AWS 기술 블로그
카카오게임즈의 Amazon Bedrock 기반 실시간 채팅 번역 구축

카카오게임즈는 글로벌 게임 퍼블리셔이자 디벨로퍼로서, 언어와 지역, 환경의 경계를 넘어 전 세계 누구나 함께 즐길 수 있는 게임 경험을 만들어가고 있습니다. 모바일, PC 온라인, 콘솔 등 다양한 플랫폼을 아우르며, 전 세계 이용자들에게 고품질의 콘텐츠를 선보이고 있으며, 게임의 본질에 집중하여 지속 가능한 가치를 창출하는 동시에, 창의적이고 잠재력 높은 게임 IP를 발굴해 글로벌 시장에서 의미 있는 성과를 쌓아가고 있습니다. 오딘: 발할라 라이징(ODIN: VALHALLA RISING)은 방대한 오픈 월드와 대규모 전투, 그리고 북유럽 신화를 바탕으로 한 흥미로운 스토리를 갖춘 MMORPG입니다. 모바일에서도 PC/콘솔 못지않은 뛰어난 그래픽 퀄리티를 체험할 수 있으며 2021년 한국에서 첫 출시된 이후, 대만과 일본에 이어 2025년 4월 29일에는 글로벌 서비스(이하 오딘:글로벌)를 오픈하였습니다.
본 글에서는 카카오게임즈가 글로벌 게임을 위해 Amazon Bedrock을 기반으로 실시간 채팅 번역 시스템을 구축한 방법을 소개합니다. 특히 저지연시간 응답을 하면서도 높은 품질의 번역을 위해 고민한 방법들과 앞으로의 초저지연시간 번역을 위해 고민하고 있는 방법을 소개합니다.
실시간 채팅 번역을 위해 GenAI를 고려하게 된 계기
전 세계 수많은 유저들이 한 공간에 모여 실시간으로 함께 게임을 즐기는 것, MMORPG의 가장 큰 매력입니다. 하지만 언어가 다르면 이 즐거움에 제약이 생깁니다. 글로벌 서비스를 준비하면서 가장 먼저 마주한 고민이 바로 언어 장벽이었습니다.
단순히 “도와주세요”, “파티 구합니다”, “공격하라!” 같은 기본 명령어뿐만 아니라, “거점을 포기하고 뒤로 돌아가 공격해!”, “막피 하지 말고 정정당당히 싸우자”, “망각의 여울에서 떨어지는 아이템 좋아요?” 처럼 상황에 따라 유저들이 주고받는 다양한 게임 특화 표현들도 정확하게 번역되지 않는다면, 소통은 물론 전투의 전략과 결과까지 영향을 줄 수 있습니다.
초기에는 기존의 번역 솔루션들도 검토해봤습니다. 하지만 다음과 같은 문제들이 명확히 드러났습니다.
- 게임 내 고유 용어나 게이머들만의 표현을 제대로 번역하기 어려움
- 자연스러운 표현이 아닌 번역 특유의 어색함
이런 상황에서 카카오게임즈는 생성형 AI(GenAI)를 실시간 채팅 번역을 위해 고려하게 되었습니다.
Generative AI 도입 검토
채팅 번역 시스템을 구축하기로 결정했을 때 카카오게임즈는 단순히 ‘최신 기술을 도입하자’와 같은 접근보다, 먼저 실제 게임 환경에서 안정적이고 실용적으로 쓸 수 있을지를 가장 먼저 고민했습니다. 특히, 글로벌 유저들이 함께 플레이하는 MMORPG 환경에서는 단순한 번역을 넘어, 게임 특유의 표현과 맥락까지 자연스럽게 전달되는 것이 매우 중요합니다. 이를 위해 GenAI 도입을 앞두고 다음과 같은 부분을 중점적으로 검토했습니다.
기존 번역 시스템, 어디까지 가능한가? 정말 실시간 “게임” 채팅 번역에 힘들까?
‘오딘:글로벌’은 대규모 전투와 협동이 핵심인 게임입니다. 그만큼 실시간 채팅을 통해 전략을 공유하거나 소통하는 일이 매우 중요합니다. 하지만 기존의 번역 API로는 게임특화 언어와 맥락 번역에 한계가 있어 게임에 자주 등장하는 “막피”, “딜량”, “거점”, “파밍” 같은 고유 용어나 슬랭을 제대로 번역하기 어려웠습니다. 결국 글로벌 서비스를 진행하고 게임 내 신규 컨텐츠가 많아지더라도 번역 품질을 유지하면서도 효율적으로 관리할 수 있는 구조가 필요했습니다.
기존 번역 솔루션 대비 Gen AI는 정말 실용적인가?
최근 주목받고 있는 생성형 AI(GenAI)가 단순히 기술 트렌드를 넘어, 실제로 ‘오딘:글로벌’에 도움이 될지 직접 확인이 필요했습니다. 프롬프트 엔지니어링(Prompt Engineering)을 통해 게임 고유 용어나 문화, 표현을 반영한 맞춤형 번역을 만들 수 있다는 점이 큰 강점이었습니다.
무엇보다 서비스를 운용하는 기술 PM 입장에서 가장 현실적인 고민은 바로 짧은 도입 기간이었습니다. 실시간 번역 시스템을 빠르게 구축해 실제 게임 빌드에 반영해야 하는 상황에서, GenAI 연동 과정을 얼마나 간단하고 빠르게 끝낼 수 있을지가 핵심 포인트였습니다. 이 부분에서 Amazon Bedrock의 강점이 매우 뚜렷하게 드러났습니다.
AWS Lambda를 이용해 번역 로직을 간단히 API화 할 수 있었고, 이를 Elastic Load Balancing(ELB)나 Amazon API Gateway에 바로 연결해 손쉽게 서비스 형태로 배포할 수 있었습니다. 또한 Amazon Bedrock에 있는 프롬프트 관리(Prompt Management), 프롬프트 최적화(Prompt Optimization) 같은 기능들은 운영의 난이도를 낮춰주었습니다. 정확한 번역을 위해 고려하던 RAG(Retrieval-Augmented Generation) 구축 역시 복잡하지 않았습니다. 게임 고유 단어나 정보를 S3에 업로드하고, 이를 Amazon OpenSearch Service에 벡터화해 저장하는 구조를 Amazon Bedrock Knowledge Bases 같은 서비스로 빠르게 구축하고 테스트해볼 수 있었습니다. 결국, 짧은 기간 내에 안정적인 시스템을 구축해야 하는 상황에 Bedrock의 최대 강점은 ‘간편함’과 ‘편리함’ 이었기에 충분히 실용적이라고 판단했습니다.
안정성, 확장성, 그리고 비용 효율성
MMORPG의 특성상, 수만 명의 사용자가 동시에 접속하더라도 번역 시스템이 안정적으로 운영되어야 합니다. 주요 고려 사항과 고민을 해결해 준 기능들은 다음과 같습니다:
- 안정성 : 교차 리전 추론(Cross-Region Inference)을 통해 안정적으로 모델 호출 관련 쿼타를 유지할 수 있습니다.
- 확장성: 서버리스 구성을 활용하고 Bedrock이 제공하는 여러 모델을 테스트해보며 사용 사례에 맞는 적합한 모델을 고를 수 있습니다. 또한 RAG를 통해 게임 고유 용어 DB를 쉽게 확장할 수 있다고 생각했습니다.
- 비용 효율성: 사용자가 많은 번역 요청을 하더라도 비용이 합리적인 범위 내에 유지되도록 해야 합니다. 프롬프트 캐싱(Prompt Caching) 기능 사용을 비롯해 최적의 모델을 선정하고자 했습니다.
아키텍처
카카오게임즈는 도입 전 검토를 면밀하게 한 끝에 GenAI를 활용해 채팅 번역 시스템을 구축하기로 결정했습니다. 게임 내 실시간 채팅 번역의 핵심은 첫 번째가 응답 속도였으며, 두 번째가 번역 품질이었습니다. 그래서 모델을 선택할 때에는 응답 속도를 중점으로 모델을 살펴 봤으며 Anthropic Claude 3.5 Haiku 모델을 선택하게 되었습니다. 또한 두 가지 아키텍처를 고려하고 여러 방법을 통해 번역 품질을 향상시키려고 노력했습니다.
아키텍처 1. Amazon Bedrock만을 활용한 아키텍처
프롬프트에 단어장을 포함하여 특정 게임에 대한 지식을 제공했으며 벡터 데이터베이스 사용에 비해 적은 데이터로 단어장을 구성합니다. 단어장이 커질수록 다채로운 표현에 답변할 수 있지만, 비용이 증가하고 레이턴시, 답변 퀄리티에 영향을 줄 수 있습니다. 단어장으로 인해 정적 데이터가 프롬프트의 대부분을 차지하며 이를 프롬프트 캐싱을 통해 최적화합니다. 기존 게임 서버 영향을 최소화하기 위해 별도의 API 형식으로 분리했습니다.
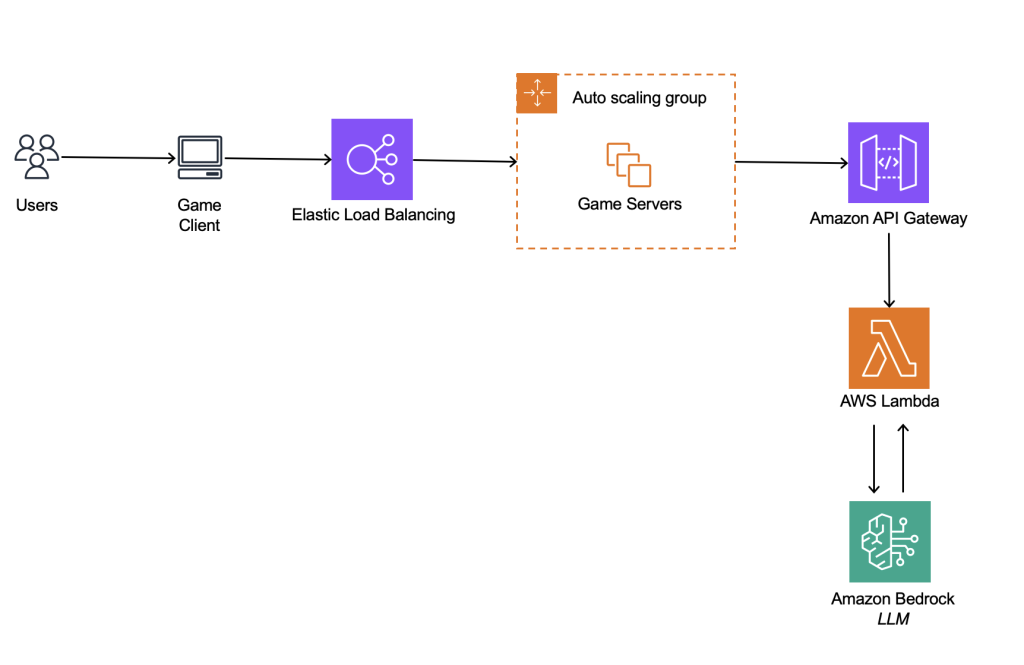
아키텍처 2. RAG를 위한 Amazon Knowledge Base를 활용한 아키텍처
Knowledge Base를 활용하여 게임 및 번역 표현에 대한 RAG를 구축하고 특정 표현에 대한 번역 내용이 필요할 때마다 벡터 데이터베이스를 조회하여 답변을 생성합니다. 게임 및 번역 표현은 텍스트 형식으로 정리된 후 S3에 저장되어 주기적으로 벡터 데이터베이스에 동기화됩니다. 아키텍처 1과 동일하게 기존 게임 서버 영향을 최소화하기 위해 별도의 API 형식으로 분리합니다.
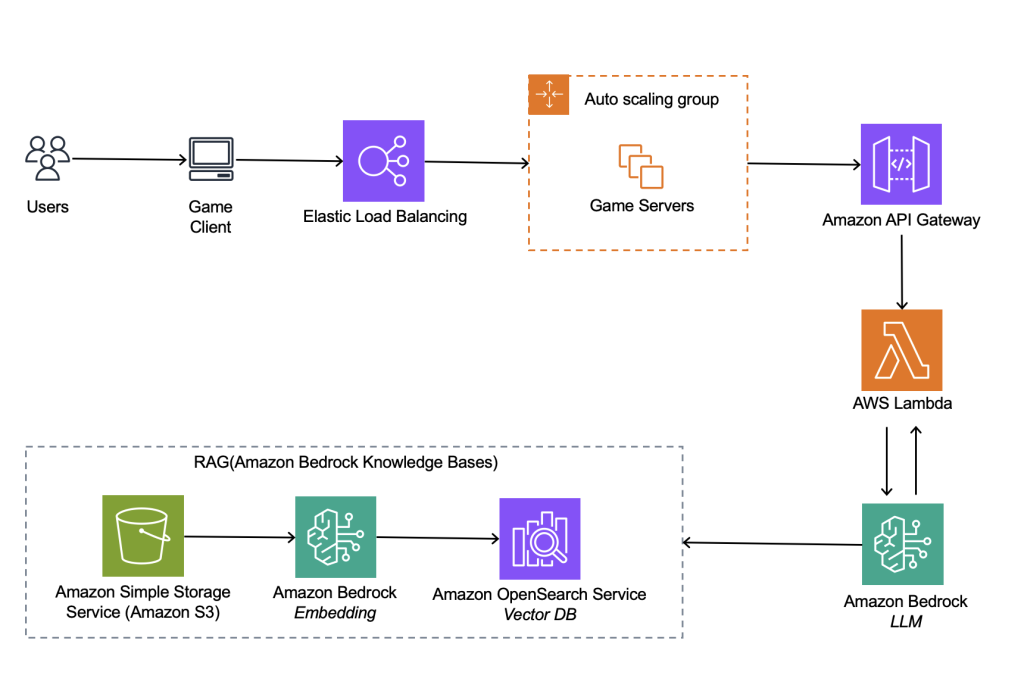
처음에는 번역 품질 향상을 위해 아키텍처 2와 같이 RAG를 고민했습니다. RAG를 사용하면 단어 데이터를 벡터화해서 저장하고 유사도 검색을 통해 정확한 번역을 할 수 있습니다. 그러나 RAG를 사용하는 경우 벡터 데이터베이스에 유사도 검색을 하게 되어 프롬프트만 사용할 때보다 응답 시간이 느려집니다. 속도가 중요한 실시간 채팅 번역의 특성상 응답 시간이 느려지는 선택지는 좀 더 면밀한 검증과 최적화가 필요했기 때문에 결국 아키텍처 1과 같이 프롬프트만 사용하는 방법을 선택했습니다. 뒤에서 서술할 프롬프트 최적화, 프롬프트 캐싱, 단어장 같은 방법들을 통해 프롬프트 만으로도 원하는 번역 품질과 저지연시간을 달성할 수 있었습니다.
프롬프트 엔지니어링/캐싱을 통한 개선
카카오게임즈는 지속적인 프롬프트 엔지니어링을 통해 번역 품질을 점진적으로 개선했습니다. ‘오딘:글로벌’의 게임 특성과 실제 운영 환경을 고려해 다음과 같은 기준으로 프롬프트를 설계했습니다.
- Instructions, Role, Output Priming을 게임 내 상황에 맞게 명확히 정의
- 게임에 대해 잘 이해하고 있는 비개발자/사업 담당자가 쉽게 수정·관리할 수 있도록 S3에 텍스트 파일(txt) 형태로 단어장을 업로드하고, 해당 단어장을 프롬프트에서 사용하여 게임 특화 용어에 대한 번역을 진행
- 개발 담당자가 프롬프트를 개선해야 하는 경우라면 Bedrock에서 제공하는 프롬프트 관리를 활용하여 버전 관리 및 테스트
- LLM을 통해 프롬프트를 재작성하고 개선해나가는 방식을 통해 프롬프트를 개선하고 있었으며, Bedrock에서 제공하는 프롬프트 최적화가 GA된 이후로는 해당 기능을 통해 지속적인 최적화
이를 통해 번역 품질을 지속적으로 개선할 수 있는 유연한 구조를 마련했습니다.
프롬프트 예제:
프롬프트의 경우 한국어로 작성해도 문제 없었지만 프롬프트 최적화 기능은 최적의 결과를 위해 영어로 권장하고 있어 이를 활용하고자 영어로 프롬프트를 작성했습니다.
또한 단어장으로 인해 고정적이고 변하지 않는 프롬프트가 길어지게 되어 프롬프트 캐싱 기능을 활용해 비용과 속도 모두를 개선했습니다. 적용 시에 프롬프트를 크게 다음과 같이 두 부분(Prefix, Suffix)으로 나누어 Prefix를 캐싱하는 방법으로 프롬프트 캐싱을 적용했습니다.
- Prefix : 고정적이며 변하지 않는 Instructions, Role, 단어장, Output Priming에 해당하는 게임 특성에 맞춰 작성된 프롬프트
- Suffix : 유저가 입력한 실시간 채팅 문자열처럼 변동적인 인풋 데이터
프롬프트 캐싱은 응답 속도도 개선되지만, 특히 캐시에서 읽어오는 경우 입력 토큰 비용이 1/10로 줄어드는 효과가 있어 길고 고정적인 프롬프트를 사용하는 경우라면 비용 최적화 측면에서도 큰 효과를 볼 수 있습니다. 게임 특화 채팅 번역 시스템에서는 단어장을 사용하기 때문에 길고 고정적인 프롬프트가 필연적으로 만들어지게 되며, 이 경우 프롬프트 캐싱이 필수적이라고 판단했습니다.
프롬프트 캐싱 사용 예제 :
# Inference parameters to use.
temperature = 0.5
top_k = 200
# Base inference parameters to use.
inference_config = {"temperature": temperature}
# Additional inference parameters to use.
additional_model_fields = {"top_k": top_k}
# Send the message.
response = bedrock_client.converse(
modelId=model_id,
messages=messages,
system=system_prompts,
inferenceConfig=inference_config,
additionalModelRequestFields=additional_model_fields
)
# Log token usage.
token_usage = response['usage']
logger.info("Input tokens: %s", token_usage['inputTokens'])
logger.info("Output tokens: %s", token_usage['outputTokens'])
logger.info("Total tokens: %s", token_usage['totalTokens'])
logger.info("Stop reason: %s", response['stopReason'])
# GenAI 모델 지정
model_id = "us.anthropic.claude-3-5-haiku-20241022-v1:0"
# 유지보수가 편하게 prompt 정보 분리 . Prompt Management로부터 가져오기
system_prompt_prefix = client.get_prompt(
promptIdentifier=PROMPT_IDENTIFIER
promptVersion=PROMPT_VERSION
)
# 입력채팅 문자열과 변환 할 언어를 지정
suffix_prompt = "{\"input_chat_str\": \"" + chat_str + "\",\n \"input_language\": \"" + language_type + "\"}"
# cachePoint 지정, prefix, suffix prompt 입력
system_prompts = [{"text": system_prompt_prefix}, {"cachePoint": {"type": "default"}}]
message = {
"role": "user",
"content": [
{"text": suffix_prompt}
],
}
messages = []
messages.append(message)
response = generate_conversation(bedrock_client, model_id, system_prompts, messages)
response_text = response['output']['message']['content'][0]['text']빠른 도입과 운영을 위한 모니터링 시스템
도입 당시, 게임 런칭이 얼마 남지 않았기 때문에 초기 프롬프트 개선 작업을 포함해서 시스템 구축을 20일 안에 했어야 하는 상황이었습니다. 프롬프트 개선과 테스트에 가장 긴 시간을 쏟았음에도 불구하고 일정을 지킬 수 있었던 이유는, 이미 카카오게임즈가 익숙하게 사용하고 있는 AWS 서비스(Lambda, ELB)들과 Bedrock의 높은 호환성 덕분이었습니다. 실제로 도입하기 위한 개발 및 연동 작업은 하루도 걸리지 않았을 정도로 매우 빠르게 채팅 번역 시스템을 구축할 수 있었습니다. 또한 프롬프트 개선과 테스트 과정에서 AWS의 기술 지원을 통해 Knowledge Base를 통한 빠른 RAG 검증 뿐 아니라 프롬프트 캐싱, 프롬프트 관리, 프롬프트 최적화와 같이 운영에 도움이 되는 Amazon Bedrock의 신규 기능들을 학습하여 지속적인 운영 최적화를 할 수 있었습니다.
도입 이후에는 다음과 같은 모니터링 요소들을 통해 시스템 안정성과 효율성을 확인하고 증가시키는 과정들을 진행하고 있습니다.
- Bedrock 런타임 지표: 인풋/아웃풋 토큰 사용량, 총 호출 수, 호출 지연 시간
- Lambda 동시성, 실행 시간 및 End to End API 호출 지연 시간
- 로그 : 게임 서버 로깅, CloudWatch Logs에서의 모델 호출 로깅을 통해 로그 확인
이러한 모니터링 시스템 덕분에 시스템 운영 안정성도 함께 확보할 수 있었습니다.
Next step : 초저지연시간을 위한 SLM
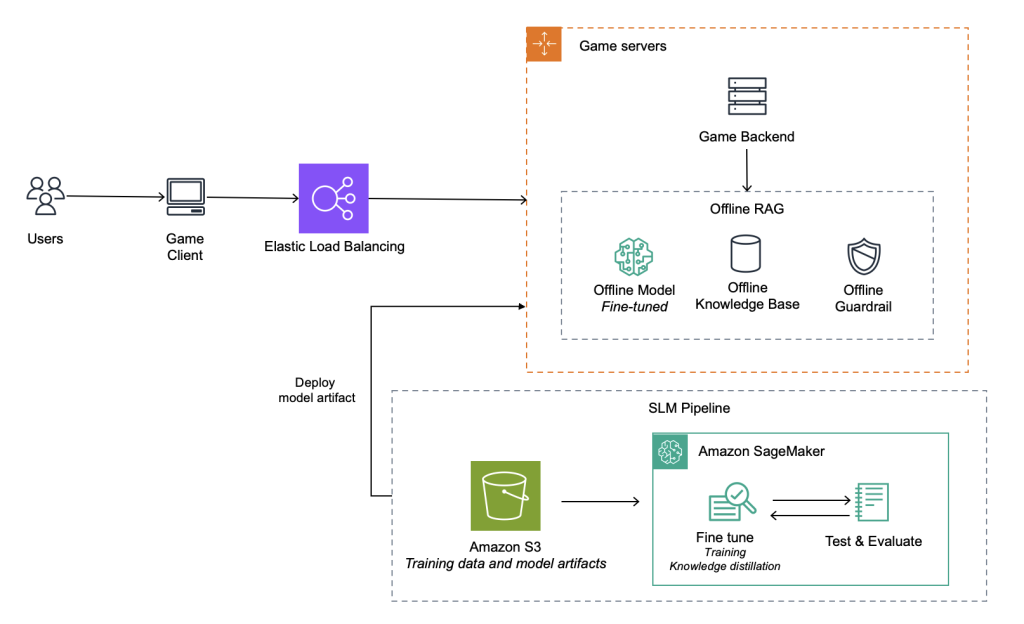
아키텍처 3. SLM을 활용한 초저지연 온디바이스 GenAI
카카오게임즈는 현재 수준의 채팅 번역 솔루션에 만족하지 않고 개선하기 위해 노력 중이며 여전히 RAG도 고려하고 있습니다. 정확한 번역 품질 뿐만 아니라 다수의 게임에 쉽게 채팅 시스템을 도입하고 관리/운영하기 위해서는 RAG가 필요합니다. RAG에서의 응답 속도 개선은 빠른 유사도 검색을 제공해줄 수 있는 In-memory 데이터베이스를 통해 구현 시 가능할 것으로 보고 있습니다.
또한 SLM(Small Language Model)을 구성하고 이를 미세 조정(Fine-tuning)하여 기존 품질을 유지하면서 초저지연시간인 GenAI 솔루션을 아키텍처 3과 같이 만드는 것을 고려하고 있습니다. 이를 통해 1초 미만의 초저지연시간을 달성하면서도 높은 정확도의 채팅 번역 시스템을 다수의 게임 컨텍스트에 맞게 제공할 예정입니다. 이 경험을 바탕으로 게임 내의 다양한 부분에 SLM을 도입할 계획을 가지고 있습니다.
결론
본 글에서는 카카오게임즈의 실시간 채팅 번역 솔루션을 구성하는 과정에서의 고민을 살펴보고 어떤 과정으로 Amazon Bedrock 사용을 결정하게 되었는지 알아봤습니다. 또한 저지연시간 달성을 위해 RAG보다 프롬프트 개선을 통해 채팅 번역 기능을 만들게 된 계기와 솔루션의 개발 및 운영을 위한 프롬프트 관리, 최적화, 캐싱 기능을 사용한 과정을 살펴봤습니다. 마지막으로 운영 과정에서 어떤 요소들을 살펴봐야 하는지 확인할 수 있었습니다.
카카오게임즈의 본 사례가 게임 안에서의 GenAI 사용을 고려하고 있거나 혹은 저지연시간 요구사항이 필요한 다른 조직들에게 도움이 되기를 바랍니다.