AWS 기술 블로그
Amazon DocumentDB 인덱스 최적화로 미리캔버스의 쿼리 성능을 개선 사례
본 게시글은 미리디의 김민석, 이효성, 노정훈님과 함께 작성하였습니다.
미리디의 미리캔버스 소개

미리디의 미리캔버스는 “누구나 쉽게, 함께 만드는 디자인” 이라는 철학 아래, 프레젠테이션부터 SNS 카드뉴스, 유튜브 썸네일, 포스터까지 일상의 모든 시각 콘텐츠를 브라우저 하나로 만들 수 있는 실시간 협업 디자인 플랫폼입니다.
앞선 포스팅에서 소개한 MongoDB Atlas에서 Amazon DocumentDB로 전환 이후, 수백만 건의 디자인 데이터 위에서 수많은 사용자가 동시에 편집하고, 검색하고, 불러오는 환경에서는 단 몇 밀리초의 쿼리 지연도 사용자 경험에 직결됩니다. 미리디 팀이 마주한 다음 과제는 바로 이 쿼리 성능을 안정적으로 유지하는 것이었습니다.
이 블로그에서는 Amazon DocumentDB로 전환하면서 겪은 인덱스 최적화 과정을 실제 쿼리 예시와 함께 공유합니다. 어떤 인덱스 전략이 효과적이었는지, MongoDB Atlas와의 동작 차이에서 비롯된 문제를 어떻게 해결했는지, 그 구체적인 경험을 담았습니다.
전환 배경과 전체 여정은 이전 포스트를 참고하세요.
→ Amazon DocumentDB로 미리캔버스의 성능 50%와 비용 30%를 개선하다
개요
MongoDB에서 인덱스 설계의 정석으로 알려진 ESR(Equality-Sort-Range) 원칙이 있습니다. Equality 조건을 먼저, Sort 필드를 다음에, Range 조건을 마지막에 배치하면 최적의 인덱스 스캔이 가능하다는 원칙입니다.
그런데 Amazon DocumentDB로 전환한 후, 동일한 인덱스와 동일한 쿼리가 기대와 다르게 동작하는 경우를 여러 차례 경험했습니다. Amazon DocumentDB의 Query Planner가 MongoDB의 것과 다르기 때문입니다.
이 블로그에서는 저희가 실제로 겪은 4가지 인덱스 패턴 문제와 해결 방법, 그리고 프로덕션 운영에서의 튜닝과 모니터링 노하우를 공유합니다.
Partial Index: $exists 조건의 함정
문제 상황
MongoDB에서는 partial index를 생성할 때 partialFilterExpression에 $exists: true 조건을 넣고, 쿼리에서도 해당 필드가 존재하는 문서만 조회하면 인덱스가 활용됩니다.
// 인덱스 생성
db.node.createIndex(
{ itemIdx: 1, type: 1 },
{ partialFilterExpression: { itemIdx: { $exists: true } } }
)
// 쿼리
db.node.find({
itemIdx: { $in: [1, 2, 3] },
type: "USER_DESIGN"
})MongoDB에서는 이 쿼리가 partial index를 활용하여 IXSCAN으로 처리됩니다. 그러나 Amazon DocumentDB에서는 이 인덱스를 사용하지 않았습니다.
원인
Amazon DocumentDB의 partial index 활용 조건은 MongoDB보다 엄격합니다. Amazon DocumentDB는 쿼리 필터가 partialFilterExpression과 정확히 일치하고 동일한 데이터 유형인 경우에만 부분 인덱스를 사용합니다.
즉, partialFilterExpression이 { itemIdx: { $exists: true } }인데 쿼리 조건이 { itemIdx: { $in: [...] } }이면, 조건이 “정확히 일치”하지 않으므로 인덱스를 사용하지 않습니다.
해결
partialFilterExpression을 쿼리 패턴과 정확히 일치하도록 재설계하거나, partial index 대신 일반 복합 인덱스를 사용합니다.
// 방법 1: partialFilterExpression을 쿼리 패턴에 맞춤
db.node.createIndex(
{ itemIdx: 1, type: 1 },
{ partialFilterExpression: {
itemIdx: { $exists: true },
type: { $eq: "USER_DESIGN" }
}}
)
// 방법 2: partial index 대신 일반 복합 인덱스
db.node.createIndex({ itemIdx: 1, type: 1 })Amazon DocumentDB에서 partial index를 사용할 때는 explain()으로 실제 인덱스 활용 여부를 반드시 확인하세요. MongoDB에서 동작했다고 Amazon DocumentDB에서도 동작한다고 가정하면 안 됩니다.
$in 연산자와 SORT_MERGE 문제
문제 상황
실시간 에디터에서 특정 부모 노드 하위의 여러 타입 문서를 시간순으로 조회하는 쿼리입니다. 인덱스는 { parentId: 1, type: 1, createdDateTz: 1, _id: 1 } 구성이었습니다.
db.node.find({
parentId: "example-parent-id-001",
$or: [
{ type: "USER_RESOURCE" },
{ type: "USER_DESIGN" }
]
}).sort({ createdDateTz: 1, _id: 1 })MongoDB에서는 $or 조건을 각각 인덱스 스캔한 후 SORT_MERGE 스테이지로 정렬된 결과를 병합합니다. 인메모리 정렬 없이 효율적으로 처리됩니다.
Amazon DocumentDB에서는 SORT_MERGE를 지원하지 않습니다. 결과적으로 $or 또는 $in으로 조회한 전체결과를 메모리에서 정렬하게 되어, 대량의 fetch와 높은 지연이 발생했습니다.
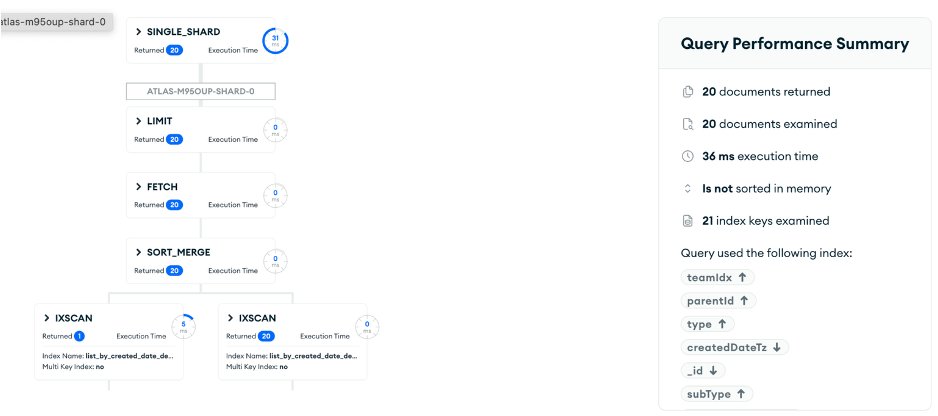
[Figure 1-1] MongoDB sort merge
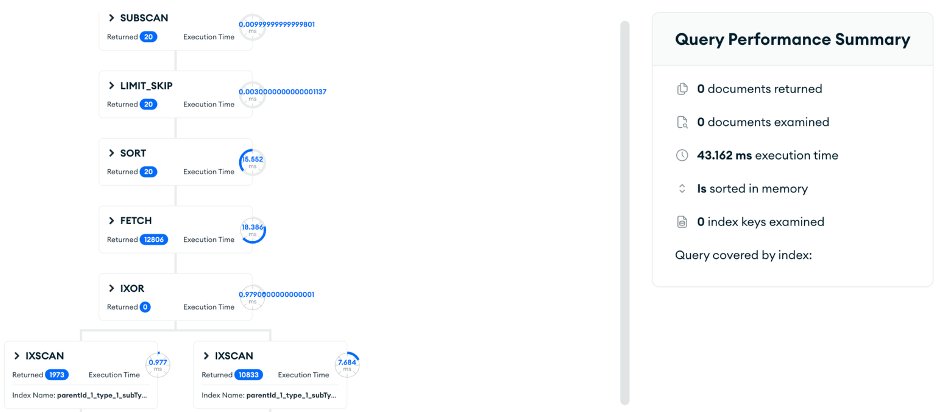
[Figure 1-2] DocumentDB 튜닝 전

[Figure 1-3] DocumentDB 튜닝 후
해결
쿼리 분리 후 애플리케이션 레벨 병합
복합 인덱스 재설계가 어렵거나 타입조합이 동적인 경우, 타입별 쿼리를 분리하여 애플리케이션에서 병합합니다.
[ 기존 ] 하나의 쿼리 ($or) ──→ DocumentDB (전체 fetch → 정렬) ──→ 결과
[ 개선 ] 쿼리 A (type=USER_RESOURCE) ──→ DocumentDB (인덱스 활용) ──┐
쿼리 B (type=USER_DESIGN) ──→ DocumentDB (인덱스 활용) ──┼→ 앱에서병합
└→ 결과Amazon DocumentDB에서 $or + sort를사용할 때는 SORT_MERGE가 없다는점을 전제로 인덱스를 설계해야 합니다. 가능하면 $or을 제거하고 복합 인덱스의 equality 필드로 흡수하세요.
Regex: Prefix 변환으로 IXSCAN 활용
문제 상황
파일 경로 기반으로 문서를 조회하는 쿼리에서 정규표현식을 사용하고 있었습니다.
// Before
db.collection.find({
path: RegExp("^MY_DRIVE:/example-folder-id/"),
id: { $ne: "example-folder-id" }
})Amazon DocumentDB에서 regex는 prefix match(/^pattern/)만 인덱스를 활용할 수 있지만, 실제로는 prefix match임에도 인덱스를 제대로 활용하지 못하는 경우가 있었습니다.
해결
regex 대신 range 쿼리로 변환하여 확실하게 IXSCAN을 활용합니다.
// After
db.collection.find({
path: {
$gt: "MY_DRIVE:/example-folder-id/",
$lt: "MY_DRIVE:/example-folder-id/\uffff"
}
})\uffff는 유니코드의 거의 마지막 문자로, 해당 prefix로 시작하는 모든 문자열을 range scan으로 커버합니다. 정규표현식을 활용한 쿼리를 range scan으로 변환한 사례입니다. 이 변환만으로 인덱스 힌트 없이 해당 쿼리의실행 계획이 카디널리티가 더 높은 IXSCAN으로 바뀌었습니다.
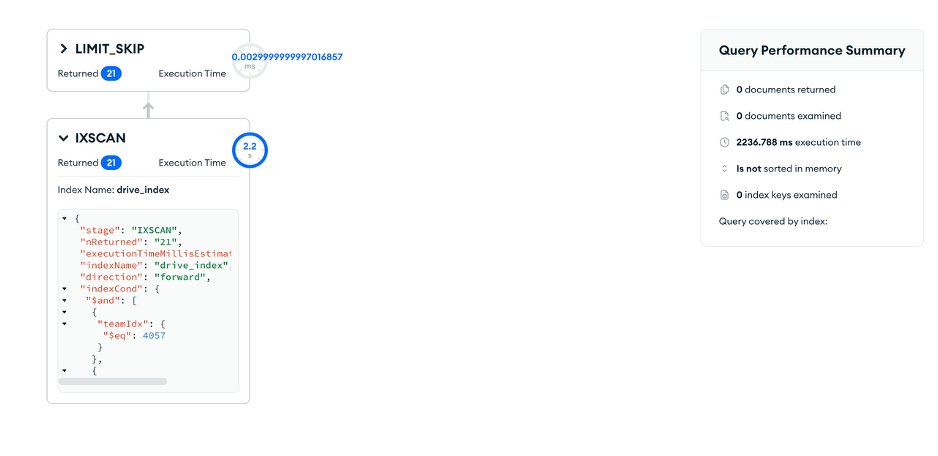
[Figure 2-1] 변환 전

[Figure 2-2] 변환 후
Document-Level Lock과 Hot Document
문제 상황
드라이브 서비스에서 통계를 추적하기위해 $inc 연산을 사용하고 있었습니다.
db.document.updateOne(
{ _id: documentId },
{ $inc: { childCount: 1 } }
)다수의 리소스가 한번에 이동되는 경우, 하나의 document에 $inc 연산이 집중됩니다. Amazon DocumentDB에서는 이것이 document-level lock 경합으로 이어져 쓰기 지연이 발생했습니다.
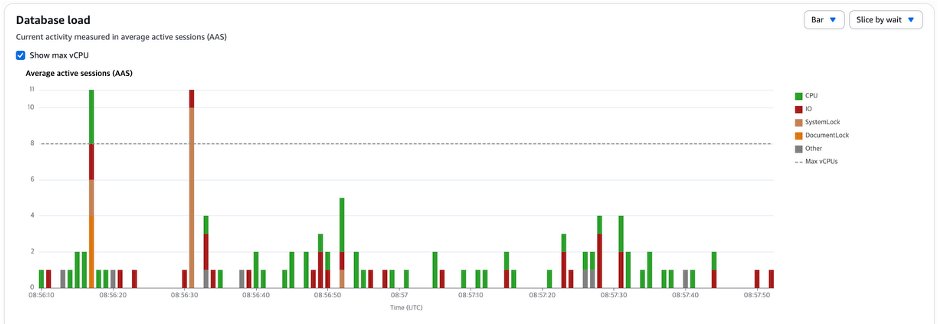
[Figure 3] DocumentDB Level Lock 경합 패턴
진단
Amazon DocumentDB의 Performance Insights에서 document-level lock 대기 시간을 확인할 수 있었습니다. 특정 document에 lock이 집중되는 “hot document” 패턴이 명확하게 보였습니다.
대응
저희는 이 문제에 대해 카운터를 Amazon ElastiCache(Redis)로 분리하는 방식을 적용했습니다. 빈번한 $inc 연산을 Redis의 INCR 명령으로 처리하고, 주기적으로 배치 업데이트를 통해 Amazon DocumentDB에 반영합니다.
이 변경으로 해당 document의 lock 경합이 해소되었고, 동시 편집 시 쓰기 지연이 정상 수준으로 복구되었습니다.
MongoDB에서는 WiredTiger의 동시성 제어가 이 패턴을 어느 정도 흡수하지만, Amazon DocumentDB에서는 hot document 패턴이 더 뚜렷하게 성능에 영향을 줍니다. $inc가 집중되는 document가 있다면 사전에 분산 전략을 수립하세요.
프로덕션 쿼리 튜닝 사례
인덱스 설계 외에도, 프로덕션 운영 단계에서 쿼리 형태를 변경하여 성능을 개선한 사례입니다. 인덱스 힌트강제 적용은 최후의 수단으로 두고, 쿼리 형태 변경으로 해결하는 것을 원칙으로 했습니다.
정렬 관련 인덱스 스캔 범위 축소
리스트의 첫 페이지 조회 쿼리 시 DocumentDB 플래너가 정렬 필드에 맞지 않는 인덱스를 선택하는 문제가있었습니다. 첫 페이지 조회 시에도 필터 조건에 정렬 필드(createdDateTz, updatedDateTz)관련 조건을 추가하여인덱스 힌트 없이 플래너가 적절하게 인덱스를 사용할 수 있도록 했습니다.
// Before: updatedDAteTz 인덱스 사용
db.collection.find({ parentId: "abc" })
.sort({ createdDateTz: -1 })
// After: 날짜 범위 조건 추가로 스캔 범위 축소
db.collection.find({
parentId: "abc",
createdDateTz: { $lte: new ISODate() }
}).sort({ createdDateTz: -1 })불필요한 정렬 조건 제거
idx, key를 활용한 쿼리에 불필요하게 포함된 정렬로 인해 SORT 스테이지가 추가되던 문제를 해결했습니다. 인덱스 순서와 정렬 순서가 일치하는 경우, 명시적 정렬을 제거하면 인덱스 스캔만으로 정렬된 결과를 얻을수 있습니다.
불필요한 샤드키 조건 제거
MongoDB 샤딩 환경에서 사용하던 샤드키 관련 조건이 Amazon DocumentDB에서는 불필요해졌습니다. 불필요한 필터 조건을 제거하여 쿼리 플래너가 최적의 인덱스를 선택하도록 유도했습니다.
// Before: 샤드키 포함
{ teamIdx: 123, itemIdx: 456, type: "USER_DESIGN" }
// After: 불필요한 샤드키 조건 제거
{ itemIdx: 456, type: "USER_DESIGN" }Query Profiler와 인덱스 통계 워밍
Query Profiler 설정
Amazon DocumentDB에서 slow query를 추적하려면 클러스터 파라미터 그룹에서 profiler를 활성화합니다.
profiler: enabled
profiler_threshold_ms: 100프로파일링 로그는 Amazon CloudWatch Logs로 내보내져 분석할 수 있습니다. 인스턴스 레벨에서 db.setProfilingLevel()로도 설정 가능하지만, 클러스터 파라미터 그룹을 통한 일괄 관리가 권장됩니다.
// 느린 쿼리 조회 (인스턴스 레벨)
db.system.profile.find().sort({ ts: -1 }).limit(10)인덱스 통계 워밍
마이그레이션 직후 의도한 인덱스를 활용하지 못하는 쿼리가 다수 발견되었습니다. 컬럼 카디널리티/쿼리/인덱스 관련 통계가 충분히 워밍되지 않은 것이 주요 원인이었습니다. AWS Support Case를 통해 이를 확인받았습니다.
마이그레이션 직후에는 통계가 충분히 축적되지 않아 Query Planner가 최적의 인덱스를 선택하지 못할 수 있으므로, 안정화 기간 동안 slow query를 집중 모니터링해야 합니다.
explain 활용법
// Amazon DocumentDB에서 쿼리 실행 계획 확인
db.collection.find({ ... }).explain("executionStats")explain 결과에서 확인할 핵심 필드:
- stage: IXSCAN(인덱스 활용) vs COLLSCAN(전체 스캔)
- nReturned vs totalDocsExamined: 비율이 클수록 비효율적
- executionTimeMillis: 실행 시간
운영 노하우: MVCC GC와 모니터링
MVCC Garbage Collection
Amazon DocumentDB는 MVCC(Multi-Version Concurrency Control) 기반으로 읽기 일관성을 제공합니다. 업데이트마다 새로운 문서/인덱스 버전이 생성되고, 고유한 MVCC ID를 소모합니다.
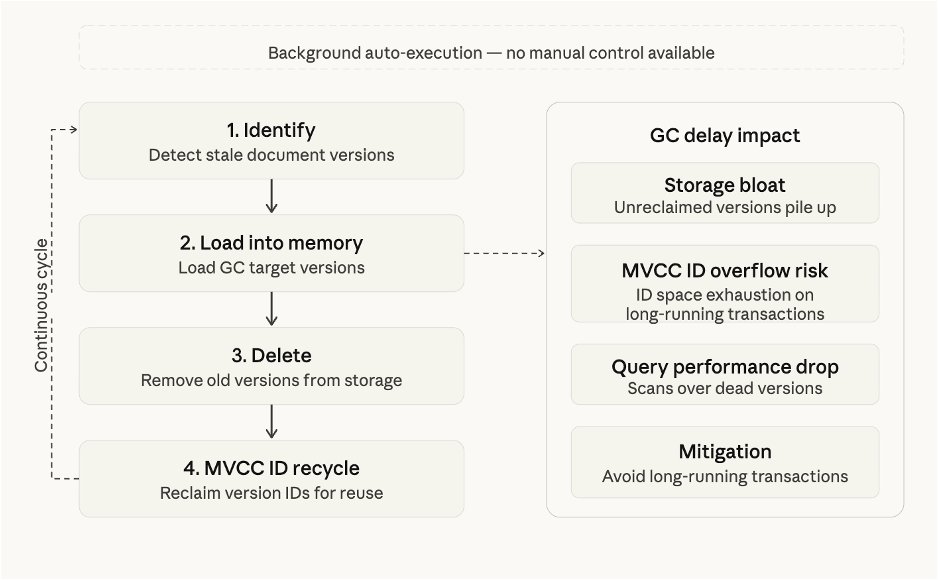
[Figure 4] 가비지 컬렉션
가비지 컬렉션은 네 단계로 동작합니다: 식별 → 메모리 로딩 → 삭제 → MVCC ID 재활용
- GC의 역할:
- 오래된 문서/인덱스 버전을 제거하여 저장 공간 확보
- MVCC ID 오버플로 방지 — 오버플로 시읽기 전용 모드로 전환되므로 주의
- 불필요한 버전 누적에 의한 쿼리 성능 저하 방지
- GC는 백그라운드에서 자동 실행되며, 실행 시점과 빈도는 시스템 부하와 MVCC ID 사용량 등에 따라 동적으로 조정됩니다. 현재 실행 윈도우를 지정하거나 수동 실행할 수 없으므로, 트래픽 피크 타임에 GC가 발생하여 성능이 저하되는 상황에 유의해야 합니다.
- 대응 방법:
- 장기 실행 트랜잭션 모니터링: 이전 버전의 MVCC ID가 누적되어 GC 부하 증가
- 불필요한 커서조기 종료: 열려 있는 커서가 MVCC 버전 정리를 차단
- GC 주기와 MVCC ID 사용량 추적: 급증 시 알람 설정
압축률 차이
Amazon DocumentDB 5.0까지는 LZ4만 지원했지만, 최신 엔진 업데이트에서 zstd 압축이 추가되었습니다. 다만 MongoDB Atlas 대비 압축률은 낮으므로, 스토리지 비용 산정시 이를 고려해야 합니다.
핵심 모니터링 포인트
- 캐시 히트율: RAM의 1/3은 자체 서빙, 2/3은 캐시에 할당. Working Set(데이터+인덱스)이 메모리에 들어가는 인스턴스 선택이 중요
- IO 비용 비율: 전체 Amazon DocumentDB 요금의 25% 이상이면 IO-Optimized 인스턴스가 유리
- GC 지표: MVCC ID 사용량, GC 빈도
- 하드웨어 리소스, 쿼리 지표, 연결 수
Amazon DocumentDB 인덱스 튜닝 체크리스트
Amazon DocumentDB 전환 시 인덱스를 점검할 때 활용할 수 있는 체크리스트입니다.
- Partial Index 조건 확인 — partialFilterExpression이 실제 쿼리 필터와 정확히 일치하는가? explain()으로 IXSCAN 여부를 확인했는가?
- $or + sort 패턴 점검 — SORT_MERGE가 필요한 쿼리가 있는가? 복합 인덱스로 흡수하거나 애플리케이션 레벨 병합으로 대체할 수 있는가?
- Regex → range 변환 — prefix match regex를 $gte/$lt range 쿼리로 변환할 수 있는가?
- Hot document 식별 — $inc 등 단일 document에 집중되는 쓰기 패턴이 있는가? 캐시 레이어로 분리할 수 있는가?
- 불필요한 샤드키 조건 — MongoDB 샤딩에서 넘어온 불필요한 필터 조건이 남아 있지 않은가?
- 정렬 조건 검증 — 인덱스 순서와 정렬 순서가 일치하는 경우 명시적 sort를 제거하여 SORT 스테이지를 방지할 수 있는가?
- 인덱스 통계 워밍 — 마이그레이션 직후 slow query를 집중 모니터링하고 있는가? Query Planner가 최적의 인덱스를 선택하기까지 안정화 기간이 필요함
결론
MongoDB에서 Amazon DocumentDB로의 전환에서 인덱스 최적화는 가장 시간이 많이 소요되었지만, 동시에 가장 큰 성능 개선을 가져온 영역이었습니다.
핵심 교훈을 요약하면 다음과 같습니다.
- Amazon DocumentDB의 Query Planner는 MongoDB와 다릅니다. 모든 주요 쿼리에 대해 explain()을 다시 실행하세요.
- SORT_MERGE가 없습니다. $or + sort 패턴은 복합 인덱스 재설계 또는 애플리케이션 레벨 병합으로 대체하세요.
- Partial index 조건은 정확히 일치해야 합니다. MongoDB에서 “비슷하게” 동작하던 것이 Amazon DocumentDB에서는 동작하지 않을 수 있습니다.
- Regex는 range 쿼리로 변환하세요. prefix match가 아니면 인덱스를 사용하지 않으며, prefix match인 경우에도 range 변환이 더 안정적입니다.
- Hot document 패턴을 사전에 식별하세요. $inc 집중은 Amazon DocumentDB에서 더 큰 영향을 줍니다.
- 인덱스 통계 워밍 기간을 고려하세요. 마이그레이션 직후에는 Query Planner가 최적의 인덱스를 선택하지 못할 수 있습니다.
- GC는 예측할 수 없습니다. 피크 타임의 성능 저하 가능성을 인지하고, MVCC ID 사용량을 모니터링하세요.
이 경험이 MongoDB에서 Amazon DocumentDB로의 전환을 준비하는 팀에게 도움이 되길 바랍니다.
관련 리소스
- Amazon DocumentDB 개발자 가이드
- Amazon DocumentDB와 MongoDB의 기능적 차이
- Amazon DocumentDB 인덱싱 모범 사례
- Amazon DocumentDB로 마이그레이션
- MongoDB ESR Rule for Creating Indexes