입력·캐시생성·캐시읽기·출력·reasoning으로 나눠 집계했습니다. 명세에 따라 효율성에 대한 유리함이 달라질 수 있다는 점을 파악했습니다.
Breakout에서도 8가지 arm 모두 제대로 동작하는 게임을 만들어냈습니다(로드 후 입력 주입 캡처, 게임에 따라 발사 대기/일시정지 오버레이가 보일 수 있습니다):
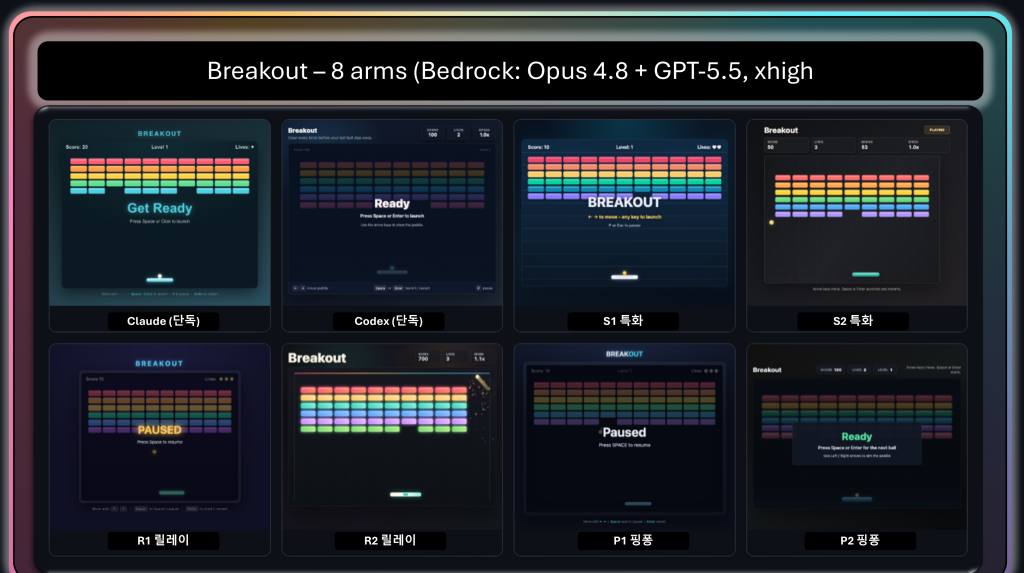
그림 6. Breakout의 8개 arm(단독 2 + 특화·릴레이·핑퐁 6). 벽돌·패들·공·HUD가 모두 갖춰져 있고, 점수가 올라 있거나 벽돌 행에 빈 칸이 생긴 컷은 실제 플레이가 진행됐음을 보여줍니다. ‘Get Ready’·’Paused’ 같은 오버레이가 보이는 컷은 게임이 라이프 사이의 대기 상태를 그대로 노출하는 경우로, 각 게임의 상태 머신이 다르다는 점도 함께 드러납니다.
교차사용이 필요한 이유
기능 점수는 거의 변별력이 없었습니다. 2명의 채점관이 거의 모든 arm에 만점을 줬습니다. Tetris 15/15, Breakout 10/10. 두 프런티어 모델이 xhigh로 만들면 10~15개짜리 체크리스트는 포화되어버린다는 뜻입니다.
그런데 채점관 두 명이 모두 유효한 46건의 비교에서, 단 한 건의 불일치가 모든 것을 말해주었습니다.
tetris/claude/run1: Claude 채점관 = 15/15, Codex 채점관 = 14.5/15. 불일치 항목은 #10 hold(드롭당 1회) 였습니다. Codex 채점관의 근거: “빈 hold 경로가 새 조각을 스폰하면서 holdUsed를 false로 재설정 → 즉시 다시 hold가 가능해져 ‘드롭당 1회‘ 규칙을 위반한다“ (라인 근거 첨부). 같은 계열인 Claude 채점관은 이 결함을 놓쳤습니다.
46번의 비교 중 유일하게 신호가 난 그 한 곳이, 하필 다른 모델 계열의 채점관이 같은 계열이 못 본 실제 버그를 잡은 지점이었습니다. 이건 우연한 노이즈가 아니라 구조적 현상입니다. 서로 다른 모델 계열은 서로 다른 맹점을 가진다. 이것이 “두 도구를 함께 쓰는” 가장 강력한 실증적 근거이고, 48런 규모에서 재현한 것입니다.
교차 리뷰에서 드러난 차이
점수가 포화됐다면 협업의 가치는 어디에 있을까요? 답은 “점수 밑에 숨은 것“, 곧 잡은 버그와 보강한 시스템에 있었습니다. 24개 협업 런을 단계별로 추적했고, 두 도구가 같은 방법(도달성 추적) 을 쓰면서도 산출의 성격이 갈린다는 것을 발견했습니다.
Codex가 Claude의 코드를 리뷰할 때(R1)는 도달성 버그헌터였습니다. 대부분의 항목에 PASS를 주지만, 잡을 때는 재현 경로가 명확한 실제 버그를 정확히 짚었습니다. 예를 들어 stale‑HUD 버그가 있습니다. 스페이스로 하드드롭을 하면 점수를 더한 뒤 곧바로 조각을 고정하는데, 그 과정에서 줄이 하나도 안 지워지면 HUD 갱신 함수가 호출되지 않아 화면 점수가 멈춥니다. Codex는 “Space → hardDrop() → 줄 클리어 없음 → HUD 미갱신”이라는 도달 경로를 정확히 적시했고, 한 줄짜리 수정을 제안했으며, Claude가 그것을 그대로 적용했습니다. 또 top‑out 누락(보드 위쪽에서 그대로 고정된 조각이 게임오버를 발동하지 못하는 결함)과, 놀랍게도 Claude 자신의 직전 수정이 만든 dead‑code 회귀(레벨 진행 코드가 도달 불가능해진 것)까지 도달성 추적으로 잡아냈습니다.
Claude가 Codex의 코드를 리뷰할 때(R2)는 폴리시·견고성 리뷰어였습니다. 방법론은 똑같이 엄격했지만(호출 그래프 추적, SRS 킥 부호 직접 검증), 그 엄격함이 결함 발견이 아니라 정확성 확인에 쓰였습니다. R2 리뷰는 예외 없이 전원 PASS로 끝났고, 모든 지적은 “폴리시일 뿐 어떤 요구사항도 막지 않음”으로 분류됐습니다. 발견은 lock delay 부재, DAS/ARR 자동반복 미구현, next 큐 깊이 같은 게임 감각 쪽에 쏠렸습니다. Claude가 가장 날카로웠던 지점은 정량 물리 추론이었습니다. 공이 최고 속도에서 프레임당 약 24px 이동하는데 이게 벽돌 높이 24px와 정확히 같아, 이산 충돌 검사로는 빠른 공이 벽돌을 터널링해 통과할 수 있다고 수치로 계산해냈습니다.
특히 인상적이었던 것은 Codex가 Claude의 직전 수정이 만든 회귀를 잡은 사례입니다. Breakout R1에서 Claude는 1라운드 개선 때 “벽돌을 다 깨면 즉시 승리”하도록 고쳤는데, 그 바람에 레벨을 올리는 startLevel(level+1) 호출이 도달 불가능해지고 레벨별 속도 증가 코드가 통째로 죽어버렸습니다. 2라운드에서 Codex가 “어떤 도달 가능한 코드도 startLevel(level+1)을 호출하지 않는다. 광고된 레벨 기반 난이도 경로가 죽었다“ 고 도달성 추적으로 적시했고, Claude가 다시 다중 레벨 진행을 복원했습니다. 협업이 한 도구의 수정이 만든 부작용까지 잡아낸 것입니다.
이 비대칭의 함의는 분명합니다. 상대 빌드의 완성도가 리뷰의 성격을 정합니다. Claude의 빌드에는 미묘한 실버그가 남아 있어 Codex가 그것을 잡았고, Codex의 빌드는 기능적으로 탄탄해 Claude는 보강에 머물렀습니다. 혼용의 효과란 곧 “한쪽이 못 보는 종류의 결함을 다른 쪽이 본다“ 는 것입니다. 그리고 교차 검수는 자기 수정도 끌어냈습니다. Codex는 Claude가 “킥 테이블이 이미 올바르다”고 잘못 단언한 부분을 실제 Node assertion 테스트로 반증해 8개 오프셋을 고쳤고, Claude는 Codex의 hold 스왑이 dropCounter를 리셋하지 않아 교체된 조각이 거의 즉시 한 칸 떨어지는 잠복 버그를 짚어 Codex가 그대로 고쳤습니다.
8가지 arm이 만든 Tetris를 나란히 놓으면, 모두 NEXT·HOLD·HUD를 갖춘 제대로 된 게임이면서도 레이아웃과 색감, 컨트롤 안내 방식은 저마다 다릅니다.
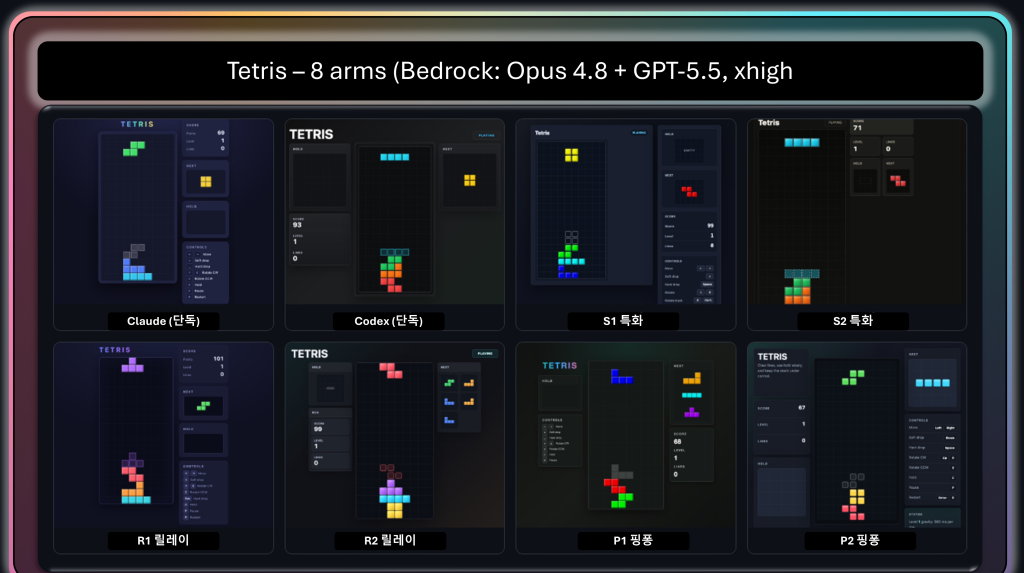
그림 7. Tetris의 8개 arm. 어느 방식으로 만들든 7종 테트로미노·NEXT·HOLD·HUD를 갖춘 동작하는 게임이 나왔다는 점이,
점수가 거의 만점으로 포화된 이유를 시각적으로 설명합니다. 동시에 보드 비율, 색 팔레트, 컨트롤 안내의 위치는 arm마다 달라,
같은 명세라도 도구·협업 방식에 따라 마감이 갈린다는 점도 함께 보여줍니다.
각 협업이 실제로 단계를 거치며 어떻게 변해갔는지는 다음 절에서 토폴로지별로 따라가 봅니다.
단계별로 따라가 보기: 협업은 화면이 아니라 코드를 바꿉니다
협업 arm은 매 단계마다 index.html을 sN.html로 스냅샷했기 때문에, 게임이 단계를 거치며 어떻게 변해가는지 그대로 볼 수 있습니다. 한 가지 미리 짚어둘 점은, 대부분의 변화가 화면에는 거의 드러나지 않는다는 것입니다. 크로스툴 리뷰가 고치는 것은 색이나 레이아웃이 아니라 도달 불가능한 승리 상태, 갱신 안 되는 HUD, 충돌 검증 누락 같은 보이지 않는 결함이기 때문입니다. 그래서 아래 단계별 montage들은 “외형은 유지되는데 점수·조각 위치만 달라지는” 모습으로 보이는데, 그 안에서 코드가 다듬어지고 있다고 읽으면 됩니다. (모든 컷은 헤드리스 Chromium으로 로드 후 입력을 주입해 캡처했으며, 게임에 따라 발사 대기/일시정지 오버레이가 보일 수 있습니다.)
릴레이: 리뷰어는 읽고 지적만, 원개발자가 고치기
R1 (Claude 개발 → Codex 리뷰 → Claude 개선, 2라운드). Claude가 만든 초기 빌드(s1)를 Codex가 review1.md로 검수하면 Claude가 그 지적을 반영해 s2를 내고, 다시 Codex 리뷰→Claude 개선으로 s3가 나옵니다. 외형은 그대로지만 stale-HUD·top-out 같은 버그가 라운드마다 사라집니다.
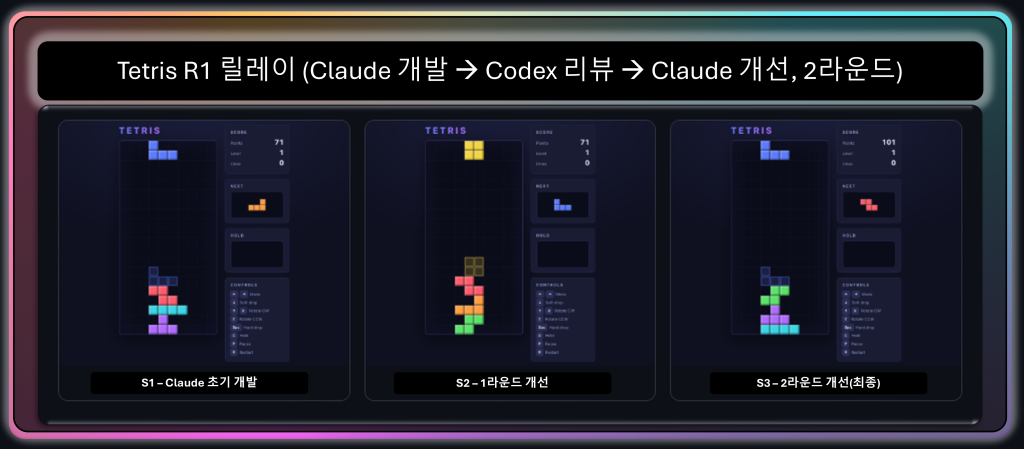
그림 8. R1 릴레이의 세 단계(s1 Claude 개발 → s2 1라운드 개선 → s3 2라운드 개선). 세 컷의 외형은 거의 같습니다.
바뀐 것은 Codex 리뷰가 짚은 stale-HUD(하드드롭 뒤 점수 미갱신)나 top-out 누락 같은,
화면에 곧장 드러나지 않는 동작 결함이기 때문입니다.
점수와 조각 위치만 달라 보이지만 그 아래에서 코드가 다듬어지고 있습니다.
R2 (Codex 개발 → Claude 리뷰 → Codex 개선, 2라운드). 방향을 뒤집으면 Codex가 만든 탄탄한 빌드를 Claude가 검수합니다. s3에서 NEXT 큐가 더 깊어진 것이 눈에 띄는데, 이는 Claude 리뷰가 제안한 “next 큐 깊이 보강” 같은 게임 감각 개선이 반영된 결과입니다.
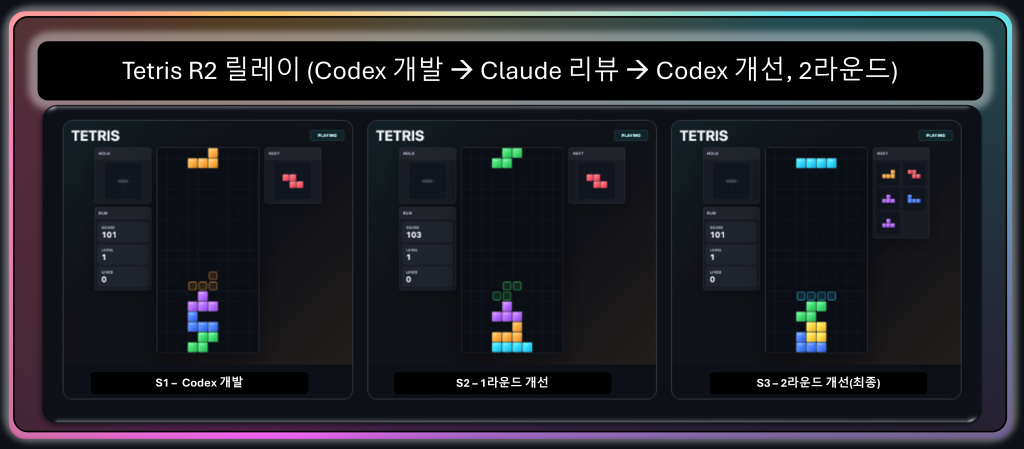
그림 9. R2 릴레이(Codex 개발 → Claude 리뷰 → Codex 개선). 세 컷 모두 ‘PLAYING’ 상태로 진행 중이며, s3에서 NEXT 미리보기 칸이
더 늘어난 것이 눈에 띕니다. Claude 리뷰가 게임 감각 쪽(예: next 큐 깊이 보강)을 제안하고 Codex가 그것을 반영한 흔적입니다.
같은 릴레이를 Breakout에서 보면, 앞서 말한 dead-code 회귀가 잡히는 과정이 담겨 있습니다. Claude가 1라운드에서 만든 부작용(레벨 진행 코드 사멸)을 Codex가 2라운드에서 적시해 복원했습니다.
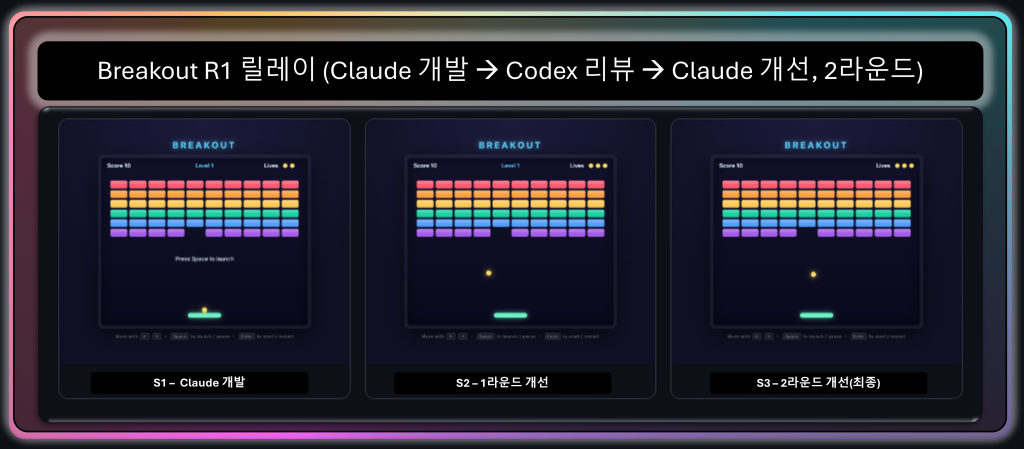
그림 10. Breakout R1 릴레이. 여기에는 한 도구의 수정이 만든 부작용을 다른 도구가 되돌리는 과정이 담겨 있습니다.
Codex가 이를 도달 불가능한 죽은 코드로 지목해 다중 레벨 진행을 복원했습니다.
핑퐁: 리뷰어가 직접 코드를 편집하기
P1 (Claude 개발 → [Codex 편집 → Claude 편집] ×2). 다섯 단계에 걸쳐 두 도구가 번갈아 index.html을 직접 고칩니다. 여기서도 외형보다는 내부 견고성이 다듬어지는데, 뒤에서 보듯 Codex 편집 단계가 종종 변경 0으로 끝나 사실상 Claude가 더 많은 몫을 맡기도 합니다.
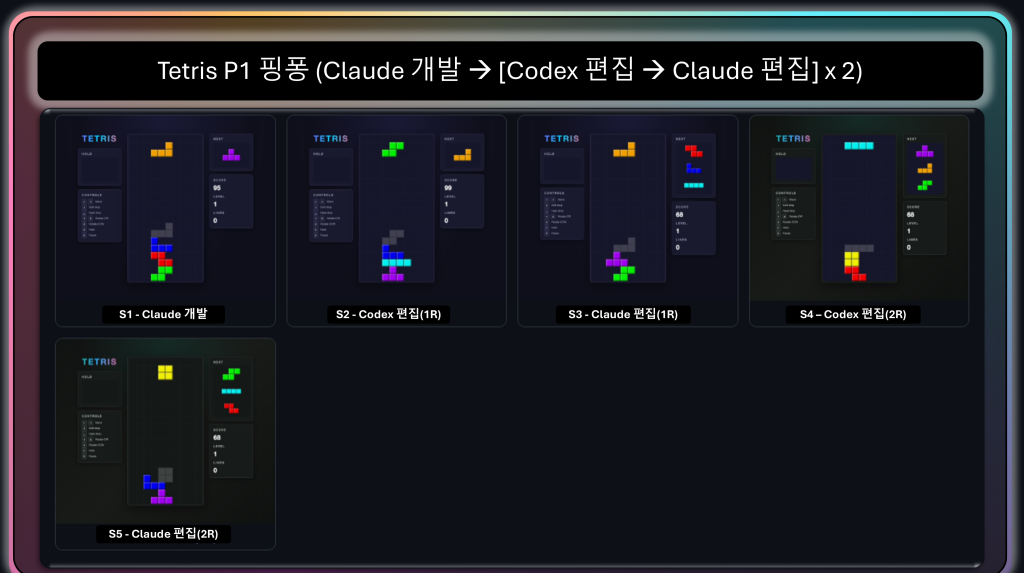
그림 11. P1 핑퐁의 다섯 단계(s1 Claude 개발 → s2 Codex 편집 → s3 Claude 편집 → s4 Codex 편집 → s5 Claude 편집).
두 도구가 번갈아 같은 파일을 직접 고치는 가장 긴밀한 방식입니다.
컷 사이의 차이가 작아 보이는데, 이는 편집이 외형이 아니라 내부 견고성에 집중되기 때문이며,
일부 Codex 편집 단계는 변경 없이 끝나기도 합니다.
P2 (Codex 개발 → [Claude 편집 → Codex 편집] ×2). 시작을 Codex가 맡은 핑퐁입니다. Claude 편집 단계(s2, s4)는 안정적으로 변화를 만들지만, Codex 편집 단계(s3, s5)는 컷오프되어 직전 상태와 동일해지는 경우가 있습니다.
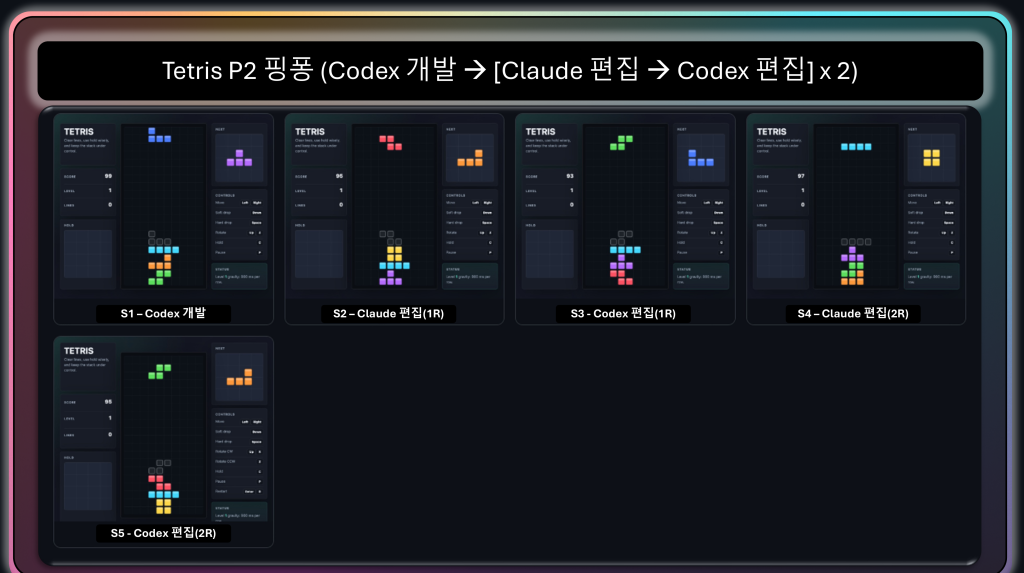
그림 12. P2 핑퐁(Codex 개발 → Claude 편집 → Codex 편집 …). Claude가 맡은 편집 단계(s2·s4)는 안정적으로 화면과 상태를 바꾸지만,
Codex가 맡은 편집 단계(s3·s5)는 직전 컷과 거의 같아지는 경우가 있습니다.
s5의 컨트롤 안내에 ‘Restart’ 항목이 추가된 것처럼, 변화가 있을 때는 주로 작은 보강에 후 종료합니다.
핑퐁 최종 산출물은 전부 만점을 받았습니다. 한쪽 도구가 멈춰도 다른 쪽의 단계가 결과를 채워 주는 복원력이 있는 셈인데, 뒤집어 보면 그 경우의 협업은 사실상 한쪽의 단독 작업으로 줄어든 것이기도 합니다. 여기서 얻은 실무 지침은 단순합니다. Codex는 리뷰전용(핸드오프) 역할에서, Claude는 편집 파트너 역할에서 서로 다른 부분에서 안정적이었습니다. 협업 파이프라인을 짤 때 이 역할 배치를 따르면 컷오프 위험을 줄일 수 있습니다.
마지막으로, 하네스를 만드는 과정에서 우리도 버그를 몇 개 만들었고 이를 그대로 기록해 두었습니다. 앞서 말한 plan 게이트 오류, 협업 arm을 풀파워로 둘 뻔한 트랙 교란(단일 변수 원칙으로 바로잡음), 채점관이 프롬프트의 예시 스키마를 그대로 출력하던 template‑echo 문제, 그리고 이 글을 쓰며 발견한 throttle 재시도 시의 토큰 과소 집계까지였습니다. 이런 사례들은 협업 하네스를 짤 때 무엇을 미리 점검해야 하는지를 알려주는 체크리스트가 됩니다. 그럼에도 전체 실행, 즉 48런과 수십 번의 채점·재시도가 6시간 넘게 사람 개입 없이 돌면서 실패 0건을 기록한 것은, 견고하게 설계한 하네스가 Bedrock의 간헐적 throttle을 재시도로 모두 흡수했기 때문입니다.
AWS위에서 하네스를 통한 혼용을 고려해보세요
48런을 놓고 보면, 단독 사용보다 역할을 나눈 교차 리뷰가 더 실용적인 경우가 분명히 있었습니다. AI 코딩 에이전트는 하나만 골라야 하는 대상이 아니라는 뜻입니다. 용도별로 정리하면 이렇습니다.
- 빠른 프로토타입, 대화형탐색적 작업, 그리고 안정적인 편집 파트너가 필요할 때 → Claude Code. 이번 실험에서 효율과 일관성이 확인됐고 핑퐁의 편집 단계도 항상 완수했습니다.
- 명세가 단순한 작업의 토큰 효율, 범위가 명확한 자율 구현, 그리고 리뷰어가 필요할 때 → Codex. 단순 명세에선 더 저렴하고 빨랐으며, 리뷰 역할에서 실제 도달성 버그를 정확히 잡았습니다(리뷰역할에서 안정적).
- 품질을 한 단계 더 끌어올리고 싶을 때 → 크로스툴 협업. 다른 계열이 리뷰하면 단일 도구가 못 보는 버그가 드러납니다. 48런에서 유일하게 갈린 채점 한 건이 바로 그 증거였습니다. 본 글을 위한 실험에서는Codex=리뷰 / Claude=편집 조합이 가장 안정적입니다. 워크로드에 따라 다를수 있다는 점은 참고 부탁드립니다.
- 그 모든 것을 Amazon Bedrock 한 곳에서. Claude도 Codex도 Bedrock에서 돌기 때문에, 계정리전·거버넌스·비용추적을 통일한 채 두 프런티어 에이전트를 선택적으로 쓰거나 혼용할 수 있습니다. 48런이 하나의 AWS 프로필·하나의 리전에서 무인으로 완주했다는 사실이 그 진입장벽이 얼마나 낮은지를 보여줍니다.
테스트하며 가장 분명하게 배운 것은, 혼용의 가치를 실현하는 것이 모델이 아니라 하네스라는 점입니다. 두 도구를 그냥 번갈아 호출하는 것만으로는 부족합니다. 산출물을 어떻게 넘기고, 리뷰를 어떻게 저장해 다음 단계로 연결하며, 각 단계를 어떻게 계측하고, throttle과 컷오프 같은 실패를 어떻게 다루는지가 협업의 성패를 가릅니다. 잘 설계된 하네스는 정상 동작할 때보다 실패를 다룰 때 더 빛을 발합니다.
그리고 이 하네스는 실험용으로 끝나지 않습니다. 과제·모델·채점 기준을 환경변수로 빼서Claude Code 스킬로 패키징해 두면, 다음부터는 “이 명세로 Claude가 만들고 Codex가 리뷰하게 해줘“ 라고 말하는 것만으로 같은 협업 파이프라인을 일상에서 불러 쓸 수 있습니다. 벤치마크를 위해 짠 배선이 그대로 재사용 가능한 도구가 되는 셈입니다. 마지막으로 Amazon Bedrock은 그 하네스를 한 계정 안에서 두 프런티어 모델 위에 올릴 공통 기반을 제공합니다. 2026년 6월, 두 도구를 함께 쓰는 일이 실험이 아니라 실무가 된 이유입니다.
참고 자료
공식 발표·모델 자료 (1차 출처)
- Anthropic, Claude Opus 4.8 발표 (2026‑05‑28). https://www.anthropic.com/news/claude-opus-4-8.
- OpenAI, Introducing GPT‑5.5 (2026‑04‑23, 코드명 ‘Spud’). https://openai.com/index/introducing-gpt-5-5/
- OpenAI Developers, GPT‑5.5 모델 사양. https://developers.openai.com/api/docs/models/gpt-5.5
- Anthropic, Claude 모델 개요. https://platform.claude.com/docs/en/about-claude/models/overview
- AWS, GPT‑5.5, GPT‑5.4, and Codex from OpenAI now generally available on Amazon Bedrock (2026‑06). https://aws.amazon.com/about-aws/whats-new/2026/06/amazon-bedrock-openai-models-codex-generally-available/
- Anthropic, Claude Code: Agent Teams. https://code.claude.com/docs/en/agent-teams. 계층형 멀티에이전트 오케스트레이션
- OpenAI Developers, Codex: Cloud(로컬‑클라우드 위임). https://developers.openai.com/codex/cloud. 위임 기능
- OpenAI Developers, Codex: Agent approvals & security(OS 수준 샌드박싱). https://developers.openai.com/codex/agent-approvals-security. macOS Seatbelt / Linux bwrap+seccomp 등 샌드박싱
- OpenAI, Codex CLI 저장소. https://github.com/openai/codex. 오픈소스(Apache‑2.0), Rust 약 96% 해당 내용.
- OpenAI, Codex Claude Code 플러그인(`codex-plugin-cc`). https://github.com/openai/codex-plugin-cc. 공식 플러그인, /codex:review/codex:rescue 참고사항
벤치마크 (독립 리더보드)
- Terminal‑Bench, Terminal‑Bench 2.0 리더보드. https://www.tbench.ai/leaderboard/terminal-bench/2.0. 공식 하네스 대 커스텀 스캐폴드 점수 차, “하네스가 점수를 좌우”.
제3자 리뷰 (의견·비교)
- Codersera, Claude Code vs OpenAI Codex (2026). https://codersera.com/blog/claude-code-vs-openai-codex-2026/. “보편적 승자 없음, 병행 사용” .
- Zapier, Codex vs Claude Code. https://zapier.com/blog/codex-vs-claude-code/. 토큰 효율 약 4배, Figma‑to‑code 비교.
- Jozefiak, Claude Code vs Codex: a real comparison (2026). https://thoughts.jock.pl/p/claude-code-vs-codex-real-comparison-2026. “Codex는 개선, Claude Code는 실행” .