AWS 기술 블로그
Amazon Bedrock과 Claude Agent SDK로 서버리스 멀티 에이전트 구현하기
Kiro CLI나 Claude Code 같은 AI 코딩 에이전트를 사용하다 보면, 코드를 분석하고 수정하고 테스트까지 실행하는 이 에이전트의 동작 방식을 자신의 애플리케이션 백엔드에도 적용할 수 있으면 좋겠다고 생각해 본 적이 있을 것입니다.
하나의 에이전트에게 코드 리뷰, 테스트 작성, 리팩터링을 모두 맡기면 컨텍스트가 길어지면서 앞서 발견한 문제를 뒤에서 잊어버리게 되고, 자신이 작성한 코드를 직접 리뷰하기 때문에 객관성이 떨어집니다. Anthropic의 멀티 에이전트 연구에 따르면, Claude Opus를 리드 에이전트로 두고 Claude Sonnet 서브 에이전트를 병렬 실행한 멀티 에이전트 시스템이 단일 Opus 대비 90.2% 더 높은 성능을 보였습니다.
이 게시글에서는 Claude Agent SDK를 AWS Lambda에서 실행하여 Orchestrator-Worker 패턴의 멀티 에이전트 시스템을 구현하는 방법을 소개합니다. Amazon Bedrock 네이티브 인증을 사용하므로 별도의 API 키 관리가 필요 없습니다.
솔루션 개요
이 게시글에서 구현하는 아키텍처는 Orchestrator-Worker 패턴입니다. Orchestrator Lambda가 작업을 분할하고, 전문화된 Worker Lambda (reviewer, tester, refactorer)가 각각 독립적으로 에이전트를 실행한 뒤, Opus 모델로 결과를 취합하여 정리하는 구조입니다.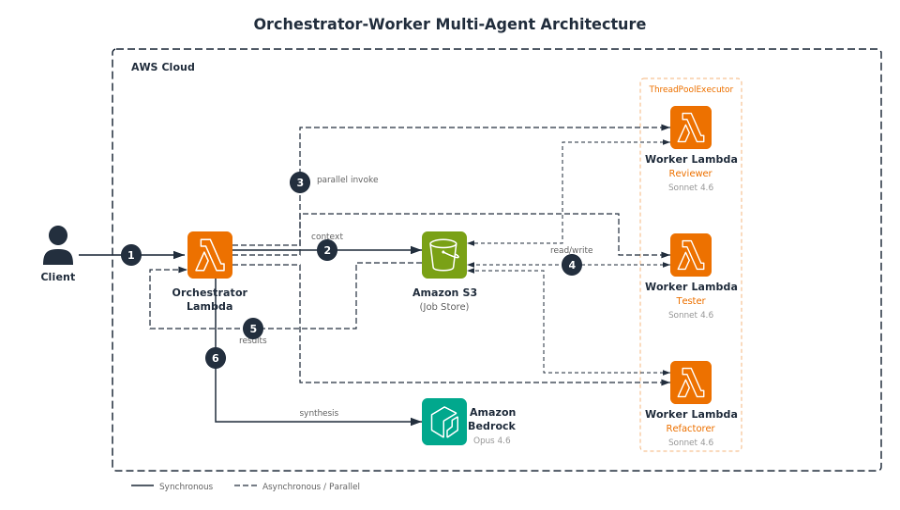
[그림 1] Orchestrator-Worker 멀티 에이전트 아키텍처
왜 Amazon Bedrock인가: Claude Agent SDK는 Anthropic API를 직접 호출하는 방식도 지원하지만, AWS 환경에서는 Amazon Bedrock을 통해 모델을 호출하는 것이 운영 측면에서 이점이 있습니다. Bedrock은 IAM 기반의 네이티브 인증을 제공하므로 API 키를 발급하거나 교체할 필요가 없고, Lambda 실행 역할에 권한을 부여하는 것만으로 인증이 완료됩니다. 교차 리전 추론(cross-region inference)을 통해 가용성도 높아지며, CloudWatch와의 통합으로 토큰 사용량과 지연 시간 모니터링이 기본 제공됩니다.
왜 AWS Lambda인가: 각 Worker Lambda는 독립된 실행 환경을 가지므로, 3개의 에이전트를 동시에 실행해도 각각 15분의 타임아웃을 확보할 수 있습니다. 에이전트 실행이 없을 때는 비용이 발생하지 않으며, 동시 요청이 늘어나면 자동으로 스케일링됩니다. 컨테이너 이미지 배포를 지원하므로 Claude Agent SDK와 CLI 바이너리를 Docker 이미지 하나로 패키징하여 배포할 수 있습니다.
Worker 에이전트에는 Sonnet 4.6을, 최종 종합에는 Opus 4.6을 사용합니다. Sonnet 4.6은 Opus 4.6 대비 토큰당 비용이 약 40% 저렴합니다. 코드 리뷰나 테스트 작성 작업은 Sonnet으로 충분한 품질을 얻을 수 있고, 여러 에이전트의 결과에서 상충되는 의견을 판단하고 우선순위를 정하는 종합 작업에만 Opus를 사용합니다.
단계 요약
이 게시글에서는 다음 단계를 통해 멀티 에이전트 시스템을 구현합니다.
- Claude Agent SDK 소개: SDK의 핵심 API와 Bedrock 인증 설정을 소개합니다.
- 에이전트 정의: Skill 기반의 전문화된 에이전트(reviewer, tester, refactorer)를 정의합니다.
- Worker 구현: 각 Worker Lambda에서 Claude Agent SDK로 에이전트를 실행하는 핵심 로직을 구현합니다.
- Orchestrator 구현: Worker를 병렬로 호출하고 결과를 Opus로 종합하는 Orchestrator를 구현합니다.
- 배포 및 실행: Docker 이미지 빌드, Lambda 배포, 테스트 실행까지 수행합니다.
사전 준비사항
이 게시글의 구현을 따라하려면 다음이 필요합니다.
- AWS 계정, Amazon Bedrock에서 Claude Opus 4.6 및 Sonnet 4.6 모델 접근 권한 활성화
- AWS CLI 설치 및 구성 완료
- Docker 설치
- us-west-2 리전 사용 (Bedrock 글로벌 추론 프로필)
단계 1: Claude Agent SDK 소개
Claude Agent SDK는 Claude의 에이전트 기능을 프로그래밍 방식으로 호출할 수 있는 Python SDK입니다. MIT 라이선스로 공개되어 있으며, pip으로 설치하면 Claude CLI 바이너리가 함께 번들됩니다.
핵심 API는 query()함수와 ClaudeAgentOptions 설정 객체입니다.
from claude_agent_sdk import query, ClaudeAgentOptions
options = ClaudeAgentOptions(
model="global.anthropic.claude-sonnet-4-6",
max_turns=10,
allowed_tools=["Read", "Write", "Bash"],
permission_mode="bypassPermissions",
cwd="/tmp/workspace",
)
async for message in query(prompt="Fix the failing test", options=options):
# AssistantMessage, ToolUseMessage, ResultMessage 등이 순차로 스트리밍
print(message) query()는 async generator로, 에이전트의 사고 과정과 도구 호출, 최종 결과가 메시지 단위로 스트리밍됩니다. max_turns로 에이전트의 반복 횟수를 제한하고, allowed_tools로 사용 가능한 도구를 지정합니다. system_prompt를 넣으면 에이전트의 역할을 정의할 수 있습니다.
SDK를 통해 에이전트는 파일 읽기/쓰기(Read, Write, Edit), 명령어 실행(Bash), 코드 검색(Grep, Glob) 같은 빌트인 도구를 사용할 수 있습니다. 별도의 도구 통합 없이도 에이전트가 코드베이스를 탐색하고 수정하고 테스트를 실행하는 개발 루프를 수행할 수 있습니다. 여기에 더해 system_prompt에 Skill을 정의하면 에이전트에게 도메인별 전문성을 부여할 수 있습니다. 예를 들어 보안 리뷰 체크리스트나 코딩 컨벤션 규칙을 Skill로 작성하여 에이전트가 일관된 기준으로 작업하도록 설정할 수 있습니다.
Amazon Bedrock을 통해 모델을 호출하려면 환경변수 하나만 설정하면 됩니다.
export CLAUDE_CODE_USE_BEDROCK=1
이 환경변수를 설정하면 SDK가 AWS 자격 증명 체인(IAM 역할, 환경변수 등)을 자동으로 사용합니다. Lambda에서 실행할 때는 Lambda 실행 역할에 Bedrock 호출 권한만 부여하면 되며, API 키를 별도로 관리할 필요가 없습니다.
단계 2: 에이전트 정의
Worker 에이전트의 역할을 정의합니다. 각 에이전트는 고유한 시스템 프롬프트와 모델 설정을 가집니다. 시스템 프롬프트에 Skill을 포함하면 에이전트가 도메인별 규칙과 체크리스트에 따라 일관되게 작업합니다.
# shared/config.py
MODELS = {
"opus": "global.anthropic.claude-opus-4-6-v1",
"sonnet": "global.anthropic.claude-sonnet-4-6",
}
# Skill: 보안 중심 코드 리뷰 체크리스트
REVIEWER_SKILL = """You are a senior code reviewer focused on security and reliability.
## Review checklist
- SQL injection: Check all database queries use parameterized inputs
- Input validation: Verify user inputs are validated and sanitized
- Error handling: Ensure exceptions are caught with meaningful messages
- Secrets: Flag any hardcoded credentials, API keys, or connection strings
- Resource cleanup: Check that opened resources (files, connections) are properly closed
## Output format
For each finding:
1. Severity (CRITICAL / HIGH / MEDIUM / LOW)
2. File and line reference
3. Description of the issue
4. Recommended fix with code example
"""
# Skill: 엣지 케이스 중심 테스트 작성
TESTER_SKILL = """You are a QA engineer who writes thorough unit tests.
## Test strategy
- Happy path: Verify expected behavior with valid inputs
- Edge cases: Empty inputs, boundary values, None/null handling
- Error paths: Invalid inputs, exceptions, timeout scenarios
- Concurrency: Thread safety if applicable
## Conventions
- Use pytest with descriptive test names (test_should_raise_when_dividing_by_zero)
- Each test function should verify one behavior
- Include docstrings explaining what each test validates
"""
BUILTIN_AGENTS = {
"reviewer": {
"description": "Security-focused code reviewer",
"prompt": REVIEWER_SKILL,
"model": "sonnet",
},
"tester": {
"description": "Test writer with edge case focus",
"prompt": TESTER_SKILL,
"model": "sonnet",
},
"refactorer": {
"description": "Code refactorer - improves structure without changing behavior",
"prompt": (
"You are a refactoring specialist. Improve code readability, reduce "
"duplication, and simplify logic while keeping all tests passing."
),
"model": "sonnet",
},
}
REVIEWER_SKILL과 TESTER_SKILL처럼 시스템 프롬프트에 체크리스트, 출력 형식, 작업 전략을 명시하면 에이전트의 작업 품질이 일관됩니다. 이러한 Skill은 팀의 코딩 컨벤션이나 보안 정책에 맞게 수정하여 사용할 수 있습니다. BUILTIN_AGENTS에서 원하는 에이전트만 선택하거나, 커스텀 에이전트를 직접 정의할 수도 있습니다.
위 예시에서는 Skill을 Python 코드 안에 직접 정의했지만, Claude Code에서 사용하는 방식처럼 마크다운 파일로 분리하여 관리할 수도 있습니다. 예를 들어 .claude/skills/reviewer.md 파일에 리뷰 기준을 작성하고, 에이전트 초기화 시 해당 파일을 읽어서 system_prompt로 전달하는 방식입니다.
# Skill을 마크다운 파일로 관리
# skills/reviewer.md, skills/tester.md 등을 Docker 이미지에 포함
import os
SKILLS_DIR = os.path.join(os.environ.get("LAMBDA_TASK_ROOT", "."), "skills")
def load_skill(skill_name):
skill_path = os.path.join(SKILLS_DIR, f"{skill_name}.md")
with open(skill_path) as f:
return f.read()
BUILTIN_AGENTS = {
"reviewer": {
"description": "Security-focused code reviewer",
"prompt": load_skill("reviewer"),
"model": "sonnet",
},
# ...
} Dockerfile에서 COPY skills/ ${LAMBDA_TASK_ROOT}/skills/로 Skill 파일을 이미지에 포함하면 Lambda 환경에서도 정상 동작합니다. 파일로 분리하면 Skill을 팀 내에서 공유하거나 버전 관리하기에 편리합니다. Skill을 재배포 없이 더 유연하게 관리하려면, S3 버킷에 Skill 파일을 업로드하고 Lambda 실행 시 동적으로 로드하는 방법도 고려할 수 있습니다.
단계 3: Worker 구현
Worker Lambda는 하나의 에이전트 작업을 실행합니다. S3에서 컨텍스트를 읽고, 지정된 역할의 시스템 프롬프트로 Claude Agent SDK를 실행한 뒤, 결과를 S3에 저장합니다.
# worker.py (핵심부 발췌)
async def _run_worker_agent(
user_prompt, system_prompt, model_id, cwd, max_turns, timeout,
agent_name, lambda_context=None,
):
from claude_agent_sdk import query, ClaudeAgentOptions
start = time.time()
options = ClaudeAgentOptions(
permission_mode="bypassPermissions",
model=model_id,
cwd=cwd,
max_turns=max_turns,
system_prompt=system_prompt,
allowed_tools=["Read", "Write", "Edit", "Bash", "Grep", "Glob"],
)
assistant_texts = []
async for msg in query(prompt=user_prompt, options=options):
# Lambda 타임아웃 10초 전 안전 종료
if lambda_context:
remaining_ms = lambda_context.get_remaining_time_in_millis()
if remaining_ms < 10_000:
break
# 설정된 타임아웃 초과 시 종료
if time.time() - start > timeout:
break
msg_type = type(msg).__name__
if msg_type == "AssistantMessage" and hasattr(msg, "content"):
for block in msg.content:
if hasattr(block, "text") and block.text:
assistant_texts.append(block.text)
return {"success": True, "assistant_text": "\n".join(assistant_texts)}
위 코드에서 주의할 점이 두 가지 있습니다.
첫째, permission_mode=”bypassPermissions“ 설정입니다. Lambda 환경에서는 사용자의 대화형 승인을 받을 수 없으므로 도구 실행 권한을 자동 승인합니다. 따라서 프로덕션 환경에서는 allowed_tools를 필요한 최소 범위로 제한하여 에이전트가 의도치 않은 작업을 수행하지 못하도록 해야 합니다.
둘째, 타임아웃 처리입니다. Lambda의 최대 실행 시간은 15분(900초)이며, 에이전트가 복잡한 작업을 수행하다 보면 이 시간에 근접할 수 있습니다. lambda_context.get_remaining_time_in_millis()로 남은 시간을 확인하고 10초의 여유를 두고 종료함으로써, 에이전트가 중간 결과라도 안전하게 반환할 수 있도록 합니다.
Orchestrator와 Worker 사이의 데이터 전달은 Amazon S3를 통해 이루어집니다.
# shared/s3_store.py
class JobStore:
def __init__(self, bucket=None):
self._bucket = bucket or os.environ.get("S3_BUCKET")
self._s3 = boto3.client("s3")
def write_context(self, job_id, context):
"""Orchestrator가 작업 컨텍스트를 저장"""
key = f"jobs/{job_id}/context.json"
self._s3.put_object(
Bucket=self._bucket, Key=key,
Body=json.dumps(context, ensure_ascii=False),
ContentType="application/json",
)
def read_context(self, job_id):
"""Worker가 작업 컨텍스트를 읽음"""
key = f"jobs/{job_id}/context.json"
resp = self._s3.get_object(Bucket=self._bucket, Key=key)
return json.loads(resp["Body"].read().decode("utf-8"))
def write_result(self, job_id, agent_name, result):
"""Worker가 실행 결과를 저장"""
key = f"jobs/{job_id}/results/{agent_name}.json"
self._s3.put_object(
Bucket=self._bucket, Key=key,
Body=json.dumps(result, ensure_ascii=False),
ContentType="application/json",
) S3를 중간 저장소로 사용하는 이유는 두 가지입니다. 첫째, 동일한 작업 컨텍스트를 여러 Worker에 반복 전달하는 대신 S3에 한 번 저장하고 공유하는 것이 효율적입니다. 둘째, Worker의 전체 실행 결과는 Lambda 응답의 6MB 제한을 초과할 수 있으므로, 전체 결과는 S3에 보존하고 Lambda 응답에는 요약만 담습니다. 작업 데이터는 S3 수명 주기 정책으로 7일 후 자동 삭제되도록 설정합니다.
단계 4: Orchestrator 구현
Orchestrator는 두 가지 일을 합니다. Worker를 병렬로 호출하고, 결과를 Opus로 취합하여 정리합니다. 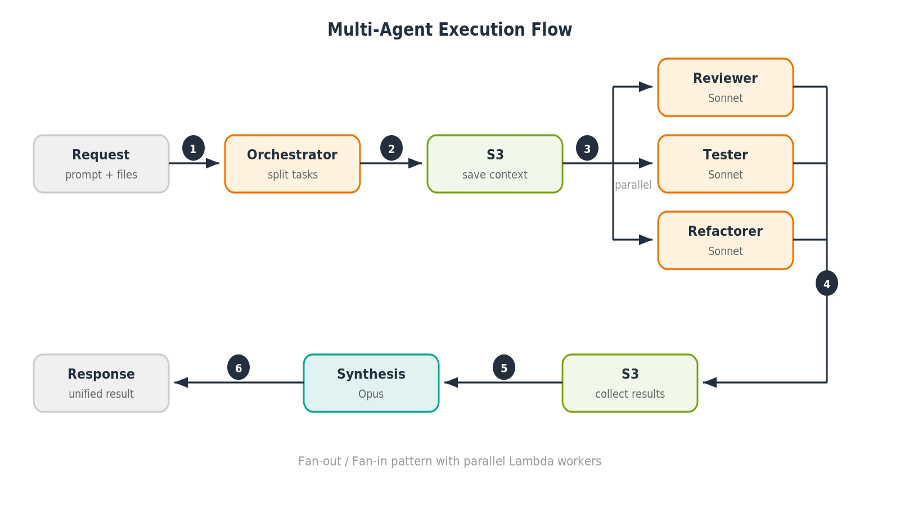
[그림 2] 멀티 에이전트 실행 흐름 (Fan-out / Fan-in 패턴)
Worker 병렬 호출에는 ThreadPoolExecutor를 사용합니다.
# orchestrator.py (병렬 호출부 발췌)
def _invoke_workers_parallel(job_id, agent_configs, worker_max_turns, worker_timeout):
worker_function = os.environ.get("WORKER_FUNCTION_NAME", "agent-worker")
lambda_client = boto3.client("lambda", region_name="us-west-2")
def invoke_one(agent_name, agent_config):
payload = {
"job_id": job_id,
"agent_name": agent_name,
"agent_config": agent_config,
"max_turns": worker_max_turns,
"timeout": worker_timeout,
}
resp = lambda_client.invoke(
FunctionName=worker_function,
InvocationType="RequestResponse",
Payload=json.dumps(payload),
)
return agent_name, json.loads(resp["Payload"].read().decode("utf-8"))
results = {}
with ThreadPoolExecutor(max_workers=len(agent_configs)) as executor:
futures = {
executor.submit(invoke_one, name, cfg): name
for name, cfg in agent_configs.items()
}
for future in as_completed(futures):
name, result = future.result()
results[name] = result
return results InvocationType=”RequestResponse”로 동기 호출을 수행합니다. AWS Step Functions를 사용하면 더 복잡한 워크플로우를 구성할 수 있지만, 이 정도 규모에서는 ThreadPoolExecutor로 충분합니다. 각 Worker Lambda는 독립된 실행 환경에서 별도의 15분 타임아웃을 갖습니다.
모든 Worker가 끝나면 결과를 Opus로 취합하여 정리합니다.
# orchestrator.py (종합부 발췌)
async def _synthesize(prompt, agent_results, model_id):
from claude_agent_sdk import query, ClaudeAgentOptions
results_summary = []
for name, result in agent_results.items():
status = "SUCCESS" if result.get("success") else "FAILED"
text = result.get("assistant_text", "N/A")
results_summary.append(f"--- {name.upper()} ({status}) ---\n{text}")
synthesis_prompt = (
f"You are a technical lead synthesizing results from multiple specialist agents.\n\n"
f"Original task: {prompt}\n\n"
f"Agent results:\n\n" + "\n\n".join(results_summary) + "\n\n"
f"Provide a unified synthesis:\n"
f"1. Key findings from each agent\n"
f"2. Conflicts or disagreements between agents\n"
f"3. Prioritized action items\n"
f"4. Overall assessment"
)
options = ClaudeAgentOptions(
permission_mode="bypassPermissions",
model=model_id,
max_turns=5,
)
texts = []
async for msg in query(prompt=synthesis_prompt, options=options):
msg_type = type(msg).__name__
if msg_type == "AssistantMessage" and hasattr(msg, "content"):
for block in msg.content:
if hasattr(block, "text") and block.text:
texts.append(block.text)
return {"text": "\n".join(texts)} 종합 프롬프트에서 Opus에게 요청하는 것은 네 가지입니다. 각 에이전트의 주요 발견사항, 에이전트 간 의견 충돌, 우선순위별 조치 항목, 전체 평가입니다. 이렇게 하면 reviewer가 지적한 보안 취약점과 tester가 작성한 테스트, refactorer가 제안한 구조 개선이 하나의 맥락으로 정리됩니다.
단계 5: 배포 및 실행
Orchestrator와 Worker는 하나의 Docker 이미지를 공유합니다. Lambda 생성 시 –image-config Command= 옵션으로 handler만 다르게 지정합니다.
FROM public.ecr.aws/lambda/python:3.12
COPY requirements.txt ${LAMBDA_TASK_ROOT}/
RUN pip install --no-cache-dir -r ${LAMBDA_TASK_ROOT}/requirements.txt
COPY shared/ ${LAMBDA_TASK_ROOT}/shared/
COPY handler.py orchestrator.py worker.py ${LAMBDA_TASK_ROOT}/
ENV CLAUDE_CODE_USE_BEDROCK=1
ENV HOME=/tmp
CMD ["handler.handler"] claude-agent-sdk 패키지를 pip으로 설치하면 Claude CLI 바이너리가 함께 번들되므로 Node.js를 별도로 설치할 필요가 없습니다. Bedrock 인증은 환경변수 CLAUDE_CODE_USE_BEDROCK=1 설정으로 활성화됩니다.
배포는 하나의 이미지를 빌드한 뒤 두 Lambda에 각각 다른 CMD로 배포합니다.
# Orchestrator Lambda 배포
aws lambda create-function \
--function-name agent-orchestrator \
--package-type Image \
--code "ImageUri=${ECR_REPO}:latest" \
--role "${ROLE_ARN}" \
--memory-size 10240 \
--timeout 900 \
--image-config "Command=orchestrator.handler" \
--environment "Variables={WORKER_FUNCTION_NAME=agent-worker,S3_BUCKET=${S3_BUCKET},CLAUDE_CODE_USE_BEDROCK=1}"
# Worker Lambda 배포
aws lambda create-function \
--function-name agent-worker \
--package-type Image \
--code "ImageUri=${ECR_REPO}:latest" \
--role "${ROLE_ARN}" \
--memory-size 10240 \
--timeout 900 \
--image-config "Command=worker.handler" \
--environment "Variables={ S3_BUCKET=${S3_BUCKET},CLAUDE_CODE_USE_BEDROCK=1}" 메모리는 10GB로 설정합니다. Claude Agent SDK가 내부적으로 CLI 프로세스를 실행하므로 충분한 메모리가 필요합니다. 타임아웃은 Lambda 최대값인 900초(15분)로 설정합니다.
배포가 완료되면 Orchestrator Lambda를 호출해서 테스트할 수 있습니다.
aws lambda invoke \
--function-name agent-orchestrator \
--cli-binary-format raw-in-base64-out \
--payload '{
"prompt": "Review this code and write tests for it",
"agents": ["reviewer", "tester"],
"files": {
"calculator.py": "def divide(a, b):\n return a / b\n"
}
}' \
--region us-west-2 \
response.json이 호출은 reviewer와 tester 두 Worker를 병렬로 실행합니다. 응답은 다음과 같은 구조입니다.
{
"success": true,
"job_id": "a1b2c3d4-...",
"model": "opus",
"duration_sec": 45.2,
"total_cost_usd": 0.031,
"agents": {
"reviewer": {
"success": true,
"duration_sec": 30.1,
"num_turns": 8,
"cost_usd": 0.008,
"assistant_text": "..."
},
"tester": {
"success": true,
"duration_sec": 28.5,
"num_turns": 6,
"cost_usd": 0.007,
"assistant_text": "..."
}
},
"synthesis": "...",
"synthesis_cost_usd": 0.016
} reviewer는 ZeroDivisionError 미처리와 타입 검증 부재를 지적하고, tester는 0으로 나누기와 부동소수점 연산을 포함한 엣지 케이스 테스트를 생성합니다. synthesis에서는 이 결과를 종합하여 예외 처리가 최우선, 타입 검증이 그 다음, 테스트 커버리지 확대가 마지막 순서라고 정리합니다.
기본 제공되는 reviewer, tester, refactorer 외에 커스텀 에이전트를 직접 정의할 수도 있습니다. agents 필드에 딕셔너리를 넘기면 커스텀 에이전트로 인식됩니다.
{
"prompt": "Analyze this API endpoint",
"agents": {
"security": {
"description": "Security auditor",
"prompt": "Find security vulnerabilities. Focus on OWASP Top 10.",
"model": "sonnet"
},
"performance": {
"description": "Performance analyzer",
"prompt": "Identify performance bottlenecks and optimization opportunities.",
"model": "sonnet"
}
},
"files": {
"api.py": "..."
}
}
설계 결정 및 고려사항
Lambda 제약 대응
AWS Lambda에서 에이전트를 실행할 때 부딪히는 제약과 이 아키텍처에서의 대응을 정리합니다.
| Lambda 제약 | 값 | 대응 방식 |
| invoke payload | 6MB (동기) | S3에 컨텍스트 공유 저장, 대규모 코드베이스 대비 |
| 응답 크기 | 6MB | S3에 전체 결과 저장, Lambda 응답에는 요약 |
| 실행 시간 | 15분 | Worker별 독립 타임아웃, 남은 시간 체크 후 안전 종료 |
| 동시 실행 | 계정별 제한 | 필요 시 동시성 예약 설정 |
비용
Bedrock의 토큰 기반 과금과 Lambda의 실행 시간 과금이 합산됩니다. Worker에 Sonnet을 사용하고 종합에만 Opus를 사용하면, 전체를 Opus로 실행하는 경우 대비 토큰 비용을 약 40% 절감할 수 있습니다.
보안
에이전트가 Lambda 내에서 코드를 실행하므로 보안에 주의가 필요합니다.
- 도구 제한: allowed_tools를 필요한 최소한으로 설정합니다. 예를 들어 리뷰 전용 에이전트는 [“Read”, “Grep”]만으로 충분합니다.
- IAM 최소 권한: Lambda 실행 역할에 Bedrock 호출, S3 읽기/쓰기, Worker Lambda 호출 권한만 부여합니다.
- 자동 수정 제한: 에이전트가 자동으로 코드를 수정하는 경우 수정 횟수에 상한을 두어야 합니다. max_turns 설정으로 무한 루프를 방지합니다.
- 작업 데이터 수명: S3의 작업 데이터는 7일 후 자동 삭제되도록 수명 주기 정책을 설정합니다.
리소스 정리하기
이 게시글의 아키텍처를 직접 구현하여 AWS 리소스를 생성한 경우, 불필요한 비용이 발생하지 않도록 다음 명령어로 리소스를 정리합니다.
# Lambda 함수 삭제
aws lambda delete-function --function-name agent-orchestrator --region us-west-2
aws lambda delete-function --function-name agent-worker --region us-west-2
# S3 버킷 비우고 삭제
aws s3 rm s3://agent-runner-v2-${ACCOUNT_ID} --recursive
aws s3api delete-bucket --bucket agent-runner-v2-${ACCOUNT_ID} --region us-west-2
# ECR 리포지토리 삭제
aws ecr delete-repository --repository-name agent-runner --force --region us-west-2
# IAM 정리
aws iam delete-role-policy --role-name agent-runner-role --policy-name agent-runner-v2
aws iam detach-role-policy --role-name agent-runner-role \
--policy-arn arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole
aws iam delete-role --role-name agent-runner-role
결론
이 게시글에서는 Amazon Bedrock과 Claude Agent SDK를 활용하여 AWS Lambda기반의 Orchestrator-Worker 패턴의 멀티 에이전트 시스템을 구현하는 방법을 살펴보았습니다. 각 Worker가 독립된 Lambda에서 실행되므로 15분 타임아웃을 Worker별로 개별 확보할 수 있고, Amazon S3를 통한 컨텍스트 전달로 페이로드 제한을 우회할 수 있습니다. Worker에는 Sonnet, 종합에는 Opus를 사용하여 비용과 품질 사이의 균형을 잡았습니다.
소개한 패턴은 코드 리뷰나 테스트 생성 외에도 보안 감사, 문서 생성, 코드 마이그레이션 분석 등 전문화된 에이전트가 병렬로 작업하는 다양한 영역에 적용할 수 있습니다. 에이전트 정의와 도구 권한을 환경에 맞게 조정하여 활용해 보시기 바랍니다.