AWS 기술 블로그
Amazon DocumentDB로 미리캔버스의 성능 50%와 비용 30%를 개선하다
본 게시글은 미리디의 김민석, 이효성, 노정훈님과 함께 작성하였습니다.
미리디의 미리캔버스 소개

미리디의 미리캔버스는 “누구나 쉽게, 함께 만드는 디자인” 이라는 철학 아래, 프레젠테이션부터 SNS 카드뉴스, 유튜브 썸네일, 포스터까지 일상의 모든 시각 콘텐츠를 브라우저 하나로 만들 수 있는 실시간 협업 디자인 플랫폼을 운영하고 있습니다.
기획자와 마케터가 같은 슬라이드를 동시에 수정하고, 팀원이 실시간으로 댓글을 달며 피드백을 주고받는 순간들 미리캔버스는 디자이너가 아니어도 누구나 전문적인 결과물을 만들 수 있도록 협업의 문턱을 낮추고 있습니다.
이러한 실시간 다중 사용자 편집 환경을 안정적으로 지원하기 위해서는, 수많은 사용자의 편집 이벤트를 밀리초 단위로 처리할 수 있는 데이터베이스 인프라가 핵심입니다. 기존에는 MongoDB Atlas를 사용하고 있었으나, 서비스가 성장하면서 IOPS 병목과 비용 문제에 직면했습니다. 이 블로그에서는 MongoDB Atlas에서 Amazon DocumentDB(withMongoDB compatibility)로 전환하면서 마주한 기술적 도전과 해결 과정, 그리고 실제 성과를 공유합니다.
전환 배경
IOPS 병목
MongoDB Atlas는 스토리지 볼륨 기반으로 IOPS가 제한됩니다. 저희 환경에서는 약 3,000 IOPS가 상한이었고, WiredTiger 스토리지 엔진의 dirty cache flush와 checkpoint 과정에서 이 한계에 자주 도달했습니다. 1분마다 수행되는 체크포인트 작업으로 IOPS 스파이크가 발생하면 쓰로틀링으로 인한 복제 지연이 뒤따랐고, 이는 사용자 경험에 직접적인 영향을 미쳤습니다. 평균적인 쓰기 워크로드 수준에서 provisioned IOPS 옵션을 선택하기에는 불필요한 비용 증가로 판단했습니다.
전환 목표
이러한 배경에서 다음 세 가지 목표를 설정하고 Amazon DocumentDB를 전환 대상으로 검토하기 시작했습니다.
- IOPS 병목 근본적 해소
- AWS 네이티브 서비스와의 통합 강화
- 인프라 비용 최적화
Amazon DocumentDB 아키텍처 이해
전환을 결정하기 전에 가장 먼저 이해해야 했던 것은, Amazon DocumentDB가 “managed MongoDB”가 아니라 Amazon Aurora 기반의 MongoDB 호환 엔진이라는 점입니다.
스토리지 아키텍처
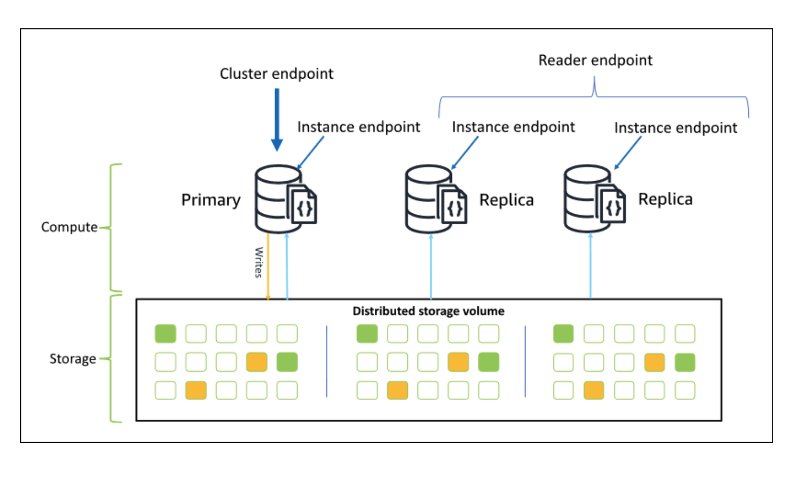
Amazon DocumentDB는 Amazon Aurora와 동일한 분산 스토리지를 사용합니다. 데이터는 3개 가용 영역(AZ)에 걸쳐 6개의 복사본으로 저장되며, 쿼럼 기반으로 내구성을 보장합니다.
- 쓰기: 6개 복사본 중 4개에 기록되면 ACK (4/6 쿼럼)
- 읽기: 6개 중 3개에서 읽어 일관성 확인 (3/6 쿼럼)
- 각 AZ에 2개씩 — Full Segment(페이지+로그)와 Tail Segment(로그만)로 구성
{kind=link}
{kind=link}
[Figure 1] Amazon DocumentDB 스토리지 아키텍처 다이어그램
이 쿼럼 모델은 동기식 복제(가장 느린 스토리지 사본이 전체를 지연)와 비동기식 복제(장애 시 데이터 유실 가능)의 절충안입니다. 6개 사본 중 4개만 응답하면 쓰기가 완료되므로 응답이 느린 2개의 사본은 무시할 수 있고, 4개에 확실히 기록되므로 1~2개 사본에 장애가 발생해도 데이터는 안전합니다.
AZ 하나가 통째로 장애를 겪더라도(해당 AZ의 스토리지 사본 2개 손실) 나머지 4개 사본으로 쓰기가 가능하고, 거기서 추가로 1개가 더 장애가 나도 3개 사본으로 읽기가 가능합니다. 여기서 말하는 6개 사본은 스토리지 레이어의 세그먼트이며, Amazon DocumentDB의 컴퓨팅 인스턴스(Writer, Replica)와는 별개입니다.
MongoDB Atlas와의 주요 차이점
Amazon DocumentDB의 Replica는 Primary의 데이터를 네트워크로 복제받는 것이 아니라, 동일한 분산 스토리지를 직접 읽습니다. Replica는 기본 인스턴스로부터 redo log와 LSN 정보를 전달받아 캐시만 갱신하며, 스토리지에는 이미 최신 데이터가 있으므로 승격 시간도 짧습니다. 이 차이가 replication lag에서 극적인 차이를 만들어냈습니다 — Atlas 37ms vs Amazon DocumentDB 2.5ms.
| 비교 대상 | MongoDB Atlas | Amazon DocumentDB |
|---|---|---|
| 복제 단위 | oplog (연산 로그) | redo log (LSN 기반) |
| 복제 대상 | Primary → Secondary (replica set) | Writer → 공유 스토리지(Replica 직접 읽기) |
| 스토리지 엔진 | WiredTiger (주기적 체크포인트) | Aurora 분산 스토리지 (WAL 직접 기록) 이용, 체크포인트를 수행하지 않음 |
| 읽기 일관성 | Read Concern 설정 | MVCC + LSN 기반 |
| 쓰기 확장 | 샤딩 (수평 분산) | 단일 Writer (수직 확장) |
IO-Optimized 스토리지 구성
Amazon DocumentDB의 IO-Optimized 스토리지 구성은 IOPS에 대한 별도 과금 없이 IO 집약 워크로드를 처리할 수 있게 해줍니다. Atlas에서 겪었던 3,000 IOPS 상한 문제가 근본적으로 해소되는 지점이었습니다.
POC: 호환성 검증
Amazon DocumentDB는 MongoDB API를 지원하지만, 100% 호환은 아닙니다. POC 단계에서 확인한 핵심 영역을 정리합니다.
API 호환성
AWS가 제공하는 호환성 평가 도구로는 애플리케이션 코드 레벨 분석이 어려웠기에, 프로덕션에서 사용하는 모든 쿼리를 직접 분석하기로 결정했습니다. mongodump / mongorestore로 개발 환경 데이터를 Amazon DocumentDB 5.0과 8.0에 적재한 뒤, explain을 통해 하나씩 검증했습니다.
- mongorestore: Amazon DocumentDB 8.0에서 bypassEmptyTsReplacement 옵션 미지원 이슈가 있어mongotools 100.9.5로 다운그레이드하여 진행
- 비호환 연산자 대체: $set aggregate → $addFields, Update Aggregate Field Path Expression → 조회 추가 방식, $lookup 내부 파이프라인 → $project/$replaceRoot로 분리
- Spring 프레임워크: Custom @Conditional Annotation으로 MongoDB/Amazon DocumentDB 환경을 분기 처리— 이 패턴은 이후 연결 전환 시에도 활용
압축률 비교
Amazon DocumentDB 5.0은 LZ4 압축, DocumentDB 8.0은 zstd 압축을 지원합니다. 저희는 8.0 + zstd를 선택했습니다. 다만 Atlas 대비 압축 효율은 낮았으며, 스토리지 비용 산정 시 이 차이를 고려해야 합니다.
| 환경 | 평균 문서 사이즈 | 압축률(미압축 대비) |
|---|---|---|
| 미압축 | 850B | — |
| Amazon DocumentDB 8.0 (zstd) | 700B | 17.60% |
| MongoDB Atlas (zstd) | 550B | 35.30% |
11억 건 기준으로 환산하면 약 165GB의 스토리지 차이가 발생합니다. IO-Optimized 구성에서는 IO 비용이 인스턴스에 포함되므로 전체 비용에서 차지하는 비율은 크지 않았지만, 대용량 데이터셋을 다루는 경우 사전에 확인이 필요합니다.
전체 데이터 셋에 대한 압축의 효율을 MongoDB Atlas에 비해 낮으나, 공유 스토리지를 사용함에 있어 기존 MongoDB Atlas 가 개별 컴퓨팅 노드별 스토리지를 가져가는 것에 비해 전체 사이즈면에서 효율을 가져갈 수 있습니다.
인덱스 전략
MongoDB에서 잘 동작하던 인덱스가 Amazon DocumentDB에서는 기대와 다르게 동작하는 경우가 많았습니다. ESR(Equality-Sort-Range) 원칙, partial index, $in 연산자, regex 패턴 등에서 차이가 있었고, 이 부분은 별도의 딥다이브 포스트에서 상세히 다룹니다.
→ 미리캔버스가 Amazon DocumentDB 전환 후 인덱스 최적화로 쿼리 성능을 개선한 방법
성능 테스트
k6를 활용한 stress test 결과입니다. POC 단계에서는 db.r6g.2xlarge 3대로 테스트를 진행했으며, 프로덕션에서도 동일한 구성으로 운영하고 있습니다.
| 항목 | Amazon DocumentDB (db.r6g.2xlarge) | MongoDB Atlas (M40, PSS 2-shard) |
|---|---|---|
| Stress QPS | 1,479/s | 1,432/s |
| Disk Write latency | 2.48ms | 1.9ms |
| avg Query latency | 1.7ms | 1.8ms |
| p95 Query latency | 4.6ms | 8.9ms |
| Max Replica lag | 25ms | 300ms |
처리량과 평균 레이턴시는 Atlas 2-shard와 비슷한 성능을 보여주지만, replication lag과 tail latency 측면에서는DocumentDB가 확연히 우수한 결과를 보였습니다.
쓰기 성능은 Atlas가 약간의 우위를 보였습니다. 이는 2-shard 구성에 따른 쓰기 분산의 이점이 반영된 결과입니다. 한편 MongoDB Atlas는 WiredTiger 엔진의 특성으로 인해 주기적인 IOPS 스파이크가 발생합니다. 이 때 IOPS 상한 초과로 인한 쓰기 쓰로틀링이 일어나면서 복제 지연이 급격히 커질 수 있고, read-after-write 일관성에 악영향을 미칠 수 있습니다.
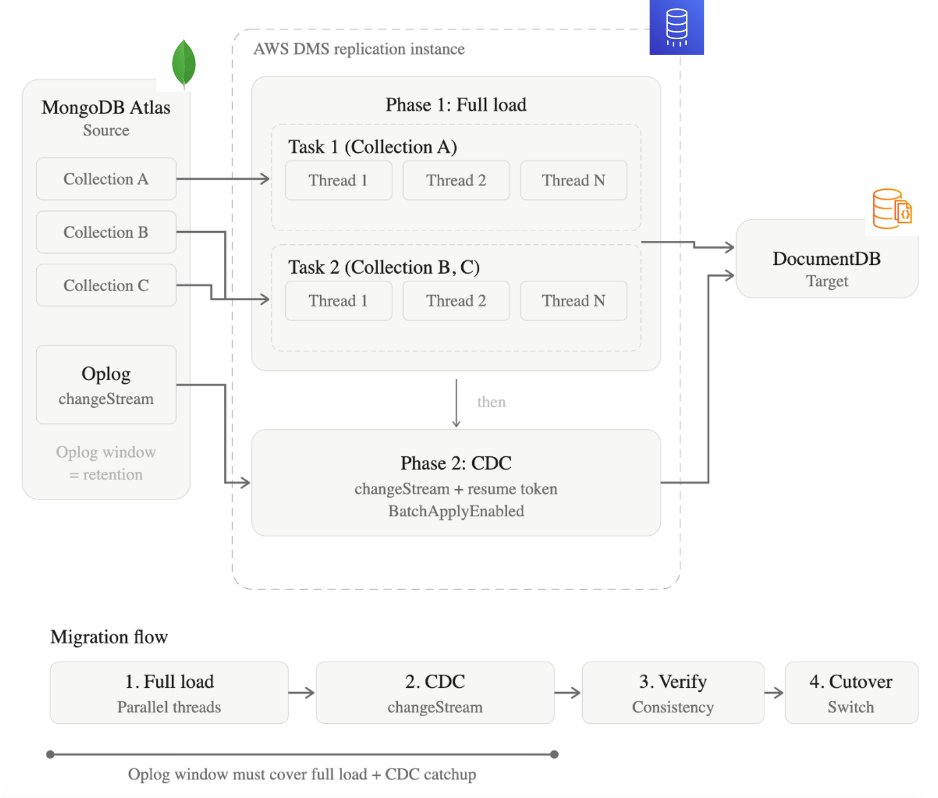
[Figure 2] DMS 기반 마이그레이션 아키텍처 다이어그램
실시간 에디터 서비스 특성상 약간의 쓰기 성능 차이와 안정성/일관성 간의 트레이드오프는 충분히 수용 가능했으며, 최종적으로 DocumentDB 마이그레이션을 선택했습니다.
마이그레이션 실행
AWS Database Migration Service(AWS DMS)를 활용하여 마이그레이션을 수행했습니다. 무중단 전환은 불가능하다고 판단했고, 마이그레이션 시나리오를 다음과 같이 확정했습니다.
- AWS DMS Full Load로 전체 데이터 적재
- Task, Thread 단위로 parallel loading
- 서비스 점검 다운타임까지 CDC로MongoDB-Amazon DocumentDB 간 싱크유지
- oplog window 범위 내에서 CDC 적용
- 다운타임 중 연결 변경
DMS 베스트 프랙티스
마이그레이션 과정에서 얻은 핵심 교훈입니다.
- 인덱스 사전 생성: AWS DMS는 인덱스 없이 로드하는 것을 권장하지만, 로드 후 짧은 시간 내에 서비스 전환이 필요했기에 인덱스를 미리 생성하고 마이그레이션을 진행했습니다.
- 병렬 로딩: source / target 데이터베이스 타입에 따라 적용할 수 있는 병렬 로드 설정과 그 효과가 다르므로, 여러 설정을 테스트해보는 것이 중요합니다.
- IO-Optimized 활용: 마이그레이션 중 대량 IO가 발생하므로, IO-Optimized 인스턴스 타입으로 변경 후진행하는 것이 비용 효율적입니다.
- 스케일링 전략: 빠른 로딩을 위해 스케일 업 후 마이그레이션하고, 완료 후 스케일 다운합니다.
Full Load: 11억 건의 병렬 로딩
AWS DMS의 Full Load는 Table-Setting 옵션으로 멀티 스레딩과 병렬 처리를 설정할 수 있습니다. MongoDB source, Amazon DocumentDB target 조합에서는 partitions-auto와 range 타입을 지원합니다.
처음에는 partitions-auto를 사용하여 컬렉션을 자동 분할하는 방식으로 접근했습니다. number-of-partitions와 max-records-skip-per-page 등의 파라미터를 조정할 수 있지만, 다양한 조합을 테스트해도 기대한 처리량이 나오지 않았습니다.
최종적으로 range 타입으로 전환하여 수동으로 균일한 경곗값을 설정한 결과, 처리량 저하 없이 빠른 시간 내에 11억 건 적재를 완료할 수 있었습니다. 대용량 컬렉션에서 자동 파티셔닝의 분할이 균일하지 않을 때는 수동 range 설정이 더 효과적이었습니다.
CDC (Change Data Capture)
Full Load 완료 후, CDC를 통해 실시간 변경분을 동기화합니다.
- changeStream 기반: MongoDB의 oplog을 changeStream으로 캡처하여 Amazon DocumentDB에 적용
- oplog window: 최소 24시간 확보 — AWS DMS가 Full Load 중 발생한 변경분을 놓치지 않도록
- ParallelApplyThreads / ParallelApplyBuffer: CDC 적용 속도 향상을 위한 병렬 처리 설정
프로덕션 CDC 손실 사례와 긴급 대응
프로덕션 환경에서 예상치 못한 장애가 발생했습니다. CDC 처리량이 저하되면서 changeStream 포지션이oplog window보다 뒤쳐졌고, 미처 처리하지 못한 변경분이 손실되었습니다.
CDC 안정화를 위한 모니터링 체계가 갖춰지기 전에 Full Load를 진행한 것이 근본 원인이었습니다. 프로덕션 수준의 쓰기 부하에서 CDC 처리량을 사전에 검증하지 못한 것입니다.
서비스 점검이 이미 고객에게 공지된 상황에서 이틀밖에 남지 않았기에, Full Load + CDC를 처음부터 재시작하는 것은 불가능했습니다. 문서 수가 적은 컬렉션은 AWS DMS를 다시 실행하여 해결했고, 대용량 컬렉션에대해서는 두 가지 긴급 대응을 진행했습니다.
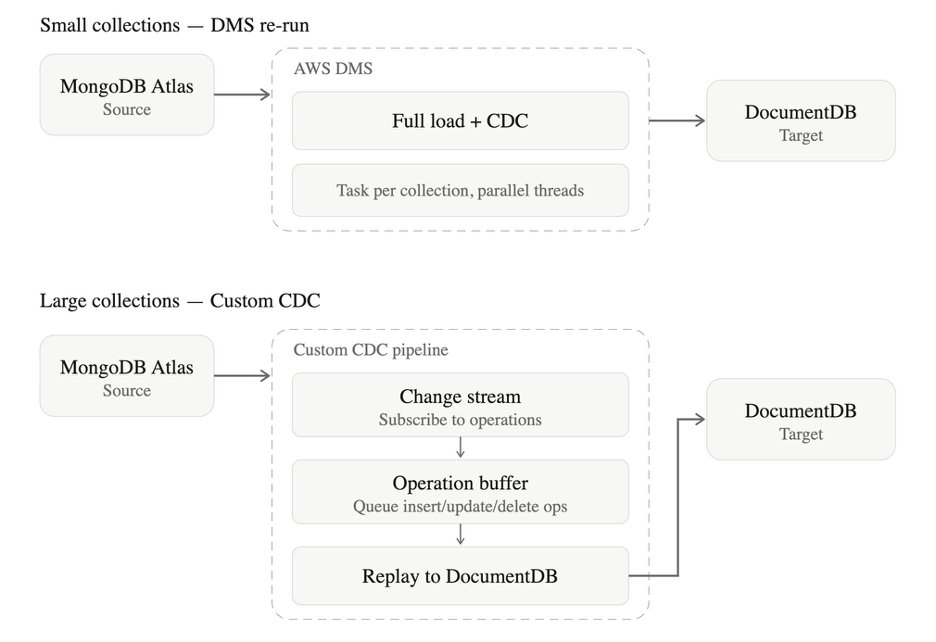
[Figure 3] CDC 장애 대응 흐름도
- 직접 CDC 구현MongoDB changeStream을 구독하여 버퍼에 저장하고, 버퍼가 차면 Target DB에 bulk write하는 시스템을 직접 구현했습니다. 동일한 MongoDB API를 사용하므로 엔티티 모델 변경 없이 빠르게 쓰기 오퍼레이션을 리플레이하는 방식으로 개발할 수 있었습니다.
- 누락 데이터 유형별 수동 복구changeStream이 끊긴 구간의 누락 데이터를 유형별로 복구했습니다.
| 유형 | 복구 방법 |
|---|---|
| 삽입 | MongoDB ObjectId에 내장된 타임스탬프를 활용, 끊긴 시각~재개 시각 사이의 문서를 조회후 삽입 |
| 수정 | Databricks에서 updatedDate 컬럼 기반으로 변경분 조회 후 수동 반영 |
| 삭제 | 하드 삭제 시 백업 컬렉션에 저장된 ObjectId 기반으로 삭제 처리 |
감사 컬럼과 백업 데이터가 이미 체계적으로 관리되고 있었기에 가능한 복구였습니다. 이 경험에서 얻은 교훈은 다음과 같습니다.
- CDC 테스트 시 프로덕션 수준의 쓰기 부하를 반드시 재현할 것
- Full Load 완료 후 CDC lag 모니터링을 즉시 시작할 것
- 데이터 감사 체계(audit column, 백업 컬렉션)가 마이그레이션 장애 복구의 마지막 안전망이 될 수 있음
연결 전환
DB 커넥션 정보를 AWS Secrets Manager로 관리하여, 전환 시 애플리케이션 재배포 없이 엔드포인트를 변경했습니다. POC 단계에서 구현한 Spring Custom @Conditional Annotation을 통해 DB 연결 문자열에 따라 레포지토리 구현체가 자동 전환되도록 구성했습니다.
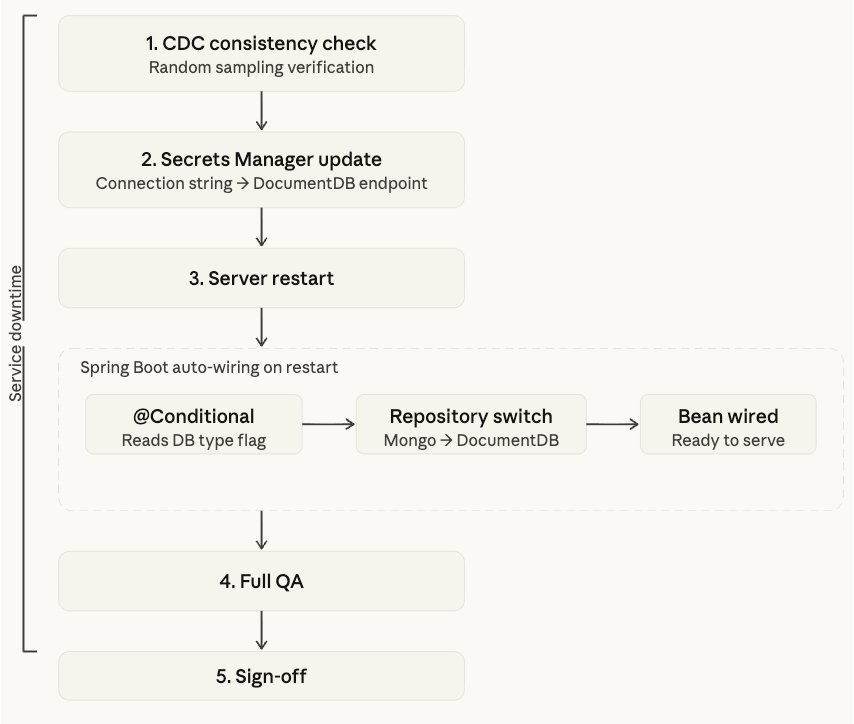
[Figure 4] 연결 전환 절차 다이어그램
서버 다운타임 동안의 전환 절차는 다음과 같습니다.
- 직접 구현한 CDC에 누락이 없는지 최신 데이터와 랜덤 샘플링 데이터 대조로 정합성 검증
- AWS Secrets Manager의 연결 문자열을Amazon DocumentDB 엔드포인트로 변경
- 서버 재기동
- 전체 기능 QA를 거쳐 점검 마무리
운영 안정화
인스턴스 구성과 Failover
프로덕션 환경에서는 db.r6g.2xlarge 3대로 구성하여 고가용성을 확보했습니다. IO-Optimized(iopt1) 스토리지를 사용하여 IOPS 과금 없이 IO 집약 워크로드를 처리합니다.
| 역할 | 인스턴스 타입 | AZ | 용도 |
|---|---|---|---|
| Primary (Writer) | db.r6g.2xlarge | AZ-1 | 읽기/쓰기 |
| Replica 1 | db.r6g.2xlarge | AZ-2 | 읽기 전용 |
| Replica 2 | db.r6g.2xlarge | AZ-3 | 읽기 전용, analytics 워크로드 |
Failover 검증 결과 약 30초 이내 복구를 확인했으며, serverSelectionTimeoutMS를 30초로 설정하여 failover 중 커넥션 재시도를 처리했습니다.
모니터링
Amazon CloudWatch Metric Stream을 활용하여 CPU, IOPS, 메모리 등 핵심 지표를 실시간 모니터링하는 체계를 구축했습니다. 특히 Working Set 대비 RAM 비율을 추적하여 IO-Optimized 모드의 효과를 지속적으로 검증했습니다.
성과
전환 완료 후 측정한 핵심 지표입니다. 프로덕션 환경은 Amazon DocumentDB 8.0, db.r6g.2xlarge × 3대, IO-Optimized(iopt1) 스토리지로 구성되어 있습니다.
| 지표 | Before (Atlas) | After (Amazon DocumentDB) | 개선 |
|---|---|---|---|
| DB 응답속도(p50) | 4.2ms | 2.1ms | 50% 개선 |
| IOPS 상한 | 3,000 (제한) | 무제한 (IO-Optimized) | 병목 해소 |
| Replication lag | 37ms | 2.5ms | 93% 감소 |
| 인프라 비용 | — | — | 약 30% 절감 |
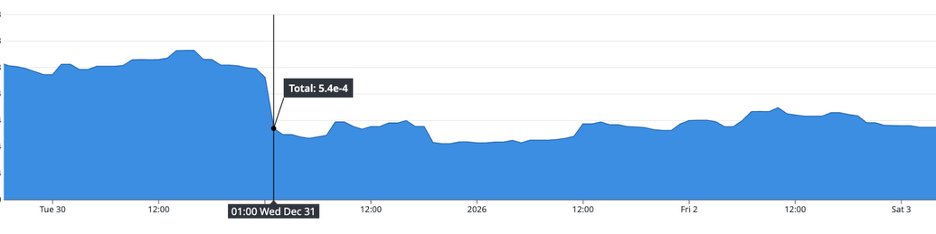
[Figure 5-1] 서비스 평균 데이터베이스 응답시간 감소
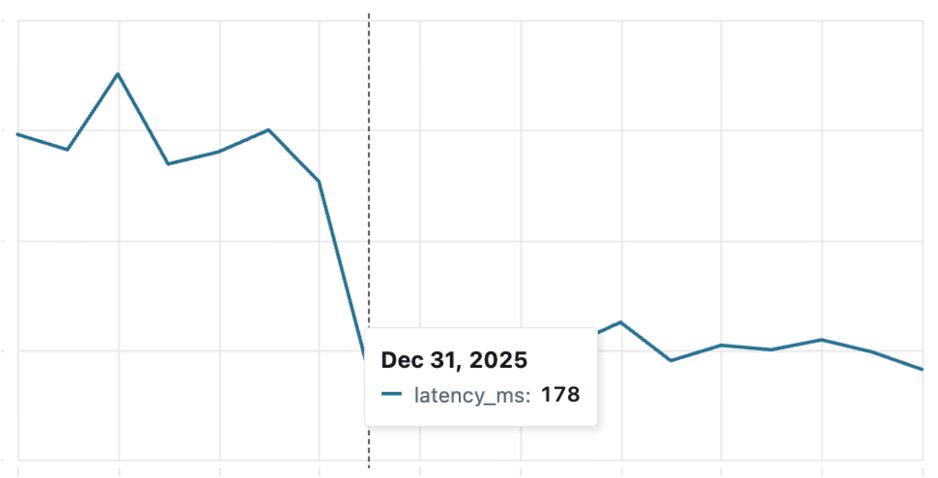
[figure 5-2] 평균 쓰기 커맨드 처리 대기시간 감소
결론
MongoDB Atlas에서 Amazon DocumentDB로의 전환을 고려하고 있다면, 저희 경험에서 얻은 핵심 교훈을 공유합니다.
- Amazon DocumentDB는 “managed MongoDB”가 아닙니다. Aurora 기반의 MongoDB 호환 엔진입니다. 아키텍처가 다르기 때문에 동작 방식도 다릅니다.
- 인덱스 전략 재설계가 가장 중요한 사전 작업입니다. MongoDB에서 잘 동작하던 인덱스가 Amazon DocumentDB에서는 다르게 동작할 수 있습니다. POC 단계에서 주요 쿼리 패턴을 모두 검증하세요.
- Write ceiling을 반드시 테스트하세요. 단일 Writer 구조이므로, 서비스의 peak write QPS가 Amazon DocumentDB Writer 한 대로 감당 가능한지 확인해야 합니다.
- Replication lag과 read-after-write 일관성을 검증하세요. 서비스 특성에 따라 이 지표가 QPS보다 더 중요할 수 있습니다.
- AWS DMS CDC의 oplog window를 충분히 확보하고, CDC lag을 실시간 모니터링하세요. Full Load 시간이 길어질 경우 oplog이 덮어씌워지면 CDC가 실패합니다. 프로덕션 수준의 쓰기 부하에서 CDC를 반드시 사전 검증하세요.
- 데이터 감사 체계를 마이그레이션 전에 점검하세요. 장애 발생 시 audit column과 백업 데이터가 최후의 안전망이 됩니다.
이 글에서 다루지 못한 인덱스 최적화의 상세 내용은 다음 포스트에서 이어집니다.
→ 미리캔버스가 Amazon DocumentDB 전환 후 인덱스 최적화로 쿼리 성능을 개선한 방법
관련 리소스
- Amazon DocumentDB 개발자 가이드
- Amazon DocumentDB와 MongoDB의 기능적 차이
- Amazon Aurora under the hood: quorums and correlated failure
- AWS DMS를 사용하여 Amazon DocumentDB로 마이그레이션
- Amazon DocumentDB IO-Optimized