AWS 기술 블로그
GraphRAG Toolkit으로 지식 그래프 인덱싱하기
기존의 RAG(Retrieval-Augmented Generation) 방식은 주로 ‘벡터 유사성 검색’에 의존합니다. 하지만 이 방식은 단순히 질문과 언어적으로 유사한 정보만 찾기 때문에, 데이터 간의 복잡한 구조적 관계나 숨겨진 맥락을 놓칠 수 있다는 한계가 있습니다.
지식 그래프(Knowledge Graph)는 이러한 한계를 보완합니다. 데이터를 개체(Entity)와 관계(Relation) 중심으로 연결하여, 질문과 직접적인 단어 유사성이 낮더라도 답변에 꼭 필요한 연관 정보를 정확하게 찾아낼 수 있도록 돕습니다.
이 글에서는 GraphRAG Toolkit을 활용해 지식 그래프를 단계별로 인덱싱하는 과정을 살펴봅니다.
이전 포스팅인 Amazon Neptune GraphRAG Toolkit을 활용하여 정교한 비정형 데이터 검색하기를 통해 Amazon Neptune GraphRAG Toolkit에 대한 개략적인 소개가 되어 있으니 한번 살펴보시는 걸 추천드립니다.
목표
비정형 텍스트 문서에서 정보를 추출하여, 그래프 저장소와 벡터 저장소를 결합한 인덱스를 구축하는 방법을 배웁니다.
- 어휘 그래프(Lexical Graph) 모델의 개념 이해
- 인덱싱할 소스 문서 검토
- 데이터 로드 및 정보 추출/저장
- 추출된 데이터의 청크(Chunk) 구성 확인
- 그래프 및 벡터 인덱스 최종 구축
- 그래프 시각화 및 쿼리 실행 테스트
Lexical Graph 모델
GraphRAG Toolkit은 지식 그래프의 한 유형인 ‘어휘 그래프’를 구축합니다. 이 모델은 소스 문서부터 세부 개체에 이르기까지 데이터가 계층적으로 연결된 구조를 가집니다.
왜 문장(Statement) 중심인가?
일반적인 RAG는 텍스트를 일정 길이로 자른 ‘청크(Chunk)’를 기본 단위로 사용합니다. 반면, GraphRAG Toolkit은 독립적인 주장이나 명확한 사실을 담고 있는 문장(Statement) 단위를 핵심 컨텍스트로 삼습니다. 이를 통해 사용자의 질문에 정확히 답할 수 있는 최적의 관련 문장 집합을 효율적으로 찾아내기 위함입니다.
어휘 그래프의 세 가지 계층
어휘 그래프는 세 가지 계층으로 구성됩니다.
제1계층 – 계보(Lineage): 원본 데이터의 출처와 분할된 청크, 그리고 이들 간의 연결 관계를 추적
제2계층 – 요약(Summarization): 주제별로 조직된 스테이트먼트와 이를 지원하는 사실 정보
제3계층 – 개체-관계(Entity-relationship): 원본 소스에서 식별된 개별 개체와 그들 간의 관계
| 계층 | 구성 요소 | 역할 |
|---|---|---|
| 계보(Lineage) | 소스, 청크 | 원본 문서와의 관계 추적 |
| 요약(Summary) | 주제, 문장, 사실 | 핵심 컨텍스트 단위 제공 |
| 개체-관계(Entity-Relationship) | 개체, 관계 | 도메인 의미 표현 |
노드별 역할
전체 어휘 그래프를 문장들의 바구니(bucket)로 생각할 수 있으며, 어휘 그래프 모델 내 다양한 노드들은 문장을 찾고 조직하는 데에 다음과 같은 특정 역할을 수행합니다.
| 노드 | 역할 |
|---|---|
| 소스(Sources) | 필터링 및 버전 관리를 위한 원본 문서 메타데이터 |
| 청크(Chunks) | 벡터 기반으로 그래프에 접근할 수 있는 진입점 |
| 문장(Statements) | 독립적인 명제, LLM에 전달되는 주요 컨텍스트 단위 |
| 주제(Topics) | 동일한 소스에 속한 문장들을 주제별로 그룹화 |
| 사실(Facts) | 서로 다른 소스에 속한 문장들을 연결 |
| 개체(Entities) | 데이터셋의 도메인 의미(Semantic)를 표현 |
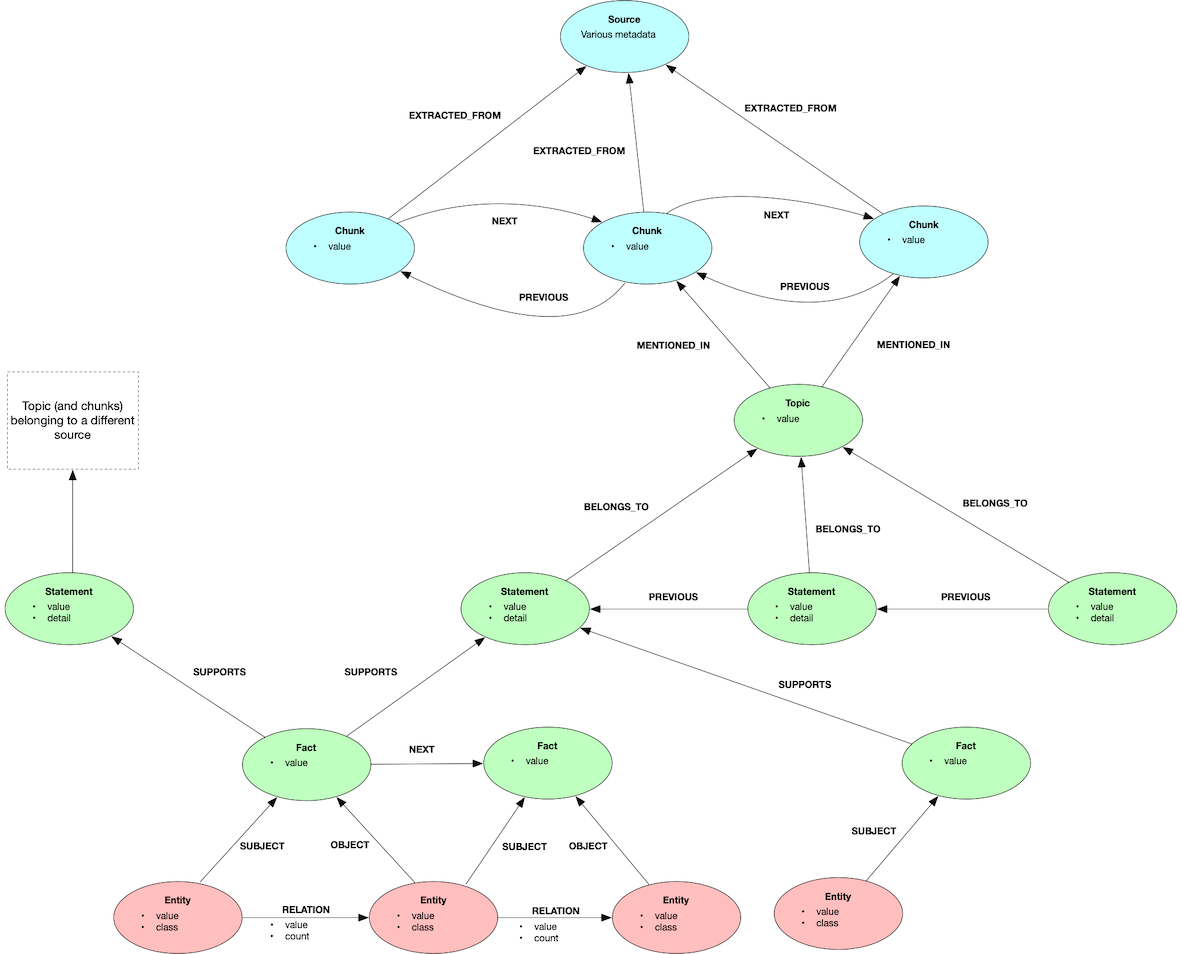
그림 1. 어휘 그래프 모델 (lexical graph model)
RAG 설계를 위한 역방향 접근과 요약 계층의 역할
성공적인 RAG(Retrieval-Augmented Generation) 설계를 위해서는 ‘역방향 접근 방식’을 채택하는 것이 유용합니다. 이는 기술적 구현 이전에 다음 두 가지 핵심 질문에 먼저 답하는 것을 의미합니다.
- 질의응답 요구사항: 워크플로가 최종적으로 충족해야 할 사용자 요구사항은 무엇인가?
- 데이터 검색 전략: 해당 요구사항을 해결하기 위해 어떤 종류의 데이터를 검색해야 하는가?
그래프 모델의 균형: 연결과 정교함
잘 설계된 그래프 모델은 ‘양방향의 균형’을 이룹니다. 이는 관련 없는 정보로 인해 맥락이 희석되는 것을 방지하면서도, 겉으로 드러나지 않지만 맥락적으로 중요한 관계를 찾아낼 수 있음을 의미합니다.
- 과잉 연결의 위험: 모든 정보를 무분별하게 연결하면, 무관한 정보가 섞여 정확한 컨텍스트 추출이 어려워집니다.
- 과소 연결의 위험: 연결이 너무 적으면, 의미적으로 연관된 중요한 정보를 발견할 기회를 놓치게 됩니다.
요약 계층(Summarization Tier)의 책임
요약 계층의 요소들은 검색의 효율성을 높이기 위해 각기 다른 역할을 수행합니다.
- 컨텍스트 단위: 어휘 단위 검색 시, 문장(Statement)은 파운데이션 모델(FM)에 전달되는 주요 컨텍스트 단위로 작동합니다.
- 연결성 구분: 요약 계층은 로컬 연결성과 글로벌 연결성을 명확히 구분하여 균형을 잡습니다.
주제(Topics) vs 사실(Facts)
| 구분 | 역할 |
|---|---|
| 주제 (Topics) | 동일한 소스에서 파생된 문장들 간의 로컬 연결성을 제공합니다. |
| 사실 (Facts) | 서로 다른 소스에서 파생된 문장들 간의 글로벌 연결성을 제공합니다. |
검색 전략과 그래프 탐색 제어
이러한 구분은 검색 전략이 그래프 탐색 방식을 정교하게 제어할 수 있도록 돕습니다.
- 로컬 우선 탐색: 대부분의 탐색을 로컬 범위 내에서 수행하며, 필요 시에만 더 먼 연결 기회를 잠정적으로 탐색합니다.
- 글로벌 우선 탐색: 광범위한 범위에서 탐색을 시작하여, 가장 유망한 주제로 범위를 좁혀 나갑니다.
Lexical Graph 구축을 위한 2단계 인덱싱 프로세스
이제 실제로 어휘 그래프(Lexical Graph)를 어떻게 구축하는지 그 방법을 살펴보겠습니다. 전체 프로세스는 크게 추출(Extract)과 구축(Build)이라는 두 단계의 파이프라인으로 나뉩니다.
1단계: 추출(Extract)
데이터에서 핵심 정보를 뽑아내는 기초 공사 단계입니다. 문서를 로드한 뒤 적절한 크기(Chunk)로 나누고, 대규모 언어 모델(LLM)을 활용해 다음 두 가지 핵심 추출 작업을 수행합니다.
- 명제(Proposition) 추출: 잘게 나뉜 텍스트 청크를 의미가 명확하고 완결된 형태의 독립적인 문장으로 변환합니다.
- 주제·개체·사실 추출: 데이터 간의 관계와 개념을 분석하여 주제(Topic), 개체(Entity), 사실(Fact) 정보를 식별하고 추출합니다.
2단계: 구축(Build)
추출된 정보를 바탕으로 실제 검색이 가능한 형태로 구조화하는 단계입니다.
- 그래프 구성: 1단계에서 얻은 결과물(명제, 개체 등)을 서로 연결하여 입체적인 지식 그래프를 생성합니다.
- 벡터 임베딩 생성: 효율적인 유사도 검색을 위해 데이터를 수치화된 벡터 데이터로 변환하여 저장합니다.
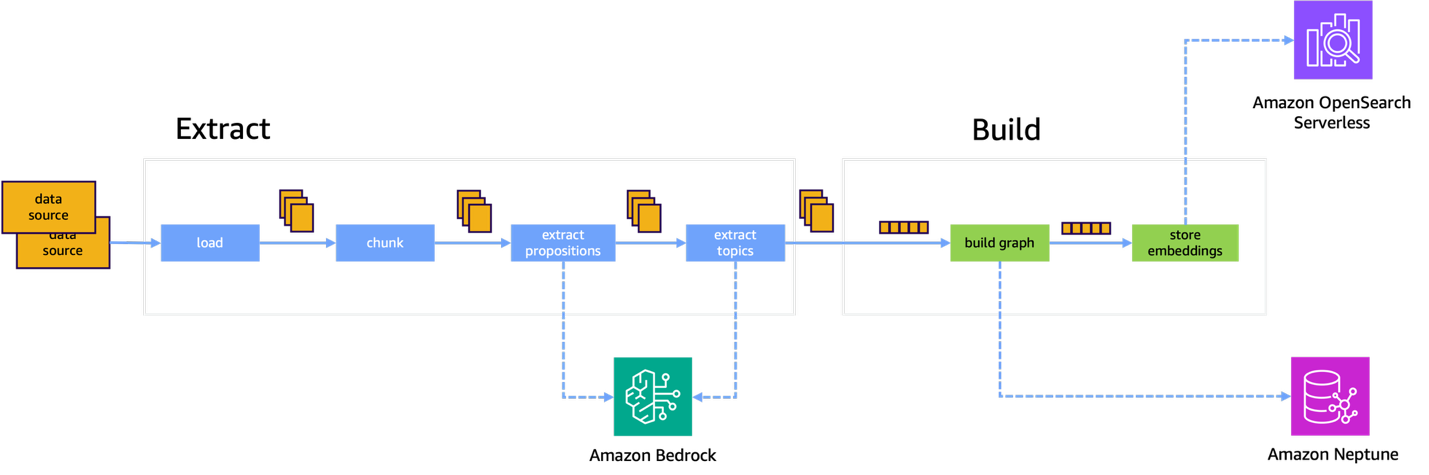
그림 2. 인덱스 프로세스
인덱싱 옵션
GraphRAG Toolkit의 가장 큰 장점 중 하나는 사용자의 환경이나 데이터 규모에 따라 인덱싱 과정을 유연하게 설정할 수 있다는 점입니다.
상황에 따른 세 가지 실행 모드
- 통합 실행 (Extract + Build): 끊김 없는 지속적인 데이터 수집이 필요할 때 두 파이프라인을 한 번에 실행할 수 있습니다.
- 분리 실행: 프로세스를 보다 정밀하게 제어하고 싶다면 추출(Extract)과 구축(Build) 단계를 각각 별도로 실행하여 관리할 수 있습니다.
- 대규모 데이터 처리 (배치 추출): 처리해야 할 데이터 양이 방대하다면, Amazon Bedrock의 배치 추론 기능을 활용하도록 GraphRAG Toolkit을 구성해 보세요. 대량의 데이터를 효율적이고 경제적으로 처리할 수 있습니다.
‘추출(Extract)’ 단계 집중 분석
추출 단계에서는 데이터를 로드하고, 텍스트를 청크한 뒤 명제 추출 및 주제/개체/사실 추출 모두를 수행하여 결과를 디스크에 씁니다.
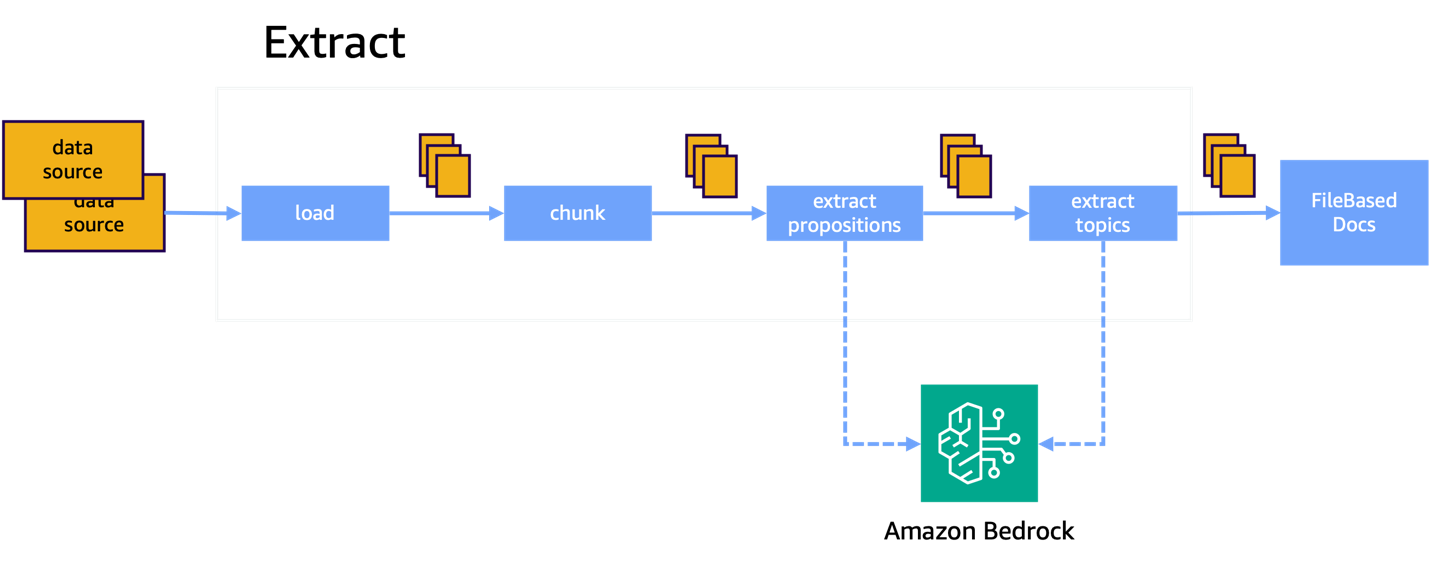
그림 3. 인덱스 프로세스의 Extract 단계
1. 데이터 불러오기 (Loading)
모든 작업의 시작은 외부 소스에서 데이터를 안전하게 가져오는 것입니다.
- 도구: LlamaIndex 리더(Reader)를 사용합니다.
- 장점: LlamaIndex는 수많은 데이터 소스에 대응하는 다양한 리더와 커넥터를 제공하므로, 어떤 형태의 데이터라도 연결할 수 있습니다.
2. 데이터 잘게 나누기 (Chunking)
대용량 텍스트를 한꺼번에 처리하는 것은 비효율적입니다. AI가 소화하기 좋은 크기로 나누는 과정이 필요합니다.
- 도구: MarkdownNodeParser나 SentenceSplitter 같은 LlamaIndex Splitter를 활용합니다.
- 기본 설정: 별도의 전략을 지정하지 않으면 GraphRAG Toolkit은 기본적으로 SentenceSplitter를 사용하여 문장 단위로 나누어 줍니다.
3. 핵심 정보 뽑아내기 (Extraction)
각 청크마다 두 번의 LLM(거대언어모델) 호출을 통해 정교하게 정보를 추출합니다.
- 명제 집합(Propositions) 추출: 잘게 나뉜 텍스트 속에서 의미가 완결된 독립적인 문장(Statement)들을 먼저 뽑아냅니다.
- 주제·개체·사실 추출: 위에서 뽑아낸 문장을 다시 분석하여 핵심 주제(Topic), 중요한 개체(Entity), 그리고 구체적인 사실(Fact) 정보를 추가로 추출합니다.
추출 코드 예시
import os
from graphrag_toolkit.lexical_graph import LexicalGraphIndex, IndexingConfig
from graphrag_toolkit.lexical_graph.storage import GraphStoreFactory, VectorStoreFactory
from graphrag_toolkit.lexical_graph.indexing.load import FileBasedDocs
from llama_index.core.node_parser import MarkdownNodeParser
from llama_index.core import SimpleDirectoryReader
with (
GraphStoreFactory.for_graph_store(os.environ['GRAPH_STORE']) as graph_store,
VectorStoreFactory.for_vector_store(os.environ['VECTOR_STORE']) as vector_store
):
# LexicalGraphIndex 인덱싱 컴포넌트 생성
config = IndexingConfig(
chunking=[MarkdownNodeParser()] # 마크다운 헤딩 기준으로 청킹
)
graph_index = LexicalGraphIndex(
graph_store,
vector_store,
indexing_config=config
)
# 소스 문서 로드
loader = SimpleDirectoryReader(
input_files=["./source-data/neptune/instance-types.md"],
file_metadata=lambda p:{'file_name':os.path.basename(p)}
)
source_docs = loader.load_data()
# 추출된 데이터 저장 위치 지정
extracted_docs = FileBasedDocs(
docs_directory='extracted',
collection_id='example-1'
)
# 데이터 추출
graph_index.extract(
nodes=source_docs,
handler=extracted_docs,
show_progress=True
)추출 결과 확인
추출된 각 청크는 다음과 같은 구조를 가집니다:
{
"metadata": {
"aws::graph::propositions": [
"<propositions>"
],
"aws::graph::topics": {
"topics": [
"<topics/statements/facts>"
]
}
},
"text": "<chunk text>"
}aws::graph::propositions: 명제 추출 결과. 대명사가 고유명사로 대체된 독립적인 문장들aws::graph::topics: 주제별로 그룹화된 문장(Statement)과 사실(Fact)
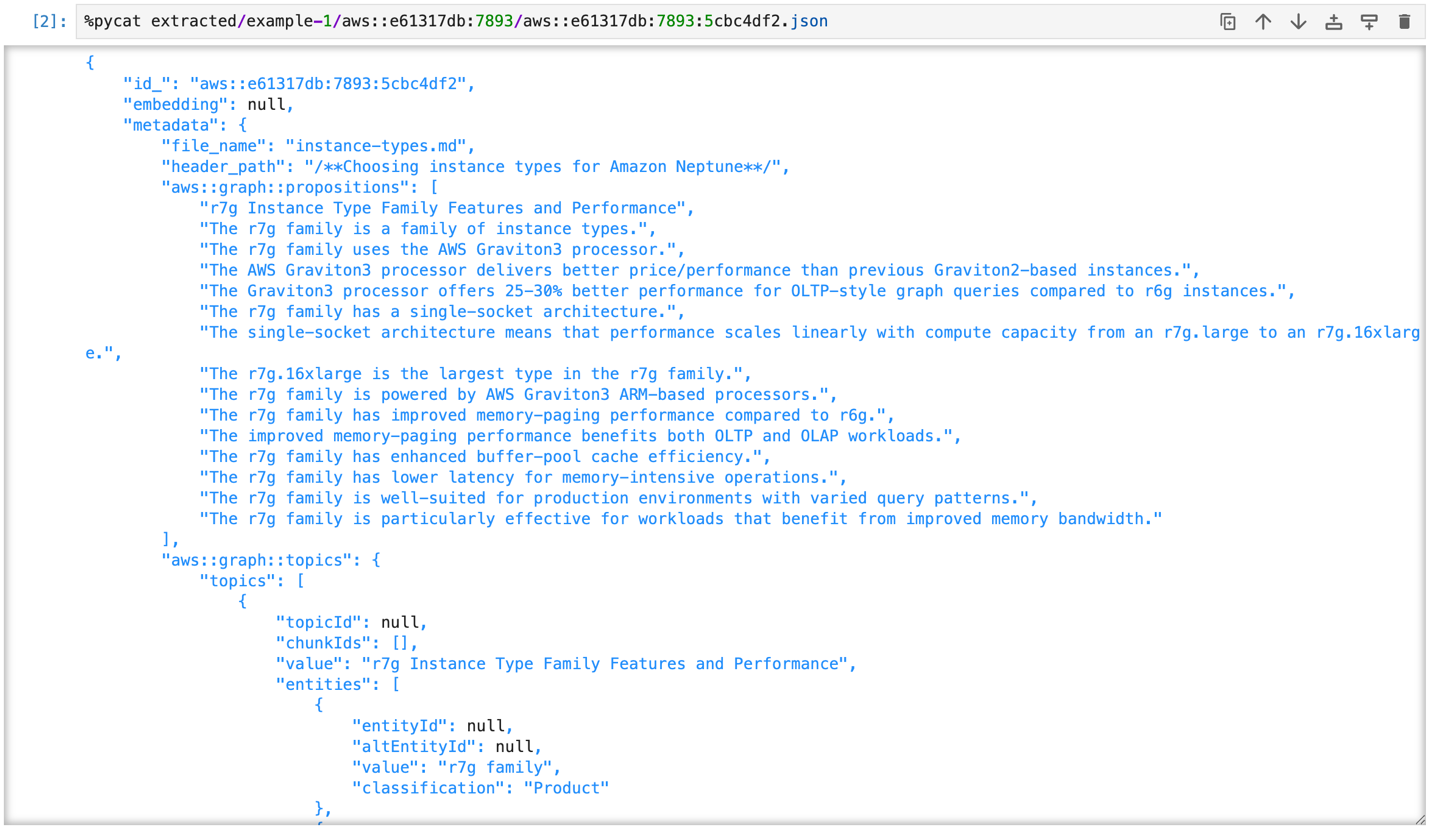
그림 4. 인덱스 프로세스의 Extract 단계에서 추출된 데이터 예시
‘구축(Build)’ 단계 집중 분석
구축 단계에서는 추출된 청크들을 사용하여 그래프와 벡터 임베딩을 생성합니다.
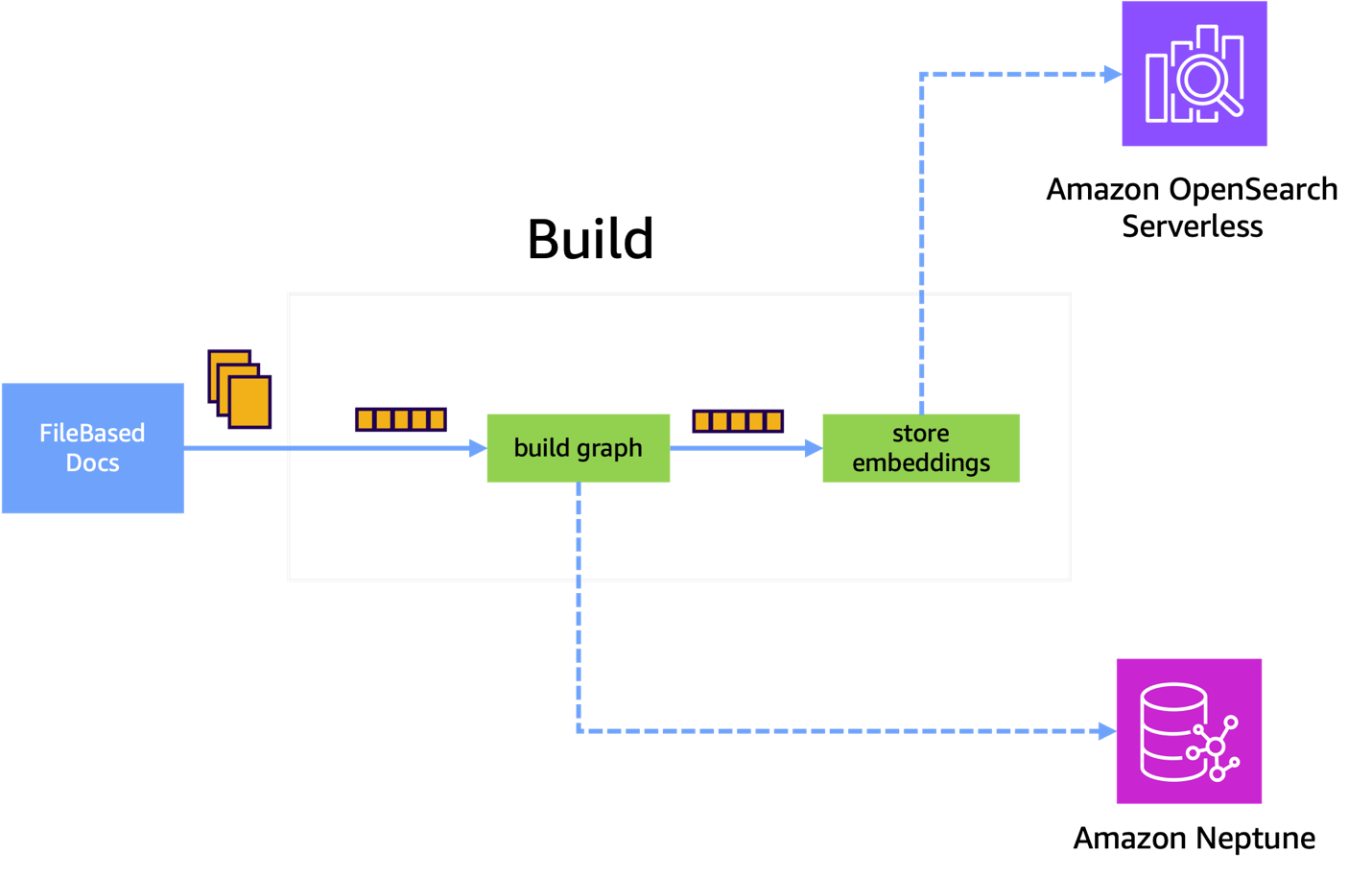
그림 5. 인덱스 프로세스의 구축 단계
구축 코드 예시
import os
from graphrag_toolkit.lexical_graph import LexicalGraphIndex
from graphrag_toolkit.lexical_graph.storage import GraphStoreFactory, VectorStoreFactory
from graphrag_toolkit.lexical_graph.indexing.load import FileBasedDocs
with (
GraphStoreFactory.for_graph_store(os.environ['GRAPH_STORE']) as graph_store,
VectorStoreFactory.for_vector_store(
os.environ['VECTOR_STORE'],
index_names=['chunk'] # 'chunk', 'topic', 'statement' 중 선택
) as vector_store
):
graph_index = LexicalGraphIndex(graph_store, vector_store)
# 이전에 추출된 데이터 소스 지정
extracted_docs = FileBasedDocs(
docs_directory='extracted',
collection_id='example-1'
)
# 그래프 및 벡터 스토어 구축
graph_index.build(
nodes=extracted_docs,
show_progress=True
)시각화 및 쿼리 (그래프 시각화)
구축 단계를 통해 그래프 구조화된 데이터를 시각화합니다.
from graphrag_toolkit.lexical_graph.visualisation import GraphNotebookVisualisation
v = GraphNotebookVisualisation(nb_classic=True)
v.display_sources()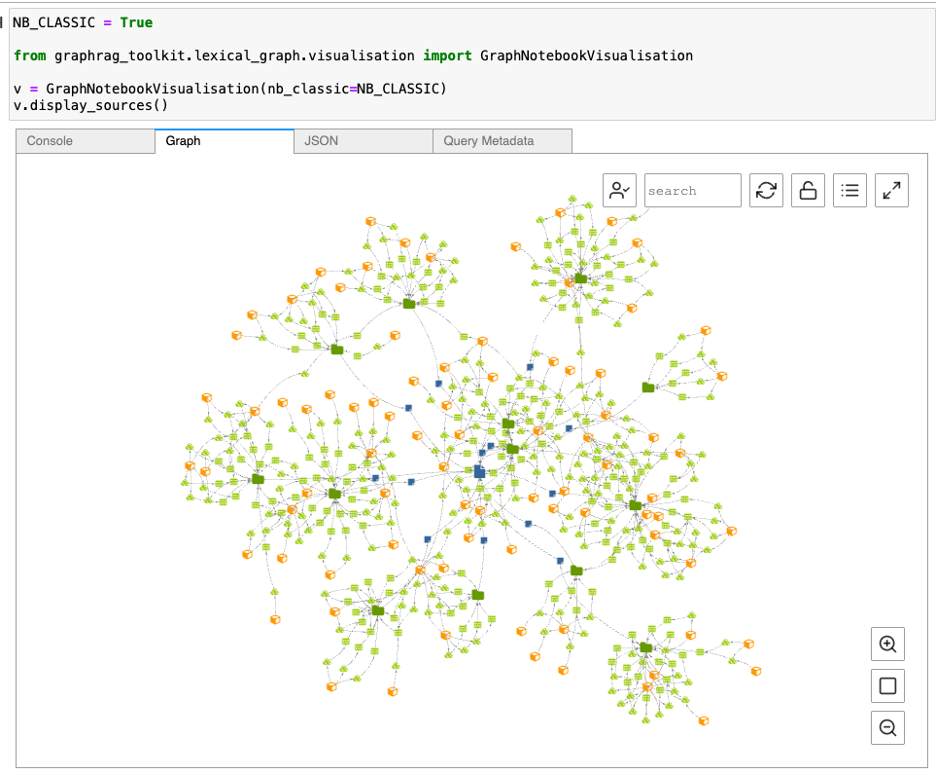
그림 6. 어휘 그래프 시각화 예시
확대/축소 도구를 이용하여 소스(Source), 청크(Chunk), 주제(Topic), 개체(Entity), 사실(Fact), 문장(Statements)를 확인할 수 있습니다.
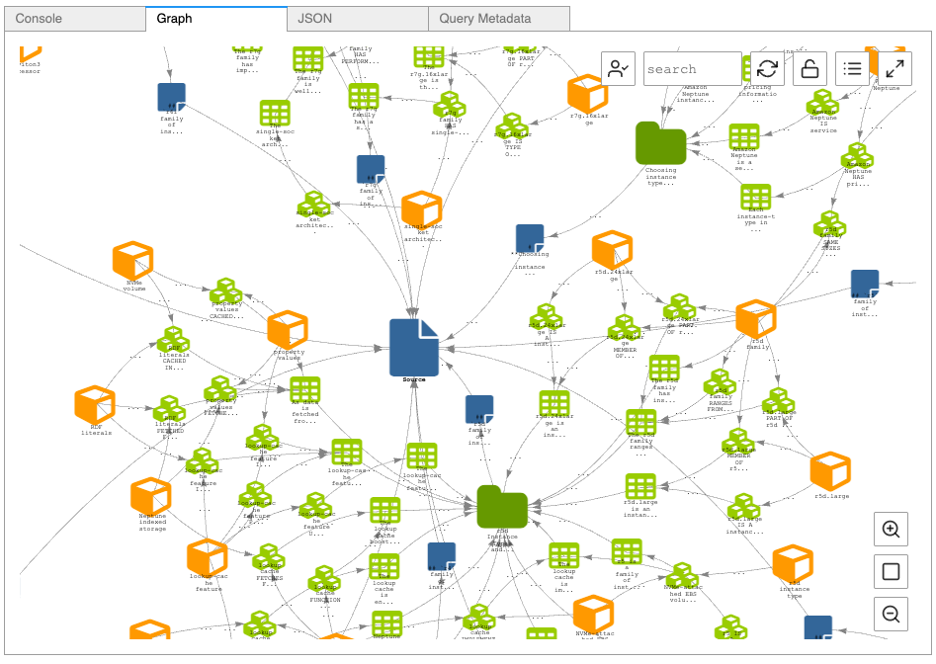
그림 7. 다양한 노드 및 관계를 시각화
추론된 스키마 시각화
데이터를 연결하는 것에서 한 걸음 더 나아가, GraphRAG Toolkit은 데이터가 담고 있는 ‘숨은 맥락’까지 찾아내 시각화합니다. 단순히 단어를 잇는 ‘어휘 그래프’를 넘어, 더 깊은 통찰을 제공하는 ‘추론된 스키마’의 힘을 살펴보겠습니다.
명시적으로 정의되지 않은 스키마 정보를 기반으로 선언되지 않은 관계 기반의 검색을 가능하게 합니다.
v = GraphNotebookVisualisation(nb_classic=True)
v.display_schema()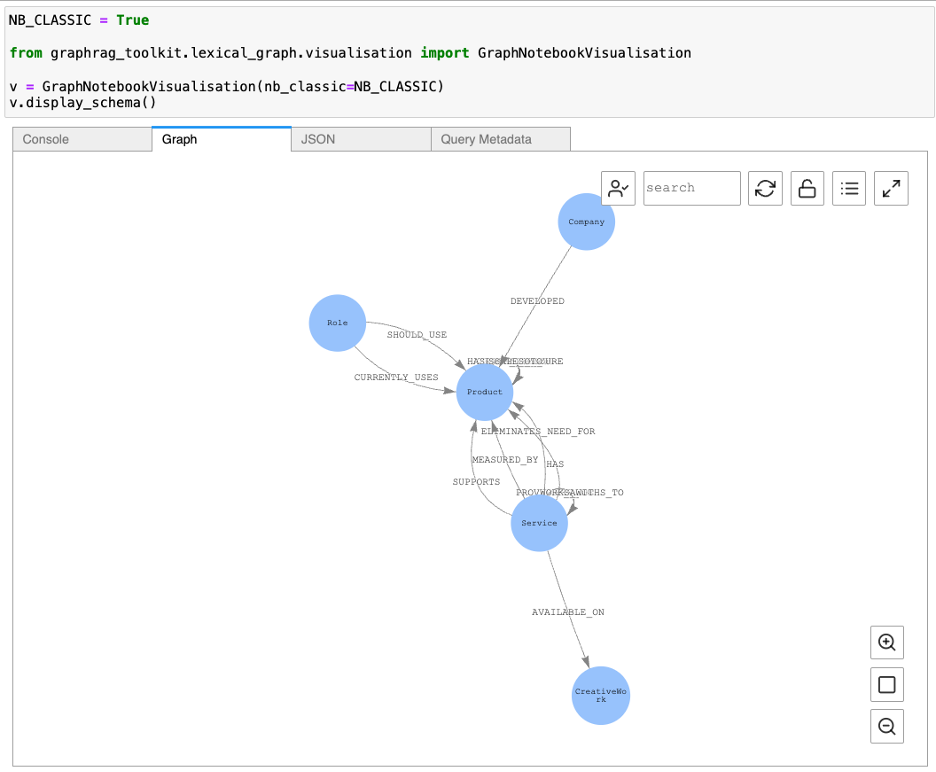
그림 8. 추론된 스키마 그래프 시각화
데이터 쿼리
아래의 쿼리에서 단순히 두 단어(r7i, r8g)가 포함된 문서를 찾는 게 아니라, 두 제품의 사양, 세대 차이, 성능 지표 간의 연결 고리를 그래프에서 추적합니다.
import os
from graphrag_toolkit.lexical_graph import LexicalGraphQueryEngine
from graphrag_toolkit.lexical_graph.storage import GraphStoreFactory, VectorStoreFactory
with (
GraphStoreFactory.for_graph_store(os.environ['GRAPH_STORE']) as graph_store,
VectorStoreFactory.for_vector_store(os.environ['VECTOR_STORE']) as vector_store
):
query_engine = LexicalGraphQueryEngine.for_traversal_based_search(
graph_store,
vector_store,
streaming=True,
no_cache=True
)
response = query_engine.query("r7i 인스턴스 제품군과 r8g 인스턴스 제품군의 차이점은 무엇입니까?")
response.print_response_stream()마치며: GraphRAG로 완성하는 지능형 지식 탐색
지금까지 GraphRAG Toolkit을 활용해 지식의 지도를 그리는 ‘인덱싱 프로세스’를 함께 살펴보았습니다. 텍스트라는 원석을 깎아 정교한 그래프라는 보석으로 만드는 과정을 다시 한번 정리해 보겠습니다.
핵심 요약
- Lexical Graph 모델: 단순한 텍스트 덩어리가 아닌, ‘문장(Statement)’ 중심의 계층적 구조를 통해 지식의 설계 철학을 세웠습니다.
- 추출(Extract) 단계: 문서를 불러오고(Loading), 적절히 나누고(Chunking), LLM을 통해 명제와 주제, 사실들을 정교하게 뽑아내는 기초 공사를 마쳤습니다.
- 구축(Build) 단계: 추출된 정보들을 유기적으로 연결하여 입체적인 그래프를 구성하고, 효율적인 검색을 위한 벡터 임베딩까지 생성했습니다.
실습해보기
GraphRAG Toolkit GitHub Workshop – Indexing에서 직접 인덱싱을 시작해 보세요.
다음 편인 GraphRAG Toolkit으로 지식 그래프 쿼리하기에서는 이렇게 구축된 그래프 위에서 쿼리의 그래프 탐색과 검색 전략에 대해 좀 더 자세하게 살펴보도록 하겠습니다.