AWS 기술 블로그
GloZ의 Amazon OpenSearch Service를 기반으로 한 자연어 이력서 검색 시스템 구축 사례 — Part 1: 데이터 파이프라인과 인덱싱
1. 회사 및 서비스 소개
글로지(GloZ Inc.)

글로지(GloZ Inc.)는 OTT, 게임, 웹툰·웹소설, 더빙 등 콘텐츠 로컬라이제이션을 전문으로 하는 기업으로, 70개 이상의 언어와 190여 개국에 콘텐츠를 전달하고 있습니다. 서울, 캘리포니아, 싱가포르, 도쿄 4개 거점과 전 세계 210여 개 도시에 분포한 언어 전문가 네트워크를 기반으로, 글로벌 OTT 파트너 품질 평가에서 4년 연속 1위를 기록해 왔습니다.
글로지는 번역 관리 플랫폼 E’nuff, 영상 번역도구 WowSub, AI 기반 로컬라이제이션 워크스페이스 LABS를 자체 개발해 운영하고 있습니다. 이번 프로젝트는 이 중 E’nuff 플랫폼에 등록된 약 10만 명의 전문 번역가 풀을 대상으로, 기존 이력서 검색 시스템을 Amazon OpenSearch Service 기반으로 재설계·고도화한 것입니다.
2. 프로젝트 배경
비즈니스 요구사항
글로지는 글로벌 콘텐츠 제작사로부터 매주 수백 건의 번역 프로젝트를 수주합니다. 각 프로젝트는 단순한 언어쌍·도메인 외에도 CAT 도구 사용 경험, 특정 콘텐츠 작업 이력, 번역가의 거주 시간대(time zone), 희귀 언어 보유 여부 등 다양한 조건이 결합됩니다. 시간대는 특히 해외 콘텐츠 제작사와의 실시간 커뮤니케이션이 필요한 프로젝트에서 중요한 매칭 조건으로 작용합니다. 또한 일반 독자 시각의 번역물 평가처럼 특정 분야의 번역 경험이 오히려 없어야 하는 특수한 요건이 필요한 경우도 있습니다.
번역 프로젝트에서는 최종 투입 인원의 수 배수에 해당하는 후보군을 초기에 확보해야 합니다. 따라서 등록된 약 10만 명의 번역가 중에서 다양한 요건을 만족하는 후보를 충분한 규모로 빠르게 추려내는 것이 프로젝트 진행 속도를 결정하는 핵심 요소이며, 이를 위한 검색 시스템이 필요합니다.
기존 워크로드의 한계점
초기에는 PostgreSQL 기반 메타데이터 필터링과 자체 구축한 벡터 검색 라이브러리를 조합한 PoC 시스템을 운영했습니다. 하지만 다음과 같은 한계로 인해 프로덕션 환경에서 확장하기 어려웠습니다.
자체 구축 벡터 라이브러리 운영의 한계
PoC 단계에서 사용한 자체 벡터 검색 라이브러리는 프로토타입 검증에는 적합했지만 프로덕션 워크로드에는 다음과 같은 문제가 있었습니다.
- 벡터 검색에는 특화되어 있으나 키워드 검색(BM25)을 함께 처리할 수 없어, 하이브리드 검색을 구현하기 위해서는 별도의 검색 엔진이 필요합니다.
- 인덱스 갱신·모니터링·확장이 표준화되어 있지 않아 운영 부담이 큽니다.
다국어·한국어 처리 미흡
이력서는 한국어, 영어를 비롯해 일본어·중국어·프랑스어 등 30여 개 언어로 작성된 다국어 문서가 혼재되어 있습니다. 한국어 이력서는 형태소 분석 부재로 동의어·조사·어미 처리가 어려웠고, 다국어 임베딩 모델만으로는 의미 유사도는 잡아내더라도 CAT Tools 이름, 플랫폼명(Netflix, Disney+), 약어(MTPE, SDH) 등의 정확 매칭이 약하다는 한계가 있었습니다. 이 때문에 키워드 검색(BM25)과 의미 기반 검색을 결합한 하이브리드 검색이 필수적이었습니다.
해결하고자 한 구체적 과제
이러한 한계를 종합하여, 본 프로젝트는 다음과 같은 과제를 해결하는 것을 목표로 삼았습니다.
- 검색 정확도: 자연어 검색 시 nDCG@10 지표(Normalized Discounted Cumulative Gain — 상위 10개 검색 결과의 관련도를 정규화한 평가 지표)에 대해 0.90 이상을 확보합니다.
- 하이브리드 검색: BM25와 Vector 검색을 단일 쿼리로 처리합니다.
- 다국어·한국어 검색 품질: Nori 형태소 분석기와 다국어 임베딩 모델을 결합하여 한국어 및 다국어 이력서 검색 품질을 확보합니다.
이 중 검색 정확도와 하이브리드 검색 최적화에 대해서는 Part 2에서 자세히 다룹니다. Part 1에서는 이를 뒷받침하는 데이터 파이프라인과 인덱싱 설계를 중심으로 설명합니다.
3. 솔루션 구현 — 데이터 파이프라인과 인덱싱
검색 엔진을 Amazon OpenSearch Service로 전환하고, Amazon Bedrock(Cohere 임베딩 + Claude LLM)을 활용한 데이터 정제·임베딩 생성 파이프라인을 구축했습니다.
Amazon OpenSearch Service

기존의 PostgreSQL 기반 메타데이터 필터링과 자체 구축한 벡터 검색 라이브러리 조합은 키워드 검색(BM25)과 벡터 검색을 별도 시스템으로 분리 운영해야 하는 구조적 한계, 인덱스 갱신·모니터링의 표준화 부재, 그리고 한국어 형태소 분석 미지원 등의 문제로 프로덕션 확장이 어려웠습니다.
Amazon OpenSearch Service를 선택한 이유는 다음과 같습니다.
- 하이브리드 검색을 단일 엔진에서 처리: BM25 키워드 검색과 k-NN 벡터 검색을 하나의 쿼리로 결합할 수 있어, 기존처럼 별도 시스템을 조합할 필요가 없습니다. Search Pipeline의 normalization-processor를 통해 두 점수의 정규화·결합 방식과 가중치를 선언적으로 제어할 수 있습니다.
- Ingest Pipeline을 통한 임베딩 자동화: ML Connector를 통해 Amazon Bedrock의 임베딩 모델을 OpenSearch에 직접 연결하여, 문서 인덱싱 시 별도 코드 없이 벡터 임베딩을 자동 생성할 수 있습니다. 임베딩 생성을 위한 별도 Lambda나 서비스를 운영할 필요가 없어 아키텍처가 단순해집니다.
- 한국어 형태소 분석 지원: Nori 형태소 분석기를 패키지로 설치하여 한국어 복합어 분해, 읽기형 변환, 품사 기반 필터링을 적용할 수 있습니다. 이를 통해 “게임 로컬라이제이션”, “K-드라마 자막” 같은 한국어 복합어 검색이 정확하게 동작합니다.
- 완전관리형: 인덱스 갱신·모니터링·확장이 표준화되어 있어, 자체 구축 대비 운영 부담이 크게 줄어듭니다. 향후 데이터 규모 확대 시에도 노드 스케일업으로 대응할 수 있습니다.
핵심 설계 원칙
- 데이터 정제(Cleansing) 우선: 임베딩 모델 선택보다 입력 텍스트(요약·메타데이터)의 품질이 검색 정확도에 더 큰 영향을 미치므로, 이력서 원문을 구조화된 메타데이터로 변환하는 파이프라인 설계에 우선순위를 두었습니다. 실제로 동일 임베딩 모델에서도 입력 텍스트 구성 방식만 바꿔도 nDCG@K가 크게 변동되었습니다.
- k-NN 알고리즘으로 HNSW 채택: k-NN 벡터 검색에서 OpenSearch가 지원하는 알고리즘은 크게 Brute Force, IVF, HNSW가 있습니다. Brute Force는 정확하지만 데이터가 늘어날수록 느려지고, IVF는 별도 학습 데이터와 클러스터 파라미터 튜닝이 필요합니다. 반면 HNSW는 그래프 기반으로 학습이 불필요하고, 인덱싱 시점에 자료구조가 구성되어 검색 시 빠른 응답이 가능합니다. 본 워크로드는 인덱싱 빈도가 낮고 검색 응답 속도가 중요한 특성이라 HNSW + L2 거리 함수 조합을 선택했습니다.
모델 선택 근거
임베딩 모델 (Cohere Embed v4): 약 30여 개 언어로 작성된 이력서가 혼재되는 환경에서 다국어 표현력이 검증된 모델이 필요했습니다. 모델별·차원별 비교 실험에서 Cohere가 Titan Text Embedding v2 대비 nDCG@10 약 40% 수준의 우위를 보여 채택했습니다.
LLM (Bedrock Claude Haiku 4.5): 이력서 메타데이터 구조화 단계에는 후처리 검증(원문과의 키워드 매칭)을 결합하여 환각을 통제했고, 이를 통해 상위 모델 없이 Haiku 4.5만으로도 안정적인 데이터 품질을 확보할 수 있었습니다.
데이터 정제 파이프라인 구축
문서 유형·구조별 파싱
이력서 파일은 PDF, DOCX, 이미지 기반 PDF 등 다양한 형식으로 제출되며, 약 30여 개 언어로 작성되어 있습니다. 모든 문서를 LLM으로 일괄 처리하면 비용 부담이 크고 응답 시간이 길어지므로, 문서 유형별로 적합한 도구를 적용하는 다단계 파이프라인을 구축했습니다.
- 텍스트 레이어가 살아있는 PDF는 PyMuPDF로 직접 추출
- DOCX는 LibreOffice 변환을 통한 텍스트 추출
- 이미지 기반 PDF·스캔본은 OCR 처리
- 위 단계에서 텍스트 추출이 실패하거나 품질이 낮은 일부 케이스에는 LLM fallback을 적용하여 보완
이 구조로 모든 문서를 LLM으로 처리하는 단순 접근 대비 비용을 크게 절감하면서도, 다양한 문서 형식에 대해 파싱 실패 없이 안정적인 처리율을 확보했습니다.
LLM 기반 메타데이터 구조화 + 동의어·표기 변형 정규화
추출된 원문 텍스트를 검색에 활용 가능한 구조화 데이터(언어쌍, 콘텐츠 도메인, 프로젝트 유형, 사용 도구, 경력 수준, 전문 분야 등)로 변환하기 위해 Bedrock Claude 모델을 활용했습니다. 이력서마다 동일한 의미를 다르게 표기하는 경우가 매우 많았기 때문에(예: “SDL Trados Studio” / “Trados Studio” / “Trados”, “ko-en” / “한영” / “Korean to English”, “MTPE” / “post-editing” / “기계번역 후편집”), LLM이 추출한 자유 텍스트를 다음 3단계로 정규화하여 표준 분류 체계에 매핑했습니다.
- 표준 어휘 사전 (VALID_VALUES): 검색에 사용할 표준 카테고리 사전 (언어쌍, 콘텐츠 도메인, 프로젝트 유형, 도구 등)
- 별칭 사전 (ALIASES): 한국어·영어·약어를 표준어로 매핑 (예: “한영” → “ko-en”, “트라도스” → “trados”, “MTPE” → “post-editing”)
- 퍼지 매칭 (Fuzzy Matching): 사전에 등록되지 않은 신규 표기는 편집 거리 기반 매칭으로 가장 가까운 표준어에 흡수
이를 통해 인덱싱 대상 이력서 전체에 대해 일관된 어휘 체계로 메타데이터를 정규화했습니다.
LLM 환각(Hallucination) 후처리 검증
LLM 기반 메타데이터 구조화 과정에서 이력서에 명시되지 않은 정보를 자동 생성하는 환각 문제가 발생할 수 있습니다. 이를 방지하기 위해 LLM 출력에 대해 원문 텍스트와의 키워드 매칭 기반 후처리 검증을 도입하여, 원문에 등장하지 않는 도구·도메인 키워드는 자동으로 제거하도록 했습니다. “LLM이 만든 메타데이터를 그대로 신뢰하지 않는다”는 원칙을 단순한 검증 단계로 구현하여, 데이터 품질을 안정적으로 확보했습니다.
검증 과정 예시
실제 이력서 파싱 결과는 LLM에 전달되어 다음과 같이 구조화된 JSON으로 변환됩니다. 모든 추출 값은 이력서 원문에 명시된 정보로만 제한되며, 환각(Hallucination) 후처리 검증을 통해 원문에 없는 필드는 자동으로 제거됩니다.
1. 입력 예시
John Doe
Experience
2022 - present Freelance Subtitle Template Creation
Standard and CC/SDH
Anonymous Studios A, USA
Anonymous Studios B, USA
2021 - 2022 Anonymous Film Studios, Munich, Germany
Education
2013 - 2022 International School, Germany
Bilingual education, English and German
Special Skills
Native English, fluent German, conversational Spanish
Microsoft Office, EZ Titles, online subtitling programs2. 출력 예시
{
"professional_summary": "Mid-level translator with experience in technical and medical translation, fluent in English and German. Work history includes freelance subtitle template creation (Standard, CC/SDH) and an internship in subtitling at a German film studio.",
"language_pairs": ["en-de"],
"content_types": ["technical", "medical", "subtitling"],
"project_types": ["translation", "subtitling"],
"tools": ["ez titles"],
"specialized_areas": [
"technical documentation",
"medical translation",
"subtitle creation"
],
"experience_level": "mid",
"total_experience_months": 36
}
자유 텍스트로 작성된 이력서에서, 검색 가능한 표준화된 필드(language_pairs, content_types, tools, specialized_areas 등)를 추출하게 되고, 별칭 사전(예: “EZ Titles” → “ez titles”)을 통해 일관된 어휘 체계로 정규화하게 됩니다.
인덱싱 아키텍처
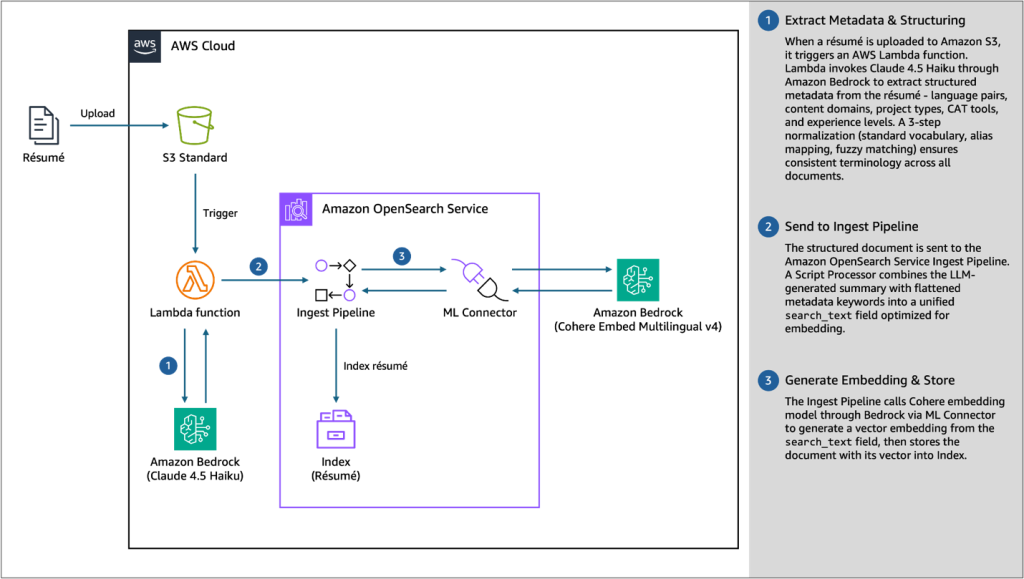
1. 메타데이터 추출 및 구조화 (Extract Metadata & Structuring)
- 이력서가 S3에 업로드되면 Lambda가 트리거되고, Amazon Bedrock의 Claude Haiku 4.5 (global.anthropic.claude-haiku-4-5-20251001-v1:0) 를 호출하여 메타데이터(언어쌍, 도메인, 도구, 경력 등)를 추출·구조화합니다. 3단계 정규화(표준 어휘 사전, 별칭 매핑, 퍼지 매칭)를 통해 일관된 용어 체계를 확보합니다.
2. Ingest Pipeline 전달 (Send to Ingest Pipeline)
- 구조화된 문서를 OpenSearch Ingest Pipeline으로 전달합니다. Script Processor가 요약 텍스트와 메타데이터 키워드를 결합하여 임베딩에 최적화된
search_text필드를 생성합니다.
3. 임베딩 생성 및 저장 (Generate Embedding & Store)
- Ingest Pipeline이 ML Connector를 통해 Amazon Bedrock의 Cohere Embed Multilingual v4를 호출하여 벡터를 생성하고, Index(Résumé)에 저장합니다.
임베딩 입력 전략 비교 — 요약 + 메타데이터 키워드 평탄화 채택
벡터 임베딩의 입력으로 사용되는 텍스트 구성이 검색 정확도에 결정적인 영향을 미친다는 점을 실험으로 확인했습니다. PoC 단계에서 4가지 입력 전략을 동일 평가 셋으로 비교하여 후보 전략을 선정한 뒤, 운영 환경의 평가 쿼리 셋(약 150건)으로 동일 경향을 재검증했습니다.
예상과 다르게, 가장 정보량이 많은 원문 전체 임베딩이 가장 낮은 정확도를 보였습니다. 각 전략의 결과를 분석하면 다음과 같습니다.
| 전략 | 설명 | nDCG@10 | 분석 |
|---|---|---|---|
| 원문 전체 | 이력서 전문을 그대로 임베딩 (약 2,000자) | 0.781 | 자기소개·취미 등 무의미한 토큰이 핵심 신호를 묻음 |
| 구조화 JSON | 메타데이터를 JSON 형태로 임베딩 | 0.802 | 중괄호·키 이름 등 구조적 토큰이 잡음으로 작용 |
| 요약만 | LLM 요약문만 임베딩 (300~500자) | 0.831 | 핵심 역량은 잡지만 도구명·키워드 정확 매칭 약함 |
| 요약 + 키워드 평탄화 | 요약 + 메타데이터를 자연어로 결합 | 0.852 | 의미 유사도 + 키워드 정확 매칭 모두 확보 |
이 결과를 바탕으로 요약 + 메타데이터 키워드 평탄화 방식을 채택했으며, PoC 단계와 운영 환경 모두에서 동일한 순위가 일관되게 관찰되었습니다.
Index Mapping 설계
resumes-v01 인덱스의 핵심 매핑은 아래와 같이 구성했습니다. embedding 필드는 knn_vector 타입으로 정의하여 k-NN 검색을 지원하고, summary 필드는 한국어와 다국어를 별도 sub-field로 분리하여 각각 Nori와 Standard analyzer로 색인합니다.
PUT resumes-v01
{
"settings": {
"index": {
"knn": true,
"knn.algo_param.ef_search": 512,
"default_pipeline": "resume-embedding-pipeline"
},
"analysis": {
"analyzer": {
"korean_analyzer": {
"type": "custom",
"tokenizer": "nori_mixed",
"filter": ["nori_readingform", "lowercase"]
},
"multilingual_analyzer": {
"type": "custom",
"tokenizer": "standard",
"filter": ["lowercase", "asciifolding"]
}
},
"tokenizer": {
"nori_mixed": {
"type": "nori_tokenizer",
"decompound_mode": "mixed"
}
}
}
},
"mappings": {
"properties": {
"embedding": {
"type": "knn_vector",
"dimension": 1024,
"method": {
"name": "hnsw",
"space_type": "l2",
"engine": "faiss",
"parameters": { "ef_construction": 512, "m": 16 }
}
},
"summary": {
"type": "text",
"analyzer": "multilingual_analyzer",
"fields": {
"korean": { "type": "text", "analyzer": "korean_analyzer" }
}
},
"language_pairs": { "type": "keyword" },
"content_types": { "type": "keyword" },
"project_types": { "type": "keyword" },
"tools": { "type": "keyword" },
"specialized_areas": { "type": "keyword" },
"experience_level": { "type": "keyword" },
"total_experience_months": { "type": "integer" }
}
}
}
주요 설계 포인트:
- default_pipeline: 인덱스 레벨에 Ingest Pipeline을 기본값으로 지정하여, 이력서 인덱싱 시 자동으로 임베딩이 생성됩니다.
- knn_vector + HNSW + L2: 그래프 기반 근사 최근접 이웃 알고리즘으로 학습 없이 빠른 응답이 가능합니다.
- korean sub-field: 같은 텍스트를 한국어 형태소(Nori) 분석으로도 색인하여 한국어 복합어·조사 처리를 강화했습니다.
- keyword 필드: 메타데이터는 정확 매칭 + 필터링용으로 keyword 타입을 사용
OpenSearch Ingest Pipeline을 통한 임베딩 자동화
앞서 설명한 Ingest Pipeline과 ML Connector를 활용하여, 인덱싱 단계에서 임베딩을 자동 생성하도록 구성했습니다. 구체적인 처리 흐름은 다음과 같습니다.
- Script Processor로 요약 텍스트와 메타데이터 키워드를 결합한 search_text 필드를 생성합니다.
- ML Connector가 search_text를 Bedrock Cohere Embedding 모델에 전달하여 벡터를 생성합니다.
- 생성된 벡터와 함께 문서가 Index에 저장됩니다.
실제로 등록한 파이프라인 형식은 다음과 같습니다.
PUT _ingest/pipeline/resume-embedding-pipeline
{
"description": "Resume embedding pipeline: summary + metadata keywords → Cohere embed-multilingual-v4",
"processors": [
{
"script": {
"lang": "painless",
"description": "Combine summary and metadata keywords into a natural-language search_text",
"source": "StringBuilder sb = new StringBuilder(); if (ctx.summary != null) { sb.append(ctx.summary); } if (ctx.language_pairs != null && ctx.language_pairs.size() > 0) { sb.append('\\nLanguages: ').append(String.join(', ', ctx.language_pairs)).append('.'); } if (ctx.content_types != null && ctx.content_types.size() > 0) { sb.append('\\nContent: ').append(String.join(', ', ctx.content_types)).append('.'); } if (ctx.project_types != null && ctx.project_types.size() > 0) { sb.append('\\nProjects: ').append(String.join(', ', ctx.project_types)).append('.'); } if (ctx.tools != null && ctx.tools.size() > 0) { sb.append('\\nTools: ').append(String.join(', ', ctx.tools)).append('.'); } if (ctx.specialized_areas != null && ctx.specialized_areas.size() > 0) { sb.append('\\nSpecialties: ').append(String.join(', ', ctx.specialized_areas)).append('.'); } ctx.search_text = sb.toString();"
}
},
{
"text_embedding": {
"model_id": "<ml-connector-model-id>",
"field_map": {
"search_text": "embedding"
}
}
}
Script Processor가 메타데이터(language_pairs, content_types, tools 등)를 자연어 형태의 키워드 문장으로 평탄화하고, text_embedding Processor가 ML Connector를 통해 Bedrock Cohere 모델을 호출하여 벡터를 자동 생성합니다. 인덱스에 default_pipeline을 지정해 두었으므로, 이력서 인덱싱 API 호출 시 별도 코드 없이 임베딩이 자동으로 생성되어 함께 저장됩니다.
이와 별개로, Bedrock Cross-Region Inference Profile을 활용하여 모델 가용성도 확보했습니다.
4. 마무리 — Part 2: 하이브리드 검색과 자연어 쿼리 변환
Part 1에서는 검색 정확도의 기반이 되는 데이터 파이프라인을 다루었습니다. 이력서 원문을 구조화하고, 정규화하고, 환각을 검증하고, 최적의 임베딩 입력 전략을 선택하는 과정이 검색 품질을 결정하는 가장 중요한 요소였습니다.
Part 2에서는 이렇게 준비된 데이터를 기반으로 하이브리드 검색 가중치 최적화, 자연어 → DSL 변환(Function Calling + RAG), 그리고 최종 비즈니스 성과를 다룹니다.